
✍🏻 25일 공부 이야기.
👀 오늘 공부한 내용의 실습 코드는 아래 사진을 클릭하면 보실 수 있습니다:)

Logistic Regression
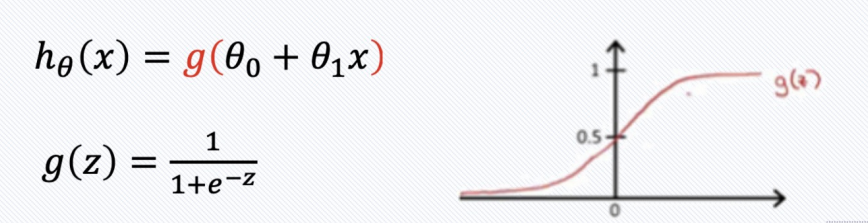
Logistic Regression 은 위와 같이 0과 1을 잘 분류해준다는 특성때문에 분류 문제에서 많이 사용된다.
추가로, 함수는 시그모이드 함수이다.
덧붙여 Decision Boundary와 Cost Function에 대한 개념 소개를 더 하자면
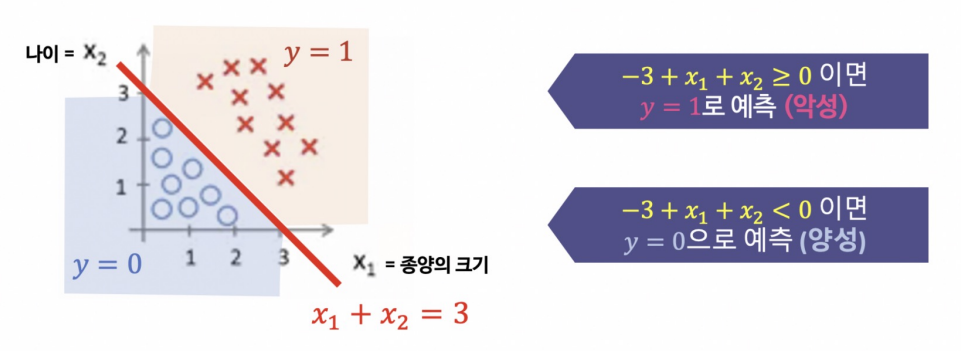 | 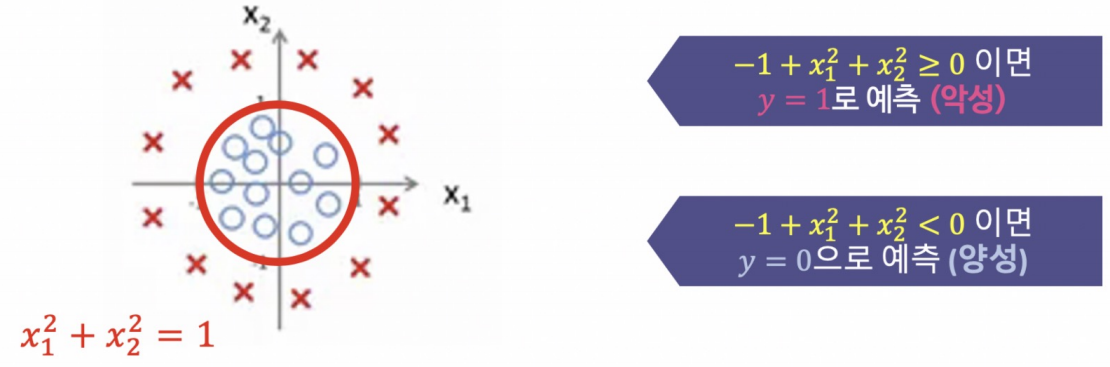 |
|---|
위와 같이 클래스가 바뀌는 지점을 Decision Boundary라고 한다.
그리고 지난 시간에 정리했던 Cost Function은 MSE를 사용했기 때문에 2차식이 나와(convex 형태) 위로 볼록하거나 아래로 볼록한 단일 형태의 그래프가 나왔지만, Logistic Regression에서는 아래와 같은 Cost Function을 사용하기 때문에 non-convex한 형태가 나올 수도 있지만 가 취해진 덕분에 미분 후 최소값을 찾는 과정은 우리가 알고있는대로 쉽게 구할 수 있을 것이다.
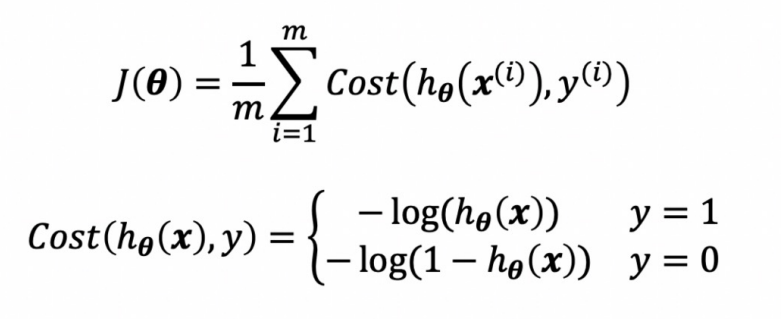
와인 데이터
그러면 앞서 실습했던 와인 데이터를 이용해 Logistic Regression도 실습해보자.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y , test_size= 0.2, random_state=13)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver= 'liblinear' , random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print("Train acc : ", accuracy_score(y_train, y_pred_tr))
print("Test acc : ", accuracy_score(y_test, y_pred_test))💻 출력
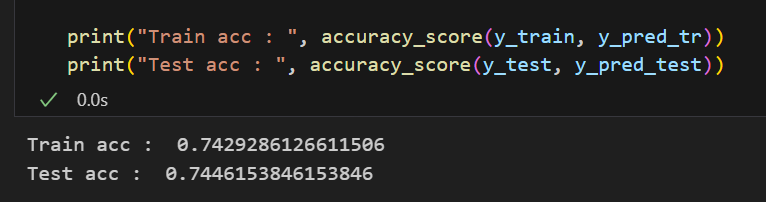
Logistic Regression의 옵션 중 solver가 있는데 이는 최적화할 때 어떤 알고리즘으로 할 것인가에 대한 사항이다. 보통 liblinear는 데이터가 작고 일대일 방식의 데이터에 많이 사용되며 sag나 saga는 데이터가 크고 다중 클래스 문제에 많이 사용된다고 한다. (다중 클래스 문제에는 newton-cg와 lbfgs도 있다.)
만약 파이프라인을 구축해본다고 하면 아래와 같이 할 수 있다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', LogisticRegression(solver='liblinear', random_state=13))
]
pipe = Pipeline(estimators)
pipe.fit(X_train, y_train)
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
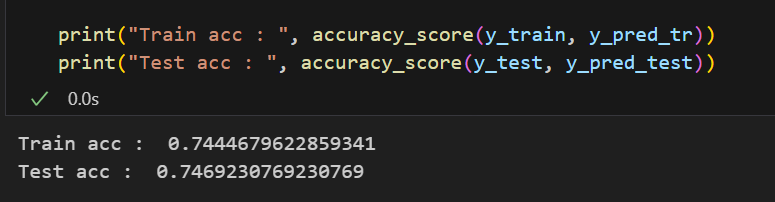
print("Train acc : ", accuracy_score(y_train, y_pred_tr))
print("Test acc : ", accuracy_score(y_test, y_pred_test))💻 출력
이전 시간에 분류 문제로 실습했던 Decision Tree와 함께 roc-curve를 그려 비교해보자.
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
models = {
'logistic regression' : pipe,
'decision tree' : wine_tree
}Decision Tree도 fit시켜주고 models 에 두 모델을 저장해주면

위와 같이 .items()를 호출해 각 모델을 부를 수 있다.
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
plt.figure(figsize = (10,8))
plt.plot([0,1], [0,1], label = 'random_guess')
for model_name, model in models.items():
pred = model.predict_proba(X_test)[:, 1] # 첫번째 컬럼은 0일 확률이므로 1일 확률인 두번째 컬럼을 추출해야함
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label = model_name)
plt.grid()
plt.legend()
plt.show()💻 출력
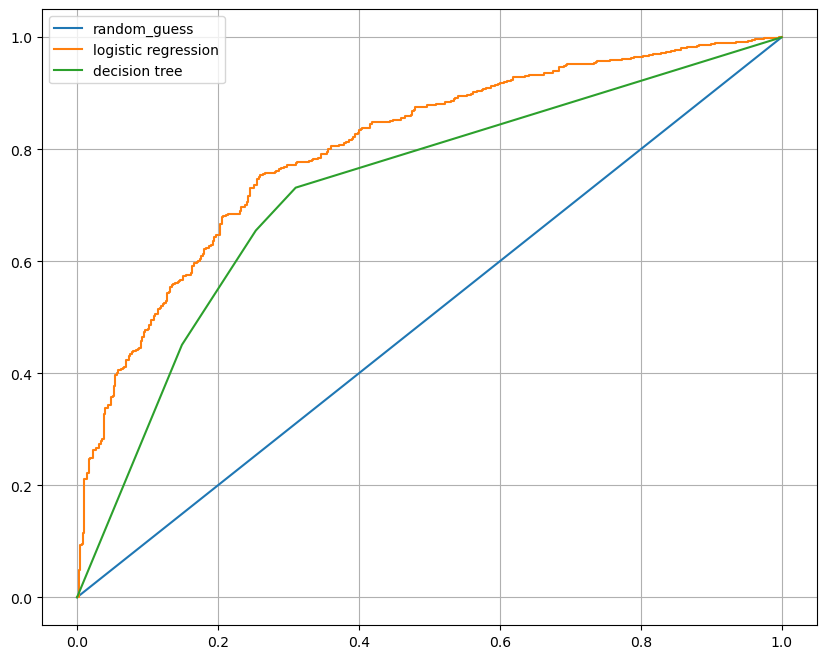
이를 이용해 for문으로 각 모델의 fpr, tpr을 그려보면 위와 같이 출력되는데 물론 이번 한 번의 과정을 통해 Logistic Regression 성능이 더 뛰어나다고는 할 순 없지만 지금 이 데이터에서는 Decision Tree보단 Logisic Regression의 성능이 더 좋아보인다.
PIMA 인디언 당뇨병 예측

50년대 까지 PIMA 인디언들은 당뇨가 없었는데 20세기 말 갑자기 인구의 50%가 당뇨에 걸리게 되면서 데이터 분석에 흥미로운 주제 중 하나로 꼽히게 되었다.
본 데이터는 캐글에 있으며 컬럼별 설명은 위 사진과 같다.
 | 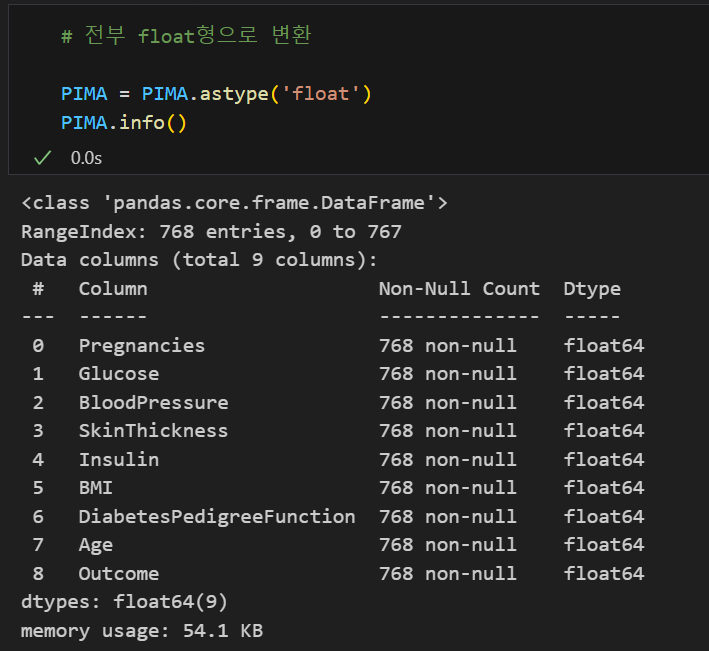 |
|---|
많은 작업을 하면서 int형을 자동으로 float형으로 변환하여 작업해주는 것들도 있지만 혹시 모르기 때문에 모두 다 float형으로 바꾼 후 작업했다.
이번 실습을 하면서 관심있게 봐주었으면 하는 부분은 바로 결측치 처리 파트이다.
결측치를 찾아줘!
앞서 info()를 통해 본 것으로는 결측치가 없어보였다. 하지만 아래 코드를 보자.
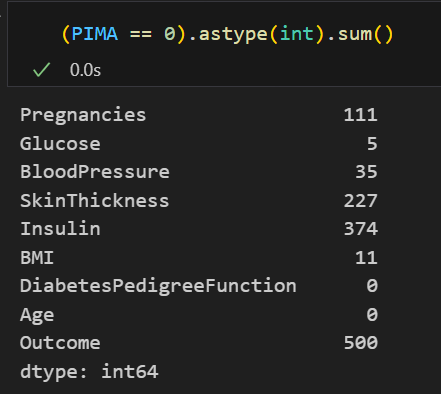
다른 컬럼들은 값이 0일 수도 있다고 생각이 들지만,
Glucose(포도당 부하 검사 수치), BloodPressure(혈압), SkinThickness(팔 삼두근 뒤쪽의 피하지방 측정값), BMI(체질량지수) 컬럼들이 0인 것은 뭔가 좀 이상하다!
바로 결측값인 것이다.
결측치는 데이터를 수집하고 가공한 사람에 따라 정의를 다르게 한다. Nan, Null, 0, - 등 여러가지가 있다. 그러므로 우리는 마냥 null이 있냐 없냐만 보고 넘어갈 것이 아닌 보다 꼼꼼하게 결측치를 확인할 줄 알아야한다.
그리고 이 결측치들을 어떻게 처리할 것인가도 고민해보아야 한다.
그냥 해당 데이터를 삭제할 것인지, 아니면 결측치를 이전 데이터의 값으로 대체할 것인지, 아니면 평균값/중앙값 등으로 대체할 것인지...
데이터가 어떤 성향을 가졌는지 보고 전문가의 조언을 받아도 되고 여러 시도를 해보며 어떤 방향으로 접근했을 때 성능이 좋게 나오는지 확인 해보아도 된다.
zero_features = ['Glucose', 'BloodPressure', 'SkinThickness', 'BMI']
PIMA[zero_features] = PIMA[zero_features].replace(0, PIMA[zero_features].mean())지금은 그냥 <평균값>으로 결측치를 대체하고 실습을 진행해보겠다.
모델링
# 데이터 분리
from sklearn.model_selection import train_test_split
X = PIMA.drop(['Outcome'], axis = 1)
y = PIMA['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y , test_size= 0.2,
stratify=y,
random_state=13)
# 모델링 from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
estimators = [
('scaler', StandardScaler()),
('clf', LogisticRegression(solver='liblinear', random_state=13))
]
pipe_lr = Pipeline(estimators)
pipe_lr.fit(X_train, y_train)
pred = pipe_lr.predict(X_test)
# 성능 평가
from sklearn.metrics import accuracy_score, recall_score, precision_score
from sklearn.metrics import roc_auc_score, f1_score
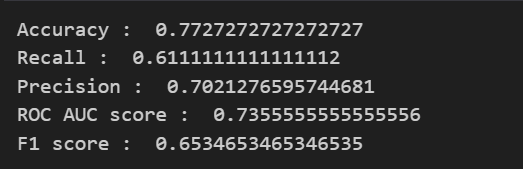
print('Accuracy : ', accuracy_score(y_test, pred))
print('Recall : ', recall_score(y_test, pred))
print('Precision : ', precision_score(y_test, pred))
print('ROC AUC score : ', roc_auc_score(y_test, pred))
print('F1 score : ', f1_score(y_test, pred))💻 출력
이제는 위 과정이 좀 익숙해졌을 것이다.
그럼 더 나아가 이것도 확인해보자.
Feature importances
각 모델의 성능을 평가하고, 쓰인 Feature들의 중요도를 추출하여 다음 모델은 어떻게 시도해볼 것인가에 대해 고민할 수 있다.
tree모델들 같은 경우, .feature_importances_ 를 호출하여 각 Feature들의 중요도를 확인할 수 있는데 Logistic Regression에서 이를 사용하려고 하면
AttributeError: 'LogisticRegression' object has no attribute 'featureimportances'
위와 같은 에러 문구를 볼 수 있을 것이다.
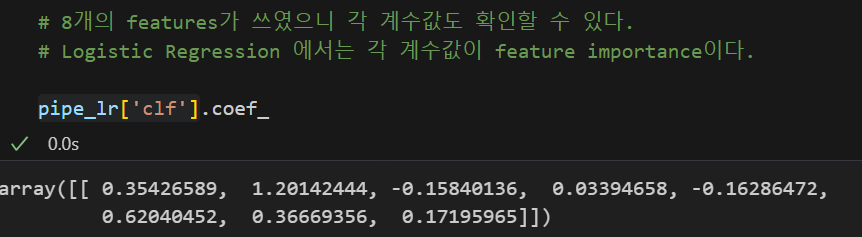
Logistic Regression에서는 하나의 방정식을 만들어주므로 각 Feature들의 계수값이 곧 중요도가 된다.
계수값은 .coef_를 통해 확인할 수 있다.
features['importance'].plot(kind = 'barh',
figsize = (11,6),
color = features['positive'].map({True : 'blue', False : "red"}))
plt.xlabel('importance')
plt.show()💻 출력
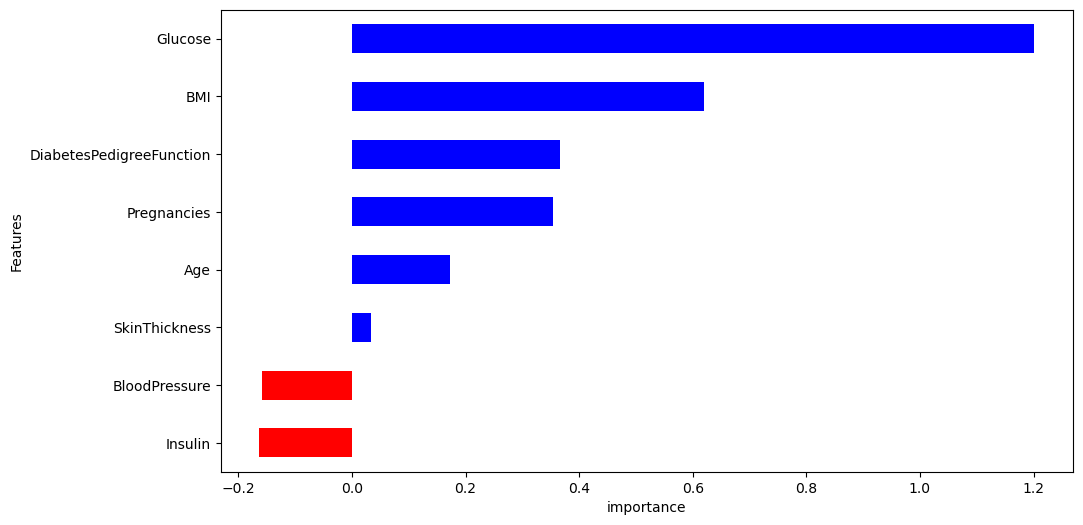
그리고 중요도를 시각화하여 보기 쉽게 정리하면 PIMA 인디언들의 당뇨를 예측하는데에 Glucose(포도당 부하 검사 수치)와 BMI 컬럼이 중요한 작용을 했다는 것을 확인할 수 있다.
Recall 과 Precision
모델을 평가하는 방법으로 Recall과 Precision이 있다. 이 둘은 반대 성향을 가지고 있는데 둘 다 성능이 좋아지는 방법이 있긴 하다.
바로 threshold를 조정하는 것이다.
하지만 이를 조정하여 Recall과 Precision이 좋아지도록 모델을 만드는 방법을 추천하지는 않는다.
왜냐하면 해당 성능이 나의 데이터에 한정적일 수도 있고 극단적인 threshold가 더 악영향을 가져올 수 있기 때문이다.
하지만 어떻게 작용될 수 있는지는 살펴보도록 하자.
Binarizer
앞서 accuracy_score, recall_score, precision_score를 호출하여 일일이 print해서 살펴본 것과 다르게 classification_report(실제값, 예측값)을 이용하면 좀 더 쉽게 해당 값들을 살펴볼 수 있다.
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test)))💻 출력
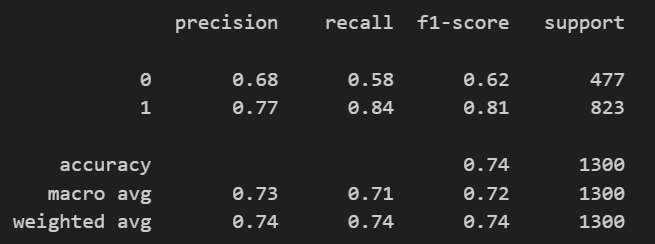
표로 아주 깔끔하게 정리하여 출력해주기도 하고
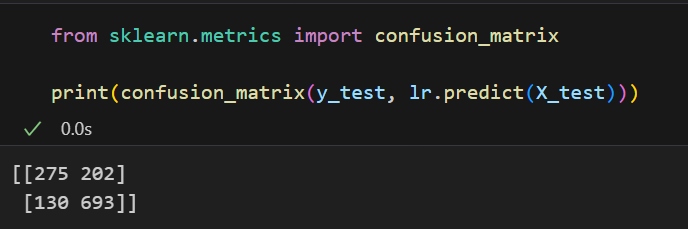
confusion_matrix를 이용하면 아래와 같이 출력해준다.
 |  |
|---|
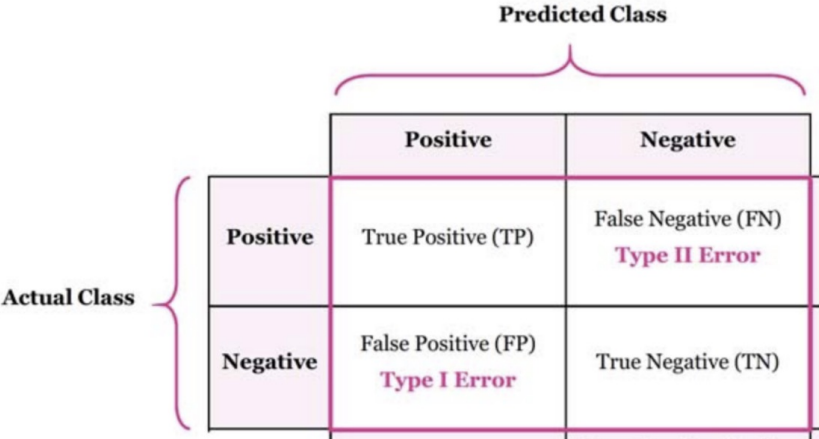
오른쪽 표에 해당하는 개수를 표로 표현해주는 것을 볼 수 있다.
우리는 지금 threshold가 변함에 따라 precision과 recall이 어떻게 변하는가를 알아봐야한다.
이를 시각화를 통해 한 눈에 파악하려면 아래와 같이 하면 된다.
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(11,6))
pred = lr.predict_proba(X_test)[:,1] # 클래스가 1이 될 확률만 추출
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precisions[:len(thresholds)], label = 'precision')
plt.plot(thresholds, recalls[:len(thresholds)], label = 'recall')
plt.grid()
plt.legend()
plt.show()💻 출력
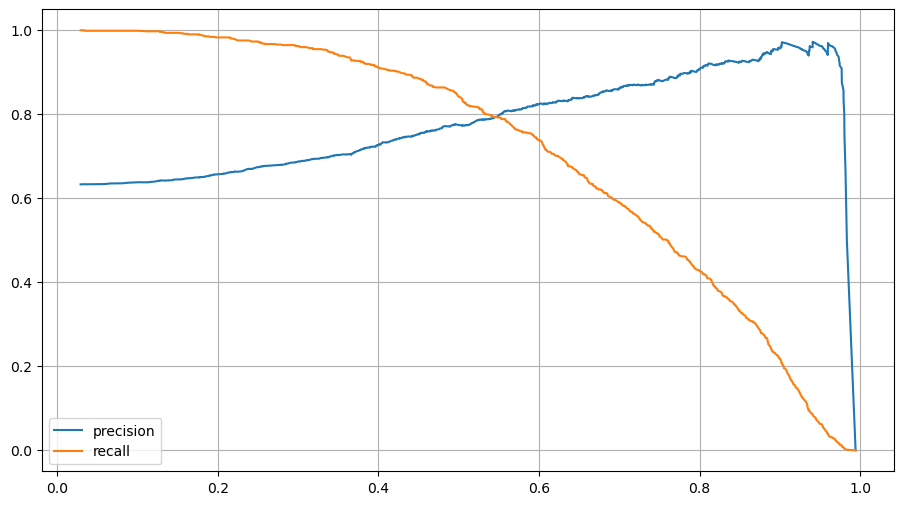
두 지표는 서로 반대 성향이기 때문에 반대의 그래프를 가지고 있는 것을 볼 수 있다.
우리는 그동안 threshold가 0.5인 것을 기준으로 성능을 평가해왔었는데 그러면 threshold는 어떻게 바꿀 수 있는 것일까?
Binarizer(threshold = 원하는 값).fit()$
을 이용하면 된다. Binarizer는 이항변수화 변환에 쓰이는 라이브러리로 연속형 변수를 특정 값 기준 이하는 0, 초과는 1로 표현할 수 있게 해주는 도구이다.
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:,1] # 클래스가 1일 때를 기준으로 0,1이 표현되는 열 추출
print(classification_report(y_test,pred_bin))💻 출력
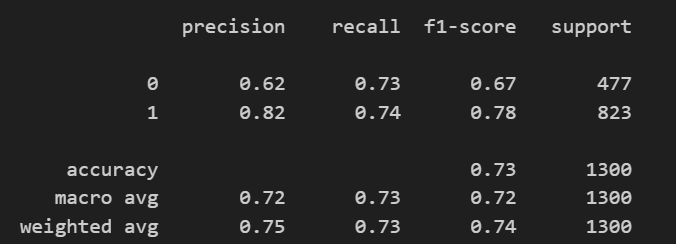
threshold가 0.6일 때의 classification_report도 확인해볼 수 있다.
앙상블 기법
앙상블 기법이란, 여러 개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법을 말한다.
다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것을 기대할 수 있다.
앙상블 기법에는 여러 방법이 있다.
Voting
Voting 기법이란, 여러 개의 분류기에서 예측한 값들을 투표를 통해 최종 예측값으로 선택하는 것을 말한다.
여기서 여러 개의 분류기를 사용했다는 점이 포인트이다. 이것이 앙상블 기법으로서의 Voting이고
최종 결정 단계에서의 Voting도 있다.
Bagging
Bagging기법은 보통 하나의 분류기를 사용하는데, 전체 데이터 셋을 중복을 허용하여 여러 샘플링으로 나누고 각각의 데이터에서 나온 결과를 투표를 통해 최종 예측값으로 선택하는 것을 말한다.
이때 데이터를 각각 샘플링해서 추출하는 방식을 부트스트래핑(bootstrapping) 분할 방식이라 한다.
Bagging기법의 대표적인 모델로 Random Forest가 있다.
Random Forest
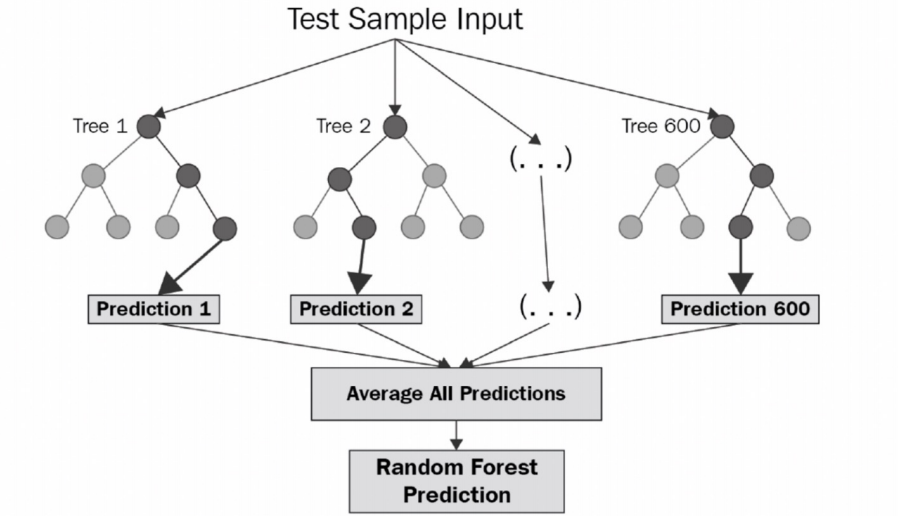
Random Forest는 Decision Tree를 여러번 반복하여 최종 결정을 하는 모델로 앙상블 기법 중 비교적 속도가 빠르며 다양한 영역에서 높은 성능을 보여주고 있다.
부트스트래핑으로 샘플링된 데이터마다 Decision Tree가 예측한 결과를 소프트 보팅 방식으로 최종 예측 결론을 얻는다.
그렇다면 결정 단계에서의 Voting은 무엇일까?
결정 단계의 Voting
하나의 데이터셋으로 여러 개의 분류기를 사용하든, 데이터셋을 여러 개로 나눈 후 하나의 분류기를 사용하든 우리에겐 많은 답안이 주어질 것이다. 이 때 많은 답들 중 다수결을 통해 최종 예측값을 선택하는 과정을 결정 단계의 Voting이라 한다.
Voting에는 하드 보팅과 소프트 보팅으로 나뉘는데,
1. 하드 보팅(Hard Voting)
하드 보팅은 분류기에서 1, 1, 0, 1이라는 답변이 나왔을 때 1을 선택하는 방식이다.
2. 소프트 보팅(Soft Voting)
소프트 보팅은 분류기에서 1, 1, 0, 1이라는 답변을 냈지만 각각의 클래스로 예측을 하게된 확률값이 있을 것이다. 이 확률값을 통해 최종 예측값을 선택하는 것이 소프트 보팅의 방식이다.
예를 들어, 각각의 클래스로 예측하게 된 확률이 다음과 같다고 하자.
1(0.9) , 1(0.8), 0(0.8), 1(0.4)
이때 1이 될 확률은 각 예측값들의 평균을 낸 0.7(= (0.9+0.8+0.4)/3)이 될 것이고 0은 그대로 0.8일 것이다. 그러면 0이라고 택한 클래스의 확률이 더 높으므로 0을 최종 예측값으로 선택하는 방식이 소프트 보팅이다.
HAR(Human Activity Recognition)

HAR 데이터를 이용해 앙상블 기법을 실습해보자.
이 데이터는 사람의 몸에 디바이스를 부착하여 사람의 행동을 인지하기 위해 수집된 데이터이다.
실제 데이터는 위 사이트에서 다운받을 수 있는데 PinkWink에 다운받아진 데이터를 이용해 실습해보도록 하자.
HAR 데이터는 feature들의 이름이 저장된 데이터와 실제 데이터가 있는 데이터 2종류로 구분되어 있다. 따라서 각각을 읽어들이고 데이터프레임의 컬럼 이름을 바꿔주는 작업을 해주어야한다.
📌 feature 이름이 저장된 데이터
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
# \s+ : 공백 문자(스페이스, 탭, 개행 등)
feature_name_df = pd.read_csv(url, sep = '\s+', header = None,
names = ['column_index', 'column_name'])
feature_name = feature_name_df.iloc[:,1].values.tolist() # 리스트 형태로 바꿔줌📌 X_train, X_test가 저장된 데이터
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep = '\s+', header = None)
X_test = pd.read_csv(X_test_url, sep = '\s+', header = None)
# 컬럼 이름 변경
X_train.columns = feature_name
X_test.columns = feature_name
## 똑같이 y_train, y_test도 읽어들이면 된다. column name은 'action'데이터를 읽어들였다면 총 4가지 작업을 해보자.
- Decision Tree
- Grid Search CV를 적용한 Decision Tree
- Grid Search CV를 적용한 Random Forest
- 중요 feature들만 골라 예측한 Random Forest
1. Decision Tree
앞서 많이 했듯이 기본 옵션만 설정해두고 구해본 accuracy_score이다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy_score(y_test, pred)💻 출력
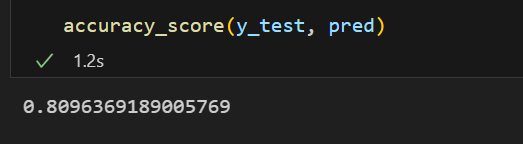
2. Grid Search CV를 적용한 Decision Tree
일단 max_depth만 여러 숫자로 돌려보자.
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6,8,10,12,16,20,24]
}
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring = 'accuracy',
cv = 5, return_train_score=True)
grid_cv.fit(X_train, y_train) # X_train에 대해 5등분한 교차검증 실행GridSearchCV를 한 결과는 아래와 같은 함수를 호출하여 확인할 수 있다.
grid_cv.best_scores_: 검증 데이터에 대한 best scoregrid_cv.best_params_: 베스트 파라미터grid_cv.cv_results_: 보다 다양한 데이터 확인 가능
grid_cv.cv_results_를 통해 확인된 결과값들 중 원하는 결과값만 뽑아서 확인할 수도 있다.
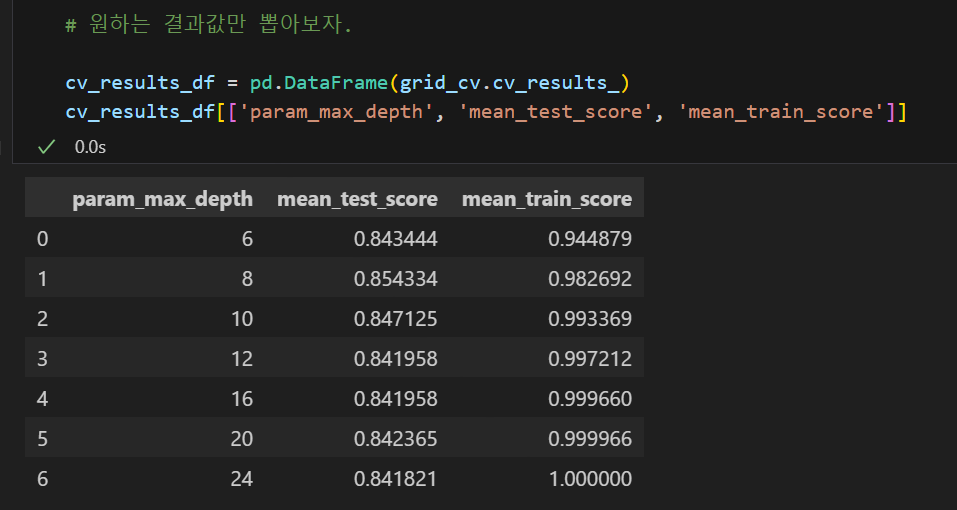
위 결과에서 보여지는 test는 실제론 X_train에서 교차검증한 validation set에 대한 스코어이다. train 데이터에 대한 스코어는 높은데 validation 데이터에 대한 스코어는 그보다는 낮아 혹시 과적합이 걱정된다면 실제 X_test에 대한 스코어도 확인해보면 된다.
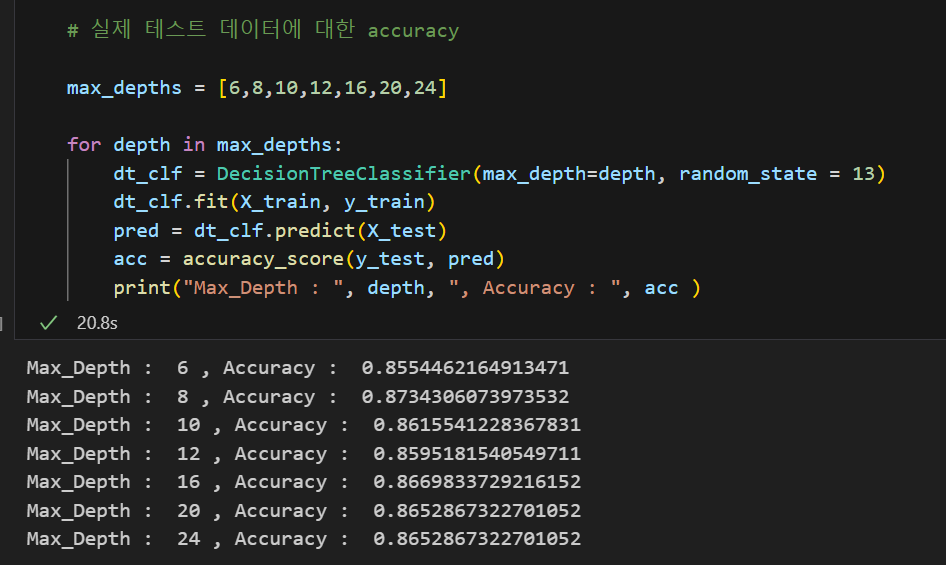
X_test에 대한 스코어도 max_depth가 8일 때 가장 높은 것을 볼 수 있다.
따라서 우리의 베스트 모델은 아래와 같다.
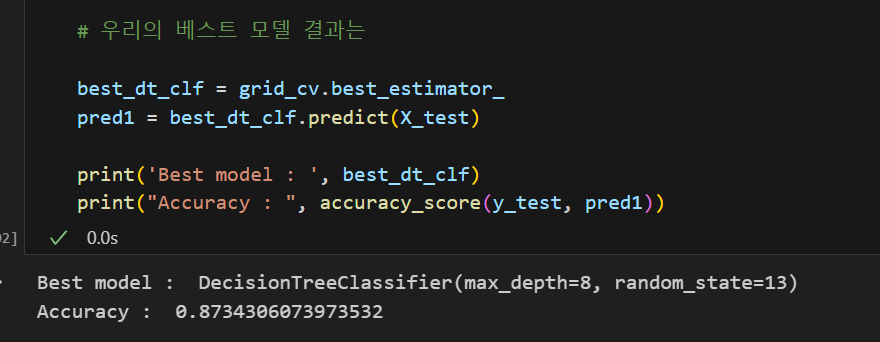
3. Grid Search CV를 적용한 Random Forest
그렇다면 Decision Tree를 여러 번 돌린 Random Forest도 한 번 돌려보자.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6,8,10],
'n_estimators' : [50,100,200], # Decision Tree 분류기 개수
'min_samples_leaf' : [8,12], # 마지막 가지에 남아있는 최소 데이터 개수
'min_samples_split' : [8,12] # 노드 당 최소 데이터 개수
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs = -1)
# n_jobs = -1 : CPU를 다 써서 학습을 시켜라
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv = 2, n_jobs= -1)
grid_cv.fit(X_train, y_train)cv_results_df = pd.DataFrame(grid_cv.cv_results_)
target_col = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_col].sort_values('rank_test_score').head()💻 출력
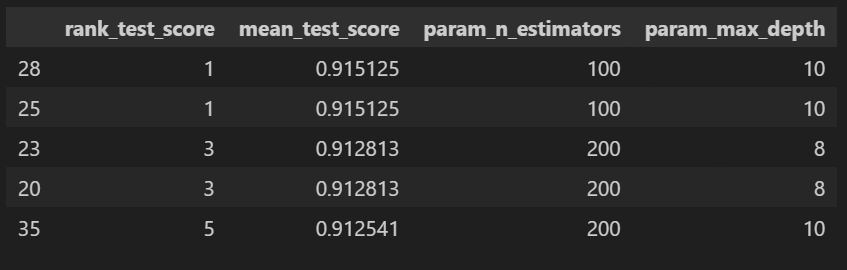
위와 같이 표를 통해 확인할 수도 있고 grid_cv.best_params_를 통해 베스트 파라미터를 확인할 수도 있다.
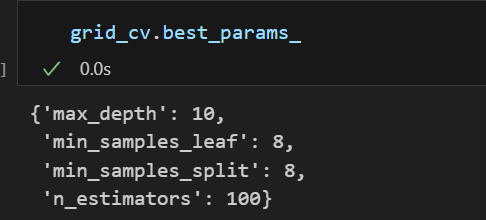
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(X_train, y_train)
pred1 = rf_clf_best.predict(X_test)
accuracy_score(y_test, pred1)💻 출력
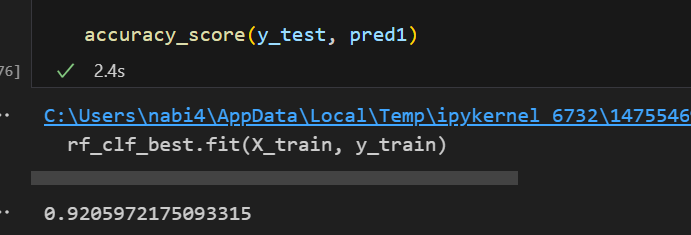
Random Forest에 GridSearchCV까지 했더니 모델 성능이 많이 향상된 것을 볼 수 있다!!
4. 중요 feature들만 골라 예측한 Random Forest
하지만 파라미터를 많이 넣을수록 feature들이 많아질수록 GridSearch하는데에, 그리고 학습시키는데에 많은 시간이 소요된다.
계산량을 줄이기 위해 중요 feature들만 학습시킬 필요가 있다.
앞서 회귀 문제에서는 feature importance를 계수값을 통해 확인했었다.
하지만 tree모델에서는 feature_importances_라는 것이 있다.
best_cols_values = rf_clf_best.feature_importances_
best_cols = pd.Series(best_cols_values, index = X_train.columns)
top20_cols = best_cols.sort_values(ascending = False)[:20]
top20_cols💻 출력
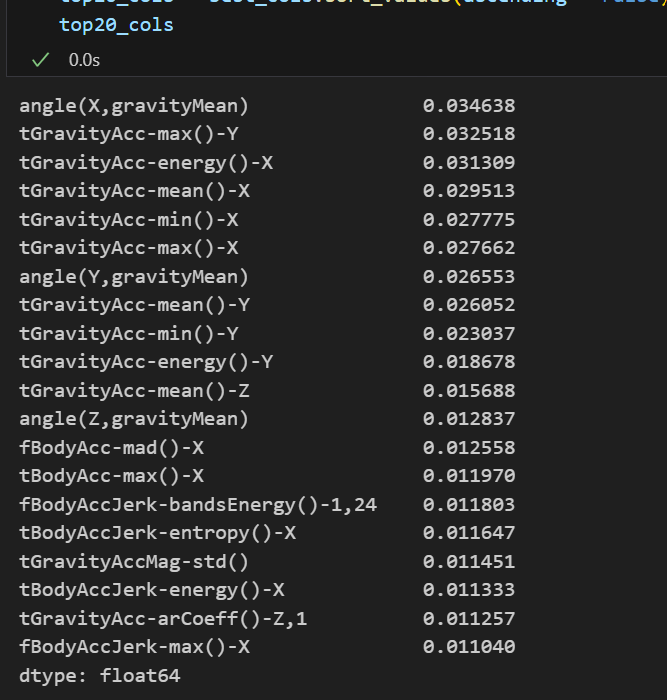
위와 같이 모델링할 때 중요하게 사용된 feature들을 한 눈에 확인할 수 있다.
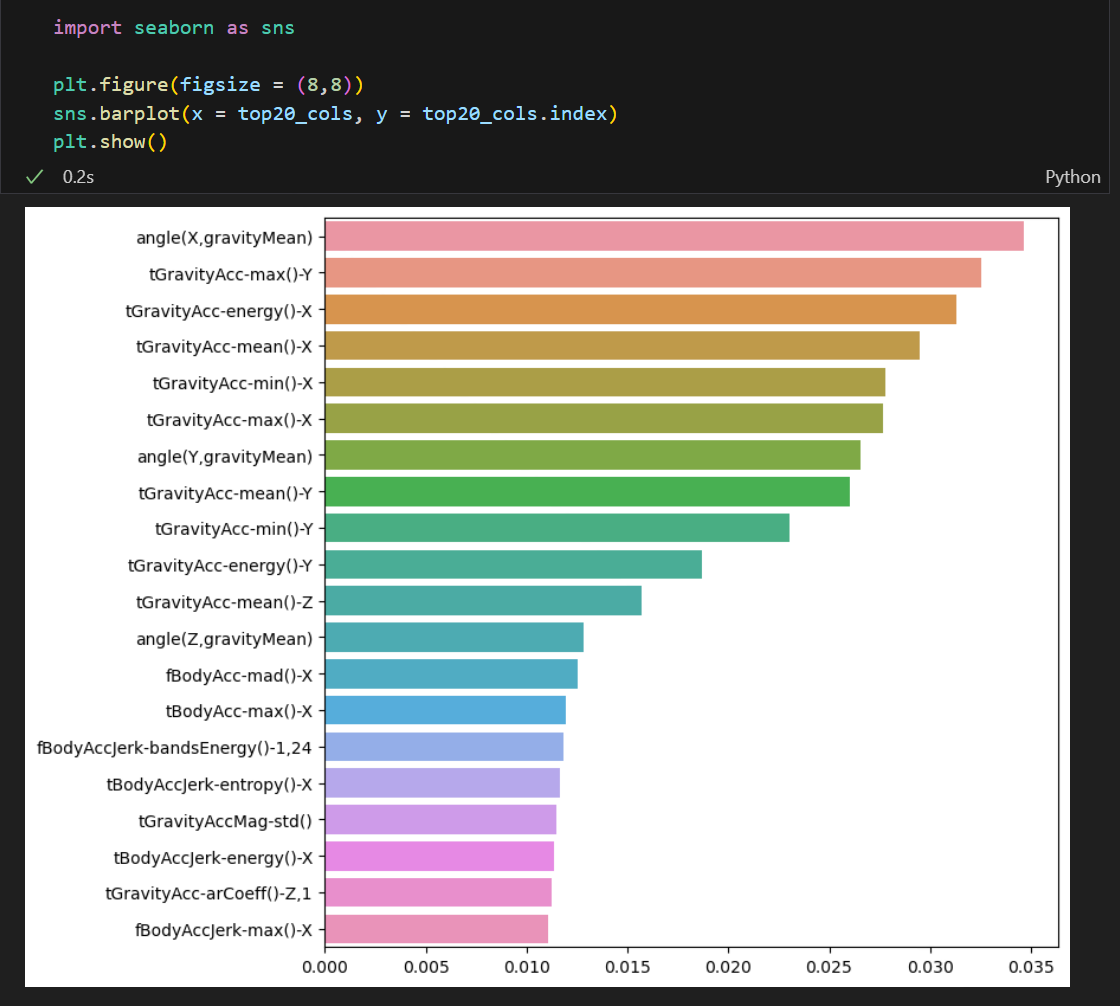
이를 시각화하면 더 한 눈에 알아볼 수 있는데 이 중요 feature들만 가지고 모델링을 할 수도 있다.
# 20개 특성만 가지고 모델링 다시
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train)
pred1_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred1_re)💻 출력
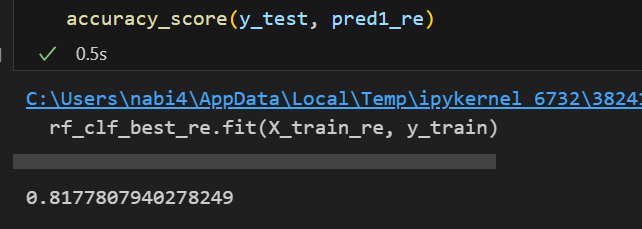
물론 모든 feature를 사용한 것과 비교하면 accuracy는 많이 떨어졌다. 하지만 학습 시간은 확실히 줄어들었다.
이와 같이 학습량이 많아도 모든 feature를 학습시킬건지, 일부 중요 feature만 가지고 학습시킬건지 또한 데이터 분석가가 결정해야할 사항 중 하나가 될 것이다.
