이번 포스팅은 RNN의 아주 기초적인 부분에 대해 공부해보려고 합니다.🚀 앞으로 NLP 분야를 공부할 예정이니 기본기를 탄탄하게 쌓는 포스팅이 되면 좋겠군요!
해당 포스팅은 Reference에 있는 일러스트로 설명하는 RNN 포스팅을 바탕으로 번역하여 정리했음을 밝힙니다.
Reference
📄 Illustrated Guide to Recurrent Neural Networks
What are RNN’s?
RNN 아이디어의 시작은 sequential information의 이용이었습니다. 전통적 신경망에서는 모든 inputs과 outputs이 서로 독립적이라 가정합니다.
그러나 많은 task에서 이 가정이 좋지는 못했습니다. 예를 들어, 문장에서 단어를 예측하려면 그 앞에 어떤 단어가 왔는지를 알아야 더 잘 예측할 수 있습니다.
RNN에는 sequence의 모든 요소에 대해 동일한 작업을 수행하여 recurrent라고 합니다.
RNN은 음성 인식, 언어 번역, 주식 예측 등에도 사용되고 이미지 인식에서 사진의 내용을 설명하는데도 사용됩니다.
RNN에 대한 내용을 다루기 전 Sequence Data와 Sequential Memory에 대해 다루고 가겠습니다.
Sequence Data
RNN은 sequence data 모델링에 능숙합니다. 그건은 무엇을 의미할까요?
시간에 따라 움직이는 공의 스틸 스냅샵을 찍는다고 가정하겠습니다.

공이 움직이는 방향을 예측해보고 싶은데요. 위의 이미지만 가지고 어떻게 예측할 수 있을까요?
어떤 방향으로 가겠다는 추측은 결국 랜덤한 추측이 될 것입니다. 공이 어디서부터 어떻게 왔는지에 대한 지식이 없다면 어디로 가는지 예측하기 어렵습니다.
공의 위치를 스냅샷으로 연속적으로 기록하면 더 나은 예측을 할 수 있는 데이터가 생깁니다.

이건 하나의 sequence라고 볼 수 있습니다.
하나가 그 다음 것을 뒤따르는 순서가 있기 때문인데요. 이제 이 정보를 통해서 공이 오른쪽으로 움직인다는 정보를 얻었습니다.
sequence data는 다양한 형태로 제공됩니다.
오디오도 natural sequence data입니다. 오디오를 spectrogram으로 잘라서 RNN에 제공할 수도 있습니다.
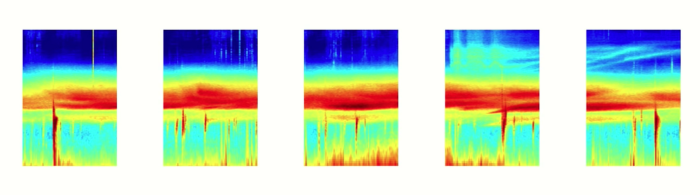
오디오 뿐만 아니라 텍스트도 시퀀스의 또 다른 형태입니다. 텍스트를 일련의 문자 또는 일련의 단어로 나눌 수 있습니다.
Sequential Memory
RNN은 이런 sequence data를 잘 처리한다고 했는데요. 그 처리를 도와주는 것이 Sequential Memory입니다.

이건 누가봐도 알파벳입니다. 그리고 이 알파벳을 처음부터 끝까지 읽을 수 있습니다.
이제는 알파벳을 거꾸로 읽어보겠습니다.

설마 바로 나오나요? 바로 나오지 않습니다.
그 이유는 이미 a-z의 순으로 알파벳을 배웠기 때문인데요. 거꾸로 읽는 sequence는 연습한 적이 없습니다.
그렇다면 여기에 문자 가 있습니다.

처음에는 어려울 수 있지만, 패턴을 파악한다면 나머지는 자연스럽게 나옵니다.
Sequential memory는 sequence patterns을 더 쉽게 인식하도록 하는 mechanism입니다.
Recurrent Neural Networks
RNN은 sequential memory에 대한 추상적인(abstract) 개념을 갖고 있습니다. RNN은 이 개념을 어떻게 기억할까요?
feed-forward neural network라 불리는 다시 전통적인 신경망 구조를 살펴보겠습니다.
이는 input layer, hidden layer, output layer의 3가지 layer를 갖고 있습니다.
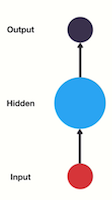
previous information를 사용하여 later information에 영향을 주는 feed-forward neural network를 가지려면 어떻게 해야 할까요?
여기서 previous information를 전달 할 수 있는 loop를 신경망에 추가합니다.
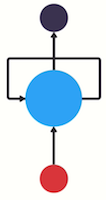
이게 RNN이 하는 일입니다. RNN은 one step에서 next step으로 흐르는 고속도로 역할을 하는 looping mechanism을 갖고 있습니다.
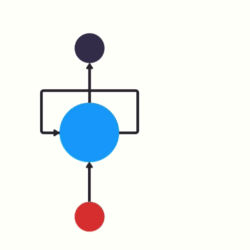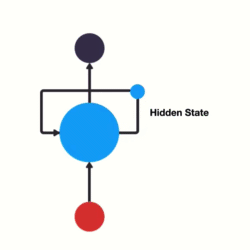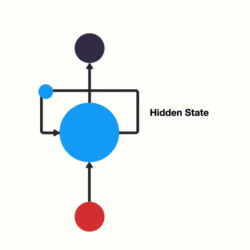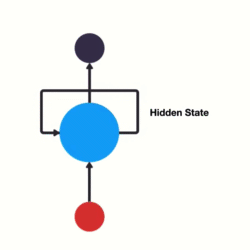
이 정보는 이전 입력값을 표현하는 hidden state입니다. 어떻게 작동하는지 더 잘 이해하기 위해 RNN 사용 사례를 살펴보겠습니다.
챗봇을 만드는 걸 가정해 봅니다. 챗봇은 사용자가 입력한 텍스트를 기반으로 의도를 분류할 수 있다고 가정합니다.

이 task를 위해 RNN을 사용해서 text squence를 encode합니다.
그 다음 RNN의 출력을 분류하기 위해 feed-forward neural network에 공급합니다.
사용자가 입력합니다.
What time is it?
시작하려면 문장을 개별 단어로 나눕니다. RNN은 순차적으로 작업하기 때문에 한 번에 한 단어씩 공급합니다.
'What', 'time', 'is', 'it', '?'

첫 번째 단계는 'What'을 RNN에 입력하는 것입니다. RNN은 'What'을 encode하고 output을 만듭니다.
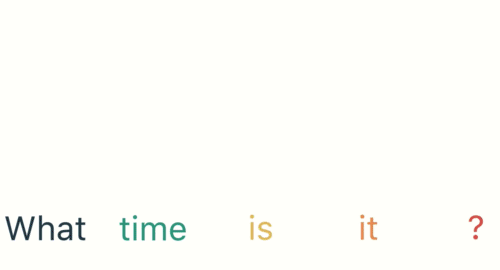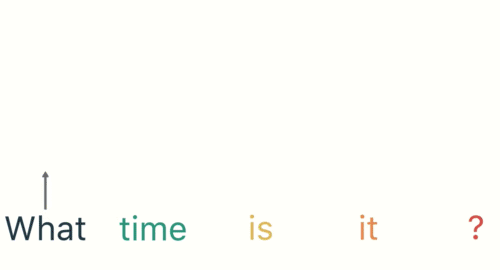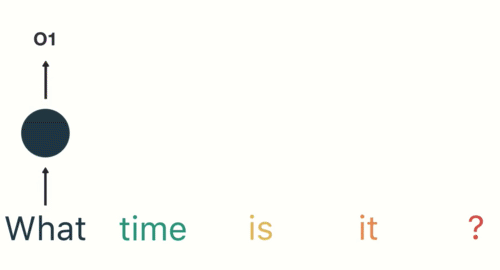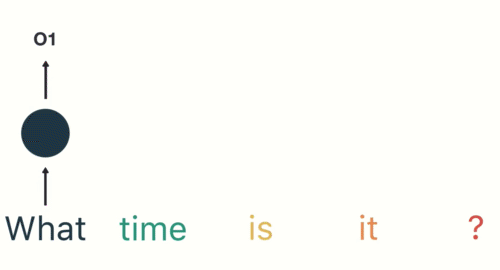
다음 단계를 위해 'time'이란 단어와 이전 단계의 hidden state을 제공합니다.
RNN은 이제 'What'과 'time'의 단어에 대한 정보를 갖고 있습니다.
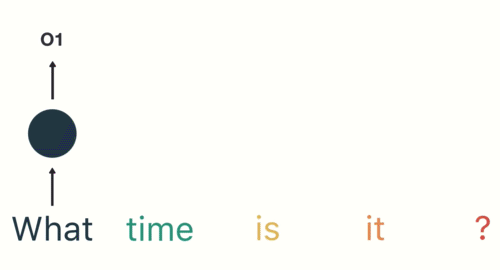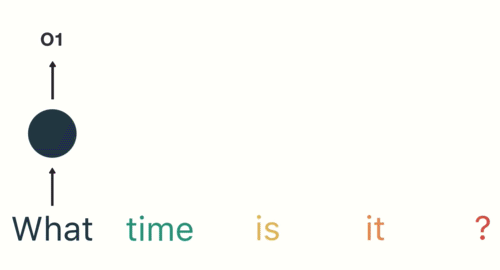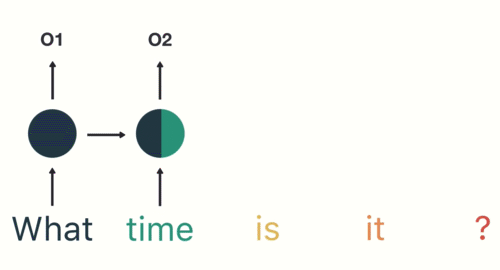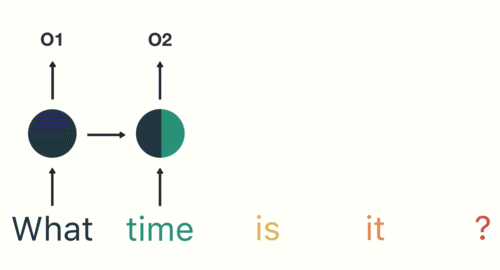
해당 과정을 마지막 단계까지 반복합니다.
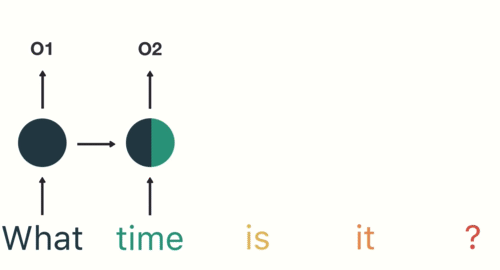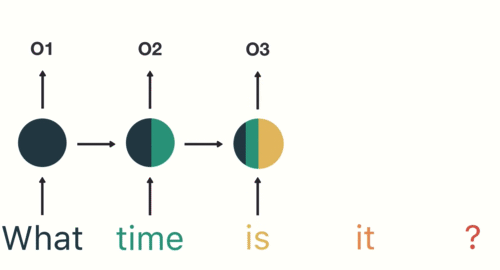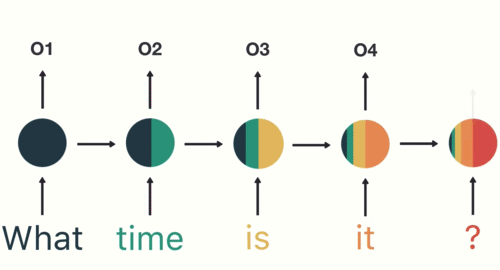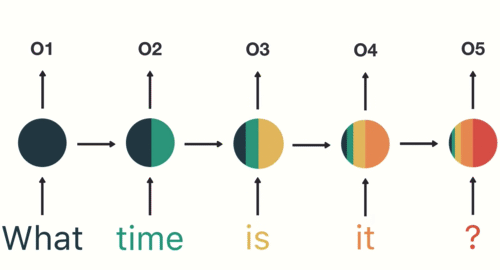
마지막 단계에서 RNN은 이전 단계의 모든 단어에서 정보를 encoding 했음을 알 수 있습니다.
최종 출력은 나머지 sequence에서 생성되었으므로 최종 출력을 가져와서 feed-forward layer에 전달하여 의도를 분류해야 합니다.
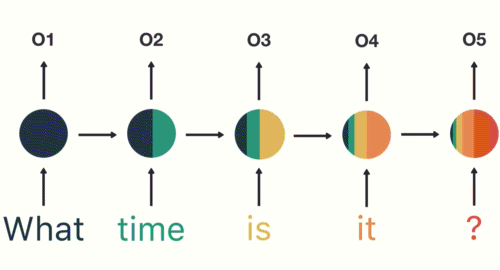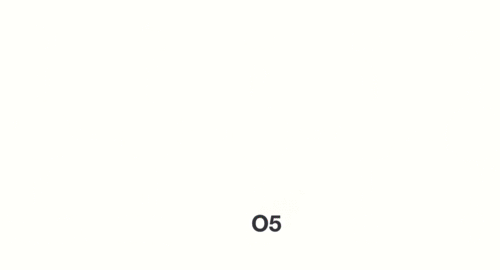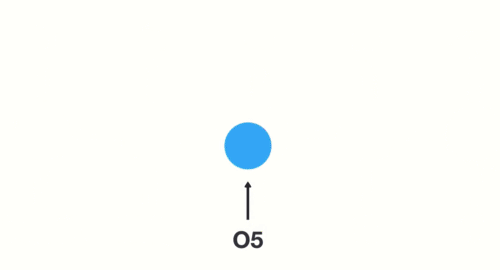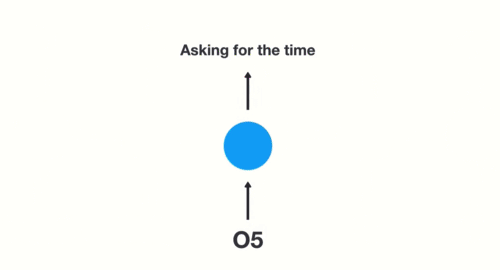
Asking for the time
rnn = RNN()
ff = feedForwardRNN()
hidden_state = [0.0, 0.0, 0.0, 0.0]
for word in inputs:
output, hidden_state = rnn(word, hidden_state)
prediction = ff(output)*Pseudo code for RNN control flow
먼저 network layer와 초기 hidden state를 초기화합니다.
hidden state의 모양과 차원은 RNN에 따라 달라집니다. 그 다음 입력을 반복하고 단어와 hidden state를 RNN에 전달합니다.
RNN은 출력과 hidden state를 반환합니다.
끝날 때까지 반복합니다. 마지막 출력을 feed-forward layer에 전달하면 예측값이 나오게 됩니다.
short-term memory
hidden state에서 이상한 색상 분포를 발견할 수 있습니다.
이를 short-term memory라고 부른다고 하네요.

*Final hidden state of the RNN
short-term memory는 다른 neural network에서도 흔히 볼 수 있는 vanishing gradient 문제로 인해 발생합니다.
RNN이 더 많은 단계를 처리할 때마다 이전 단계의 정보를 유지하는데 문제가 생깁니다. 'What'과 'time'이라는 단어의 정보는 마지막 단계에서 거의 존재하지 않습니다.
short-term memory와 vanishing gradient의 문제는 신경망을 훈련하고 최적화하는데 사용하는 알고리즘인 backpropagation의 특성 때문에 생깁니다.
그 이유를 이해하기 위해 deep feed-forward neural network에 대한 backpropagation 영향을 살펴보겠습니다.
neural network의 training에는 3가지 주요 단계가 있습니다.
- forward pass를 수행하여 예측합니다.
- loss function을 사용해서 예측과 정답 비교
- loss function은 network가 얼마나 잘못 수행하고 있는지에 대한 추정치로 오류값을 출력합니다.
- 해당 error 값을 사용해 각 network node에 대한 gradient를 계산하는 backward pass를 수행합니다.
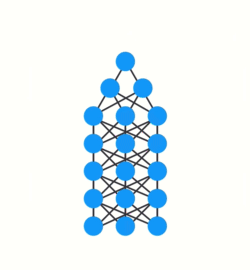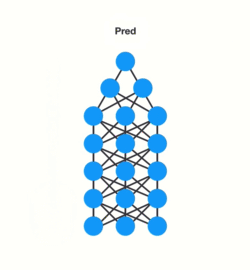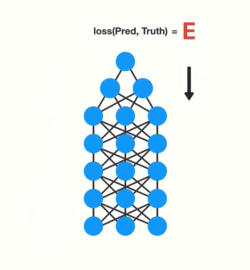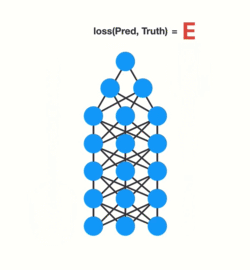
gradient는 network가 학습할 수 있도록 weight을 조정하는데 사용하는 값입니다.
backpropagation을 수행할 때, 각 layer의 node들은 이전 layer의 gradient에 대한 gradient를 계산합니다.
따라서 이전 layer의 값이 작으면 현재 layer에 대한 값은 더 작아집니다.
이로 인해 gradient가 다시 아래로 전달됨에 따라 기하급수적으로 작아집니다.
초기 layer는 weights들이 작아진 gradient로 거의 update되지 않아서 제대로 된 학습을 수행하지 못합니다.
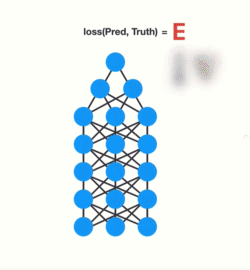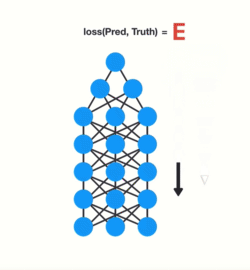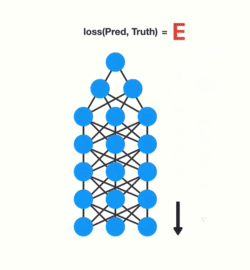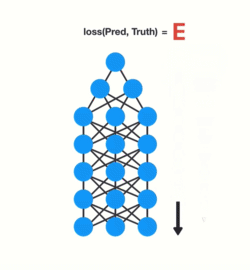
RNN에서도 각 time step이 network의 layer라 볼 수 있습니다.
RNN을 훈련하면서 각 time step로 전달되면서 점점 축소됩니다.
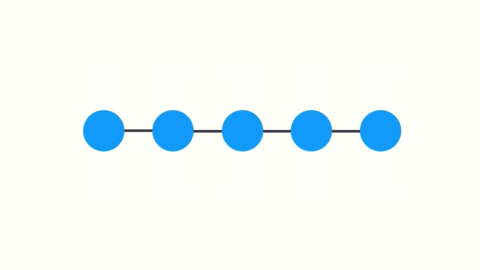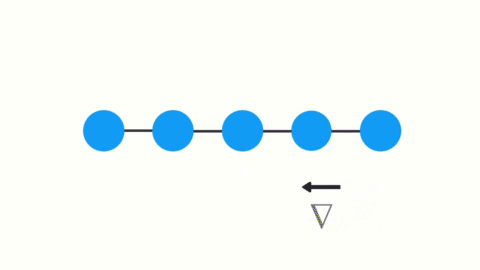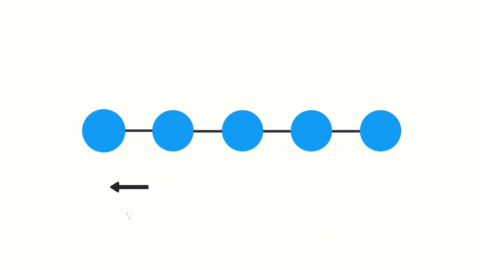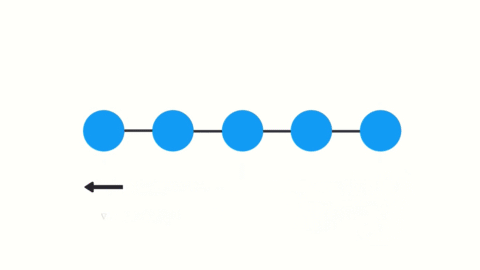
gradient가 weights을 update하는 역할을 수행하기 때문에, 작은 gradient는 작은 update를 만들고 초기 layer가 학습하지 못하게 만들어 버립니다!
기울기가 사라지면 RNN은 시간 단계에 걸쳐 long-range dependencies를 학습하지 못합니다.
아까 예시를 들었던 챗봇이 network가 short-term memory를 갖게 돼서 사용자의 목적인 'What'과 'time'이란 단어를 고려 못하게 되는 겁니다.
Long Short-Term Memory(LSTM)
RNN은 short-term memory를 갖습니다. 그래서 단기 기억 상실증을 완화하기 위해 두 개의 특수한 RNN이 만들어졌습니다.
그게 바로 Long Short-Term Memory, 줄여서 LSTM이라 부르는 것입니다.
다른 하나는 Gated Recurrent Units, GRU입니다.
두 개는 기본적으로 같은 기능을 하지만 'gate'라는 mechanism을 사용하여 long-term dependencies을 학습합니다.
gate는 hidden state에 추가하거나 제거할 정보를 학습할 수 있는 tenrsor 작업이며, 이 능력으로 단기 기억상실증이 완화됩니다.
LSTM은 다음 게시글에서 다루도록 하겠습니다!
Summary
번역한 포스팅에서는 RNN을 뒤늦게 That wasn’t too bad이라 포장합니다.
RNN은 예측하기 위한 sequence data를 처리하는데는 좋지만 단기 기억 상실증을 갖고 있었는데, 그렇다고 무조건 LSTM이나 GRU를 사용하라는 게 아니라고 합니다.
RNN은 training time이 빠르고 computing resource를 덜 사용하는 장점이 있습니다.
계산할 연산이 더 적기 때문인데요.
long-term dependencies가 있는 더 긴 sequence를 모델링한다면 LSTM이나 GRU 사용을 권장합니다.

와 rnn에 대한 설명과 더불어 vanishing gradient에 대한 설명이 너무 좋네요...😭 감사합니다!!