
✍🏻 31일 공부 이야기.

오늘 공부한 실습 코드는 위 깃허브 사진을 클릭하면 이동됩니다 :)
Mask Data(Kaggle)
이번에는 마스크를 쓴 사람과 쓰지 않은 사람들의 사진을 학습하여 마스크 착용 여부를 알아내는 실습을 해보자.
캐글에서 파일을 다운받아줬는데 파이썬에서도 압축파일을 풀어주는 라이브러리가 있다.
📌 압축 파일 관리 툴
# 압축파일 관리 툴
import zipfile
content_zip = zipfile.ZipFile('./data/archive.zip') # 압축 해제
content_zip.extractall('./data')
content_zip.close()
import os
os.listdir('./data/Face Mask Dataset/') # 폴더 내 파일명(디렉토리명) 확인 가능💻 출력
['Test', 'Train', 'Validation']
나는 코드 파일이 있는 폴더에 data라는 폴더를 만들어주었고 그 안에 해당 zip 파일이 들어가있었다.
압축을 해제하고 해당 폴더 안에 어떤 것들이 들어가있는지 확인해보았더니 'Test', 'Train', 'Validation' 폴더가 더 있는 것을 확인할 수 있었다.

📌 파일 정리
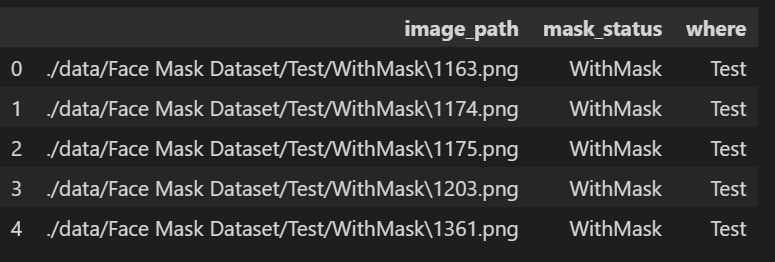
이미지 파일로 가득한 것들을 이미지 경로, 마스크 착용 여부, 파일이 있는 폴더 이름 총 3가지 변수로 분리한 데이터프레임을 만들어보았다. (관리하기 편하게 😊 )
# 파일을 정리해보자.
path = "./data/Face Mask Dataset/"
dataset = {'image_path' : [], 'mask_status' : [], 'where': []}
for where in os.listdir(path): # where은 위에서 보았다시피 Test, Train, Validation이 된다
for status in os.listdir(path + "/" + where): # WithMask , WithoutMask
for image in glob.glob(path + where + '/' + status + '/' + '*.png'):
dataset['image_path'].append(image)
dataset['mask_status'].append(status)
dataset['where'].append(where)
# 데이터프레임화
dataset = pd.DataFrame(dataset)
dataset.head()💻 출력
📌 데이터 확인
# 랜덤하게 어떤 사진들이 있는지 확인
import cv2
plt.figure(figsize=(15, 10))
for i in range(9):
random = np.random.randint(1, len(dataset))
plt.subplot(3, 3, i + 1)
plt.imshow(cv2.imread(dataset.loc[random, 'image_path']))
plt.title(dataset.loc[random, 'mask_status'], size = 15)
plt.xticks([])
plt.yticks([])
plt.show()💻 출력

grayscale을 적용시키지 않아 사진이 푸르게 나왔지만 어느정도 어떤 데이터가 들어있는지 확인은 가능하다.
우리는 마스크 착용 여부에 관한 모델링을 진행할 것이니, 각 Test, Train, Validation 폴더에 있던 사진들의 마스크 착용 여부 분포도 짚고 넘어가야한다.
만약 불균형인 데이터라면 oversampling이든 undersampling이든 샘플링을 통해 그 균형을 맞춰주어야한다.
# Train, Test, Val 데이터가 분리되어있는대로 사용
train_df = dataset[dataset['where'] == 'Train']
test_df = dataset[dataset['where'] == 'Test']
val_df = dataset[dataset['where'] == 'Validation']
# Train, Test, Val 데이터 분포 확인
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
sns.countplot(x = train_df['mask_status'])
plt.title('Training Dataset', size = 10)
plt.subplot(1, 3, 2)
sns.countplot(x = test_df['mask_status'])
plt.title('Test Dataset', size = 10)
plt.subplot(1, 3, 3)
sns.countplot(x = val_df['mask_status'])
plt.title('Validation Dataset', size = 10)
plt.show()💻 출력
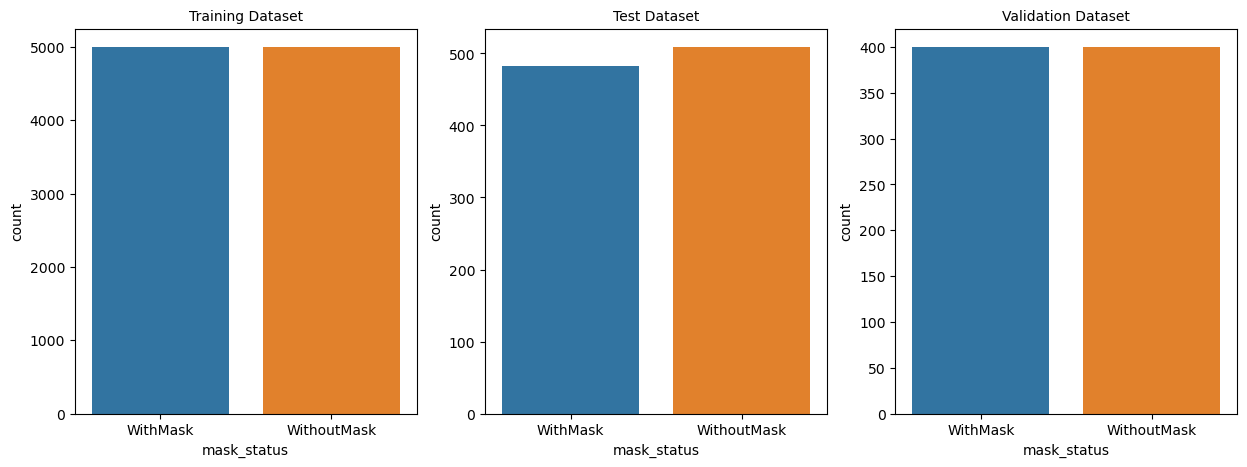
다행히 분포가 고르게 되어있어 따로 작업을 해줄 필요는 없어보인다.
데이터 전처리
이제 딥러닝을 돌리기 위한 데이터를 전처리해주어야한다.
data = []
image_size = 150
for i in range(len(train_df)):
# grayscale 변환
img_array = cv2.imread(train_df['image_path'][i], cv2.IMREAD_GRAYSCALE)
# resizing
new_image_array = cv2.resize(img_array , (image_size, image_size))
# encoding
# withmask를 1로 표시
if train_df['mask_status'][i] == 'WithMask':
data.append([new_image_array, 1])
else:
data.append([new_image_array, 0])위 작업은 이미지로 되어있는 데이터를 grayscale로 변환하고 150 * 150 사이즈로 만들어준 후, 마스크 착용 여부(착용 -> 1, 착용 X -> 0)의 데이터를 만들어준 것이다.
# 데이터 저장
X = []
y = []
for image in data:
X.append(image[0])
y.append(image[1])
X = np.array(X)
y = np.array(y)
# 그냥 한 번 더 데이터 분리
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=13)그렇게 만들어진 데이터를 각각 X, y 변수에 두고 우리에겐 데이터가 폴더 별로 나누어져있긴 하지만 그냥 한 번 더 데이터를 분리 시켜 모델링을 해보았다.
LeNet
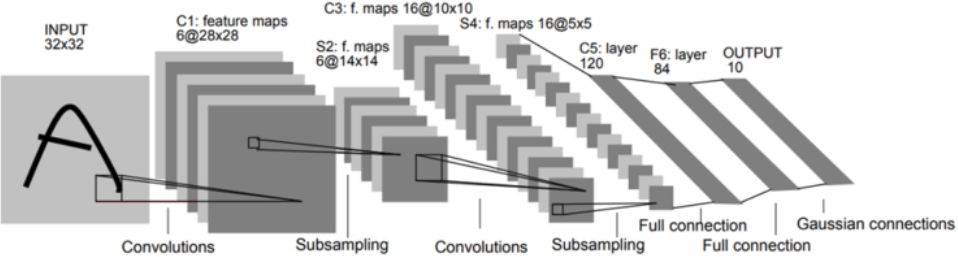
오늘 사용해볼 모델은 CNN의 개념이 도입된 LeNet이라는 모델이다.
CNN의 개념이 도입되었다란, convolution layer와 pooling, dropout 등 앞서 배웠던 이론으로 레이어를 쌓은 것을 말한다.
LeNet에도 여러 종류가 있고 현재 다양하게 변형이 되어서 어떤 것이 특정 LeNet이다!! 라고 말하기 어렵지만 그냥 가볍게 흐름만 파악하는 용으로 실습해보자.
# 모델링(LeNet)
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, kernel_size = (5, 5), strides = (1, 1), padding = 'same',
activation = 'relu', input_shape = (150, 150, 1)),
layers.MaxPooling2D(pool_size = (2, 2), strides = (2, 2)),
layers.Conv2D(64, (2, 2), activation = 'relu', padding = 'same'),
layers.MaxPooling2D(pool_size = (2, 2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation = 'relu'),
layers.Dense(1, activation = 'sigmoid') # 단일분류이므로 출력은 1개로
])
model.compile(optimizer = 'adam', loss = tf.keras.losses.BinaryCrossentropy(),
metrics = ['accuracy'])
# 학습
# (크기, 해상도1, 해상도2, 채널)
X_train = X_train.reshape(len(X_train), X_train.shape[1], X_train.shape[2], 1)
X_val = X_val.reshape(len(X_val), X_val.shape[1], X_val.shape[2], 1)
history = model.fit(X_train, y_train, epochs=4, batch_size=32)
# 성능
model.evaluate(X_val, y_val)validation set에서의 성능은 loss: 0.0970 - accuracy: 0.9710 로, 꽤 좋은 성능을 보이는 것 같다.
# 0.5보다 큰 경우 1로 취급
prediction = (model.predict(X_val) > 0.5).astype('int32')
print(classification_report(y_val, prediction))
print(confusion_matrix(y_val, prediction))💻 출력
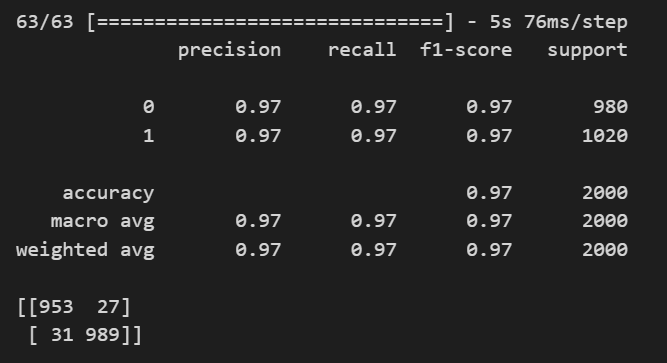
그리고 0.5보다 큰 것은 마스크를 착용했다고 하고 classification_report와 confusion_matrix를 그려보아도 꽤 괜찮아보인다.
제로베이스를 수강하며 틀리게 예측한 것에 대해 왜 틀리게 예측한 것인지 들여다 볼 필요성을 은근 강조하고 계시는 걸 느꼈다.
그래서 이번에도 틀린 것에 대해 확인해본 결과 아래와 같았다.
# 틀린 것에 대한 확인
wrong_result = []
for n in range(0,len(y_val)):
if prediction[n] != y_val[n]:
wrong_result.append(n)
len(wrong_result) # 58
import random
samples = random.choices(population = wrong_result, k = 6)
plt.figure(figsize = (14, 12))
for idx, n in enumerate(samples):
plt.subplot(2, 3, idx + 1)
plt.imshow(X_val[n].reshape(150, 150), interpolation='nearest')
plt.title(prediction[n])
plt.axis('off')
plt.show()💻 출력

사진이 확대되어있거나, 흐린 부분과 같은 사진들은 잘 인식을 못 하는 것 같다!
