
✍🏻 26일 공부 이야기.
오늘 실습한 코드는 아래 깃허브 사진을 클릭하면 이동합니다!

Boosting Algorithm
Boosting Algorithm에는 앞서 배운 Voting과 Bagging그리고 Boosting과 Stacking등이 있다.
Voting, Bagging은 여러 개의 분류기의 예측값을 투표를 통해 최종 예측 결과를 결정하는 방식이었는데 Boosting은 무엇일까?
Boosting은 여러 개의 약한 분류기가 순차적으로 학습을 하면서 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행하는 방식이다.
이때 약한 분류기란, 성능은 떨어지지만 속도가 빠른 분류기를 뜻한다.
Boosting은 그래디언트부스트, XGBoost, LightGBM 등이 있다.
와인 데이터를 통해 이들을 실습해보자.
와인 데이터
앞서 계속 실습했던 taste 컬럼에 대한 예측을 여러 모델들을 학습시키고 평가해보자. 이번에는 각각 모델을 돌리는 것이 아닌 한 번에 돌리는 방법이다.
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
models = []
models.append( ('AdaBoostClassifier', AdaBoostClassifier()))
models.append( ('GradientBoostingClassifier', GradientBoostingClassifier()))
models.append( ('RandomForestClassifier', RandomForestClassifier()))
models.append( ('DecisionTreeClassifier', DecisionTreeClassifier()))
models.append( ('LogisticRegression', LogisticRegression()))위 models변수에 모델명과 모델을 저장해준다.
from sklearn.model_selection import KFold, cross_val_score
results = []
names = []
for name, model in models:
kfold = KFold(n_splits=5, random_state=13, shuffle= True) # shuffle : 데이터 분할 전 데이터를 섞어라.
cv_results = cross_val_score(model, X_train, y_train, cv = kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(name, cv_results.mean(), cv_results.std())💻 출력

그리고 교차검증을 실시하며 각 모델의 성능을 추출하고 평균을 통해 최종 성능값을 확인해보기로 했다.
아래와 같이 시각화를 통해 확인할 수도 있다.
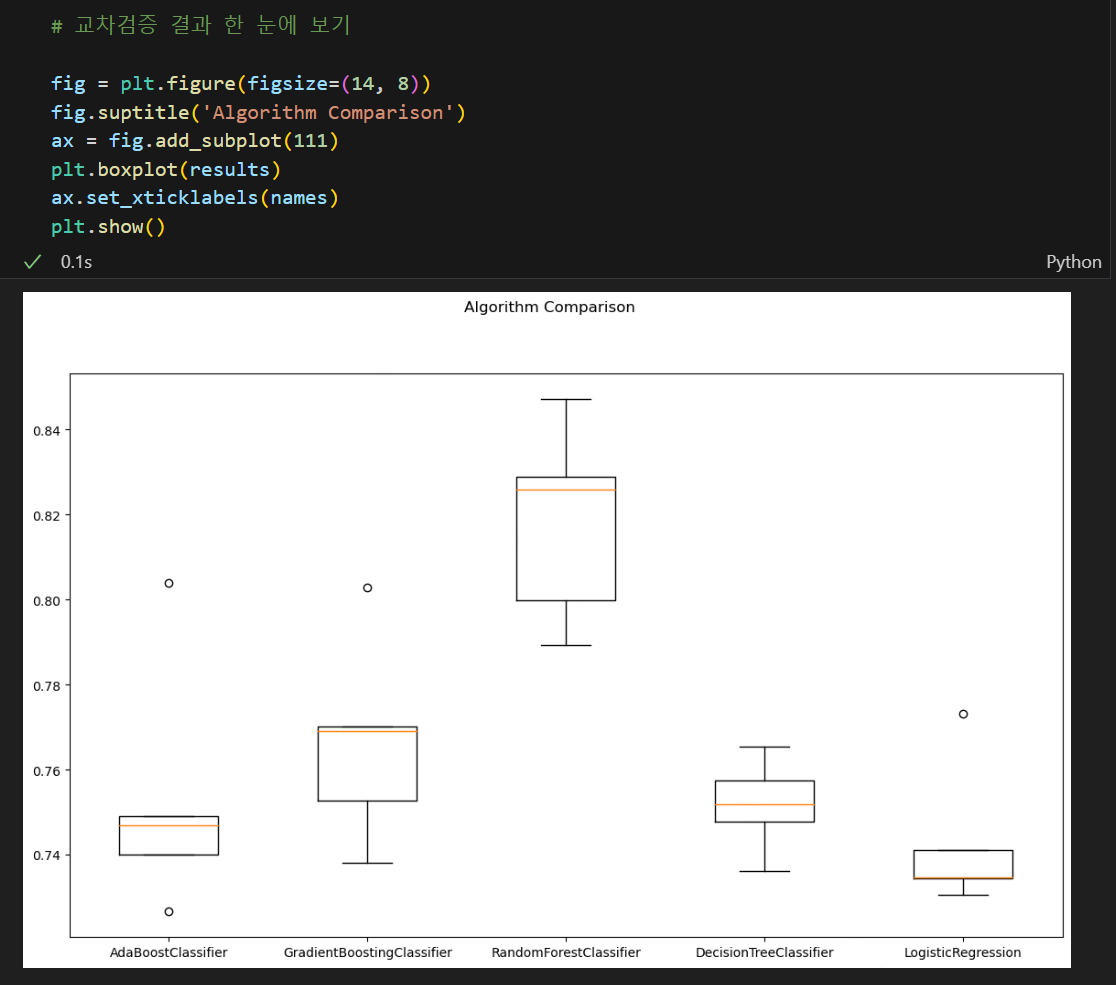
지금 와인 데이터에 대해서는 Random Forest의 성능이 제일 좋아보이지만, 이 모델이 무조건 좋다!가 아니다. 데이터의 특성마다 모델들의 성능은 달라진다는 것을 명심하자!
KNN

KNN은 K-Nearest Neighbor의 줄임말로, 지도 학습 알고리즘 중 하나인 K-최근접 이웃이다.
💡여기서 복습! 지도학습이란?
: 모델을 학습시킬 때 정답지까지 같이 주고 학습시키는 것을 말했다.
KNN의 알고리즘은 간단하다. 데이터로부터 k번째까지 가까운 데이터들의 클래스를 확인하고 투표를 통해 해당 데이터의 클래스를 결정하는 방식이다.
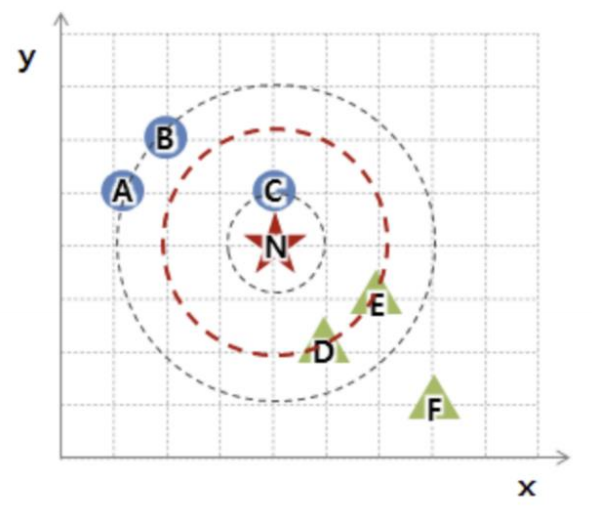
예를 들어 N의 클래스를 결정하고자 한다고 해보자.
- k = 1일 때, N과 가장 가까운 데이터는 C(○)이므로 N은 ○가 된다.
- k = 3일 때, N과 가장 가까운 데이터는 C(○), D(△), E(△)이므로 N은 △가 된다.
- k = 5일 때, N과 가장 가까운 데이터는 C(○), D(△), E(△), A(○), B(○)이므로 N은 ○가 된다.
이런 느낌인 것이다. 즉 KNN은 k값에 따라 결과가 바뀔 수도 있다.
KNN을 사용하기 위해선 또 필요한게 있는데
바로 거리 계산.
일반적으로 알고 있는 두 점 사이의 거리를 계산하는 공식을 이용하면 되지만 주의할 점이 하나 있다.
x축과 y축의 변화량이 다르다면 단위에 따라 계산되는 거리가 달라지므로 표준화를 하는 것이 좋다고 한다.
iris 데이터
iris 데이터를 통해 실습해보자.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5) # default = 5
knn.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
accuracy_score(y_test, pred)💻 출력
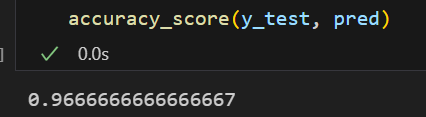
이때 KNN은 그냥 주어진 데이터로부터 가장 가까운 클래스가 무엇인지 찾는 과정이기 때문에 이전 모델과 같이 실제로 학습(fit)을 하지는 않는다. 하지만 sklearn 상 fit을 시켜주어야하기 때문에 코드는 실행시켜주어야한다.
GBM(Gradient Boosting Machine)
여러 개의 약한 분류기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해가는 방식이 Boosting Algorithm이라 했다. GBM은 가중치를 업데이트할 때 경사하강법을 이용하는 것을 말한다.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
gb_clf = GradientBoostingClassifier(random_state=13)
gb_clf.fit(X_train, y_train)
gb_pred = gb_clf.predict(X_test)
accuracy_score(y_test, gb_pred)똑같이 GradientBoostingClassifier을 임포트하여 사용할 수 있다.
# GridSearch
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [100,500],
'learning_rate' : [0.05, 0.1]
}
## verbose 옵션 : 수행 결과 메세지 출력 여부
## 0(default) : 출력 x, 1 : 간단한 메세지 출력, 2 : 하이퍼파라미터별 메세지 출력
grid = GridSearchCV(gb_clf, param_grid=params, cv = 2, verbose=2, n_jobs=-1)
grid.fit(X_train, y_train)
accuracy_score(y_test, grid.best_estimator_.predict(X_test))또한 GridSearchCV도 할 수 있는데 GBM은 속도가 매우 느리다는 단점이 있다.
HAR 데이터로 실습해보려고 했는데 15분이 넘게 돌아가고 있어서 output을 확인하지 못했다 😭
속도가 빠른 Boosting Algorithm은 없을까?
XGBoost
!pip install xgboost

트리 기반의 앙상블 학습에서 주목받고 있는 알고리즘이다.
GBM 기반의 알고리즘인데, GBM의 느린 속도를 다양한 규제를 통해 해결했다.
특히 병렬 학습이 가능해졌으며 Regression과 Classification 문제를 모두 지원한다.
XGBoost는 반복 수행시마다 내부적으로 학습 데이터와 검증 데이터를 교차검증을 수행하는데 교차검증을 통해 최적화되면 반복을 중단하는 조기 중단 기능을 가지고 있다.
주요 파라미터
nthread: CPU의 실행 스레드 개수를 조정하는 파라미터. 디폴트는 전체 스레드를 사용함.eta: GBM의 학습률n_estimatorsmax_depth
조기 중단을 하기 위한 파라미터
early_stopping_rounds: 조기 중단할 수 있는 최소 반복 횟수eval_set: 평가를 수행하는 별도의 검증 데이터 셋eval_metric: 평가를 수행하는 성능 기준
XGBoost를 사용하기 위한 몇 가지 주의사항이 있다.
먼저, fit시킬 때 xgb.fit(X_train, y_train)의 형태를 생각할 것이다.
하지만 이 때 X_train과 y_train을 그대로 사용하면 에러를 보게 될 것이다.
먼저 XGBoost에는 numpy array 값의 형태로 데이터를 넣어주어야하기 때문에 X_train -> X_train.values 로 변경해주어야한다.
ValueError: Invalid classes inferred from unique values of
y.
또한 위와 같은 에러를 보게 되었다면 y_train 안에 데이터들이 0부터 시작하는 것이 아니여서 그런 것이니 아래와 같은 작업을 실행시킨 후 다시 fit을 시켜주면 된다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.fit_transform(y_test)따라서 최종 모델링하는 코드는 아래와 같다.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_train = le.fit_transform(y_train)
y_test = le.fit_transform(y_test)
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimators = 400, learning_rate = 0.1, max_depth=3)
xgb.fit(X_train.values, y_train) # xgboost에는 numpy values값의 형태로 넣어주어야한다.
accuracy_score(y_test, xgb.predict(X_test))💻 출력
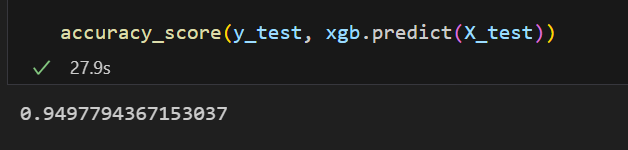
그럼 조기 종료 조건은 어떻게 할 수 있는가.
# 조기 종료 조건과 검증 데이터 지정
evals = [(X_test.values, y_test)] # 검증 데이터 셋. 이번 실습에서는 테스트 셋을 검증 셋으로 설정했다.
xgb = XGBClassifier(n_estimators = 400, learning_rate = 0.1, max_depth=3)
xgb.fit(X_train.values, y_train, early_stopping_rounds=10, eval_set=evals)
accuracy_score(y_test, xgb.predict(X_test))💻 출력
위와 같이 조기 종료 조건 파라미터를 설정해주면 된다.
성능이 조금 떨어질 수도 있겠지만 시간이 단축된다는 장점이 있다.
LightGBM
!pip install lightgbm
LightGBM또한, XGBoost와 함께 주목받고 있는 알고리즘 중 하나이다. LightGBM은 속도가 굉장히 빠르지만 적은 수의 데이터에는 어울리지 않는다고 한다.(일반적으로 10000건 이상의 데이터 필요)
XGBoost는 CPU만 쓰지만 LightGBM은 GPU 버전도 존재한다.(아마 버전을 따로 설치해야하는 것 같다.)
from lightgbm import LGBMClassifier
lgbm = LGBMClassifier(n_estimators = 400, learning_rate = 0.1, max_depth=3)
lgbm.fit(X_train.values, y_train)
accuracy_score(y_test, lgbm.predict(X_test.values))💻 출력

속도가 굉장히 빨랐다!
