
✍🏻 2일 공부 이야기.

오늘 공부한 실습 코드는 위 깃허브 사진을 클릭하면 이동합니다 :)
Star Wars
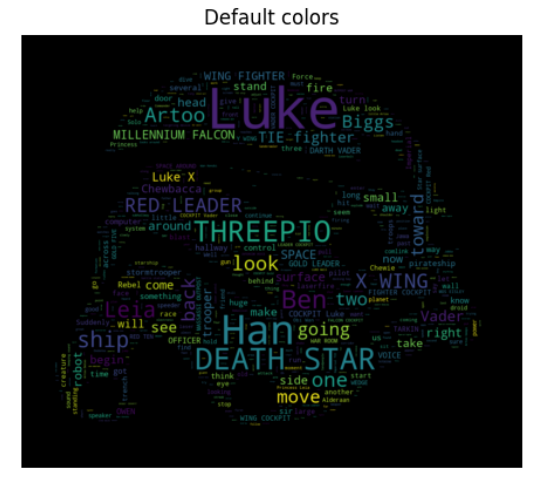
이번에는 스타워즈 글을 가지고 워드클라우드를 해보자.
데이터는 위에서 다운받아주었다.
text = open('./data/06_a_new_hope.txt').read()
text = text.replace("HAN", "Han")
text = text.replace("LUKE'S", "LUKE")
mask = np.array(Image.open('./data/06_stormtrooper_mask.png'))먼저 데이터를 다운받아주고 수정하고자 하는 단어는 수정해준다.
# STOPWORDS : 큰 의미가 없는 단어 토큰 모음
stopwords = set(STOPWORDS)
stopwords.add('int')
stopwords.add('ext')큰 의미가 없는 단어들도 추가로 설정해주고
wc = WordCloud(
max_words = 1000, mask = mask, stopwords = stopwords,
margin = 10
).generate(text)
default_colors = wc.to_array()WordCloud를 설정해준다. 이때 기본으로 설정되어있는 색상값들을 알아볼 수도 있다.
하지만 이번에는 마스크 안에 들어가는 색상값을 좀 바꿔보자. 공식문서를 보면 다음과 같은 커스텀 색상이 가능한 것으로 나와있다.
 |  |
|---|
https://amueller.github.io/word_cloud/auto_examples/a_new_hope.html
위 링크로 들어가면 코드도 나와있다. 자세한 설명은 나와있지 않아서 좀 더 조사해보았다.
- word: 현재 처리 중인 단어
- font_size: 해당 단어에 사용될 폰트 크기
- position: 해당 단어의 위치
- orientation: 해당 단어의 방향
- random_state: 무작위로 생성된 상태 값으로써 색상 선택에 사용될 수 있음 (선택적 매개변수)
- **kwargs: 기타 추가적인 매개변수들이 포함될 수 있음
return 'hsl(0, 0%%, %d%%)' % random.randint(60, 100)과 같은 형식으로 색상값을 반환하는데를 HSL(Hue-Saturation-Lightness) 색상 모델을 사용하는 것이었다.
또한 아래와 같은 추가적인 내용이 있었다.
첫 번째 파라미터인 '0'은 Hue 값을 나타내며 범위는 0부터 360까지 가능합니다. 두 번째 파라미터인 '0%%'은 Saturation 값을 나타내며 퍼센트로 표현되고 보통 그대로 '0%'로 설정하여 채도 없음을 의미합니다. 세 번째 파라미터 %d%%'은 Lightness 값을 나타내며 퍼센트로 표현되고 여기서는 무작위로 생성된 정수값이 들어갑니다.
따라서 위 코드에서는 'Hue=0', 'Saturation=0%', 'Lightness=60%~100%' 범위 내에서 임의의 회색 계열 색상을 반환하게 됩니다.
하지만 이렇게 커스텀한 색깔을 이용하는 것 보단matplotlib의 colormap을 이용하면 훨씬 편리할 것 같았다!
📌 워드클라우드 글자 컬러맵 설정 : https://jimmy-ai.tistory.com/135
# 마스크 안의 글자를 회색 톤으로 맞추기 위한 방법
import random
def grey_color_func(word, font_size, position, orientation, random_state = None, **kwargs):
return 'hsl(0,0%%, %d%%)' % random.randint(60,100)
import matplotlib.pyplot as plt
plt.figure(figsize = (12,12))
plt.imshow(wc.recolor(color_func=grey_color_func, random_state=13))
plt.axis('off')
plt.show()💻 출력

워드클라우드에 적절한 색상값을 표현할 수도 있는 것을 배웠다.
다음은 법안 내용을 실습해보자.
육아휴직관련 법안
KoNLPy는 대한민국 법령을 가지고 있어서 편리하게 파이썬으로 읽어들일 수 있다. 지금은 많은 법령 중 제 1809890호 의안을 이용해보자.
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib import rc
rc("font", family = "Malgun Gothic")한글을 시각화하기 때문에 한글 설정이 필요했다.
import nltk
from konlpy.corpus import kobill
doc_ko = kobill.open('1809890.txt').read()
doc_ko모든 워드클라우드의 시작은 데이터 읽어들이기.
해당 라이브러리들을 import해주고 kobill.open('법령 번호.txt').read()를 통해 쉽게 법령을 텍스트로 읽을 수 있다.
그리고 앞서 배운 명사를 분석해주는 함수는 아래와 같다.
from konlpy.tag import Okt
t = Okt()
tokens_co = t.nouns(doc_ko)
tokens_co💻 출력

그리고 명사 분석된 토큰들을 별명을 붙여 다양한 기능을 사용할 수 있게 만들어주기 위해
ko = nltk.Text(tokens_co, name = '육아휴직법')코드를 실행시켜주었다. 위는 tokens_co 토큰들을 육아휴직법이란 별명을 붙여준 코드이다.
이렇게 ko 변수는 다양한 작업을 할 수 있다.
len(ko): 전체 명사 개수 출력ko.tokens: 전체 명사 출력len(set(ko.tokens)): 중복되지 않은 유일한 명사 단어 출력ko.vocab(): 각 명사들의 호출 횟수 출력ko.count('원하는 단어'): 특정 단어의 빈도수 출력ko.concordance('원하는 단어'): 해당 단어 좌우에 있는 단어를 같이 출력ko.collocations(): 연관된 단어(collocation)를 출력해주는데 이는 null값으로 반환될 수도 있음
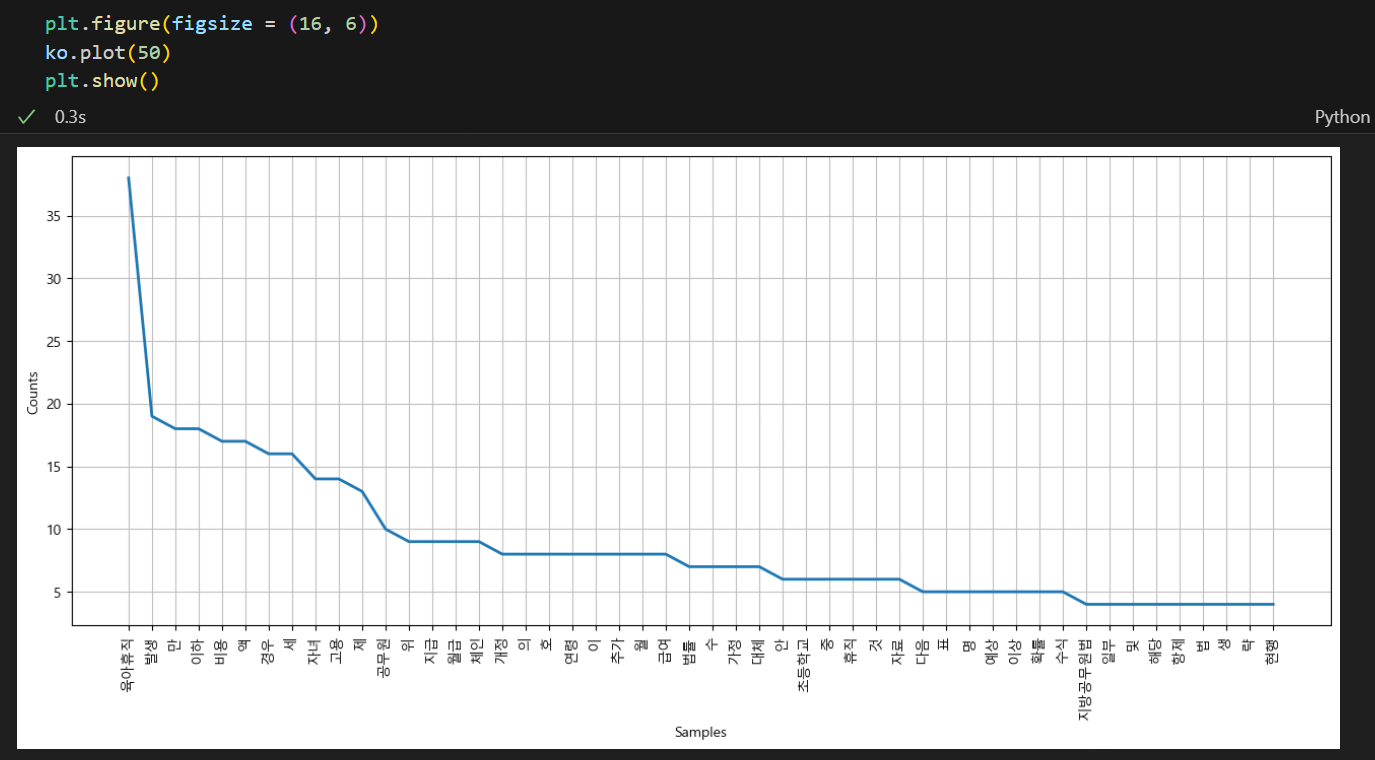
위와 같이 가장 많이 사용된 명사들을 시각화할 수도 있다. ko.plot(원하는 개수) 를 입력해주면 가장 많이 호출된 명사 개수 만큼 그 호출 횟수와 함께 시각화해준다.
하지만 여기서 만, 액, 세 등 불필요한 단어도 섞여있는 것을 볼 수 있다. 이들을 제거해주기 위해선 stopwords에 넣어주어야하는데 한글은 그것이 좀 복잡해서 일일이 손으로 집어넣어주어야하는 경우가 대부분이다.
stop_words = [
'.', '(', ')', ',', "'", '%', "-", "x", ").",
"의", "자", "에", "안", "번", "호", "을", "이", "다", "만",
"로", "가", "를"
]
# 위 stop_words를 제외한 명사를 다시 설정해줌
ko = [each_word for each_word in ko if each_word not in stop_words]불필요한 단어들을 제외한 명사 분석된 토큰들을 다시 불러주고 시각화를 다시 해보면 아래와 같다.
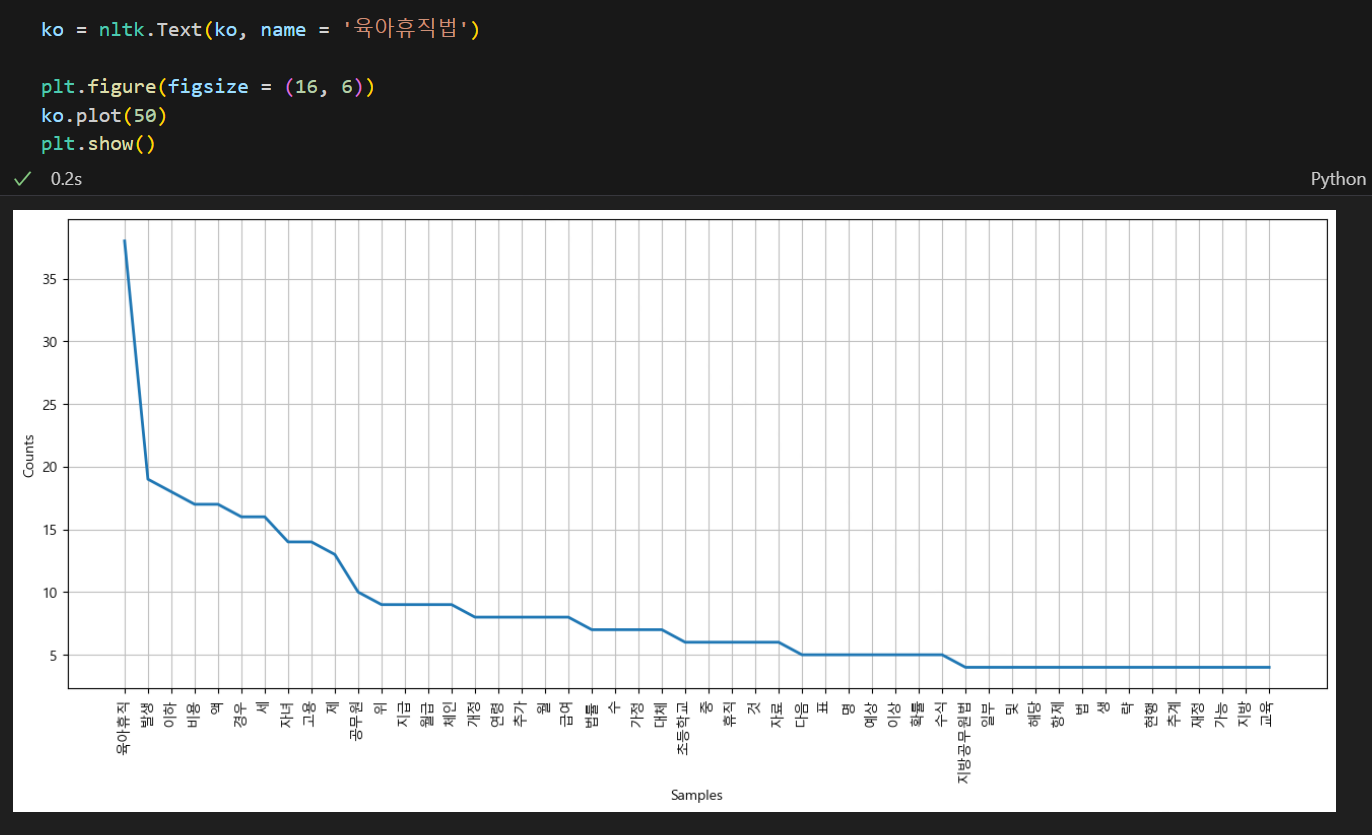
plt.figure(figsize=(16,6))
ko.dispersion_plot(['육아휴직', '초등학교', '공무원'])💻 출력
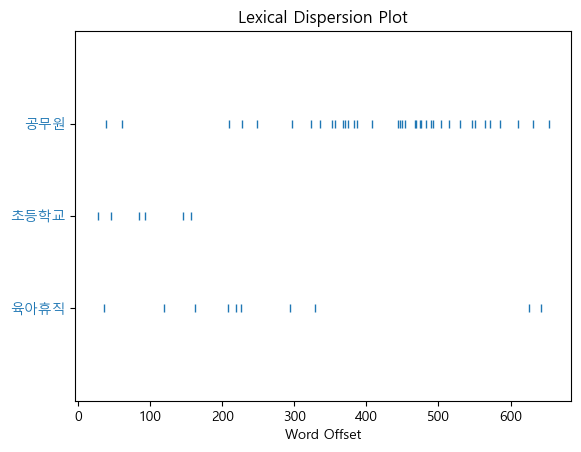
또한 위와 같이 ko.dispersion_plot(['원하는 단어'])를 이용하면 전체 단어들 중 해당 단어가 어디에 위치해있는지를 알 수 있다.
그렇다면 이제 마지막으로 워드클라우드를 해보면 아래와 같은 결과를 볼 수 있다.
data = ko.vocab().most_common(150) #가장 많이 불린 단어 150개
wordcloud = WordCloud(
font_path = "C:\Windows\Fonts\malgun.ttf", # 글씨체
relative_scaling = 0.2, # 단어 사이 간격
background_color = 'white' # 배경색
).generate_from_frequencies(dict(data))
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()💻 출력

나이브베이즈 감성분석
from nltk.tokenize import word_tokenize
import nltk나이브 베이즈 분류기는 자연어 처리에서 가장 많이 사용되는 분류기이다. 기계학습 분야에서 특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기로 광범위하게 연구되고 있다.
영어 버전과 한글 버전 두 가지 버전의 감성 분석을 짧게 실습해보려고 한다.
언어와 관계없이 나이브베이즈 감성 분석의 단계는 아래와 같다.
- Train 데이터 만들기(지도학습이기 때문에 정답지도 같이!)
- Train 데이터 문장들을 단어 단위로 쪼개어 중복되지 않은 유일한 단어들만 모인 전체 말뭉치 만들기
- 전체 말뭉치 속 단어들이 Train 데이터의 각 문장 속 단어에 포함되어있는지 여부를 정답지 라벨과 같이 출력하기
- 나이브베이즈 분류기 학습시키기
- 테스트 데이터를 만들고 단어를 쪼개 전체 말뭉치 속 단어 대비 테스트 문장 단어 포함 여부 출력하기
- 학습된 나이브베이즈 분류기에 넣어 예측시키기
전체 방향은 위와 같지만 한글은 형태소에 따라 분석 결과가 많이 달라져서 좀 더 추가되는 내용이 있다. 아래 실습 코드를 보고 다시 또 살펴보자.
영어
📌 1. Train 데이터 만들기
train = [
("i like you", "pos"),
("i hate you", "neg"),
("you like me", "neg"),
("i like her", "pos")
]📌 2. 전체 말뭉치 만들기
sentence = train[0] # ("i like you", "pos")
word_tokenize(sentence[0]) # word_tokenize 는 띄어쓰기를 기준으로 단어를 분리해줌이때 sentence는 ("i like you", "pos")를 반환하고 word_tokenize(sentence[0])의 word_tokenize는 띄어쓰기를 기준으로 단어를 분리해주기 때문에 위의 결과는 ['i', 'like', 'you']가 된다. 이를 이용해서 중복되지 않은 Train 데이터의 단어들을 추출할 수 있다.
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words 💻 출력
{'hate', 'her', 'i', 'like', 'me', 'you'}
set을 이용해 중복되지 않은 유일한 단어들만 추출했다.
📌 3. {전체 말뭉치 단어 : Train 문장 포함 여부}, Train 라벨 형태로 출력하기
# 전체 말뭉치 속 각 단어 : train 문장 단어에 속하는지 여부(True/False), train 라벨
t = [({word : (word in word_tokenize(x[0])) for word in all_words} , x[1]) for x in train]
t💻 출력

📌 4. 나이브베이즈 분류기 학습시키기
classifier = nltk.NaiveBayesClassifier.train(t) # 훈련
classifier.show_most_informative_features() 💻 출력
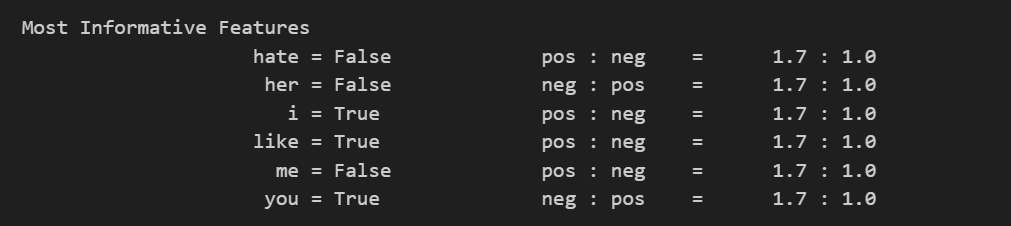
nltk에서는 sklearn의 fit이 train이다. train을 실행시켜 분류기를 학습시켜준 후 show_most_informative_features()을 통해 가장 많은 정보를 담고 있는 특성을 볼 수도 있다.
출력된 결과를 해석해보자면, 아래와 같이 해석할 수 있다.
'hate' 라는 단어가 없을 때 pos:neg의 비율은 1.7:1이다. 그리고 'her'라는 단어가 없을 때 neg:pos 의 비율은 1.7:1이다.
📌 5. 테스트 데이터 만들기 및 분류기에 들어갈 상태 만들어주기
test_sentence = 'i like MeRui'
test_sent_features = {
word.lower() : (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features # 전체 말뭉치 대비 테스트 문장 단어 포함 여부💻 출력
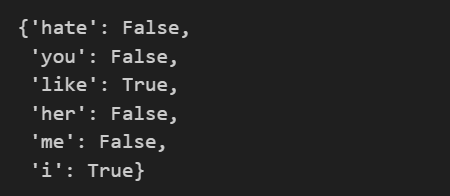
📌 6. 테스트 데이터 예측하기
classifier.classify(test_sent_features)classify는 sklearn의 predict와 같은 기능을 한다. 따라서 위 코드를 실행시켜주면 'pos'라는 테스트 데이터에 대한 예측값을 얻을 수 있다.
한글
이번에는 한글로도 해보자.
📌 1. Train 데이터 만들기
from konlpy.tag import Twitter
pos_tagger = Twitter()
train = [
("메리가 좋아", "pos"),
("고양이도 좋아", "pos"),
('난 수업이 지루해', 'neg'),
('메리는 이쁜 고양이야', 'pos')
]📌 2. 전체 말뭉치 만들기
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words 💻 출력
{'고양이도', '고양이야', '난', '메리가', '메리는', '수업이', '이쁜', '좋아', '지루해'}
여기서 '고양이도', '고양이야'를 다른 것으로 인식하고 '메리가'와 '메리는' 또한 다른 언어로 인식하고 있다. 이대로 분석하면 문제가 생기기 때문에 한글 감성 분석을 할 때엔 형태소 분석이 꼭 필수이다.
def tokenize(doc):
return ['/'.join(t) for t in pos_tagger.pos(doc, norm = True, stem = True)]
train_docs = [(tokenize(row[0]), row[1]) for row in train]
train_docs💻 출력
[(['메리/Noun', '가/Josa', '좋다/Adjective'], 'pos'),
(['고양이/Noun', '도/Josa', '좋다/Adjective'], 'pos'),
(['난/Noun', '수업/Noun', '이/Josa', '지루하다/Adjective'], 'neg'),
(['메리/Noun', '는/Josa', '이쁘다/Adjective', '고양이/Noun', '야/Josa'], 'pos')]
형태소 분석을 한 후 품사를 단어 뒤에 붙여주는 tokenize함수를 만들어 각 Train 데이터가 단어/품사 형태로 출력되게 만들어주었다.
tokens = [t for d in train_docs for t in d[0]]
tokens💻 출력
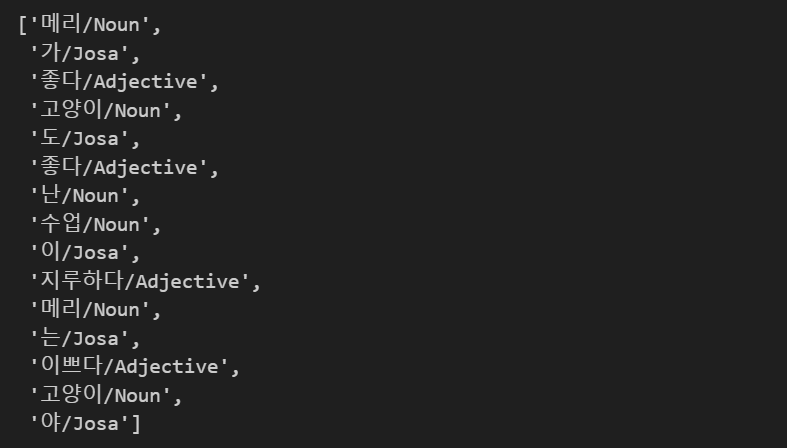
그리고 각 단어/품사 를 출력하여 전체 말뭉치를 만들어주었다.
📌 3. {전체 말뭉치 단어 : Train 문장 포함 여부}, Train 라벨 형태로 출력하기
def term_exists(doc):
return {word : (word in set(doc)) for word in tokens}
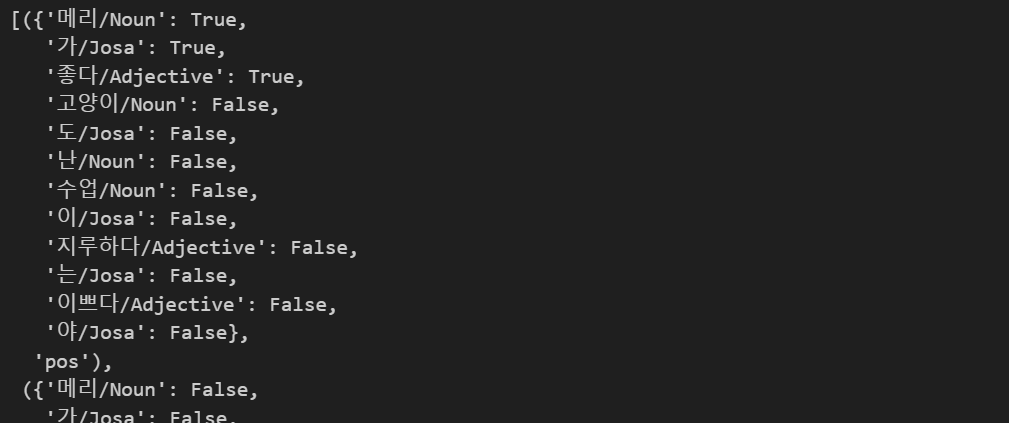
train_xy = [(term_exists(d), c) for d, c in train_docs]
train_xy💻 출력
📌 4. 나이브베이즈 분류기 학습시키기
classifier = nltk.NaiveBayesClassifier.train(train_xy)📌 5. 테스트 데이터 만들기 및 분류기에 들어갈 상태 만들어주기
test_sentence = [('난 마치면 메리랑 놀거야')]
test_docs = pos_tagger.pos(test_sentence[0])
test_sent_features = {word : (word in tokens) for word in test_docs}
test_sent_features💻 출력

📌 6. 테스트 데이터 예측하기
classifier.classify(test_sent_features)💻 출력
'pos'
한글 감성 분석에서 2번의 형태소 분석을 하지 않았을 때 해당 테스트 문장의 예측값은 'neg'가 나왔다. 이렇듯 한글에서는 형태소 분석이 필수임을 잊지 말자!!
문장 유사도
문장을 벡터로 표현할 수 있으면 두 점 사이 거리를 구하는 공식으로 두 문장 간 유사도를 측정할 수도 있을 것 같다.
문장 유사도를 측정할 수 있는 방법 2가지를 소개하겠다.
거리를 측정하는 것은 지도 학습이 아니기 때문에 따로 정답지는 필요없다. 문장 유사도를 측정하는 방법은 아래와 같은 전체적인 과정을 실행시킨다.
- Vectorizer 호출
- Train 데이터 생성
- (한글의 경우) 형태소 분석을 통해 Train 데이터를 변환
- Vectorizer fit_transform
- Test 데이터 생성 및 분류기에 들어갈 형태 만들어주기
- 거리 측정 후 유사한 문장 반환
Count Vectorize
📌 1. Vectorizer 호출
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df = 1)📌 2. Train 데이터 생성
# 거리만 측정하는 것이므로 지도학습이 아니다.
contents = [
'상처받은 아이들은 너무 일찍 커버려',
'내가 상처받은 거 아는 사람 불편해',
'잘 사는 사람들은 좋은 사람 되기 쉬워',
'아무 일도 아니야 괜찮아'
]📌 3. (한글의 경우) 형태소 분석을 통해 Train 데이터를 변환
from konlpy.tag import Okt
t = Okt() # 형태소 분석 엔진
contents_tokens = [t.morphs(row) for row in contents]💻 출력
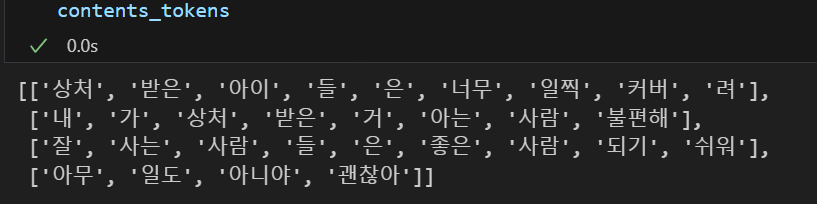
morphs를 사용하면 위와 같이 형태소들이 추출되는 것을 볼 수 있다. 우리는 이후 nltk의 CountVectorizer를 사용할 것인데 이는 띄어쓰기로 단어를 구분한다. 따라서 그에 맞는 형태를 만들어주기 위해 형태소 단위로 잘라진 문장을 띄어쓰기하여 다시 하나의 문장으로 합쳐주는 작업이 필요하다.
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize💻 출력

📌 4. Vectorizer fit_transform
X = vectorizer.fit_transform(contents_for_vectorize)
X이때 아래와 같은 해석을 할 수 있다.
- Train 문장 개수, 전체 말뭉치 단어 개수
num_samples, num_features = X.shape
# (4, 17)
# 문장 개수 , 전체 말뭉치 단어 개수 출력- 전체 말뭉치 단어
vectorizer.get_feature_names_out() # 전체 말뭉치 단어- 전체 말뭉치 대비 Train 데이터 단어 호출 개수 반환
X.toarray().transpose()💻 출력
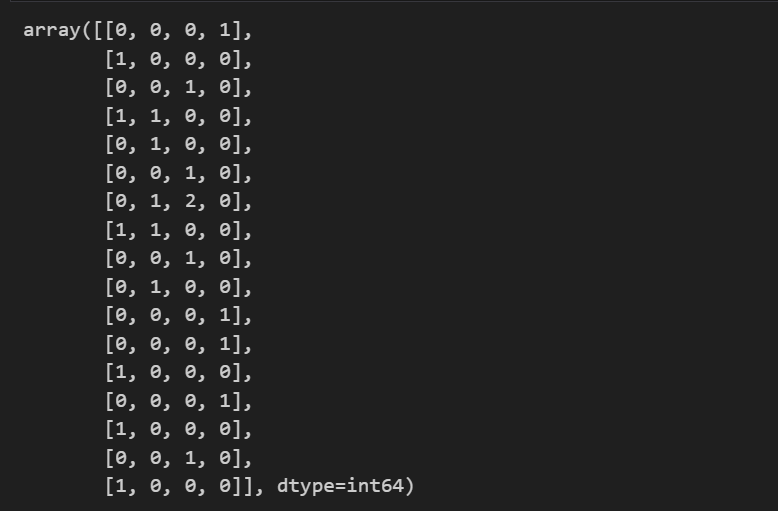
행은 전체 말뭉치 단어, 열은 각 Train 문장에 해당한다.
위 행렬을 통해 전체 말뭉치 단어 대비 Train 데이터 단어가 몇 번 호출되었는지 알 수 있다.
📌 5. Test 데이터 생성 및 분류기에 들어갈 형태 만들어주기
new_post = ['상처받기 싫어 괜찮아']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + " " + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize💻 출력
[' 상처 받기 싫어 괜찮아']
# 테스트용 문장을 벡터화
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()💻 출력
array([[1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int64)
📌 6. 거리 측정 후 유사한 문장 반환
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())단순한 두 사이 거리를 구하는 공식을 이용한 함수를 하나 만들어주고 Train 데이터와 Test 데이터 사이의 거리를 구해준다.
dist = [dist_raw(each, new_post_vec) for each in X]dist에는 [2.449489742783178, 2.23606797749979, 3.1622776601683795, 2.0]와 같은 결과값이 담겨있고
print("Best post index is ", dist.index(min(dist)), 'dist = ', min(dist))
print("Test post is --> ", new_post)
print("Best dist post is --> ", contents[dist.index(min(dist))])💻 출력
Best post index is 3 dist = 2.0
Test post is --> ['상처받기 싫어 괜찮아']
Best dist post is --> 아무 일도 아니야 괜찮아
거리가 가장 작은 문장을 추출하여 가장 유사한 문장을 추출할 수 있다.
결국은 문장을 벡터로 잘 만드는 것과 만들어진 벡터 사이의 거리를 계산하는 것이 중요하다.
그렇다면 벡터화하는 방법 중에 단어 호출 횟수를 세는 것 이외에 다른 방법은 무엇이 있을까?
TF-IDF Vectorize

from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')tf-idf를 이용해서도 두 점 사이의 거리를 구할 수 있다.
앞서 CountVectorizer를 이용한 코드를 모두 TfidfVectorizer로 바꿔주고 내용은 그대로이다.
또한 두 점 사이의 거리를 구할 때 정규화를 진행시킨 후 구할 수도 있다. 정규화를 한 후 두 점 사이의 거리를 구하게 되면 한 쪽의 특성이 두드러지는 것을 방지할 수 있다는 장점이 있다.
def dist_norm(v1, v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())아래는 TfidfVectorizer을 이용한 전체 코드이다.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')
# Train 데이터 벡터화
X = vectorizer.fit_transform(contents_for_vectorize)
# Test 데이터 벡터화
new_post_vec = vectorizer.transform(new_post_for_vectorize)
# Train - Test 사이 간 거리
dist = [dist_norm(each, new_post_vec) for each in X]
# Test 문장과 유사한 Train 문장 추출
print("Best post index is ", dist.index(min(dist)), 'dist = ', min(dist))
print("Test post is --> ", new_post)
print("Best dist post is --> ", contents[dist.index(min(dist))])💻 출력
Best post index is 3 dist = 1.1021396119773588
Test post is --> ['상처받기 싫어 괜찮아']
Best dist post is --> 아무 일도 아니야 괜찮아
위 내용을 바탕으로 네이버 API를 호출하여 지식인 내용 중 유사한 문장을 추출한 실습도 진행해보았는데 코드가 비슷해서 깃허브에 올려둔 파일을 참고하면 좋을 것 같다.
