
✍🏻 5일 공부 이야기.

오늘 공부한 실습 내용은 위 깃허브 사진을 클릭하면 이동합니다 :)
네이버 책 가격 회귀 예측

우리는 이전, 네이버 API를 통해 상품을 검색하는 코드를 만들었었다.
이를 이용해 "네이버에 <파이썬>을 검색하여 나오는 도서들의 가격을 예측해보자."
이 문제는 그러면 <회귀> 문제가 될 것이다.
다른 함수는 이전에 만들어둔 함수와 똑같은데 get_fields 함수만 이번에 활용될 함수로 조금 변형시켜 주고, get_search_url, get_result_onpage, delete_tag 함수를 사용했다.
# 한 페이지의 내용을 pandas로 반환해주는 함수
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
## 수정된 부분
price = [each["discount"] for each in json_data["items"]]
publisher = [each["publisher"] for each in json_data["items"]]
isbn = [each["isbn"].split() for each in json_data["items"]]
result_pd = pd.DataFrame({
"title" : title,
"price" : price,
"isbn" : isbn,
"link" : link,
"publisher" : publisher
}, columns = ["title", "price", "isbn", "link", "publisher"])
return result_pd그리고 1000개의 데이터를 수집해주고 정리해주었다.
# API를 이용한 1000개의 데이터 수집
result_book = []
for n in range(1, 1000, 100):
url = get_search_url('book', '파이썬', n,100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_book.append(pd_result)
result_book = pd.concat(result_book)
# 인덱스 정리
result_book.reset_index(drop = True, inplace = True)
# 가격 데이터형 정리
result_book['price'] = result_book['price'].astype('float')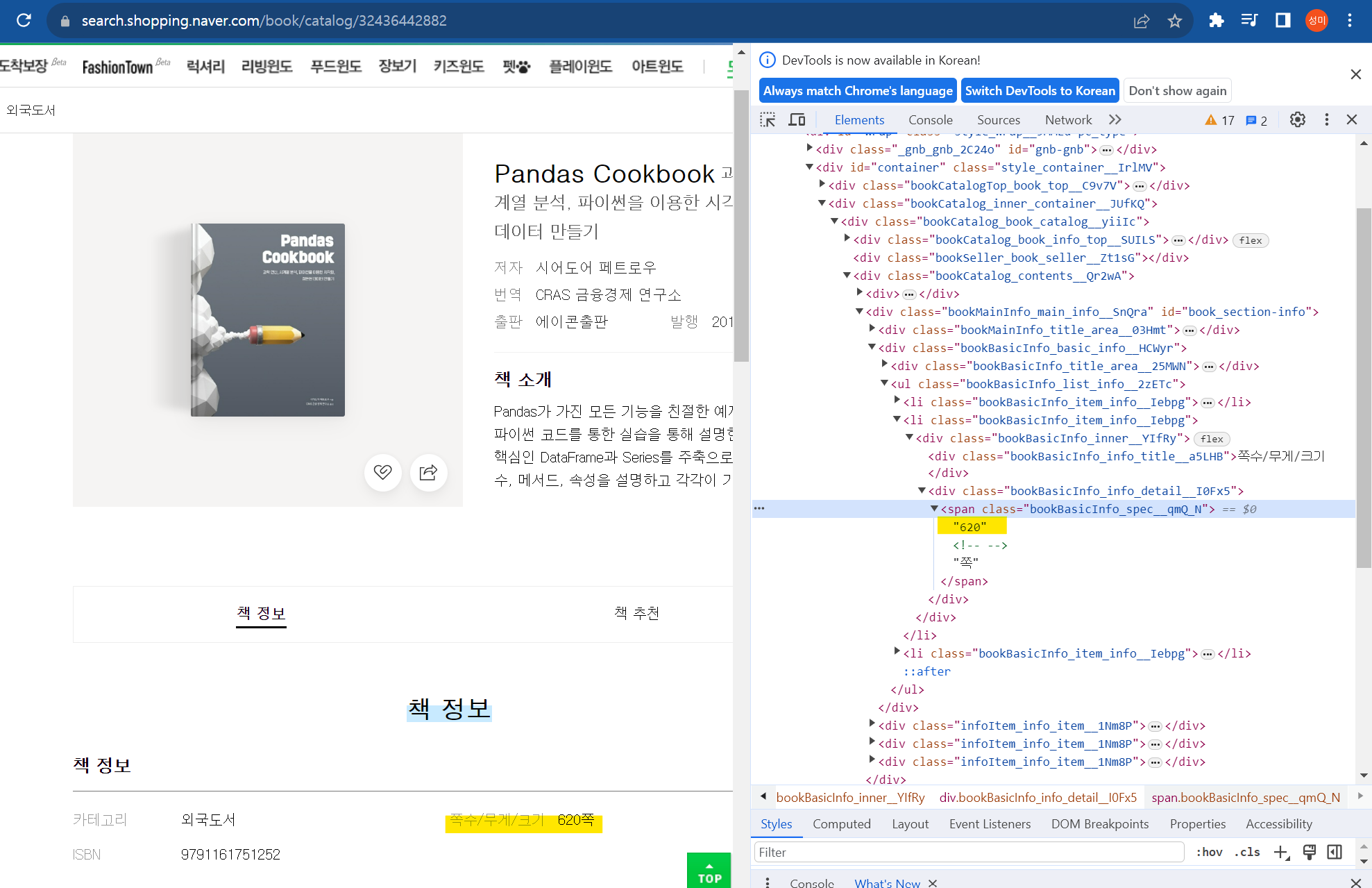
그리고 책 쪽수 정보도 얻어와보자.
import re
tmp = soup.find_all(class_ = 'bookBasicInfo_spec__qmQ_N')[0].get_text()
result = re.search(r'\d+', tmp) # 숫자 정보만 추출
result.group() 위와 같이 클래스명을 넣어주고 숫자 정보만 추출해주는 정규표현식을 사용해주면 '620'만 얻어올 수 있다.
이를 모든 데이터에 적용시켜보자.
# 페이지 정보를 얻기 위한 함수
def get_page_num(soup):
tmp = soup.find_all(class_ = 'bookBasicInfo_spec__qmQ_N')[0].get_text()
# 페이지가 동작하지 않거나, 페이지 정보가 없는 경우가 생길 수 있으므로 예외 처리를 진행함
try :
result = re.search(r'\d+', tmp) # 숫자 정보만 추출
return result.group()
except:
print("====> Error in get_page_num")
return np.nan
# 전체 데이터에 대해 실시
import time
page_num_col = [] # 페이지 데이터가 담길 변수
for url in result_book['link']:
print(url)
print(time.time())
try:
page_num = get_page_num(BeautifulSoup(urlopen(url), 'html.parser'))
page_num_col.append(page_num)
# urlopen이 되지 않은 경우를 대비하여 예외 처리 실행
except:
print("===> Error in urlopen")
page_num_col.append(np.nan)
print(len(page_num_col))
time.sleep(0.5)
result_book['page_num'] = page_num_col중간에 페이지 정보가 없거나, urlopen이 되지 않아 에러가 났을 때 중단되지 않고 계속 실행되도록 예외처리도 꼼꼼하게 해주었다.
(지금 생각해보면 get_page_num 함수를 호출했을 때 페이지 정보가 없어 tmp 변수가 불러지지 않을 때도 "===> Error in urlopen" 예외처리로 빠진 것 같다.)
# 데이터 형 변환
result_book['page_num'] = result_book['page_num'].astype('float')
for idx, row in result_book.iterrows():
if np.isnan(row['page_num']):
print("Start fix..")
print(row['link'])
page_num = get_page_num(BeautifulSoup(urlopen(row['link']), 'html.parser'))
result_book.loc[idx, 'page_num'] = page_num
time.sleep(0.5)page_num 컬럼을 숫자형으로 바꿔주고 np.nan이 입력된 데이터들에 대해 한 번 더 입력해보라고 코드를 실행시켰는데 IndexError: list index out of range 에러가 떴다. np.nan으로 입력된 데이터들은 모두 페이지 정보 데이터가 없어 tmp 변수를 찾을 수 없어 위 에러가 떴던 것 같다.
그래서 만약 위에서 get_page_num 함수에서는 페이지 정보가 없었을 때의 예외처리를 넣고 전체 페이지 데이터를 입력하는 코드에서는 urlopen이 되지 않을 때의 예외처리를 하고 싶다면 아래와 같이 get_page_num 함수 코드를 수정하는 것이 맞는 것 같다.
def get_page_num(soup):
tmp = soup.find_all(class_='bookBasicInfo_spec__qmQ_N')
# 페이지 정보가 있는 경우
if len(tmp) > 0:
try:
result = re.search(r'\d+', tmp[0].get_text()) # 숫자 정보만 추출
return result.group()
except:
print("====> Error in get_page_num")
return np.nan
# 페이지 정보가 없는 경우
else:
print("====> 'bookBasicInfo_spec__qmQ_N' class not found")
return np.nan# 다시 시도했지만 입력이 안된 책 정보들은 삭제
result_book = result_book[result_book['page_num'].notnull()]
# 엑셀로 정리
writer = pd.ExcelWriter("./data/python_books.xlsx" , engine = 'xlsxwriter')
result_book.to_excel(writer, sheet_name ='Sheet1')
workbook = writer.book
workbook = writer.sheets['Sheet1']
workbook.set_column("A:A", 5)
workbook.set_column("B:B", 60)
workbook.set_column("C:C", 10)
workbook.set_column("D:D", 15)
workbook.set_column("E:E", 10)
workbook.set_column("F:F", 50)
writer.save()가격 정보가 없는 데이터는 삭제하고 엑셀로 해당 데이터프레임을 저장해주었다.
이제부터 진짜 분석이다 ㅎㅎ^^
raw_data = pd.read_excel('./data/python_books.xlsx', index_col = 0)
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 8))
sns.regplot(x = 'page_num', y = 'price', data = raw_data)
plt.show()💻 출력
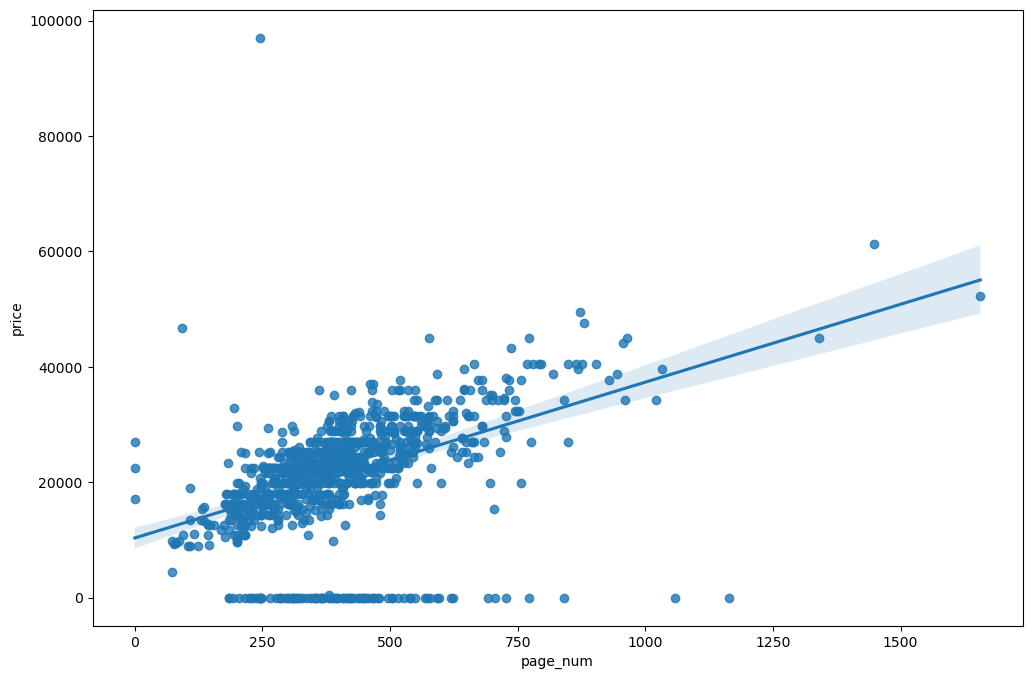
우리의 목적은 책의 가격을 예측하는 것이므로 page_num과 price 사이의 regplot을 그려보았다. 은근 둘의 상관성이 있는 것 같다.
출판사들의 분포 편차가 너무 심해서 일부 상위 4개의 출판사들의 page_num과 price 사이의 regplot도 그려보았다.
import seaborn as sns
# 출판사별 가격 회귀 시각화 함수
def show_regplot_pub(publisher, ax):
raw_1 = raw_data[raw_data['publisher'] == publisher]
sns.regplot(x='page_num', y='price', data=raw_1, ax=ax)
fig, ax = plt.subplots(1, 4, figsize=(20, 8))
show_regplot_pub('에이콘출판', ax[0])
show_regplot_pub('한빛미디어', ax[1])
show_regplot_pub('위키북스', ax[2])
show_regplot_pub('비제이퍼블릭', ax[3])
plt.show()💻 출력
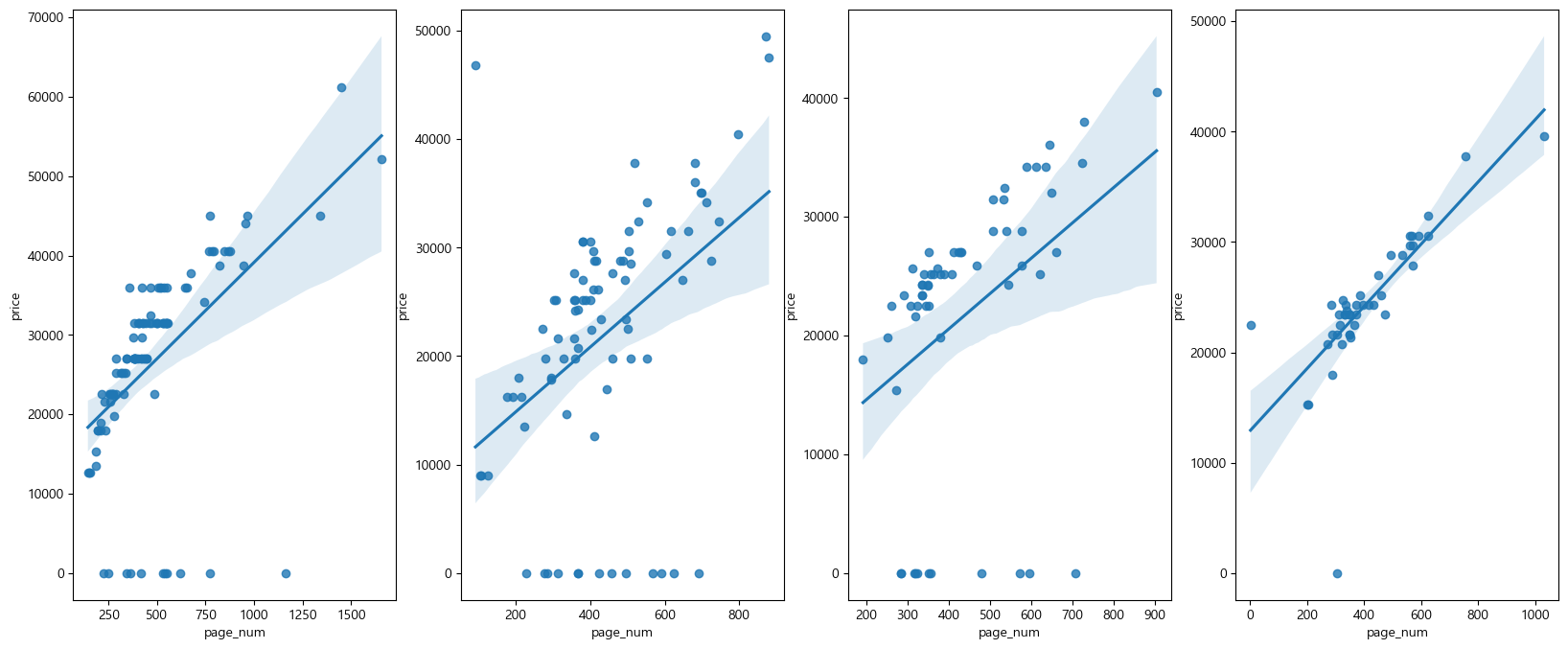
출판사별 페이지 개수에 따른 가격을 예측하는 것도 나쁘지 않아보인다.
# 데이터 분리(페이지 정보 - 가격 회귀 예측)
from sklearn.model_selection import train_test_split
X = raw_data['page_num'].values
y = raw_data['price'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
X_train = X_train.reshape(-1,1)
X_test = X_test.reshape(-1,1)
# 모델 학습
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
# 에러 계산
from sklearn.metrics import mean_squared_error
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
rmse_tr = (np.sqrt(mean_squared_error(y_train, pred_tr)))
rmse_test = (np.sqrt(mean_squared_error(y_test, pred_test)))
print("RMSE of Train Data : ", rmse_tr)
print("RMSE of Test Data : ", rmse_test)💻 출력
RMSE of Train Data : 9265.243542372275
RMSE of Test Data : 7447.320295153908
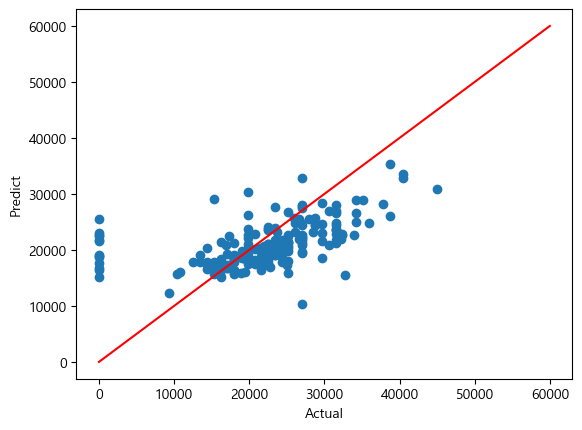
회귀 문제에서 모델의 성능을 평가하는 것 중 RMSE가 있다. 실제값과 예측값을 시각화한 것을 보아하니, 실제값보다 싸게 예측한 것이 많아보인다.
이번에는 출판사별 가격 예측을 해보자.
앞서 시각화된 출판사 중 회귀로 잘 표현된 "비제이퍼블릭" 출판사의 가격을 예측해보자.
raw_1 = raw_data[raw_data['publisher'] == "비제이퍼블릭"]
X = raw_1['page_num'].values
y = raw_1['price'].values"비제이퍼블릭" 출판사 데이터만 추출하여 위와 똑같이 코드를 실행시켜주면
💻 출력
RMSE of Train Data : 2203.4514471499165
RMSE of Test Data : 7685.712498848275
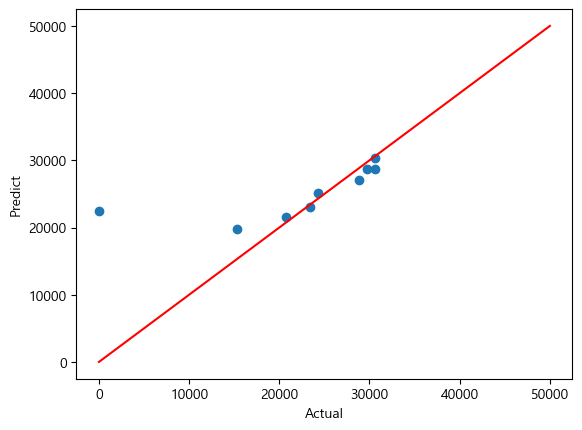
아래와 같은 결과를 얻을 수 있다.
데이터의 수가 적어서 성능이 좋아보인 걸수도 있지만 앞의 결과보단 성능이 좋아보이긴 한다 :)
클러스터링
from sklearn.cluster import KMeans문장의 유사도, PCA 등 우리는 앞서 비지도 학습을 배웠다. 비지도 학습의 다른 모델 중 하나가 클러스터링이다.
군집화라고도 불리는 클러스터링이란, 비슷한 샘플들의 모임이라 생각하면 된다.
클러스터링 중 가장 일반적인 알고리즘은 K-Means이다. 임의의 지점을 선택해서 해당 중심(= KMeans에는 평균을 의미)에 가장 가까운 포인트들을 선택하는 군집화이다. 거리 기반 알고리즘이라 속성의 개수가 많을 경우 계산량도 커지고 정확도가 많이 떨어지는 단점이 있다.
몇 개의 군집으로 나눌 것인지에 대한 선택은 n_clusters 옵션을 통해 우리가 설정해주어야하는 하이퍼파라미터이다.
iris
앞서 여러번 실습했던 iris 데이터에서 실습해보자.
우리는 여러 번의 실습을 통해 petal 특성들이 유의미하다는 것을 알기 때문에 데이터를 읽고 편의상 petal 컬럼만 추출했다.
feature = iris_df[['petal length', 'petal width']]
# 군집화
model = KMeans(n_clusters = 3) # 몇 개로 군집화 할건지는 우리가 정해줘야함
# 아래와 같은 옵션들이 더 있다.
# init : 초기 군집 중심점의 좌표를 설정하는 방식
# max_iter : 최대 반복횟수, 모든 데이터의 중심점 이동이 없으면 종료
model.fit(feature)fit을 시켜주면 아래와 같은 정보를 얻을 수 있다.
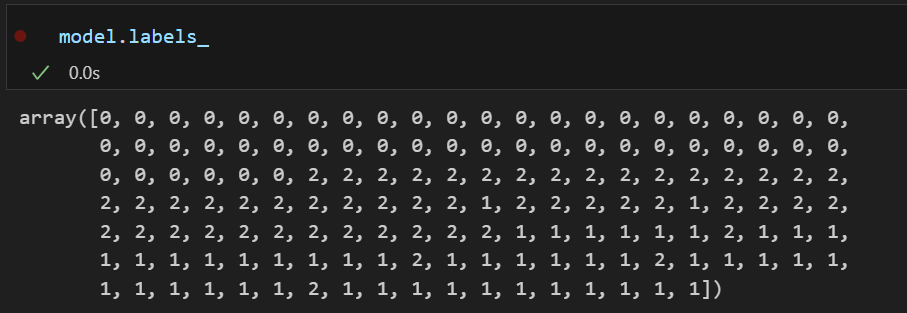 | 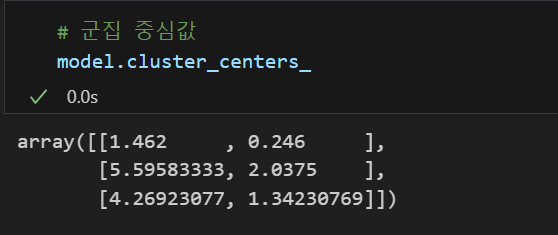 |
|---|
💡 여기서 주의해야할 것이 있다.
지금 이것들은 비지도 학습이기 때문에 우리가 익히 알고있는 iris 의 라벨의 순서와는 다르다. labels_에 출력되는 것은 군집화된 특정 라벨이지 본래 타겟 데이터의 라벨과는 상관 없음을 주의하자.
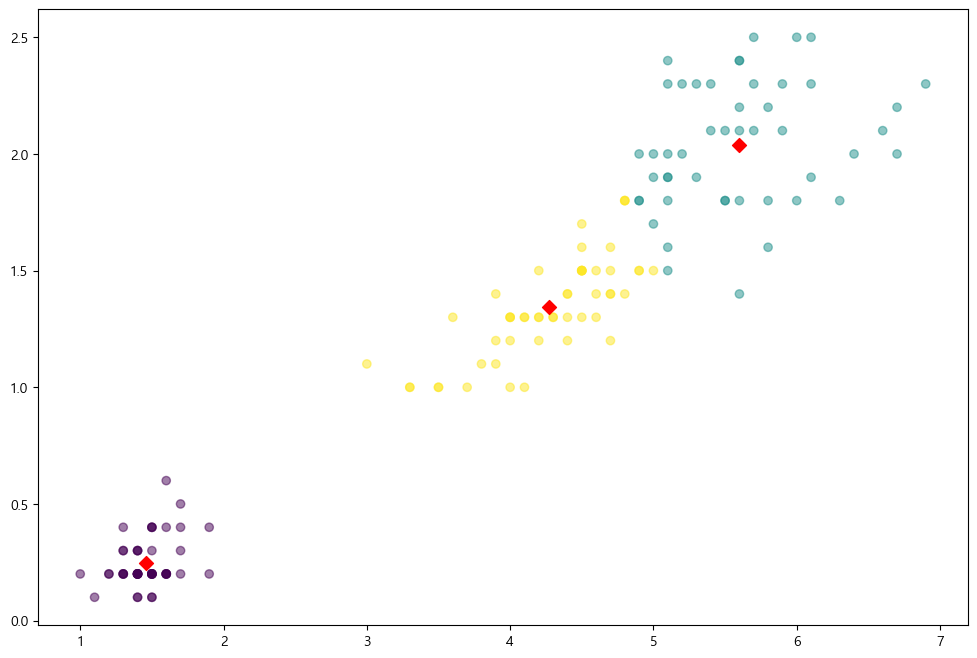
데이터들이 군집된 것을 시각화해보면 아주 이쁘게 잘 된 것 같다.
make_blobs
다음으론 클러스터링을 공부하기 좋은 데이터인 make_blobs을 실습해보자.
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples= 200, # 200개의 데이터
n_features=2, # 2개의 피쳐
centers = 3, # 3개의 중심값
cluster_std=0.8,# 데이터들의 표준편차
random_state=0
)
print(X.shape, y.shape)
# y의 값들과 각 값들의 개수 출력
unique, counts = np.unique(y, return_counts = True)
print(unique, counts)💻 출력
(200, 2) (200,)
[0 1 2][67 67 66]
위와 같이 데이터를 읽어주면 설정한 값에 따라 200개의 데이터가 0 : 67개, 1 : 67개, 2 : 66개가 있는 것을 볼 수 있다.
데이터를 정리해주고 군집화를 실시하여 시각화하면 아래와 같은 결과를 볼 수 있다.
# 결과 시각화
centers = kmeans.cluster_centers_ # 군집 중심값
unique_labels = np.unique(cluster_labels)
markers = ['o', 's', '^', 'P', "D", 'H', 'x'] # 마커 모양
for label in unique_labels:
label_cluster = cluster_df[cluster_df['kmeans_label'] == label]
center_x_y = centers[label]
# 실제값 표시 및 군집화된 컬러 표시
plt.scatter(x = label_cluster['ftr1'], y = label_cluster['ftr2'],
edgecolors='k', marker = markers[label])
# 중심값
# 배경 설정
plt.scatter(x = center_x_y[0], y = center_x_y[1], s = 200, color = 'white',
alpha = 0.9, edgecolor = 'k', marker=markers[label])
# 글씨 설정
plt.scatter(x = center_x_y[0], y = center_x_y[1], s = 70,
color = 'k', edgecolor = 'k', marker = '$%d$' % label)
plt.show()💻 출력
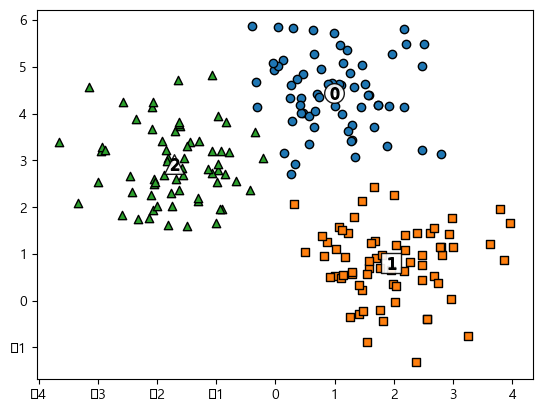
잘 분리된 것 같다..!!
하지만, 언제나 시각화의 결과를 보고 성능이 좋아보인다/아니다를 판단할 순 없다. 지도학습은 정확도, recall 등 모델을 평가할 수 있는 기준이 있었는데 비지도학습 모델은 어떻게 평가해야할까?
비지도 학습을 평가하기 위해 <실루엣 분석>을 많이 활용한다.
실루엣 분석이란 각 군집 간의 거리가 얼마나 효율적으로 분리되어있는지를 나타내는 것으로 다른 군집과는 거리가 떨어져있고 동일 군집 간의 데이터는 서로 가깝게 잘 뭉쳐져있는지를 확인할 수 있다.
실루엣 분석
pip install yellowbrick
위 분의 링크가 잘 정리된 것 같아 참고용으로 올려두었다!
iris 데이터를 군집화한 것을 실루엣 분석으로 시각화하고 싶다면 아래와 같이 코드를 작성할 수 있다.
from yellowbrick.cluster import silhouette_visualizer
silhouette_visualizer(kmeans, iris.data, colors = 'yellowbrick')💻 출력
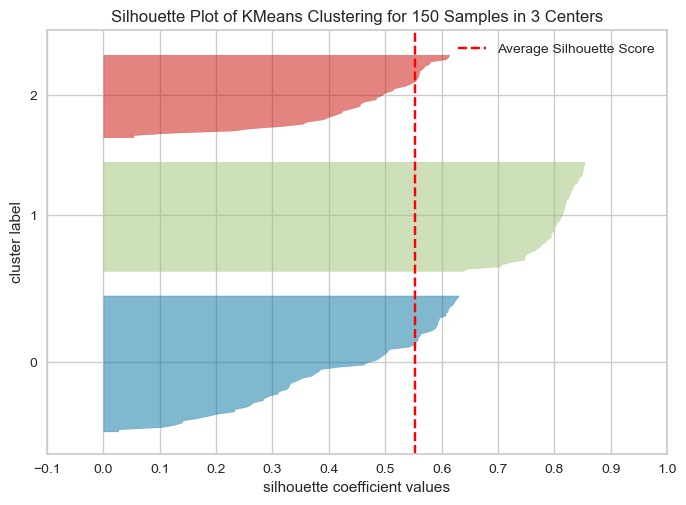
군집이 잘 분리된 모델일 수록 각 모양간의 간격이 넓고 뭉개지지 않은 형태를 띈다.
이미지 분할
KMeans를 통해 이미지를 읽어 해당 이미지 속 색상을 추출하여 이미지를 다시 읽는 것도 가능하다. 딥러닝에 들어가면 더 좋은 성능을 가진 모델을 배울텐데 지금은 단순히 색상을 분할하는 것을 목적으로 간단히 짚고 넘어가보자.
# 이미지 읽기
from matplotlib.image import imread
image = imread('./data/image.jpg')
plt.imshow(image)💻 출력
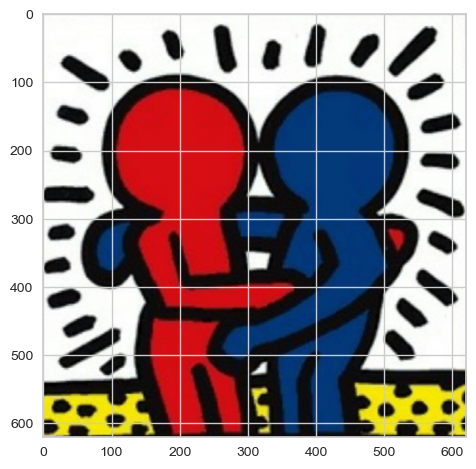
나는 위와 같은 그림을 분할시켜보려 한다.
# 좀 더 여러가지 군집화를 진행
segmented_imgs = []
n_colors = [10,8,6,4,2]
for n_clusters in n_colors:
kmeans = KMeans(n_clusters=n_clusters, random_state=13).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_].astype(int)
segmented_imgs.append(segmented_img.reshape(image.shape))
# 각 cluster 별 그림
plt.figure(figsize=(10,5))
plt.subplots_adjust(wspace=0.05,hspace = 0.1)
plt.subplot(231)
plt.imshow(image)
plt.title("Original image")
plt.axis('off')
for idx, n_clusters in enumerate(n_colors):
plt.subplot(232 + idx)
plt.imshow(segmented_imgs[idx])
plt.title("{} colors".format(n_clusters))
plt.axis('off')
plt.show()💻 출력

추출된 색상의 개수에 따라 그림이 표현되는 것이 달라지는 것을 볼 수 있다.
