✍🏻 27일 공부 이야기.
오늘 실습한 코드는 아래 깃허브 사진을 클릭하면 이동합니다.

credit card fraud detection(신용카드 부정 사용 검출)
이 또한 캐글 데이터이다.
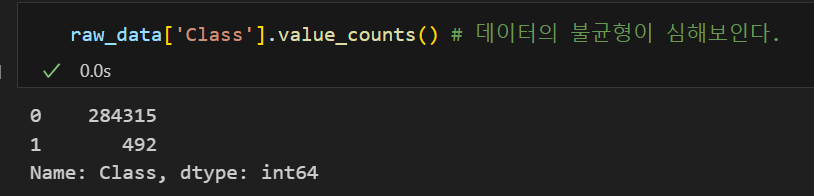
위 데이터는 신용카드 사기 검출 분류 실습용 데이터이며 Class 컬럼이 사기 유무를 의미한다.(우리의 타겟 데이터!!)
 |  |
|---|
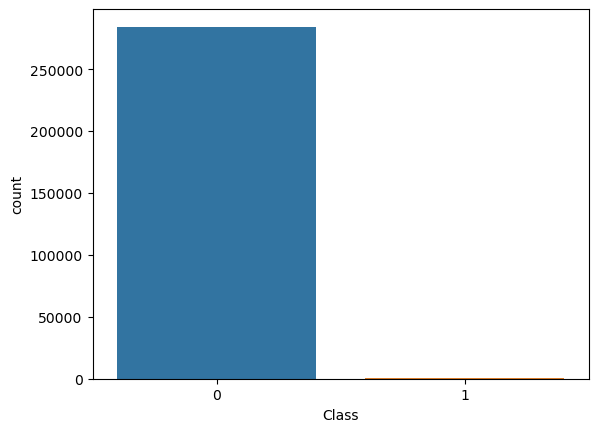
Class 컬럼은 전체 데이터의 약 0.17%만이 사기를 의미하는 1을 가지고 있어 데이터 불균형이 굉장히 심하다.
일단, Class의 분포를 Train셋과 Test셋에 동일하게 적용하여 데이터를 나누고 데이터의 불균형을 확인하면 아래와 같다.
X = raw_data.iloc[:, 1:-1] # V1 ~ Amount 컬럼까지
y = raw_data.iloc[:, -1] # Class 컬럼
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
stratify=y,
random_state=13)
np.unique(y_train, return_counts = True)💻 출력

그리고 여러 모델들을 돌릴 것이기 때문에 분류기 성능을 반환하는 함수와 roc 커브를 출력해주는 함수를 만들어두자.
📌 분류기의 성능 확인 함수
# 분류기 성능을 return하는 함수
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def get_clf_eval(y_test, pred):
acc = accuracy_score(y_test, pred)
pre = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred)
return acc , pre, recall, f1, roc_auc
# confusion matrix 출력 함수
from sklearn.metrics import confusion_matrix
def print_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
acc, pre, recall, f1, auc = get_clf_eval(y_test, pred)
print('***Confusion matrix***')
print(confusion)
print('***********************')
print("Accuracy : {0:.4f} , Precision : {1:.4f}".format(acc, pre))
print("Recall : {0:.4f} , F1 : {1:.4f}, AUC : {2:.4f}".format(recall, f1, auc))📌 roc 커브 출력 함수
# roc 커브
from sklearn.metrics import roc_curve
def draw_roc_curve(models, model_names, X_test, y_test):
plt.figure(figsize=(10,10))
for model in range(len(models)):
pred = models[model].predict_proba(X_test)[:,1]
fpr, tpr, threshold = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label = model_names[model])
plt.plot([0,1], [0,1], 'k--', label = 'random quess')
plt.title('ROC')
plt.legend()
plt.grid()
plt.show()첫번째 시도 - 무작정 돌려보자
그리고 이제 일단 무작정 모델들을 돌려보자.
우리가 배운 LogisticRegression, DecisionTreeClassifier, RandomForestClassifier, LGBMClassifier의 성능을 살펴보자.
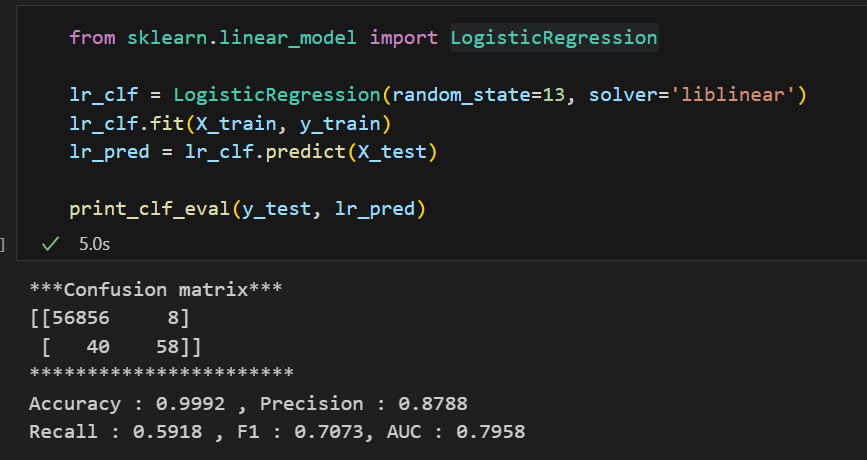 LogisticRegression LogisticRegression | 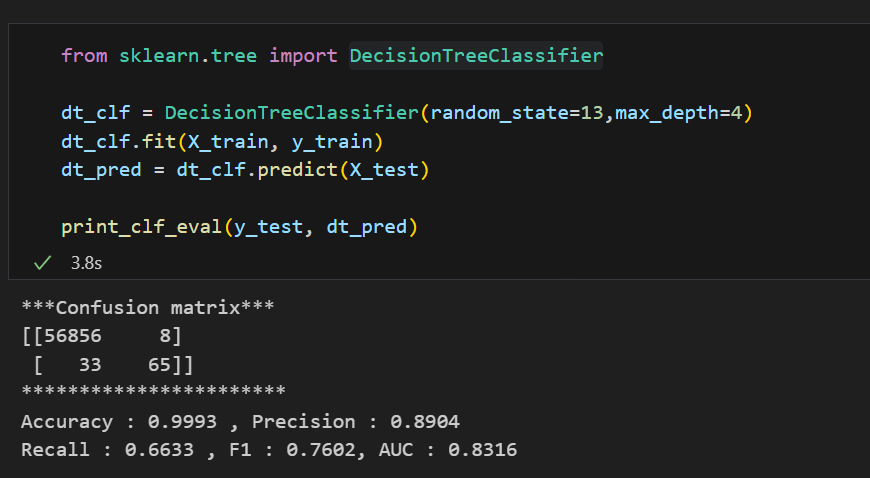 Decision Tree Decision Tree |
|---|---|
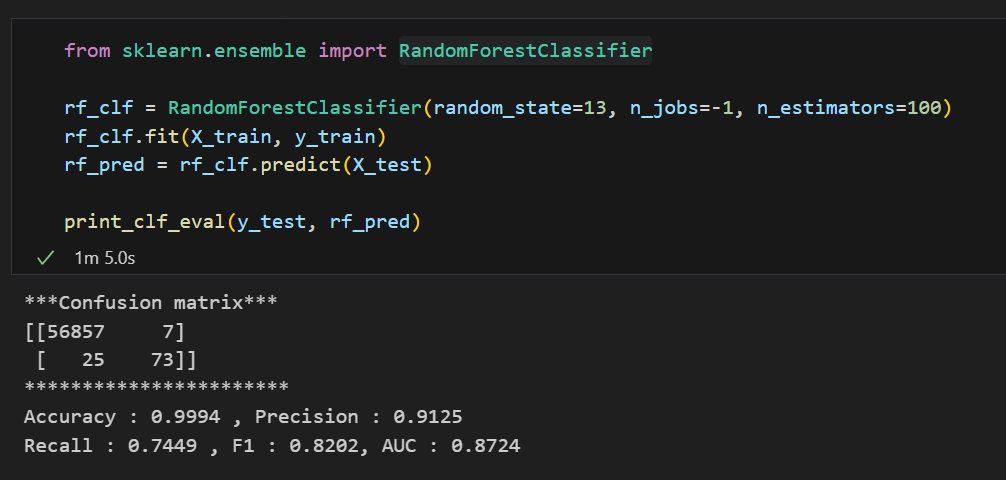 Random Forest Random Forest | 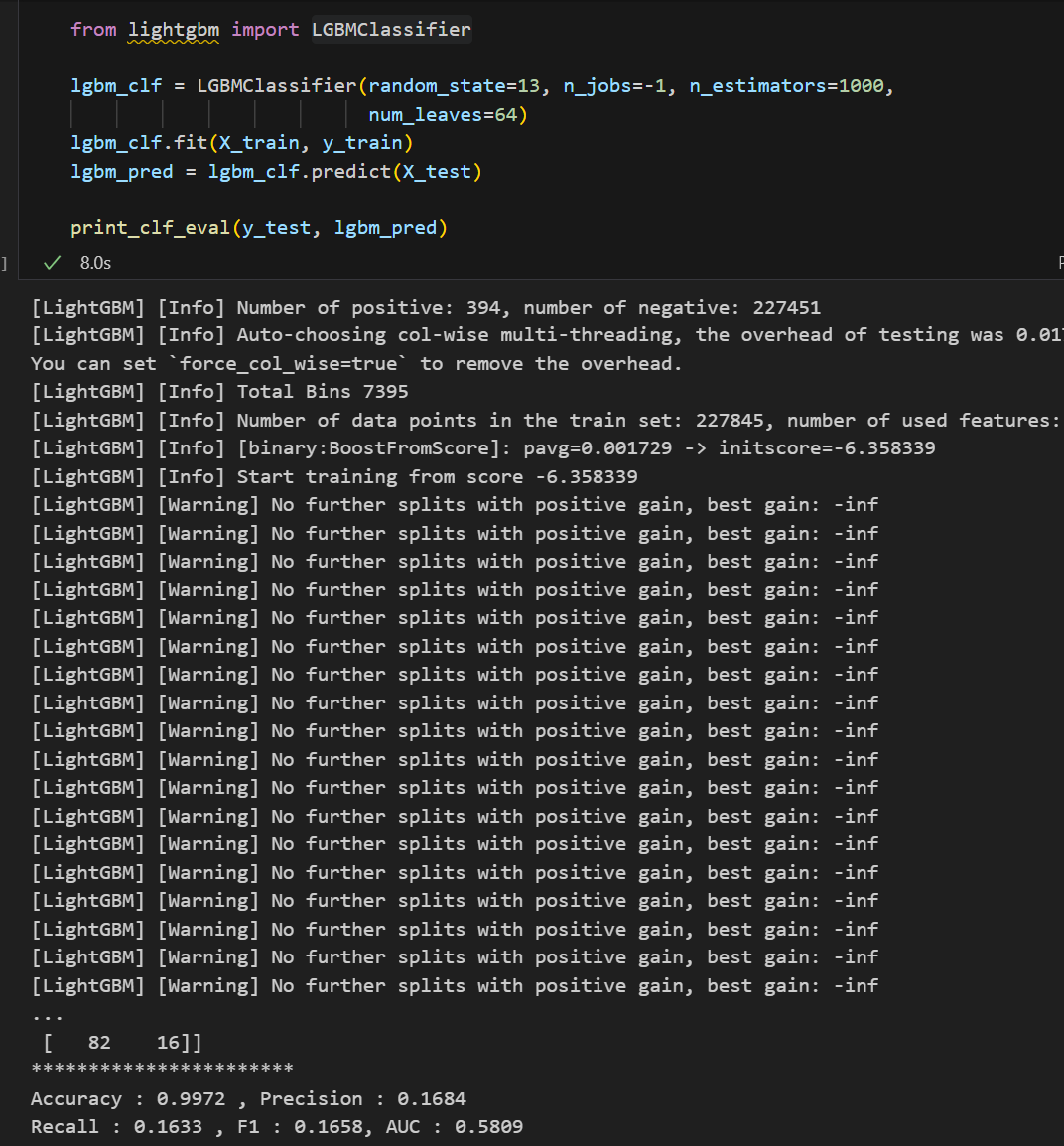 LightGBM LightGBM |
각각의 모델들을 한 눈에 살펴보기엔 좀 힘들다. 모델과 Test 데이터를 입력하면 성능을 출력해주고 각 모델들의 성능을 데이터프레임으로 정리해주는 함수를 만들어보자.
📌 다수의 모델들의 성능을 데이터프레임으로 반환하는 함수
# 모델과 데이터 입력시 성능을 출력하는 함수
def get_result(model, X_train, y_train, X_test, y_test):
model.fit(X_train, y_train)
pred = model.predict(X_test)
return get_clf_eval(y_test, pred)
# 다수의 모델들의 성능을 정리하여 데이터프레임으로 반환하는 함수
def get_result_pd(models, model_names, X_train, y_train, X_test, y_test):
col_names = ['accuracy', 'precision', 'recall', 'f1', 'roc_auc']
tmp = []
for model in models:
tmp.append(get_result(model, X_train , y_train, X_test, y_test))
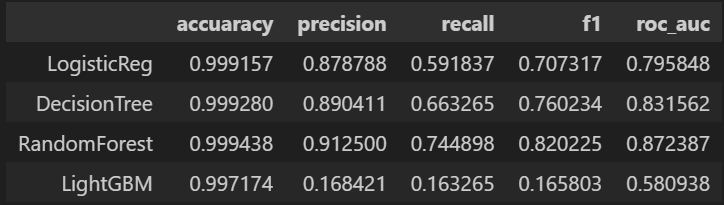
return pd.DataFrame(tmp, columns=col_names, index = model_names)위 함수를 이용해서 앞서 네 가지 모델을 돌리면 아래와 같다.
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results💻 출력
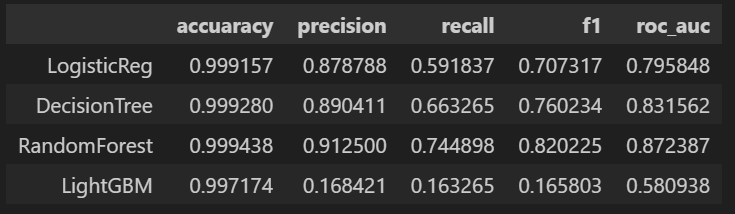
이때 우리는 무엇을 보아야할까? accuracy가 99%로 높다고 마냥 좋아하면 될까?
아니다.
우리가 가진 데이터는 현재 데이터의 불균형이 있기 때문에 잘 살펴보면 실제 1(Fraud)를 잘 예측할 수 있어야할 것이다. 그러면 우리에게 중요한 모델 성능 지표는? Recall일 것이다.
Recall을 좀 더 향상시키기 위해 다른 시도도 해보자.
두번째 시도 - scaler
# 'amount'(신용카드 사용 금액) 컬럼 확인
plt.figure(figsize=(10,5))
sns.distplot(raw_data['Amount'], color = 'r')
plt.show()💻 출력
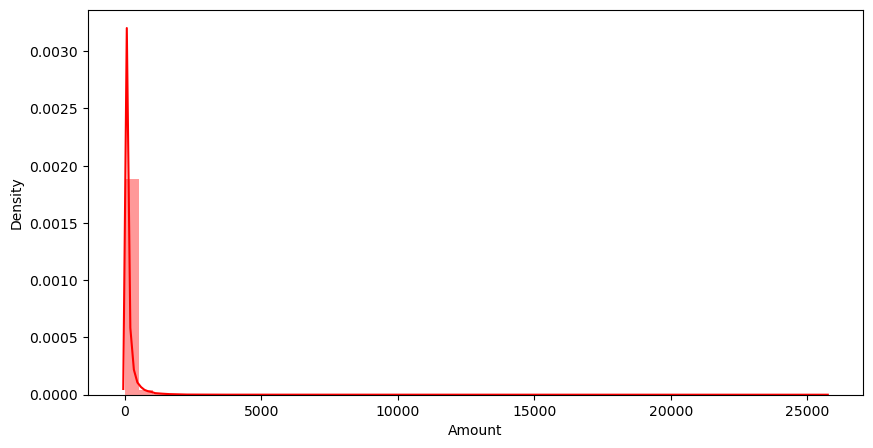
각 컬럼들의 데이터 분포를 살펴보다가 Amount 컬럼의 분포가 눈에 띄었다. 특정 범위에 너무 몰려있는데 만약 1(Fraud)을 구분하는데에 해당 컬럼이 영향을 끼친다면 데이터 분포가 좀 더 고르게 되어있어야 성능이 좋아질 것이다.
먼저 StandardScaler를 적용해보자.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
amount_n = scaler.fit_transform(raw_data['Amount'].values.reshape(-1,1))
raw_data_copy = raw_data.iloc[:, 1:-2]
raw_data_copy['Amount_Scaled'] = amount_n
X_train, X_test, y_train, y_test = train_test_split(raw_data_copy, y, test_size=0.2,
stratify=y,
random_state=13)
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticReg', 'DecisionTree', 'RandomForest', 'LightGBM']
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results 💻 출력
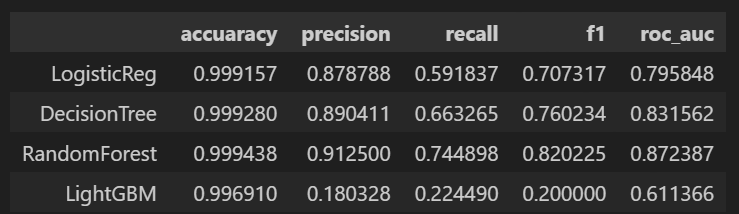
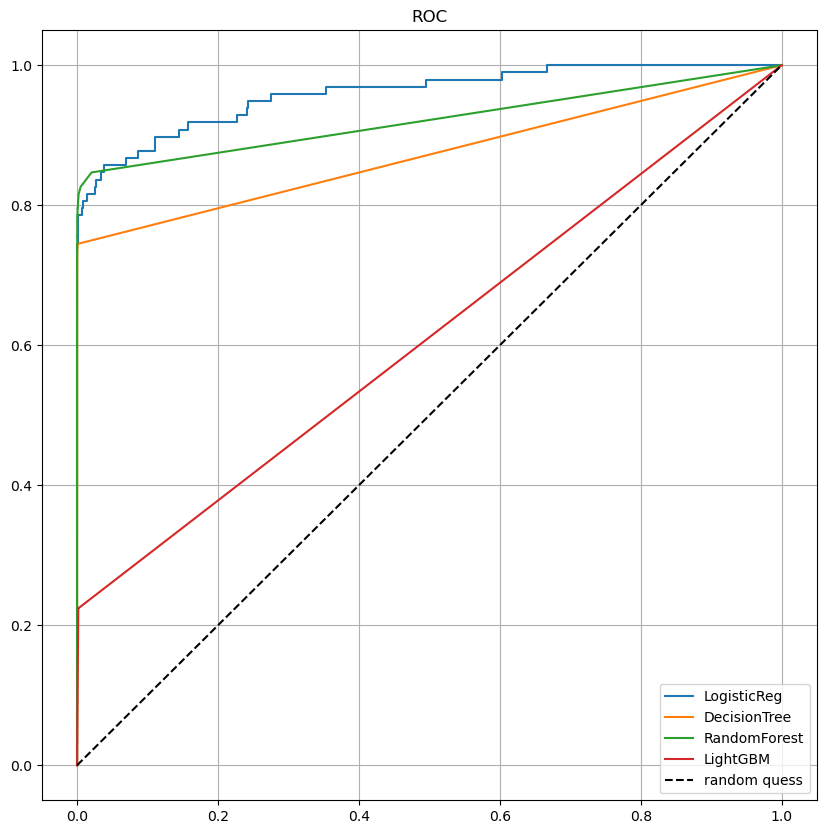
앞서 만든 함수를 통해 살펴본 roc 커브도 같이 보았는데 큰 성능 향상은 없어보인다.
두번째로, StandardScaler대신 log를 취해보자.
amount_log = np.log1p(raw_data['Amount'])
raw_data_copy['Amount_Scaled'] = amount_log
plt.figure(figsize=(10,5))
sns.distplot(raw_data_copy['Amount_Scaled'], color = 'r')
plt.show()💻 출력
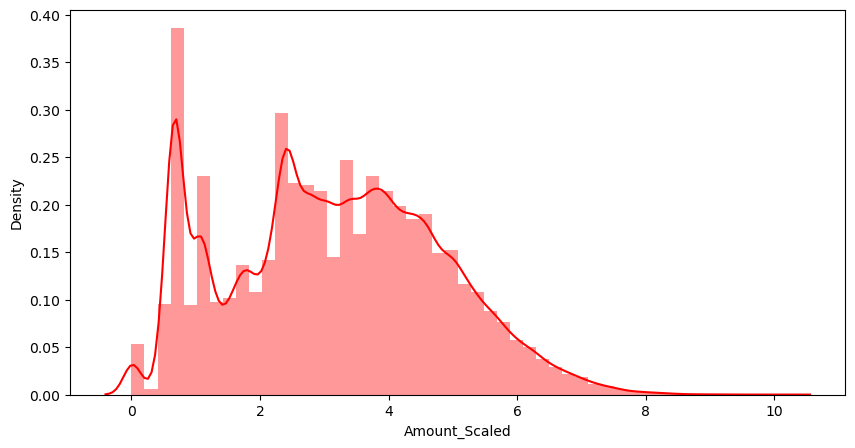
오! 얼추 데이터의 분포가 고르게 된 것 같다. 성능이 좀 괜찮아졌을까!??
음.. 별 차이는 없는 것 같다.
다른 처리가 필요할 듯 싶은데 무엇을 더 할 수 있을까?
세번째 시도 - 이상치 제거
이상치들을 제거해보자.
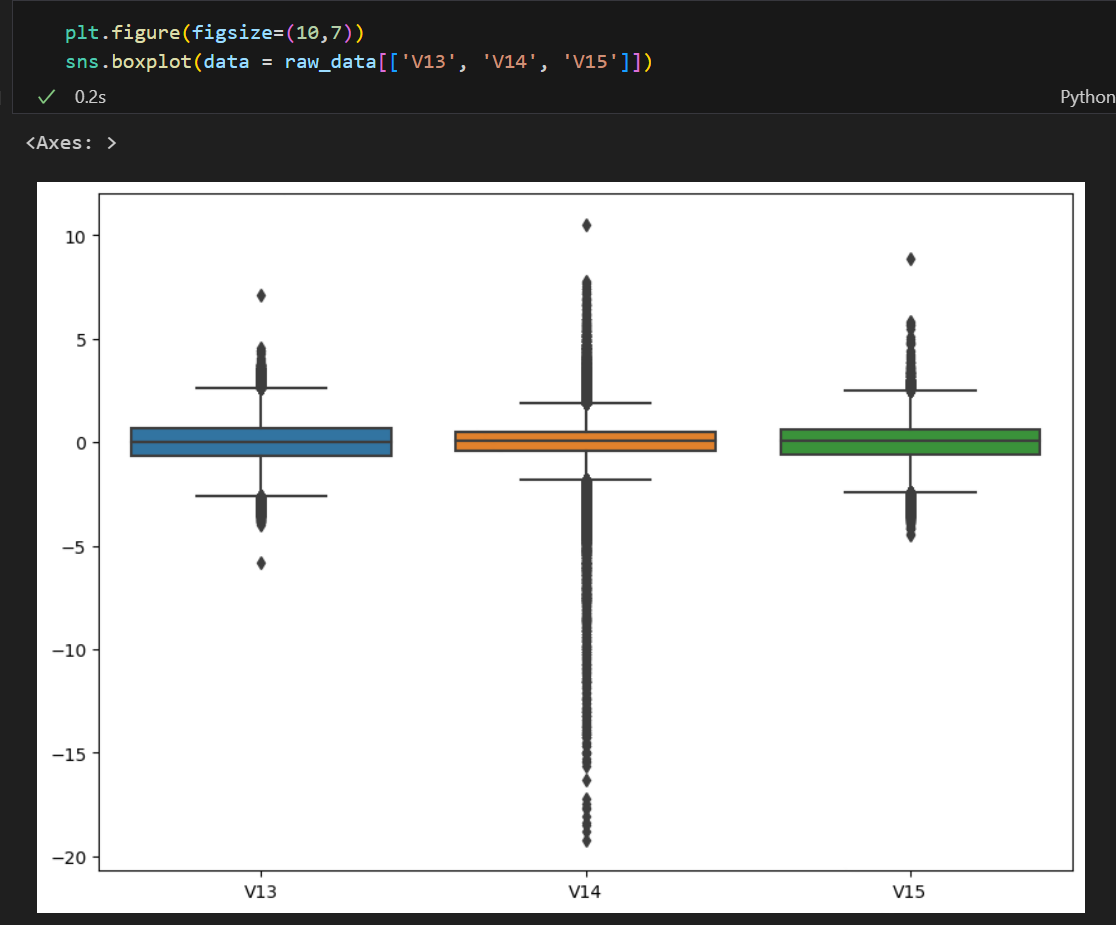
위 세 컬럼들을 보았을 때 박스 플럿의 꼬리에서 벗어난 이상치들이 많은 것 같다.
1(Fraud)들이 가지고 있는 데이터 중 이상치들이 있는 데이터는 삭제하고 다시 모델들을 돌려보자.
📌 boxplot의 IQR을 이용한 이상치들의 인덱스를 반환하는 함수
def get_outlier(df = None, column = None, weight = 1.5):
fraud = df[df['Class'] == 1][column] # fraud 데이터에 대해서만 이상치를 찾아볼 예정
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_indexoutlier_index = get_outlier(df = raw_data, column= 'V14', weight = 1.5)
raw_data_copy.drop(outlier_index, axis = 0, inplace = True)
# 이상치를 삭제하기 위함 -> 이후 y만 추출
raw_data.drop(outlier_index, axis = 0, inplace = True)
X = raw_data_copy
y = raw_data.iloc[:, -1] # 이상치를 제거한 y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
stratify=y,
random_state=13)위 함수를 이용해 이상치들을 제거하고 데이터를 다시 분리시킨 후, 모델들을 돌려본 결과는 아래와 같다.
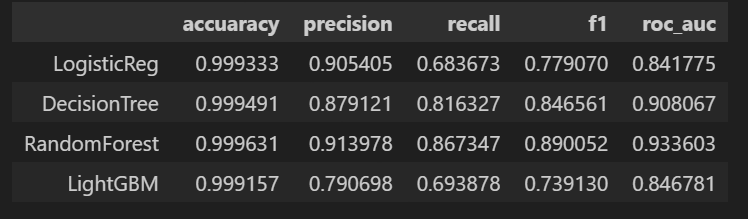
사알짝 좋아진 것 같지만 아직 아쉽긴 하다. 무엇을 더 할 수 있을까?
네번째 시도 - 데이터 불균형 해소
우리가 가지고 있는 데이터는 불균형이 심한 상태였다.
두 클래스의 분포를 강제로 맞춰보는 작업을 해보자.
클래스의 분포를 맞추는 방법에도 여러가지가 있는데, 먼저 언더샘플링과 오버샘플링이 있다.
-
언더 샘플링 : 많은 수의 데이터를 적은 수의 데이터로 조정
-
오버 샘플링 : 적은 수의 데이터를 많은 수의 데이터로 조정
-
대표적으로
SMOTE방식이 있는데imblanced-learn이라는 파이썬 패키지를 이용하면 됨. -
!pip install imbalanced-learn -
SMOTE
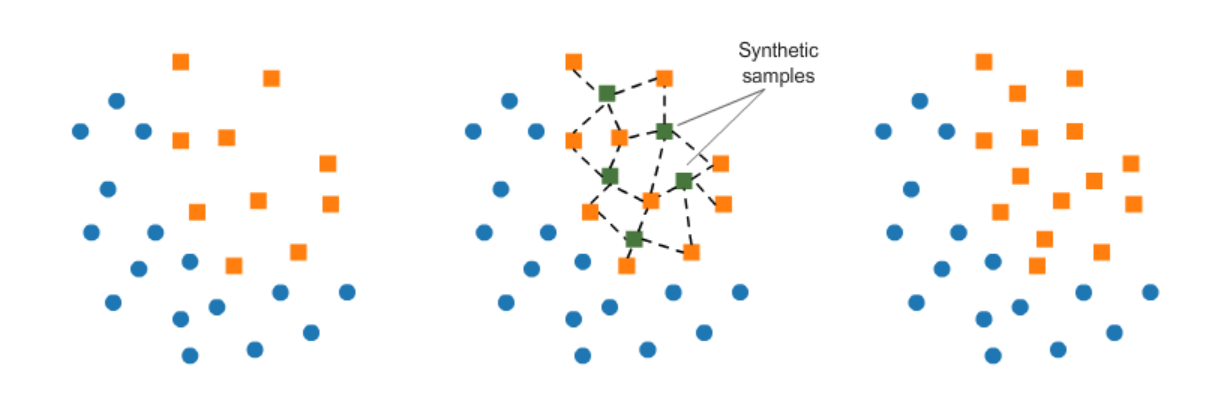
: 간단히 말하면 적은 데이터 세트에 있는 개별 데이터를 KNN으로 찾아서 데이터의 분포 사이에 새로운 데이터를 만드는 방식.
-
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=13)
X_train_over, y_train_over = smote.fit_resample(X_train,y_train)Train 데이터 셋을 SMOTE를 이용해 resample한 데이터를 X_train_over, y_train_over에 넣어주었다.
이때, 데이터를 조작하는 것은 Train 데이터에 한해서라는 것을 주의해야한다. Test 데이터는 왜곡되면 안되기 때문에 어떠한 작업도 하지 않고 그냥 모델에 적용!만 할 것.
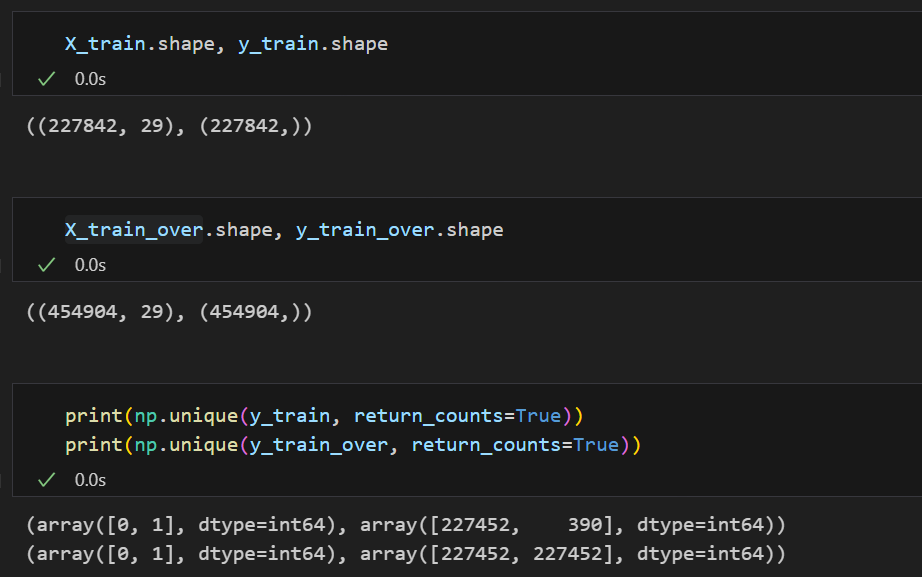
SMOTE작업을 통해 클래스의 분포가 같아졌다.
이를 모델들에 돌려본 결과는 아래와 같다.
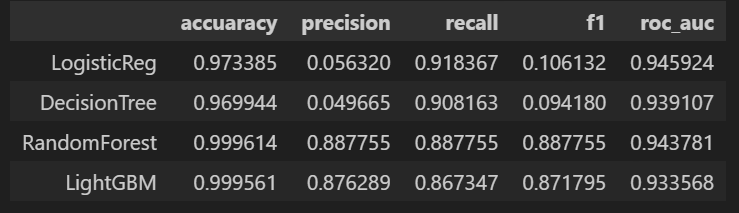 | 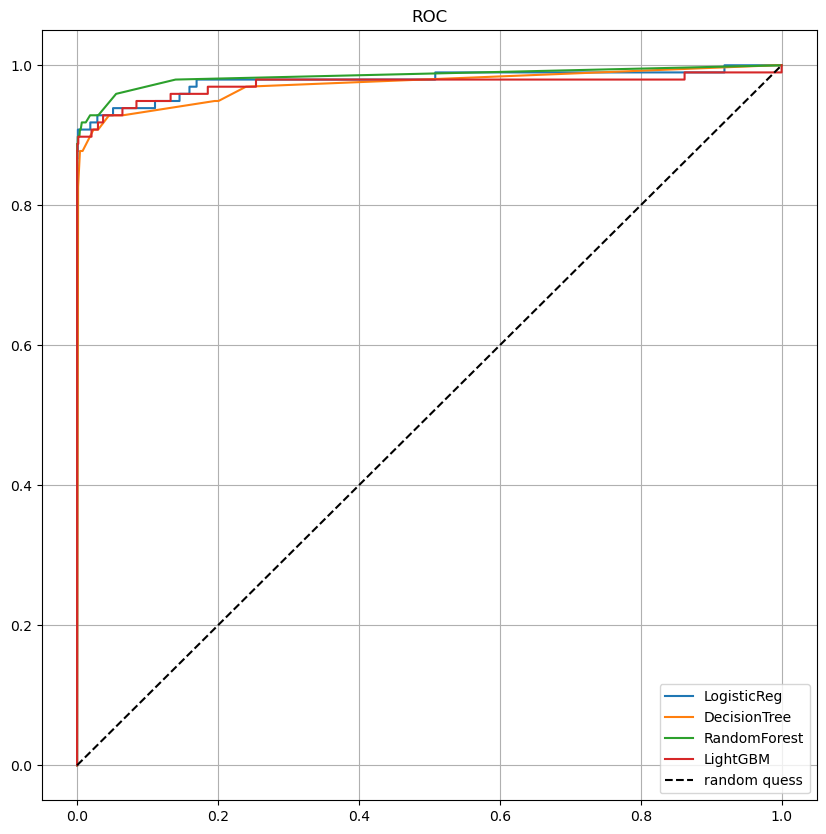 |
|---|
우오옹!! 모든 모델들에 대해 성능이 향상된 것 같다 😆
비록 Precision이 떨어진 것도 보이지만, 무엇을 선택할 건지는 데이터 분석가의 몫 ㅎㅎ
우리가 배운 것들을 적용시켜보는 실습은 이정도에서 마무리하도록 하겠다.
NLP(Natural Language Processing, 자연어 처리)
환경 만들기
!pip install konlpy
!pip install tweepy==3.10.0
!conda install -y -c conda-forge jpype1==1.0.2
!conda install -y -c conda-forge wordcloud
!conda install -y nltkcmd창 또는 JupyterNotebook, VSCode 등 자신이 사용하고 있는 프로그램에 위 패키지들을 설치시켜주어야한다.
import nltk
nltk.download()또한 위 코드를 실행시키면 아래와 같은 창이 하나 뜨는데
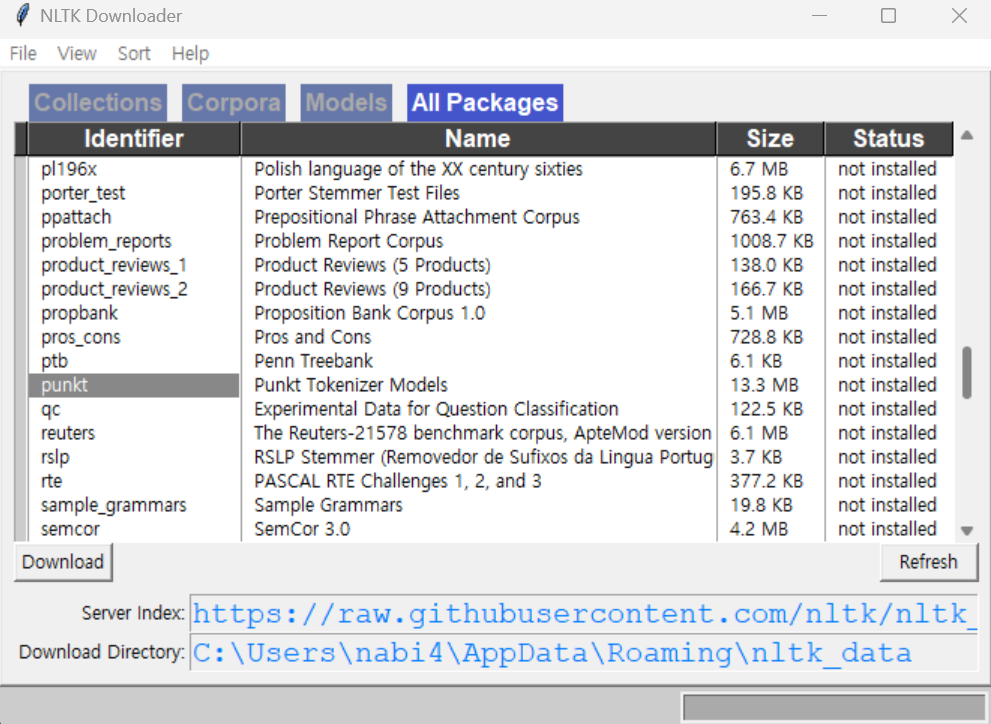
[All Package] 를 누르고 Identifier 중에서 punkt와 stopwords를 다운로드 해주면 된다.
그리고 X표를 눌러 빠져나온다.
from konlpy.tag import Okt
t = Okt()위 코드가 정상 실행되면 환경 세팅은 끝났다 :)
미리보기
자연어처리에서 사용할 수 있는 형태소 분석기에는 여러 종류가 있는 것 같다.
그 중 Kkma, Hannanum, Okt만 가볍게 살펴보자.
순서는 동일하게 분석기 호출 -> 문장 입력 으로 이루어진 것 같다.
그리고 함수는 아래와 같다.
pos: 형태소와 품사 반환nouns: 명사 반환morphs: 형태소 반환
이때 형태소(morpheme)는 의미를 가지는 가장 작은 단위로, '되었습니다.' 라는 어절(띄어쓰기 되는 단위)도 '되(동사)', '었(시제 어미)', '습니다(종결 어미)', '.' 로 형태소가 구분된다.
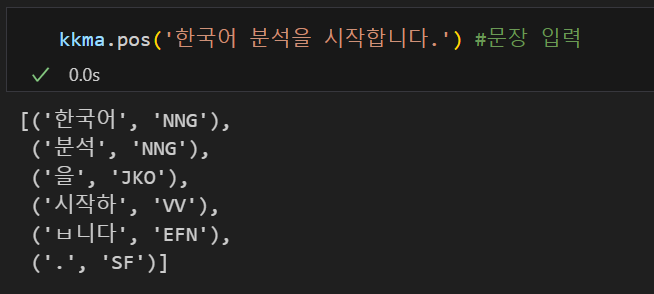
from konlpy.tag import Kkma
kkma = Kkma() # 분석기 호출
kkma.pos('한국어 분석을 시작합니다.') #문장 입력💻 출력
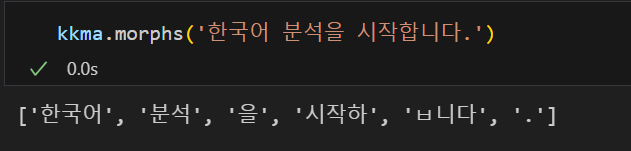
kkma.morphs('한국어 분석을 시작합니다.')💻 출력
위와 같이 다른 분석기들도 동일한 결과를 출력해준다.
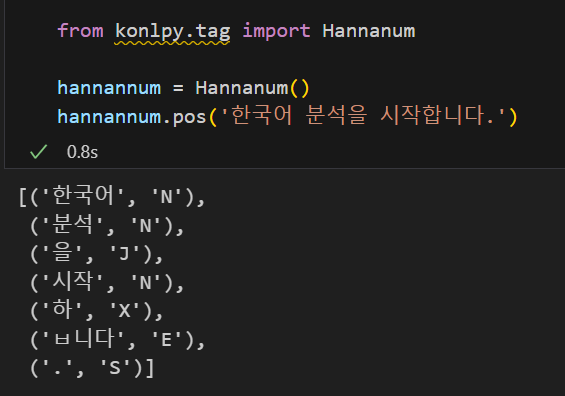 Hannanum Hannanum | 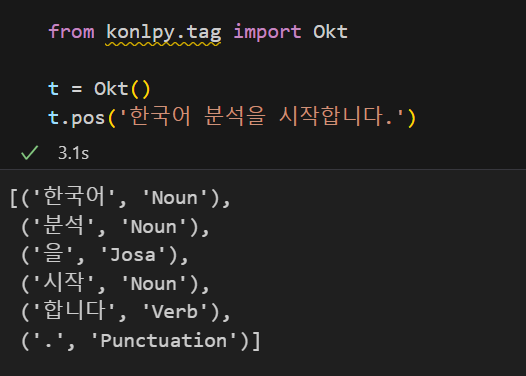 Okt Okt |
|---|
워드클라우드
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Image워드클라우드에 대해 간단하게 살펴보자.

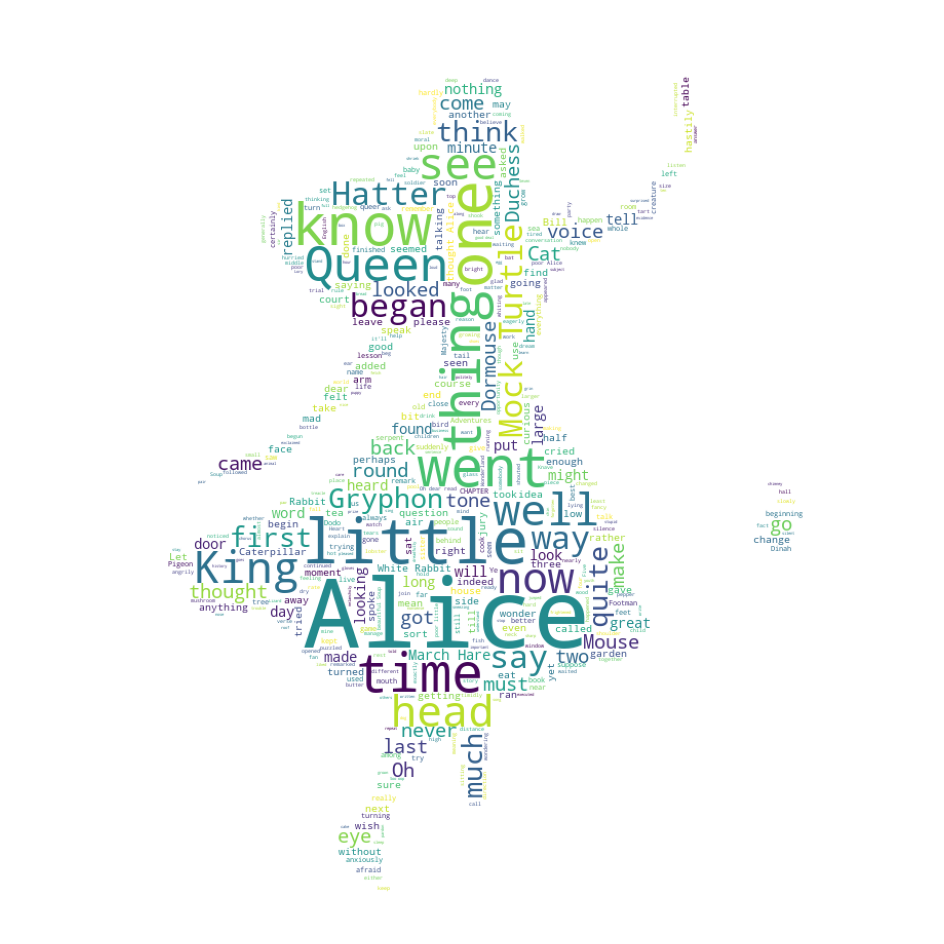
워드클라우드는 위와 같이 텍스트에서 단어의 빈도수에 따라 해당 단어를 크게 표시해놓은 그림이다.
한 번, 앨리스 동화책 이야기를 앨리스 그림 위에 워드클라우드를 그려보자.
https://github.com/PinkWink/ML_tutorial/tree/master/nltk_dataset
위 링크에서 alice.txt와 alice_mask.png를 다운받아 사용했다.
다운받은 데이터 확인하기.
- 텍스트
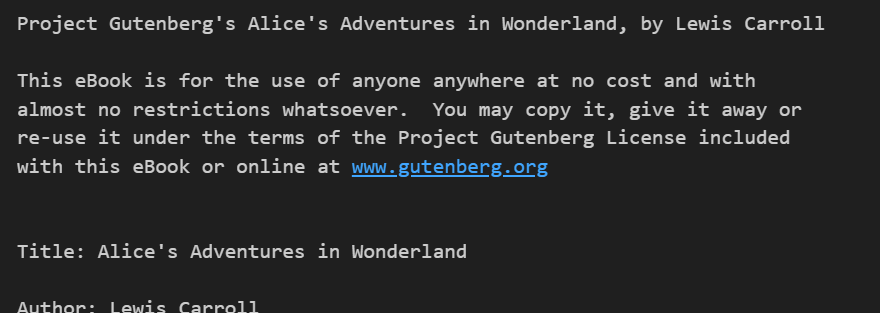
text = open('./data/06_alice.txt').read()
print(text)💻 출력
- 이미지
alice_mask = np.array(Image.open('./data/06_alice_mask.png'))파이썬에서 이미지를 읽을 때는 여러 방법이 있지만 픽셀값으로 변환시킨 numpy array를 matplotlib을 통해 그리는 방법이 있다. 위 코드가 픽셀 값으로 변환시킨 과정이고
import matplotlib.pyplot as plt
plt.figure(figsize = (8,8))
plt.imshow(alice_mask, cmap = plt.cm.gray)💻 출력
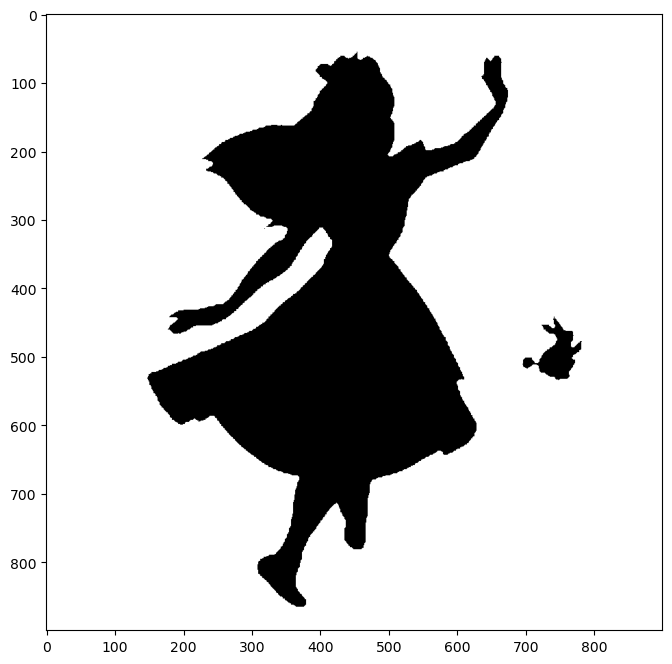
위 코드를 통해 확인할 수 있다.
워드클라우드를 하기 전, 큰 의미가 없는 단어들은 제외하고 그림을 그릴 필요가 있다.
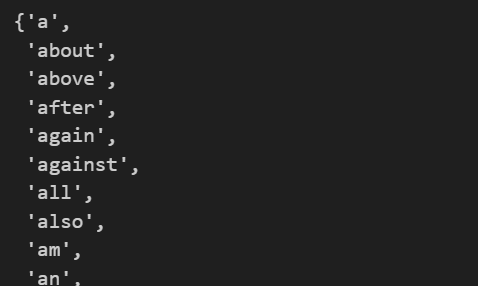
큰 의미가 없는 단어 토큰들이 모아져있는 것이 바로 아까 다운받은 STOPWORDS이다.
stopwords = set(STOPWORDS)
stopwords💻 출력
그리고 어떤 단어를 더 추가하고 싶다면 아래와 같이 하면 된다.
stopwords.add('said') alice.txt에는 'said'라는 단어도 많이 나오는데, 큰 의미가 없어 이 또한 포함시켜주었다.
이제 WordCloud를 이용하여 alice.txt의 단어 빈도수를 출력해보자.
wc = WordCloud(
background_color='white', # 배경색
max_words= 2000, # 최대 단어 수
mask=alice_mask, # 바탕 배경 지정
stopwords=stopwords # 불필요한 단어
)
wc = wc.generate(text)
wc.words_ # 각 단어들의 발생빈도를 반환해줌💻 출력
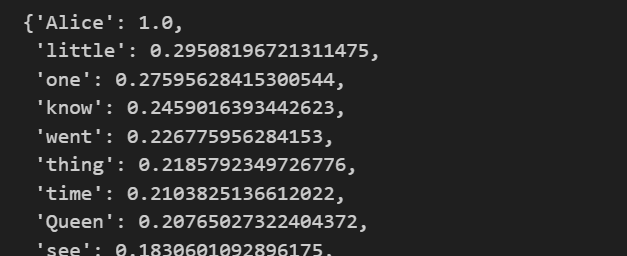
그리고 이를 그림으로 그리면 아래와 같다.
plt.figure(figsize = (12,12))
plt.imshow(wc)
plt.axis('off')
plt.show()💻 출력