
✍🏻 30일 공부 이야기.

오늘 공부한 내용은 위 깃허브에 올려두었습니다 :)
사진을 클릭하면 깃허브로 이동해요 !
딥러닝
TensorFlow
!pip install tensorflow
머신러닝을 위한 오픈소스 플랫폼 및 딥러닝 프레임워크
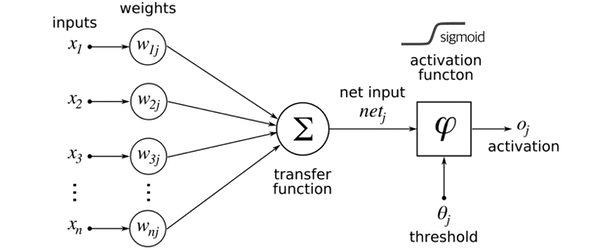
뉴런의 신경망에서 아이디어를 얻어서 딥러닝이 시작이 되었는데,
이때 신경망의 최소 단위를 뉴런이라 하고
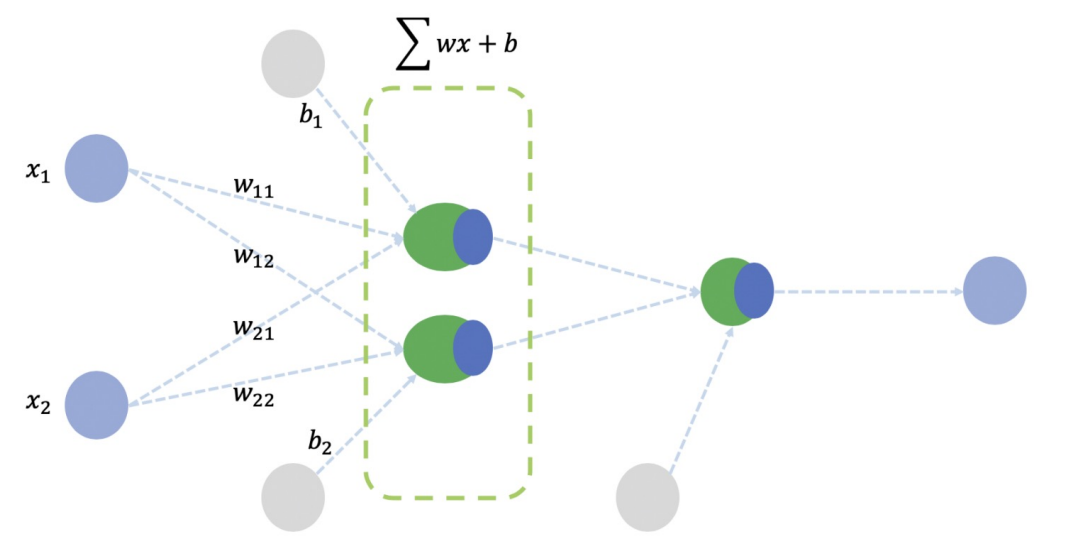
뉴런은 위 사진과 같이 입력, 가중치, 활성화 함수, 출력으로 구성되어있다.
뉴런에서 학습할 때 변하는 것은 가중치이며,
처음에는 초기화를 통해 랜덤값을 넣고 학습 과정에서 일정한 값으로 수렴하는 과정을 겪는다.
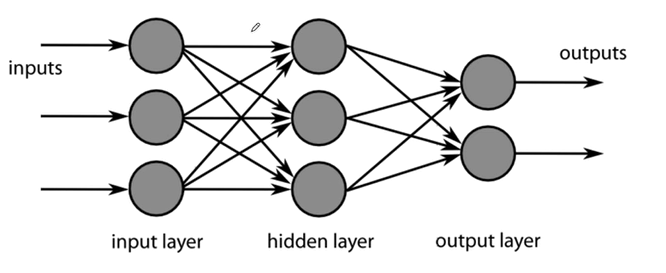
뉴런들이 모여있는 형태를 레이러하고 하며 이들이 모여 망(net)이 된다.
이런 신경망들이 많아지면 Deep Learning이 되는 것이다.
아래 3가지(회귀, 단일 분류, 다중 분류) 문제를 실습해보며 맛 보자!!
회귀 - Age, Weight를 통한 Blood fit 예측
📌 데이터 준비
raw_data_link = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/x09.txt'
raw_data = np.genfromtxt(raw_data_link, skip_header=36)
# 1열은 인덱스, 2열의 1들은 구분선 표시, 3열 ~ 5열까지가 실제로 들어있는 데이터이다.현재 raw_data에서 얻고자 하는 것은 Age, Weight 값을 주었을 때 Blood fat을 예측하는 것이다.
Linear Regression 모델로 이를 풀어보자.
📌 데이터 분리
# Train
x_data = np.array(raw_data[:, 2:4], dtype = np.float32)
y_data = np.array(raw_data[:,4], dtype = np.float32) # (25, )
y_data = y_data.reshape((25, 1)) # (25, )은 numpy 연산이 되지 않으므로 (25, 1)로 reshapeTrain에 사용할 데이터를 분리해주었다.
이제 모델링을 할 것인데 머신러닝 때와 비슷하게
모델 구성 -> 학습 -> 예측 순으로 진행된다.
📌 모델 구성
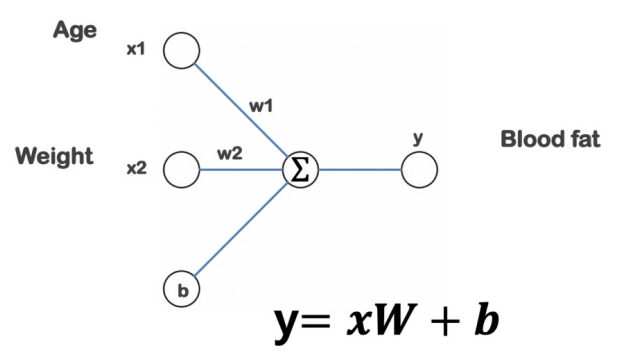
# 모델링
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape = (2, )), # 얻고자 하는 입력 shape이 2개, bias 1개
])
model.compile(optimizer = 'rmsprop', loss = 'mse') # mse를 기준으로 최적화하는 가중치 반환위 사진과 같은 구성을 가진 모델을 코드로 짜면 위와 같다.
이때 loss 함수란,
학습을 위해서 정해주어야하는 함수로, 정답까지 얼마나 멀리 있는지를 측정할 수 있는 함수이다.
loss 함수를 설정하고 optimizer를 설정하는 방식인데, optimizer는 loss를 어떻게 줄일 것인지를 결정하는 방법을 선택하는 것이다.
실습을 하면서 이에 대해 더 알아보자.
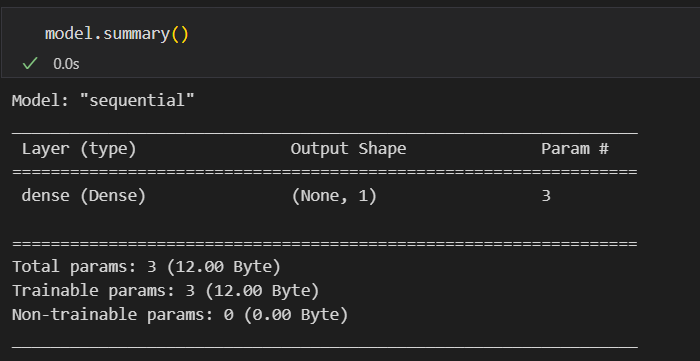
summary()를 통해 현재 모델이 어떻게 구성이 되어있는지 확인도 가능하다.
📌 학습
# 학습
hist = model.fit(x_data, y_data, epochs=5000)💻 출력
epoch이 늘어남에 따라 loss값이 줄어드는 것을 볼 수 있다.
history()를 통해 아래와 같이 시각적으로도 loss값이 떨어지는 것을 확인할 수 있다.
plt.plot(hist.history['loss'])
plt.title('Loss Value by epochs')💻 출력
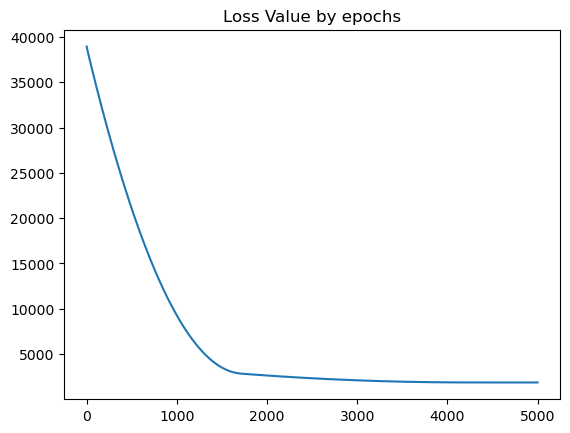
한 3천번 정도까지만 학습했어도 충분했을 것으로 보인다.
📌 예측
이제 학습된 모델을 이용하여 예측을 해보자. 머신러닝 때와 같이 predict를 이용해주면 된다.
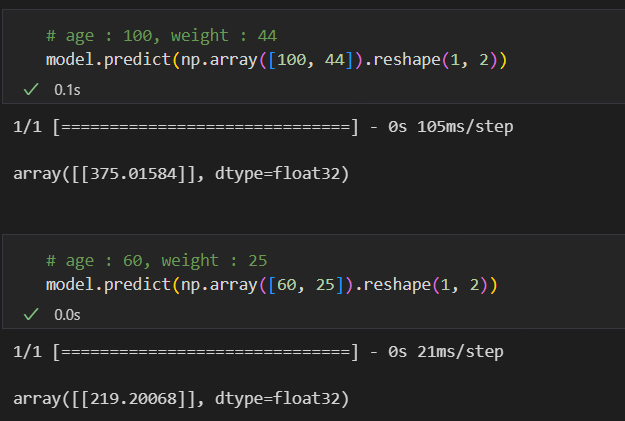
추가로, 학습된 가중치와 bias도 아래와 같이 확인할 수 있다.
W_, b_ = model.get_weights()
W_, b_💻 출력
(array([[1.2490779],
[5.57116 ]], dtype=float32),
array([4.977017], dtype=float32))
단일 분류 - XOR 문제
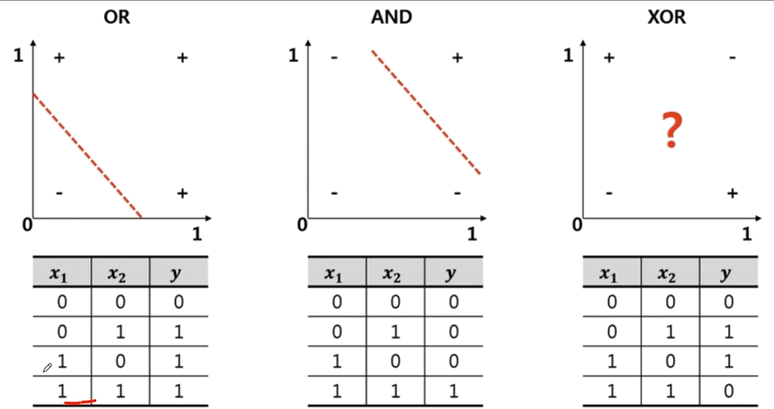
XOR 문제는 앞서 직선 하나로 해결할 수 있었던 것과 달리, 절대 선형 문제로 풀 수 없다. 즉, 뉴런 하나로 문제를 해결할 수 없고 레이어를 2개 이상 쌓아야한다는 뜻이 된다.
📌 데이터 준비
# 데이터 준비
X = np.array([[0,0],
[1,0],
[0,1],
[1,1]])
y = np.array([[0], [1], [1], [0]])간단하게 데이터를 준비하고 모델링을 해보자.
📌 모델 구성
# 모델링
model = tf.keras.Sequential([
# 입력을 2개 받아 각각 출력한 다음
tf.keras.layers.Dense(2, activation='sigmoid', input_shape = (2, )),
# 출력된 결과를 하나로 모아줌
tf.keras.layers.Dense(1, activation='sigmoid')
])activation function - 'sigmoid'
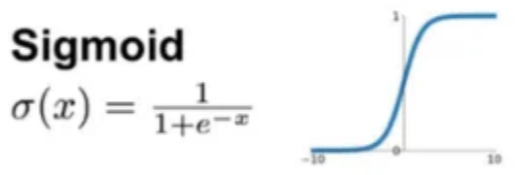
이때 activation 함수로 sigmoid를 설정한 이유는 비선형 함수를 같이 통과시켜 주는 데에 의의가 있다.
디폴트 설정은 선형 함수(직선)이므로 이를 두 번 통과시키면 결국엔 선형 함수가 되어버려 우리가 기존에 직선 하나로 해결할 수 없어 레이어를 2번 쌓은 효과가 사라진다.
따라서 선형이 되지 않도록 activation 함수를 비선형 함수인 sigmoid를 설정해준 것이다.
# 확률적으로 샘플링하여 학습시킨 후 계산하라는 코드
model.compile(optimizer=tf.keras.optimizers.SGD(lr = 0.1), loss = 'mse')
model.summary() # 모델 구성 확인optimizer로는 SGD를 사용했는데 이와 관련된 내용은 iris 데이터를 실습하며 더 자세히 설명하도록 하겠다.
📌 학습 및 예측
# 학습
# epochs : 지정된 횟수만큼 학습
# batch_size : 한 번의 학습에 사용될 데이터의 개수
hist = model.fit(X, y, epochs=5000, batch_size=1)
# 예측
model.predict(X)다음에 이야기할 소재이지만 언급만 해놓자면, 레이어가 2개 이상일 때 오차를 어떻게 계산하는지가 딥러닝 세계에서 항상 의문이었다.
맨 마지막 단계에서는 실제값이 있으니 오차를 계산할 수 있지만, 중간 단계에서는 실제값이 없기 때문에 오차 계산이 어려웠던 것이다. 이후, 역전파라는 개념이 등장하면서 이를 효과적으로 풀 수 있게 되었는데 이 이론은 다음 iris 데이터를 실습 때 더 언급하겠다.
다중 분류 - iris 데이터
📌 데이터 준비
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
먼저 다중 분류의 값은 위와 같이 클래스로 분류되어있다.
우리는 오차를 실제값 - 예측값 형식으로 두 차이를 계산해주었는데 분류에서는 오차를 이렇게 바로 계산하면 안된다.
오차를 계산할 때 이 형식이 가능하도록 데이터를 변형시켜주어야하는데 이 때 사용하는 것이 원 핫 인코딩이다.
원 핫 인코딩
# y label 변형
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse = False, handle_unknown='ignore')
enc.fit(y.reshape(len(y), 1))
enc.categories_ # [array([0, 1, 2])]
# 실제 변형
y_onehot = enc.transform(y.reshape(len(y), 1))
y_onehot[:3] # 이런 형태로 변환되었다.💻 출력
array([[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.]])
📌 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=13)이제 모델을 구성해보자.
모델을 구성하기 전, 앞서 설명했던 역전파와 activation function, optimizer에 대해 알아보며 모델을 구성해보자.
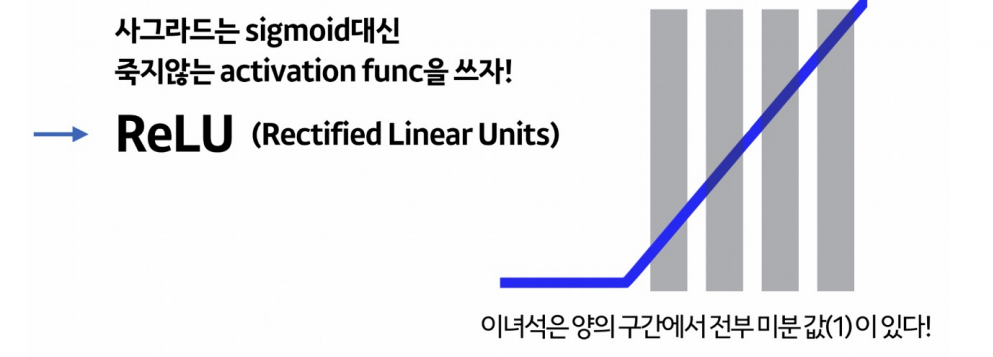
activation function - 'relu'
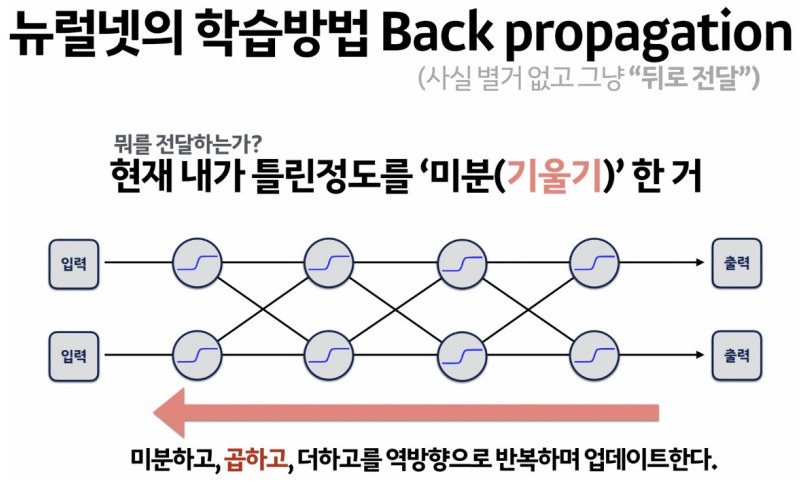
역전파
 |  | 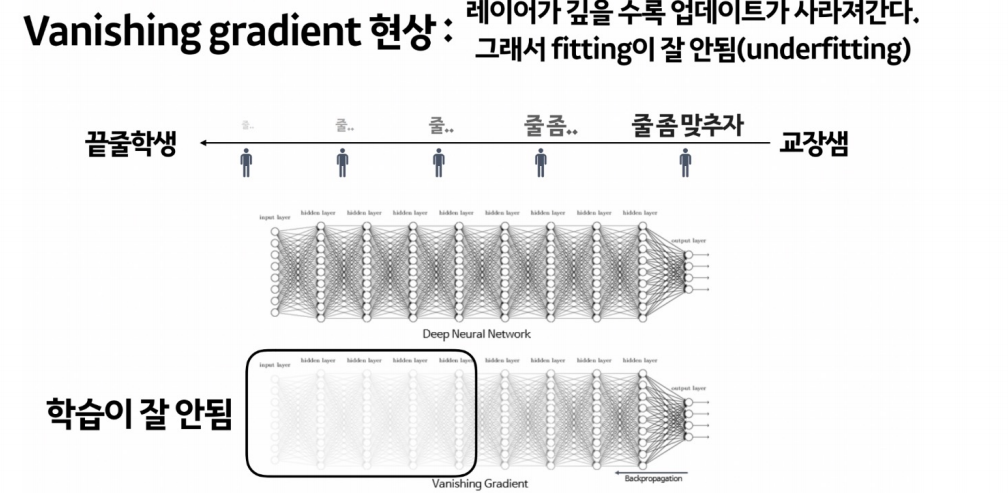 |
|---|
relu는 레이어가 깊어질수록 gradient vanishing 현상이 생기는 sigmoid 함수를 대신하기 위해 사용하는 것이다.
activation function - 'softmax'
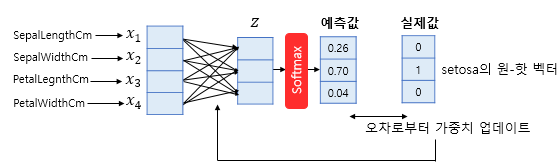
🖱️ 사진 클릭시 softmax 설명 링크 이동
그리고 모델을 구성할 때 마지막 activation function은 내가 얻고자하는 대답에 맞는 함수를 선택해야한다.
1️⃣
예를 들어, 첫 번째 실습 문제처럼 회귀 예측 같은 경우에는 해당 output을 그대로 받으면 되기 때문에 아무것도 설정해주지 않았다.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape = (2, )),
])2️⃣
두 번째 XOR 문제와 같은 단일 분류 같은 경우에는 O or X의 값을 반환해주면 되므로 output에 sigmoid를 해주었다.
model = tf.keras.Sequential([
# 입력을 2개 받아 각각 출력한 다음
tf.keras.layers.Dense(2, activation='sigmoid', input_shape = (2, )),
# 출력된 결과를 하나로 모아줌
tf.keras.layers.Dense(1, activation='sigmoid')
])3️⃣
마지막 iris 데이터와 같은 다중 분류 문제의 경우에는 단일 분류처럼 O or X가 아닌 각 클래스에 해당할 확률을 반환해주고 가장 큰 확률을 가지는 클래스를 최종 예측값으로 선택하는 과정이 필요하다. 이 흐름이 진행될 수 있도록 우리는 softmax를 이용해줄 것이다.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape = (4, ), activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])optimizer 의 종류
이제 loss function을 줄여나가며 compile을 해주어야한다.
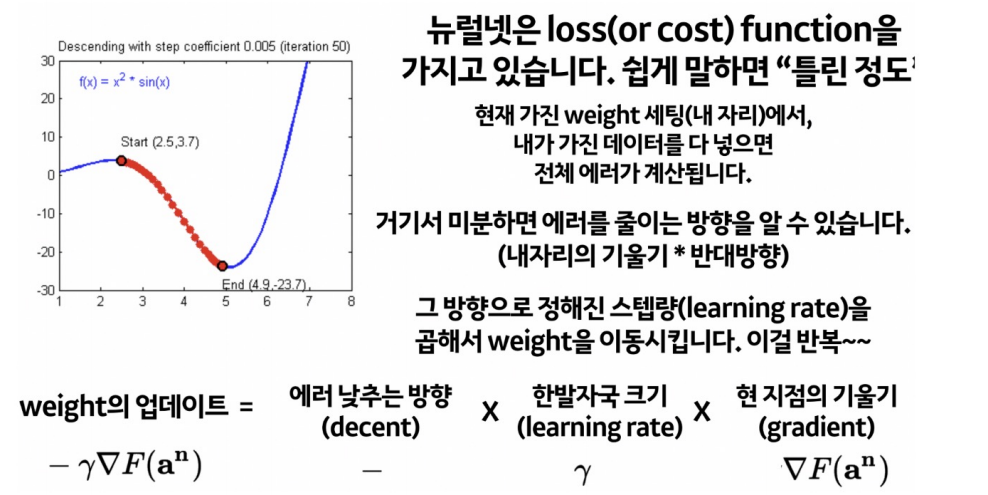
이때 loss function의 현 가중치에서의 기울기(gradient)를 구해서 loss를 줄이는 방향으로 업데이트를해 나가는데 어떤 방식으로 줄여나가는지를 결정하는 것이 optimizer 이다.
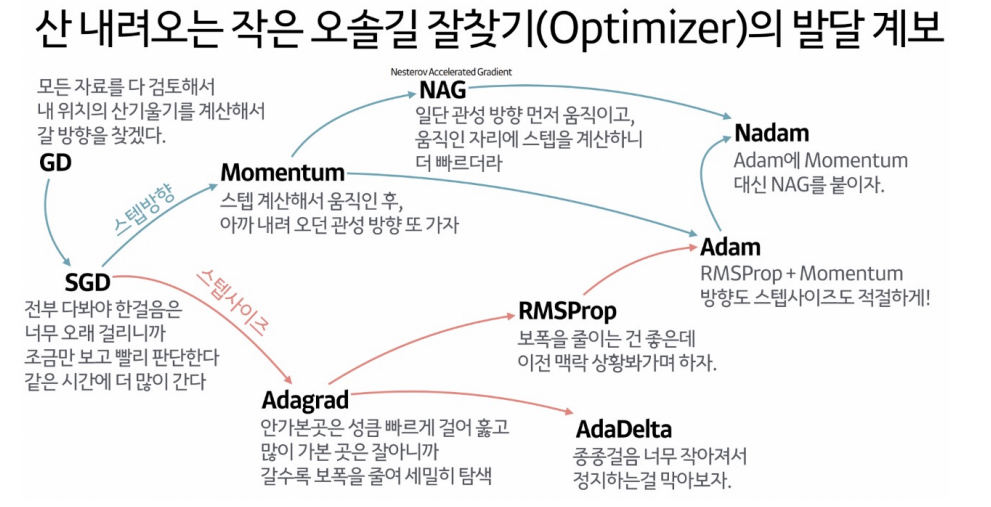
optimizer의 종류는 위와 같이 많이 있다. 데이터의 종류에 따라 어떤 것이 좋은지는 확인해보아야겠지만, 기본적으로 adam을 많이 사용한다고 한다.
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
model.summary()💻 출력
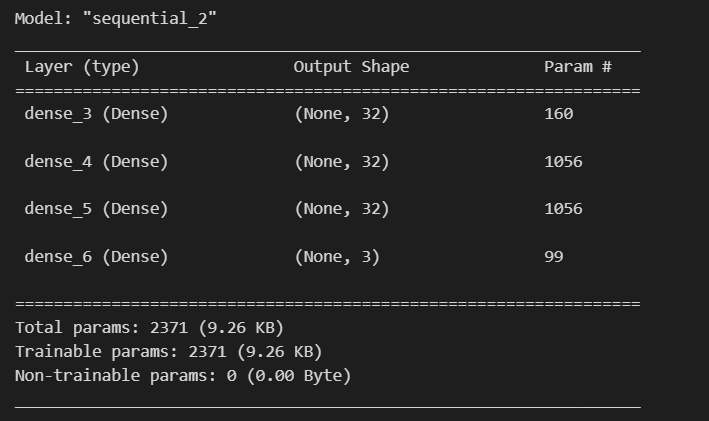
📌 학습 및 평가
# 학습
hist = model.fit(X_train, y_train, epochs=100)
# 모델 평가
model.evaluate(X_test, y_test, verbose = 2)💻 출력
[0.09855823218822479, 1.0]
loss와 accurcay도 확인할 수 있다.
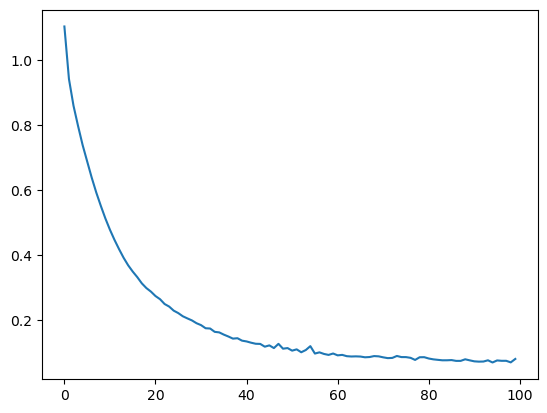 plt.plot(hist.history['loss']) plt.plot(hist.history['loss']) | 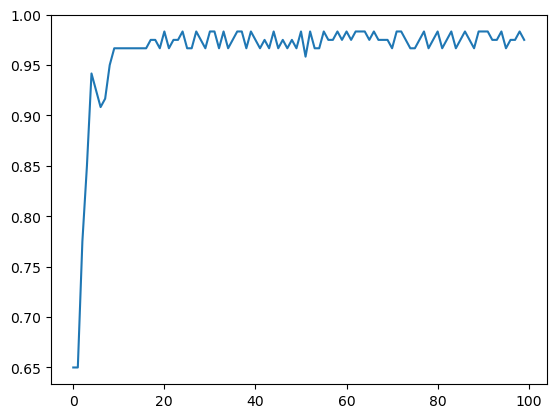 plt.plot(hist.history['accuracy']) plt.plot(hist.history['accuracy']) |
|---|
다중 분류 - MNIST
이전 머신러닝 파트에서 MNIST를 사용해본 적이 있다.
이번에는 딥러닝을 통해 필기체 숫자를 인식해보자.
📌 데이터 준비
# 데이터 읽기
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0 , x_test / 255.0각 픽셀은 255가 최대값이여서 이를 나눠줌으로써 0 ~ 1사이의 값으로 조정해주었다. 일종의 min-max scaler를 적용한 셈이다.
이때 이전 흐름과 비슷하게 간다면 이 또한 다중 분류 문제이므로 y의 값을 원핫 인코딩을 통해 변환해주어야한다. 하지만 이 과정이 귀찮다면(??) 비슷한 기능을 하는 loss function의 sparse_categorical_crossentropy을 이용하면 된다.
이번 실습에서는 이것을 한 번 이용해보자.
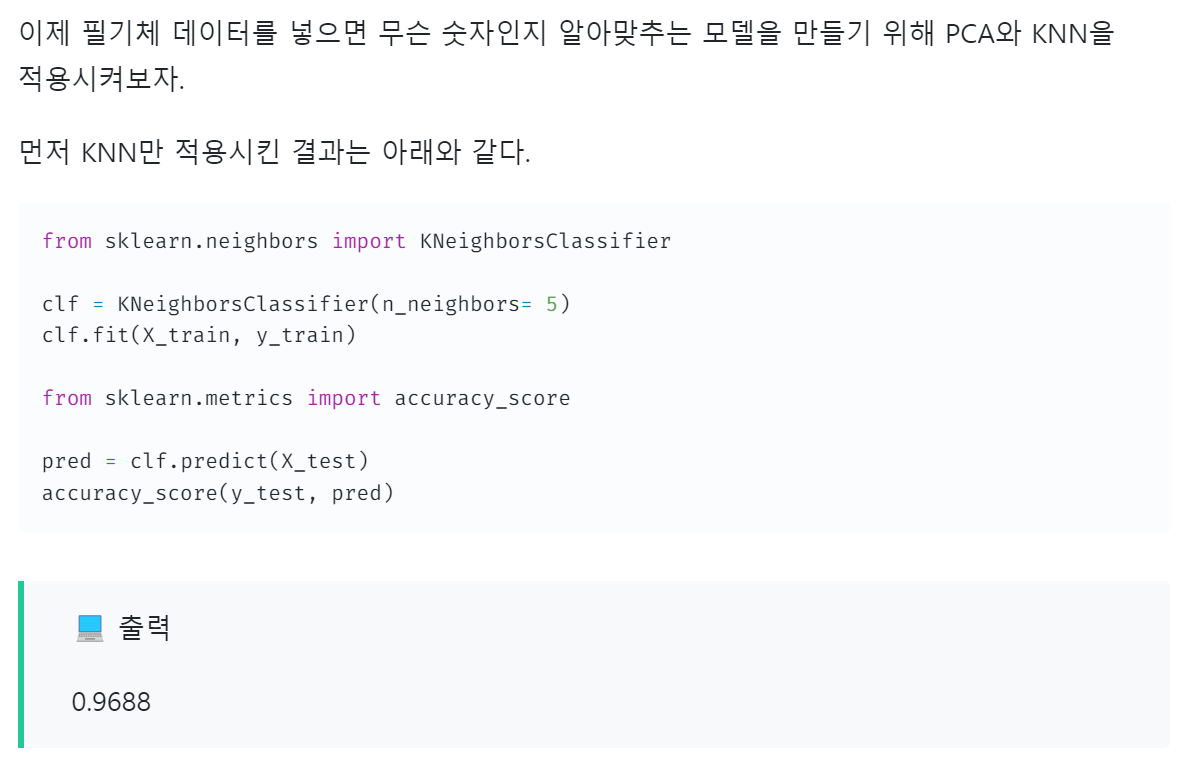
이번 모델은 위와 같은 구성을 가질 것이다. 이에 맞게 모델을 구성하면 아래와 같다.
📌 모델 구성 및 학습
# 모델링
model = tf.keras.models.Sequential([
# x_train[0].shape # (28, 28)
# (28, 28) 픽셀이 input_shape이 된다. 이를 1열로 쫙 펴준다.
tf.keras.layers.Flatten(input_shape = (28, 28)),
# 1000개의 노드를 거치자
tf.keras.layers.Dense(1000, activation='relu'),
# 0 ~ 9사이의 클래스 중 어디에 속할지 확인
tf.keras.layers.Dense(10, activation='softmax'),
])
model.compile(optimizer='adam', loss = 'sparse_categorical_crossentropy', metrics = ['accuracy'])
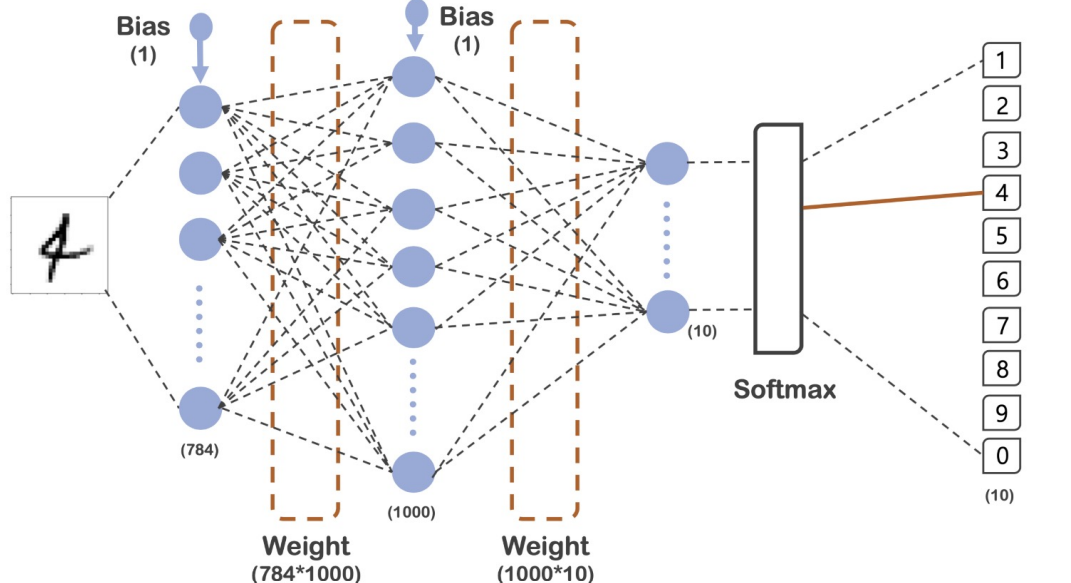
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=100, verbose=1)
accurcay도 거의 1에 가깝게 나오고 있다.
이 모델을 어떻게 사용할 수 있는지 한 번 살펴보자.
이 모델은 마지막에 softmax를 쓰고 있으므로 각 클래스에 해당하는 확률을 반환해준다.
# 예측
predicted_result = model.predict(x_test)
predicted_result[0] # 첫번째 데이터에 대한 predict 값💻 출력
array([1.5260557e-11, 4.0400780e-11, 4.4488035e-10, 1.2108550e-06,
2.6351195e-14, 3.2343700e-12, 1.9304675e-17, 9.9999881e-01,
2.2159567e-10, 3.5912335e-09], dtype=float32)
따라서 위와 같이 확률 값이 반환되는 것을 볼 수 있다.
여기서 확률값이 최대가 되는 클래스가 최종 예측값이 되는 것인데, 최대값의 위치를 반환해주는 argmax를 이용하면 편하다.
predicted_label = np.argmax(predicted_result, axis = 1)
wrong_result = []
for n in range(0, len(y_test)):
if predicted_label[n] != y_test[n]:
wrong_result.append(n) # 틀린 인덱스
len(wrong_result) # 틀린 값들 개수위와 같이 y_test와 비교하여 183개의 데이터가 틀렸다는 것을 알 수도 있고
import random
samples = random.choices(population=wrong_result, k = 16) # 틀린 것들 중 랜덤으로 몇 개만 살펴보자.
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(x_test[n].reshape(28, 28) , cmap = 'Greys')
plt.title('Label : ' + str(y_test[n]) + ' | Predict : ' + str(predicted_label[n]))
plt.axis('off')
plt.show()💻 출력

틀린 것들 중 랜덤으로 골라 실제 라벨과 예측값이 어떻게 다른지도 확인해볼 수 있다.
MNIST에서는 Fashion 관련 데이터도 있으니 관심있는 사람들은 한 번 해봐도 좋을 것 같다 :)
CNN
이전 영상처리를 하는 분야에서는 그림에 블러 처리를 한다던가 아니면 그림을 흑과 백의 그림으로 바꾸는 등의 필터를 적용하는 작업을 할 때에 픽셀 값의 변화(=미분값)를 계산하여 그 값의 변동이 심한 지점을 특징으로 잡아내는 작업들을 했었다.
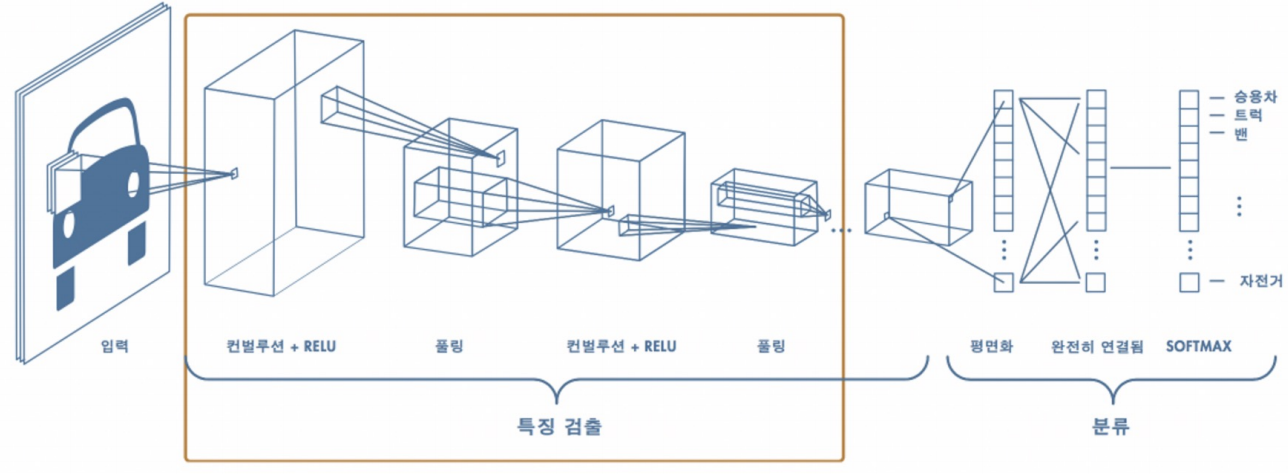
이런 작업들을 딥러닝에서 하기 위하여 미분값 즉 특징들을 계산해주는 파트와 이를 이용하여 클래스로 분류하는 분류 파트로 나누어진 작업이 바로 CNN이다.
Convolution Layer : 패턴들을 쌓아가며 점차 복잡한 패턴을 인식한다
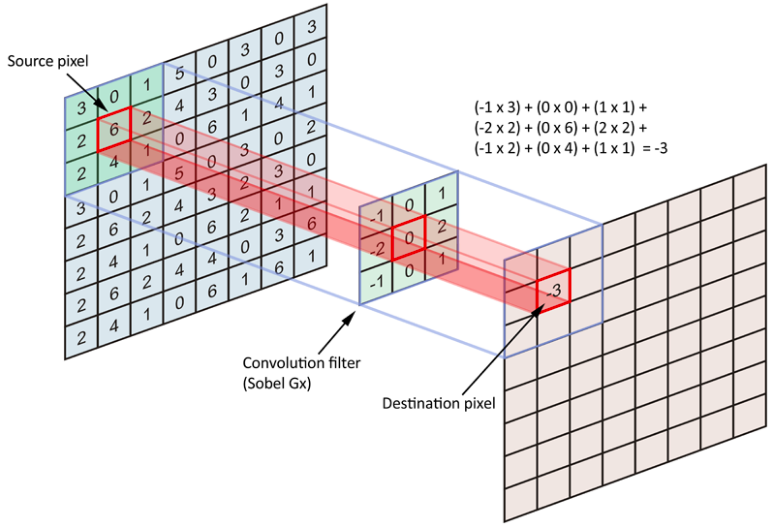 | 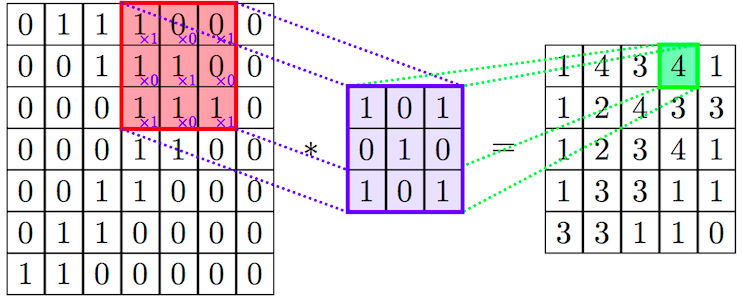 |
|---|
이때 계산된 필터를 Convolutional Filter라고 하는데 이를 직접 구할 수도, 학습을 통해 구할 수도 있다.
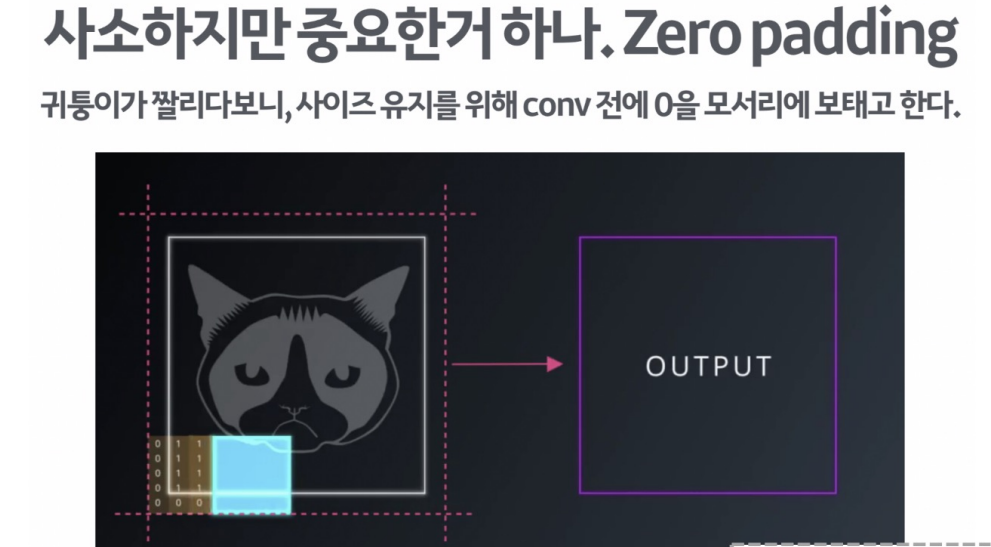
또한 이렇게 계산된 필터는 가장자리에 있는 데이터들이 짤리는 경우가 많아 사이즈를 유지하기 위해 conv 진행 전에 0을 모서리에 채우고 계산을 하는 zero padding 도 있다.
Pooling : 사이즈를 줄여가며, 더욱 추상화 해나간다
 |  |  |
|---|
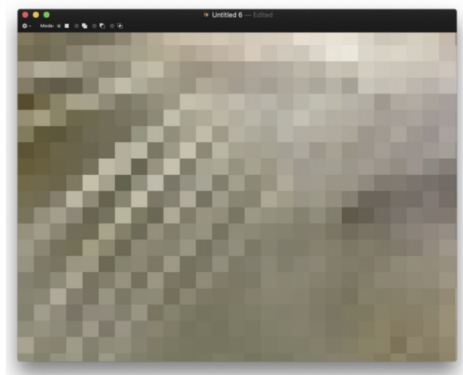
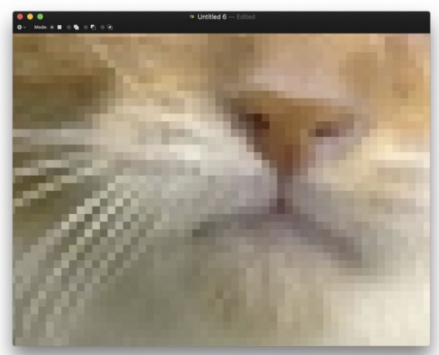
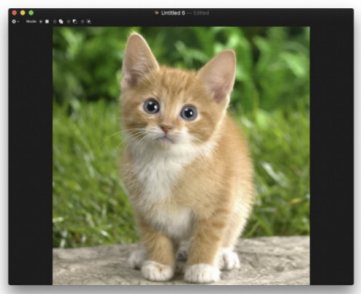
이미지를 너무 확대해서 보면 해당 그림이 무엇인지를 모를 수 밖에 없다. 이런 경우, 이미지와 거리를 두고 좀 멀리서 보면 해당 이미지가 무엇인지 알 수 있다.
딥러닝에게 "좀 멀리서 봐!"라는 메세지를 전달해주는 것이 Pooling이다.
Max Pooling
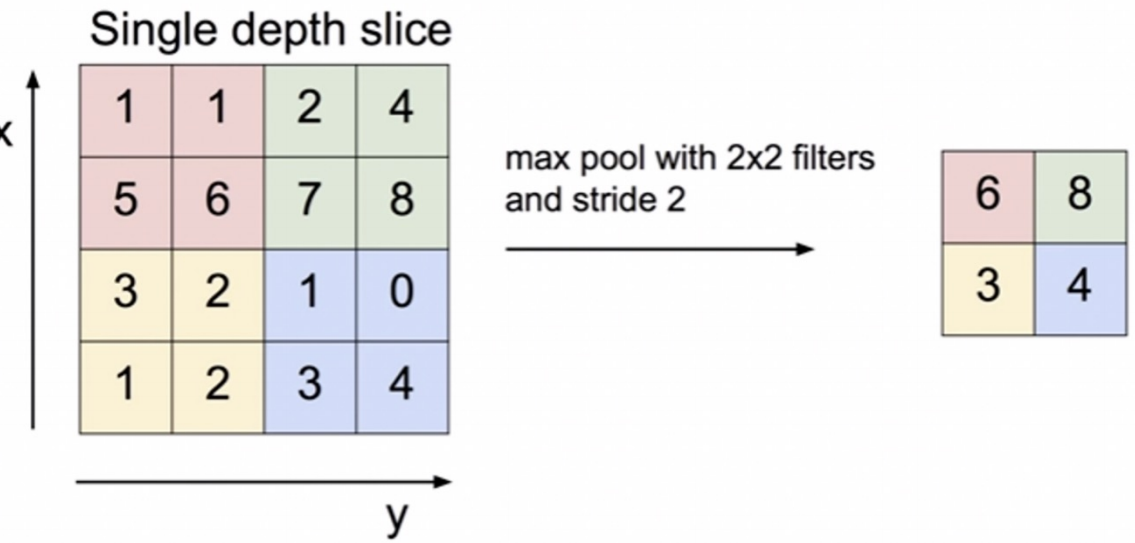
Pooling에도 여러 방법이 있는데 그 중 Max Pooling은 그룹 중 가장 큰 값을 대표값으로 정하여 계산하는 방법이다.
이때 그룹을 선택하는 옵션이 stride인데 해당 그림에서는 2를 선택했기 때문에 2칸 건너 뛰어서 다음 그룹이 결정된 것이다.
Dropout

Dropout은 모델에게 융통성을 좀 기르게 해주는 방법으로 학습을 시킬 때 일부러 정보를 누락시키거나, 중간 중간 노드를 끄는 것을 말한다.
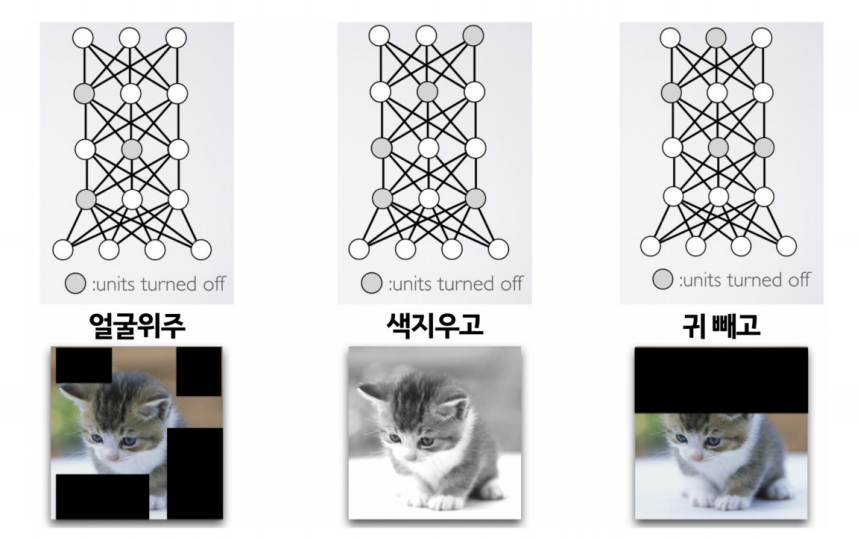
이런 과정을 거쳐 응용력을 길러주는 것이다.
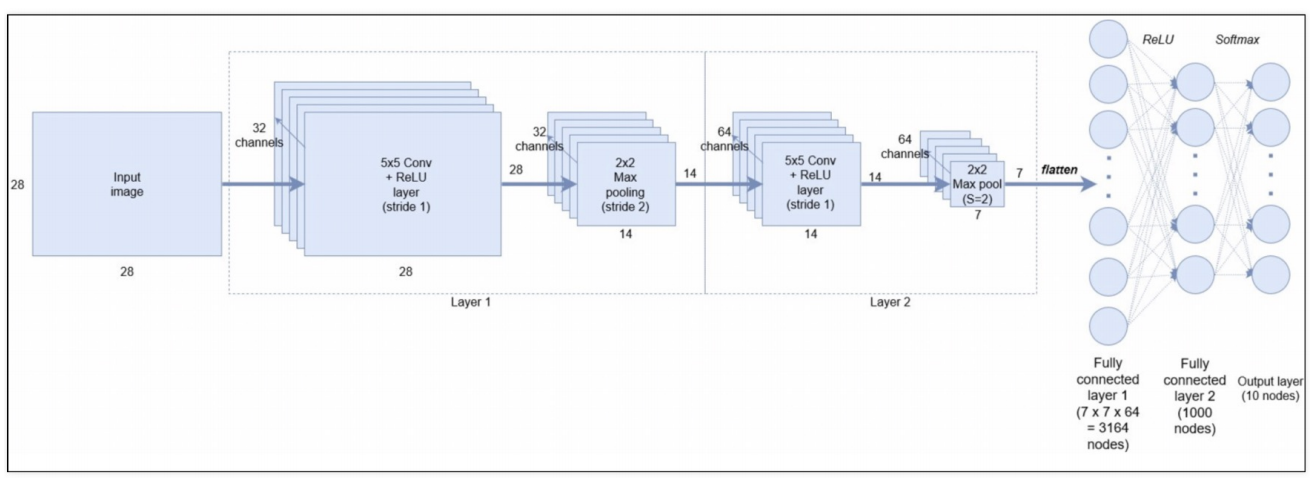
그렇다면 이제 위 모델을 한 번 코드로 짜보자.
# 데이터 준비
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255.0 , X_test / 255.0
# channel이 들어가므로 해당 차원과 맞춰주기 위한 reshape
# 기존 shape ((60000, 28, 28), (10000, 28, 28))
X_train = X_train.reshape((60000, 28, 28, 1))
X_test = X_test.reshape((10000, 28, 28, 1))
# 모델링
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, kernel_size = (5, 5), strides = (1, 1), padding = 'same', activation = 'relu',
input_shape = (28, 28, 1)),
layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2)),
layers.Conv2D(64, (2, 2), activation = 'relu', padding = 'same'),
layers.MaxPool2D(pool_size = (2, 2), strides = (2, 2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation = 'relu'),
layers.Dense(10, activation = 'softmax')
])
model.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy', metrics = ['accuracy'])
# 학습
hist = model.fit(X_train, y_train, epochs=5, verbose = 1, validation_data=(X_test, y_test))
# 모델 평가
score = model.evaluate(X_test, y_test) # loss: 0.0360 - accuracy: 0.9894
