
이전 포스트에서 테스트 해봤던 Ollama를 쫌 더 다양하게 활용하기 위해 Python에서 사용하는 실습을 진행해보았다. 이번에는 예제 코드를 활용한 간단한 기능한 구현해보고 앞으로 HuggingFace 모델 가져오기, LangChain과 함께 사용하기 등 추가 실습을 더 진행해볼 예정이다.
실습은 파이썬 가상환경을 만들어서 진행했고, 한국어로 사용할 수 있는 모델을 찾기 위해서 여러 모델들을 테스트 해보았다. 한국어 채팅은 Gemma의 성능이 가장 좋았다. 아래 실습에서는 여러 모델을 섞어서 진행하겠다.
- Llama2
- Mistral
- Solar
- Gemma
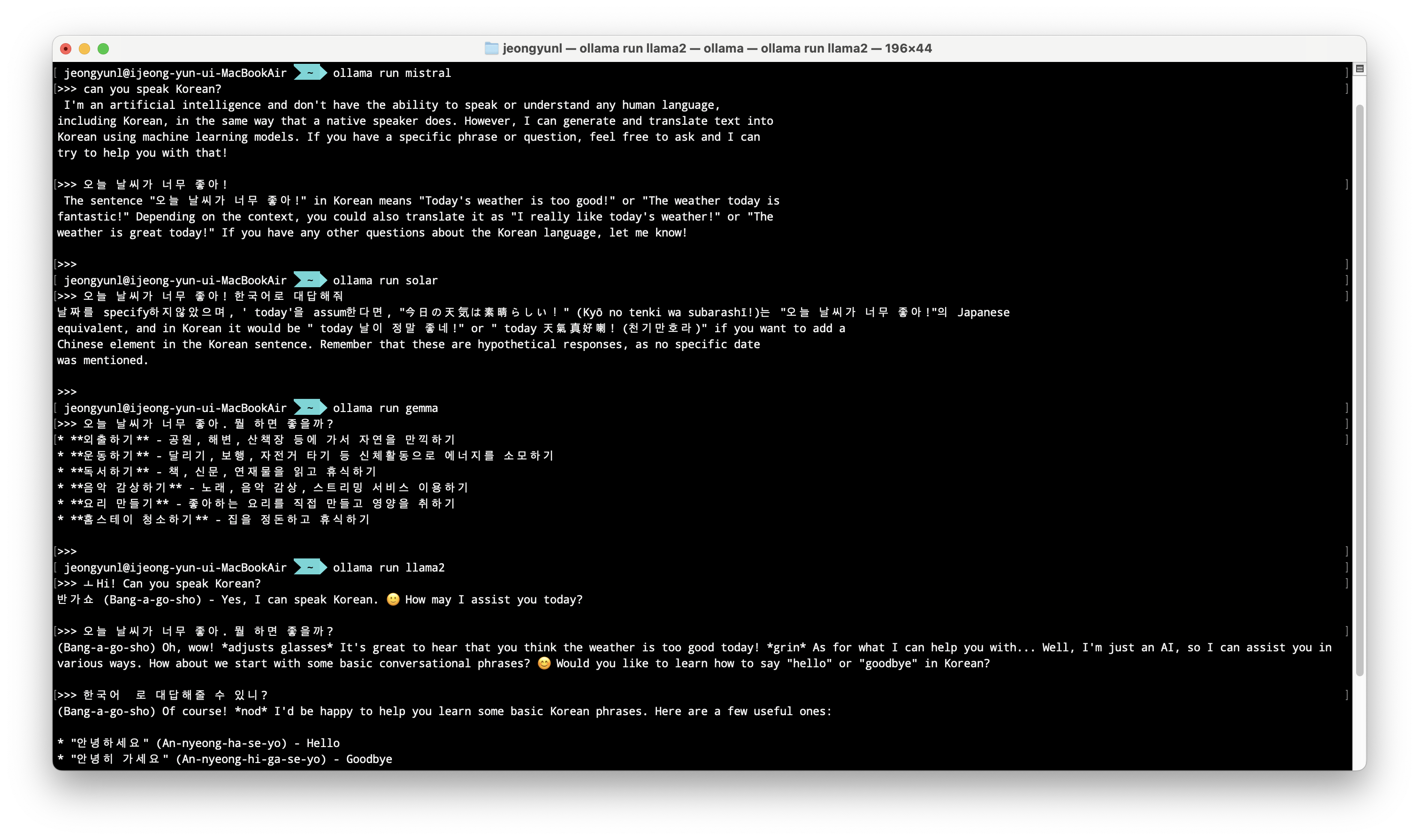
구글의 Gemma만 제대로된 답변을 주고 있다. (역시 따끈따끈한 모델..) Solar는 한국에서 만들었는데(Upstage) 학습할 때 한국어 데이터셋을 많이 안 포함 시킨 건지 왜 성능이..? (10.7B size 기준)
.
.
.
설치 및 세팅
파이썬에서 Ollama를 사용하는 방법은 공식 깃헙 에서 잘 설명해주고 있다.
pip install ollama우선 Ollama를 설치한다. (가상환경에서 진행하므로 이전에 terminal에서 설치해 준 것과 무관하게 다시 설치해줘야 한다)
import ollama
ollama.pull('llama2')ollama를 import하고 모델을 설치해준다. 터미널에서 ollama run gemma를 통해 모델을 다운로드하고 바로 실행할 수 있지만, python에는 모델을 pull해온다. ollama.list()를 통해서 설치한 모델 리스트를 확인할 수 있고 ollama.delete('llama2')를 통해 모델을 삭제할 수도 있다.
response = ollama.chat(model='solar', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])content에 input prompt를 작성하면 답변이 생성된다. model을 바꿔가면서 테스트해봤는데, 모델에 따라서 답변의 길이, 응답 특성 등이 살짝씩 달랐다.
임베딩 벡터 얻기 + 검색(with ChromaDB)
Ollama에 이 기능이 공개된 건 꽤 최근인 것 같은데, 답변을 출력할 뿐만 아니라 답변의 embedding vector를 제공한다는 것이다. 공식 문서에서는 RAG를 구축하는데 사용할 수 있다고 설명하고 있고 (1)임베딩 (2)DB저장 (3)검색 (4)답변생성 의 과정을 실습해볼 수 있는 예시를 제공한다. 코드는 모두 Ollama에서 제공한 것이며, 사용 모델만 내가 설치한 모델로 바꿔서 진행하였다.
ollama.embeddings(model='mistral', prompt='The sky is blue because of rayleigh scattering')위 코드를 실행하면 출력 결과로 답변과 함께 embedding vector가 나온다.
다음으로는 Ollama와 ChromaDB를 각각 사용해서 임베딩 벡터를 생성하고 저장한 뒤 검색하는 과정을 진행해보겠다.
pip install chromadb우선 ChromaDB를 설치한다.
import ollama
import chromadb
documents = [
"Llamas are members of the camelid family meaning they're pretty closely related to vicuñas and camels",
"Llamas were first domesticated and used as pack animals 4,000 to 5,000 years ago in the Peruvian highlands",
"Llamas can grow as much as 6 feet tall though the average llama between 5 feet 6 inches and 5 feet 9 inches tall",
"Llamas weigh between 280 and 450 pounds and can carry 25 to 30 percent of their body weight",
"Llamas are vegetarians and have very efficient digestive systems",
"Llamas live to be about 20 years old, though some only live for 15 years and others live to be 30 years old",
]
client = chromadb.Client()
collection = client.create_collection(name="docs2")
# store each document in a vector embedding database
for i, d in enumerate(documents):
response = ollama.embeddings(model="mistral", prompt=d)
embedding = response["embedding"]
collection.add(
ids=[str(i)],
embeddings=[embedding],
documents=[d]
)documents에는 임베딩을 진행한 문서를 넣어주고, embedding model은 mistral을 사용했다. 데이터양이 적어서 금방 실행된다.
# an example prompt
prompt = "What animals are llamas related to?"
# generate an embedding for the prompt and retrieve the most relevant doc
response = ollama.embeddings(
prompt=prompt,
model="mistral"
)
results = collection.query(
query_embeddings=[response["embedding"]],
n_results=1
)
data = results['documents'][0][0]prompt에 질문을 넣어주면 해당 질문의 답변을 얻을 수 있는 가장 유사한 문장을 documents에서 찾는다. (embedding vector로 가장 유사도가 높은 문장을 찾는 걸로 알고 있는데, 정확한 방법은 알지 못한다. 추후 Langchain과 함께 사용하는 부분에 추가하겠다)
output = ollama.generate(
model="mistral",
prompt=f"Using this data: {data}. Respond to this prompt: {prompt}"
)
print(output['response'])가장 유사성이 높은 문장을 찾아오는 것까지도 유용하지만, 그 문장을 가지고 다시 model에 넣어서 매끄러운 답변을 생성하는 과정이다.
여기까지 하면 거의 ChatGPT와 같은 모델을 뚝딱 만들어 낸 것이다! 좀 더 많은 기능들을 붙이거나 미세한 조정(chunk size 조정 등) LangChain을 사용하는 것이 유용하겠지만, 이렇게 간단한 작업은 각각 불러와서 진행해도 충분할 것 같다.
참고자료

pip 으로 ollama 패키지 설치하면 터미널 기반 ollama도 따라와서 설치가 되는걸까요??