이번 포스팅은 LSTM의 아주 기초적인 부분에 대해 공부해보려고 합니다.🚀 앞으로 NLP 분야를 공부할 예정이니 기본기를 탄탄하게 쌓는 포스팅이 되면 좋겠군요!
해당 포스팅은 Reference에 있는 일러스트로 설명하는 LSTM 포스팅을 바탕으로 번역하여 정리했음을 밝힙니다.
Reference
🔗 Illustrated Guide to LSTM’s and GRU’s: A step by step explanation
Short-term Memory의 문제
Recurrent Neural Networks는 Short-term Memory 문제를 갖습니다.
sequence가 매우 길면 이전 time step에서 다음 step으로 정보를 전달하는데 어려움을 겪습니다.
따라서 예측을 수정하기 위해 텍스트의 단락을 처리하려고 할 때, RNN은 초기의 중요 정보를 생략할 수 있습니다.
backpropagation하는 동안 RNN은 vanishing gradient 문제를 겪는데요. gradient 값이 작아지며 학습에 대한 기여도가 낮아집니다.

위는 gradient update 규칙입니다.
따라서 RNN에서 작은 gradient를 update 받는 layer는 학습을 중지합니다.
RNN이 긴 sequence에서 본 것을 잊는 Short-term Memory 문제에 대해 살펴보았습니다.
그 솔루션으로 나온 것이 LSTM과 GRU입니다.
Long Short-Term Memory(LSTM)
gate는 sequence에서 어떤 data를 보관하거나 버려야 하는지 학습할 수 있습니다.
그렇게하면 관련 정보를 긴 sequence chain으로 전달하여 예측할 수 있습니다.
RNN 기반의 최신 연구는 이 두 네트워크로 이용이 된다고 합니다.
LSTM 및 GRU는 음성 인식, 음성 합성 및 텍스트 생성, 비디오 캡션 생성 등에 이용됩니다.
Intuition
한 가지 실험을 해본다고 합니다.
당신은 시리얼을 사기 위해 온라인에서 리뷰를 보고 있습니다.
먼저 리뷰를 읽고 그 다음에 그 리뷰를 좋게 생각했는지 아닌지를 결정합니다.

리뷰를 읽으면 뇌는 무의식적으로 중요 키워드만 기억합니다.
아마 머릿속에는 "Amazing", "perfectly balanced breakfast" 등의 중요한 키워드만 떠오를 것이고
“this”, “gave“, “all”, “should” 같은 단어는 별로 신경도 안 쓸 겁니다.
친구가 다음날 시리얼 리뷰는 어땠냐고 묻는다면 "will definitely be buying again" 정도가 떠오를 것입니다.

그리고 이것이 LSTM과 GRU가 하는 일입니다. 예측을 위해 관련된 정보만 유지하고, 관련 없는 정보는 잊어버리는 학습을 합니다.
이 경우 기억나는 단어가 좋았는지 판단을 하게 만듭니다.
Review of Recurrent Neural Networks
RNN을 다시 살펴보겠습니다.
RNN은 아래 그림처럼 작동합니다. 첫 단어는 기계가 읽을 수 있는 vector로 변환됩니다. 그 다음 vector sequence를 하나씩 처리합니다.
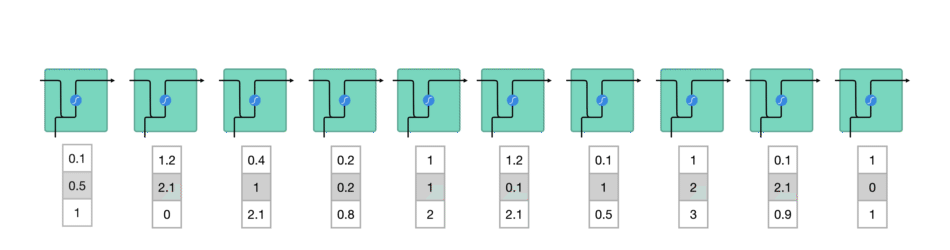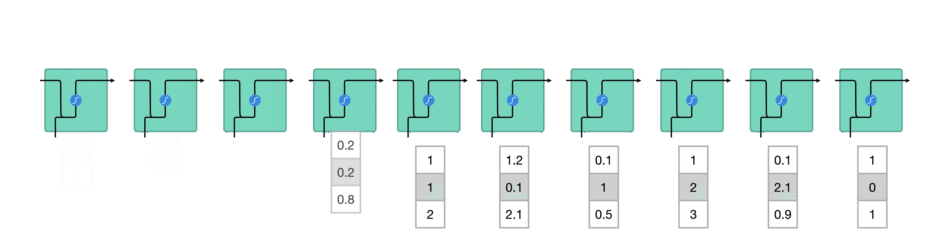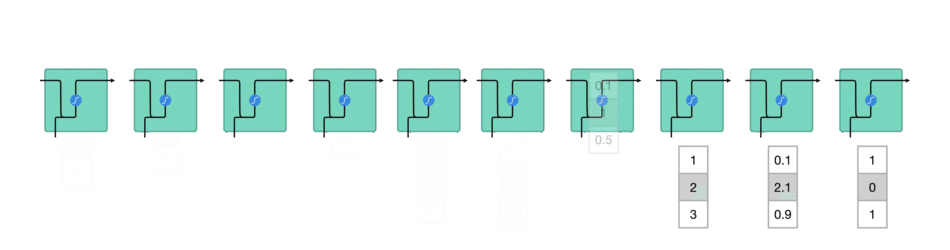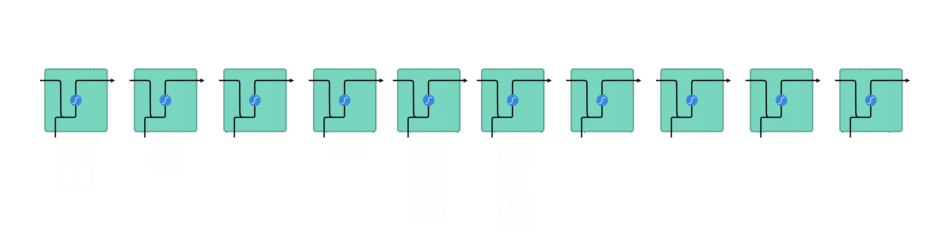
처리하는 동안 이전 hidden state를 sequence의 다음 단계로 전달합니다.
hidden state는 neural network의 memory 역할을 합니다.
network가 이전에 본 이전 data에 대한 정보를 보유합니다.
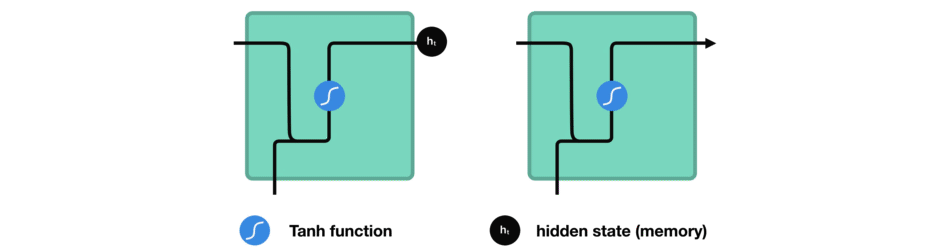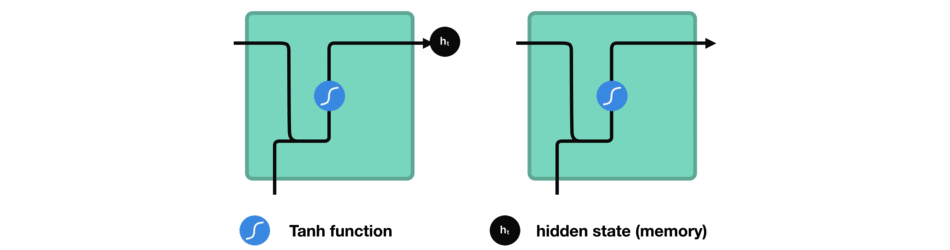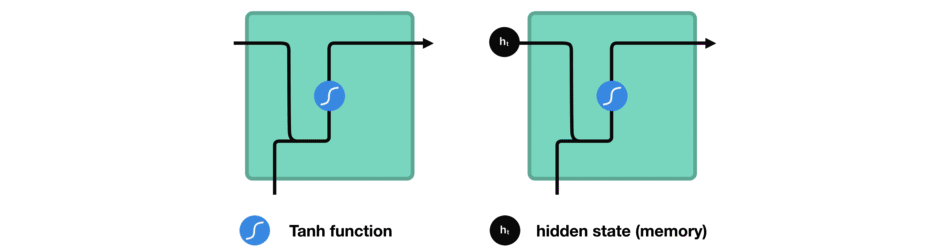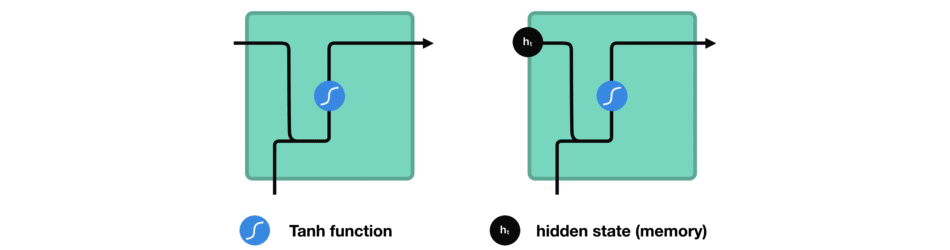
hidden state를 계산하는 방법을 보기 위해 RNN의 cell을 살펴보겠습니다.
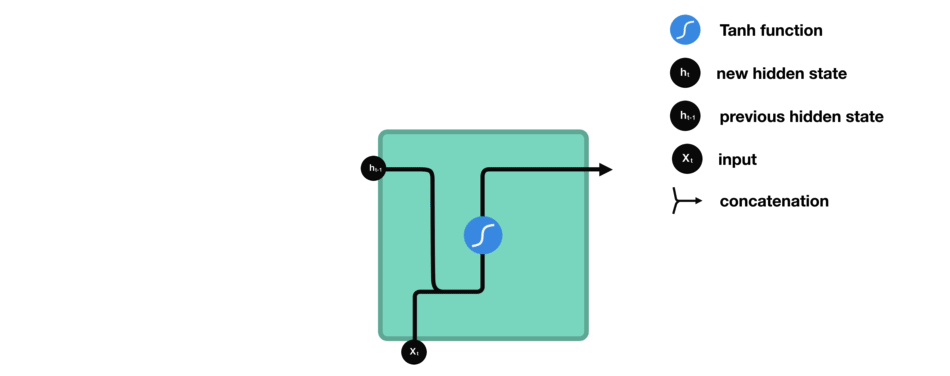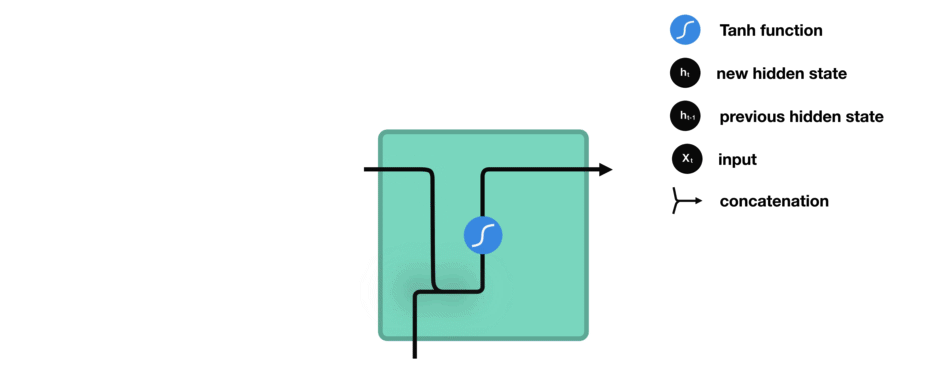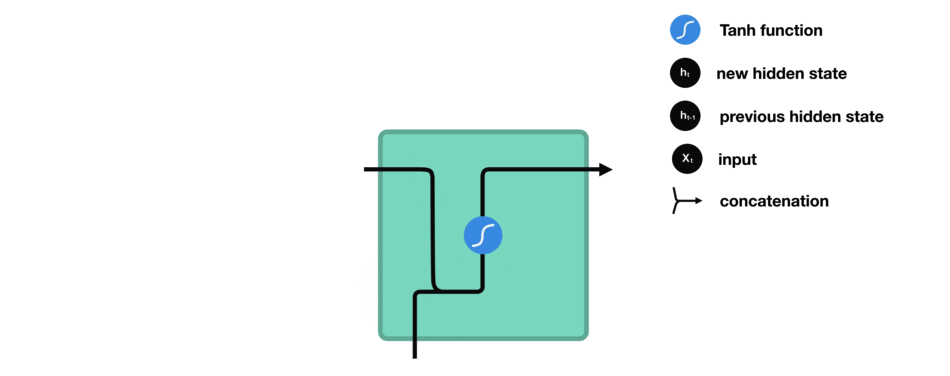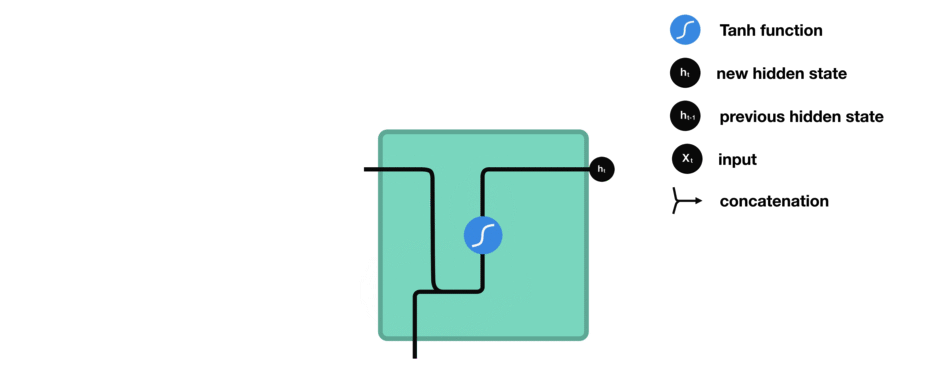
입력과 이전 hidden state를 결합하여 vector를 형성합니다. 해당 vector에는 현재 입력과 이전 입력에 대한 정보가 있습니다.
vector는 activation을 거쳐서 출력은 새로운 hidden state 또는 network의 memory입니다.
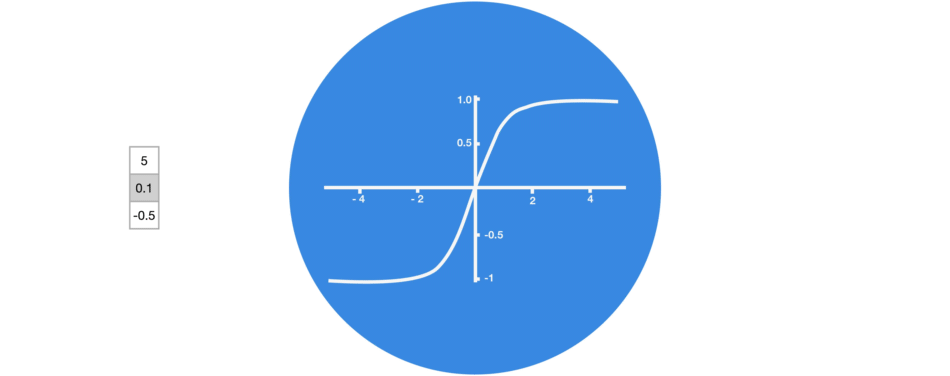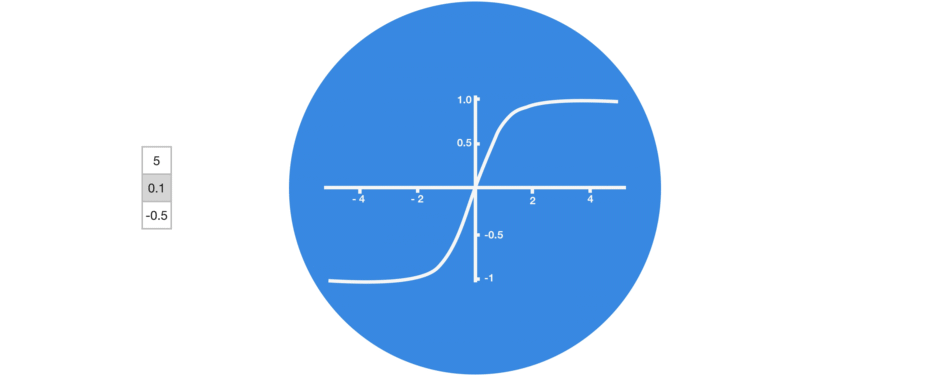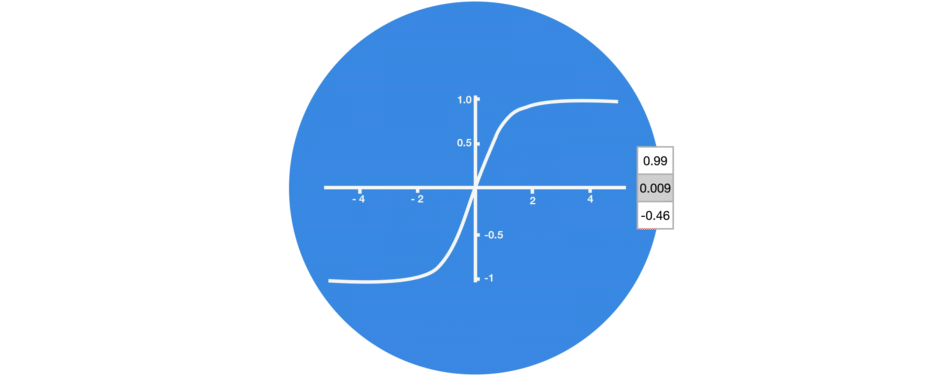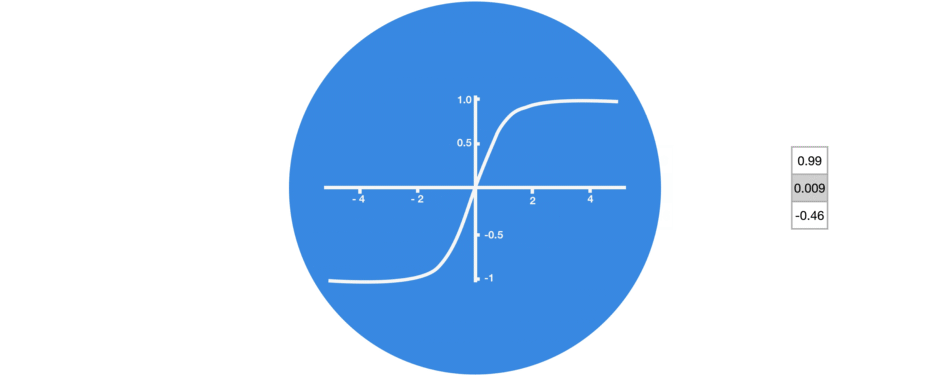
tan h
tan h는 network를 통해 흐르는 값을 조절하는데 사용됩니다.
tan h의 함수는 출력 값이 항상 [-1, 1]이 되도록 압축합니다.
vector는 neural network를 통과할 때 다양한 연산을 거쳐 많은 변형을 겪습니다.
계속해서 3을 곱한다고 가정해봅시다. 일부 값이 폭발적으로 증가하여 다른 값이 무의미해질 수 있습니다.

*vector transformations without tanh
tan h가 없는 vector의 변형과 tan h가 있는 vector의 변형을 비교해보세요.

*vector transformations with tanh
tan h가 -1과 1 사이를 유지하도록 하여 neural network의 출력을 조절합니다.
tan h가 허용하는 경계 사이에 위와 같은 값이 어떻게 유지되는지 눈으로 확인할 수 있습니다.
이게 RNN이 작동하는 방식이며 short sequence에서는 잘 작동합니다.
LSTM과 GRU의 경우, 훨씬 적은 계산 리소스를 사용한다고 합니다.
이제 살펴보겠습니다.
LSTM
LSTM은 RNN과 유사한 제어 흐름을 갖고 있습니다. 정보가 전달될 때 전달되는 데이터를 처리합니다.
차이점은 cell 내의 작업인데요.
RNN
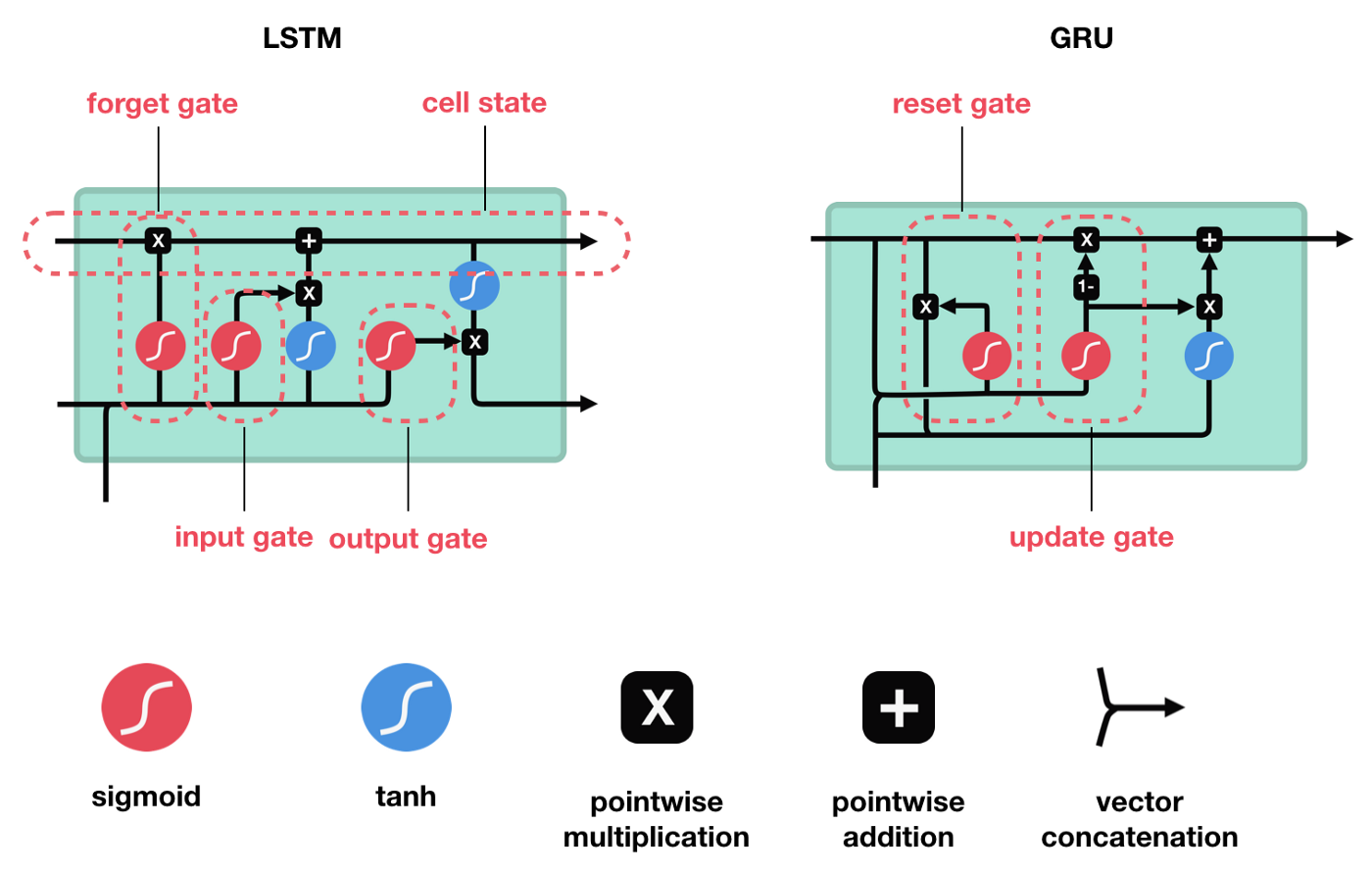
LSTM cells and Operations
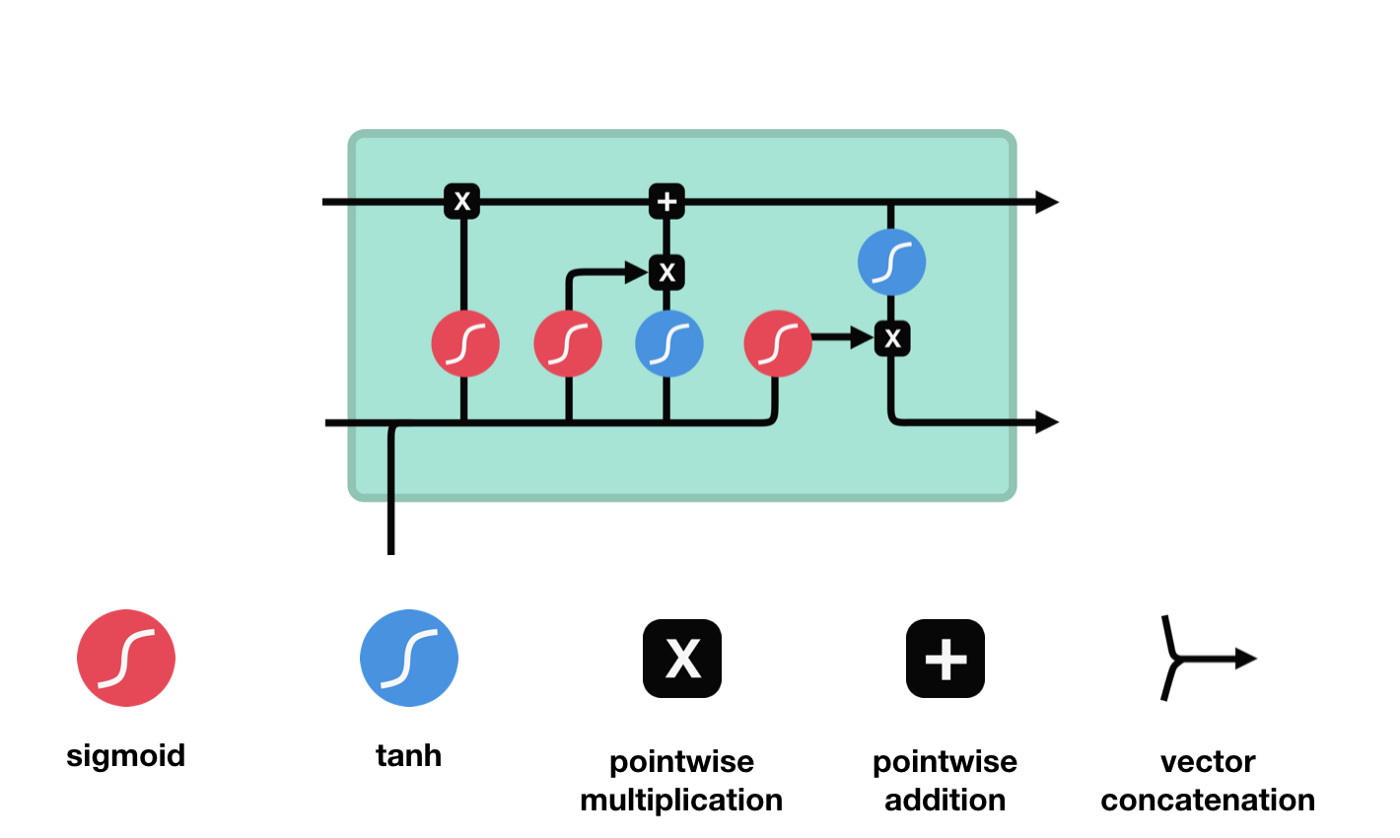
이 작동은 LSTM이 정보를 유지하거나 잊어버릴 수 있도록 하는데 사용되고, 이 단계를 하나씩 살펴보겠습니다.
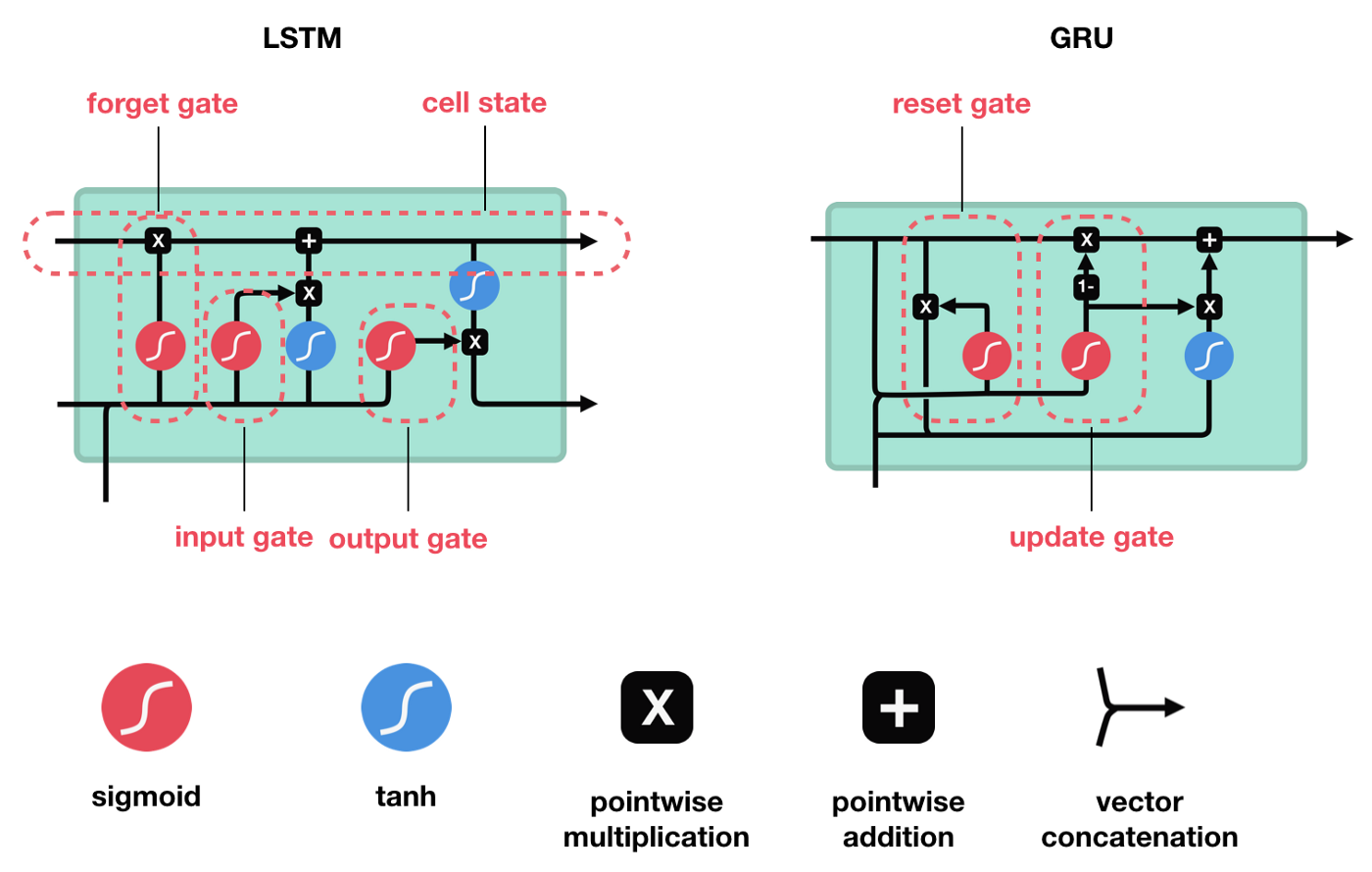
ⅰ) 핵심 개념
LSTM의 핵심 개념은 cell state와 various gates입니다.
cell state는 sequence chain 아래로 정보를 전달하는 고속도로 역할을 합니다. 네트워크의 'memory'라고 볼 수 있습니다.
이론적으로는 cell state는 sequence 처리 전반에 걸쳐 관련 정보를 전달할 수 있습니다.
따라서 이전 time step의 정보여도 이후 time step에 이동하여 short-term memory의 영향을 줄입니다.
cell state가 진행됨에 따라 정보는 gate를 통해 cell state에 추가되거나 제거됩니다.
gate는 cell state에 대해 허용되는 정보를 결정하는 다양한 neural network입니다. training 중 유지하거나 잊어야 할 정보가 무엇인지를 학습합니다.
ⅱ) Sigmoid
gate는 sigmoid activations을 포함합니다. sigmoid activation은 tanh activation과 비슷한데요.
-1과 1 사이로 squash하는 대신에 0과 1 사이의 값으로 squash합니다.
data를 'update'하거나 'forget'할 때 유용합니다. 그 이유는 0을 곱한 숫자는 0이 되어 값이 사라지거나 'forgotten' 잊어버리게 돼서입니다.
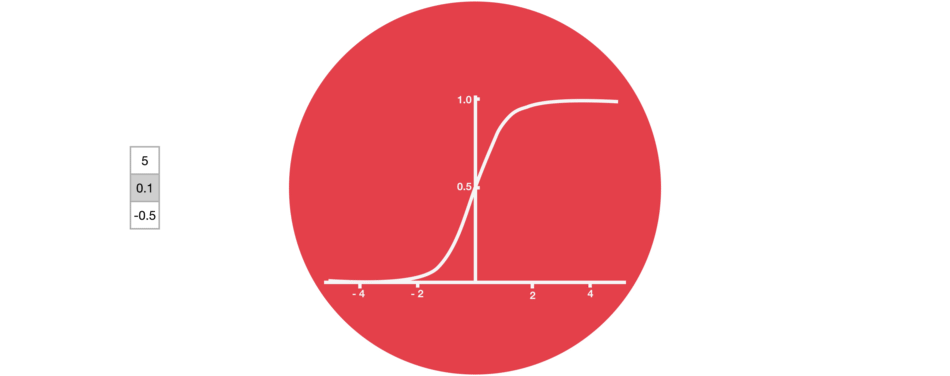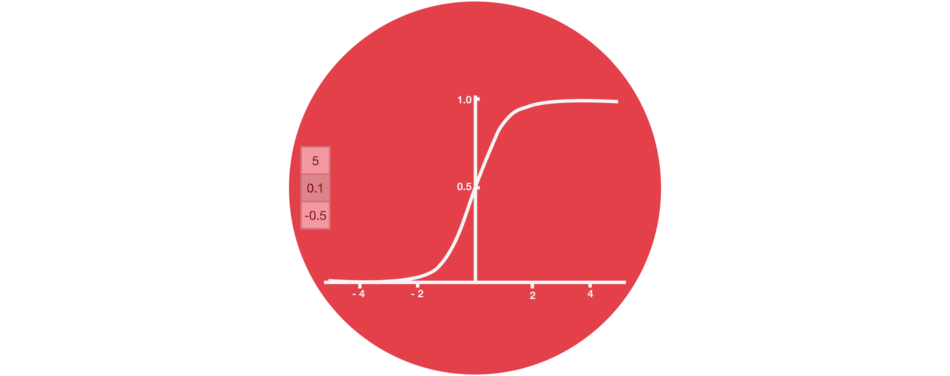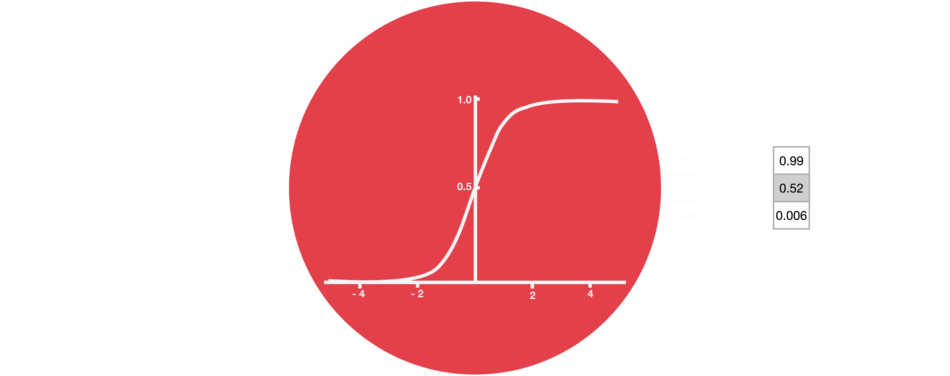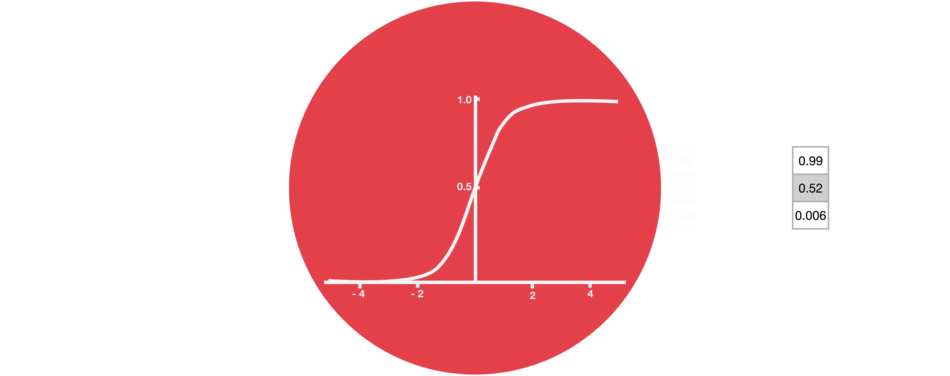
1을 곱한 숫자는 동일한 값이 유지되므로 해당 값은 동일하거나 'kept' 유지됩니다.
네트워크는 중요하지 않은 data까지 학습할 수 있으므로 잊어버릴 수 있거나 유지해야 하는 데이터가 중요합니다.
다양한 gate들이 하는 일을 살펴보겠습니다.
LSTM에는 정보의 흐름을 제어하는 3개의 다른 gate가 있습니다.
- forget gate
- input gate
- output gate
ⅲ) Forget Gate
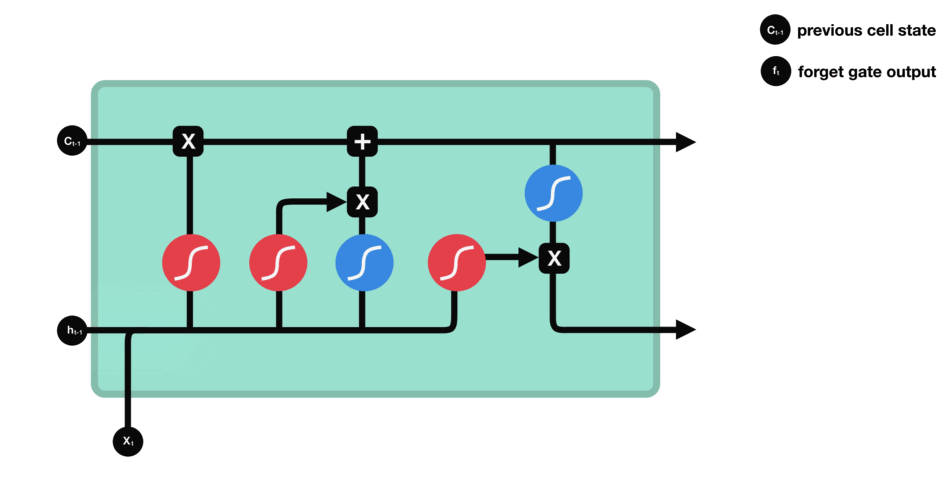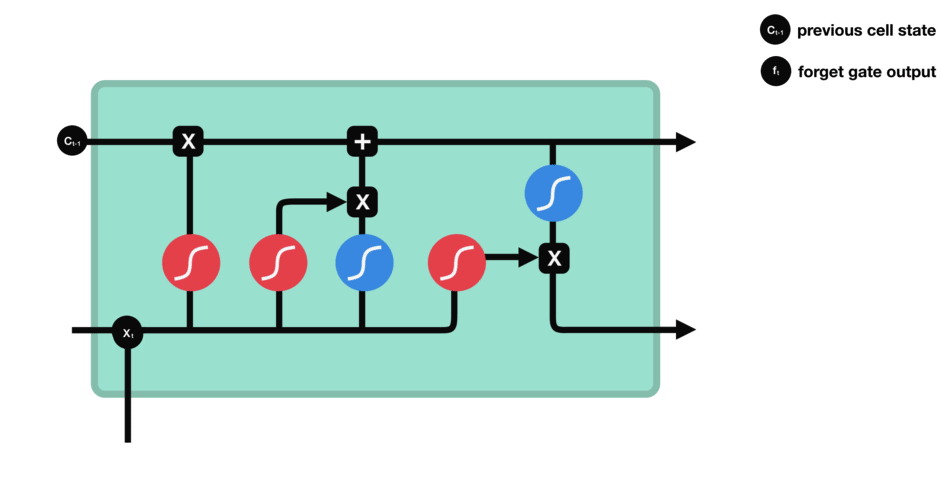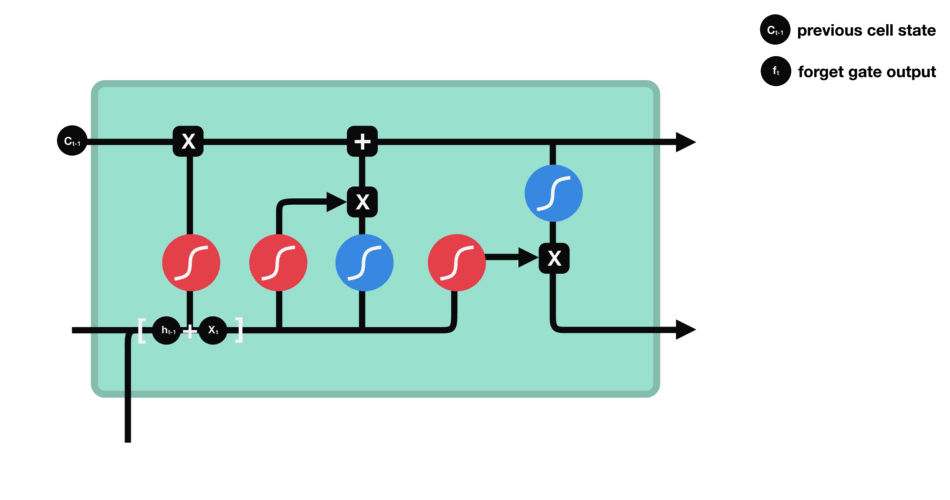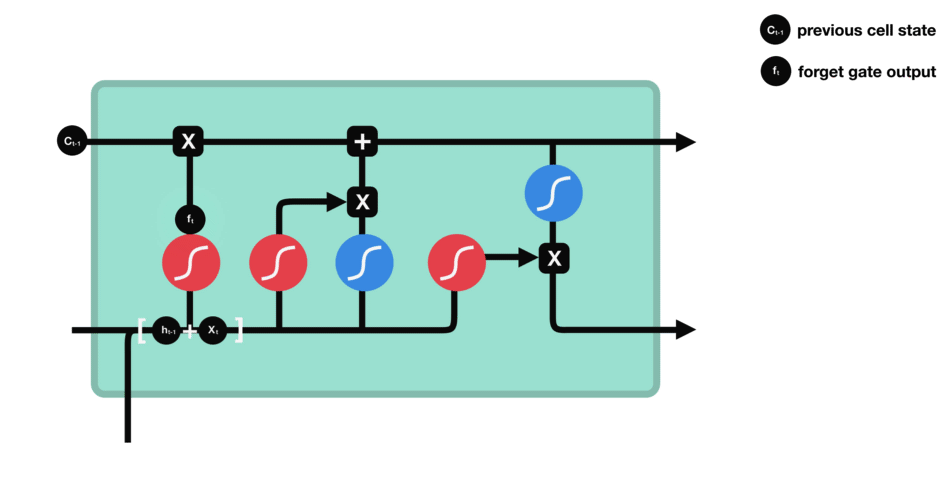
먼저 Forget Gate가 있습니다.
forget gate는 어떤 정보를 잊거나 보관해야 하는지를 결정합니다.
이전 hidden state의 정보와 현재 입력의 정보는 sigmoid 함수를 통해 전달되고, 값은 0과 1 사이입니다.
- 0에 가까울 수록 잊어버리고, 1에 가까울수록 유지합니다.
forget gate를 거치면서 이전 시각의 정보가 삭제됩니다.
ⅳ) Input Gate
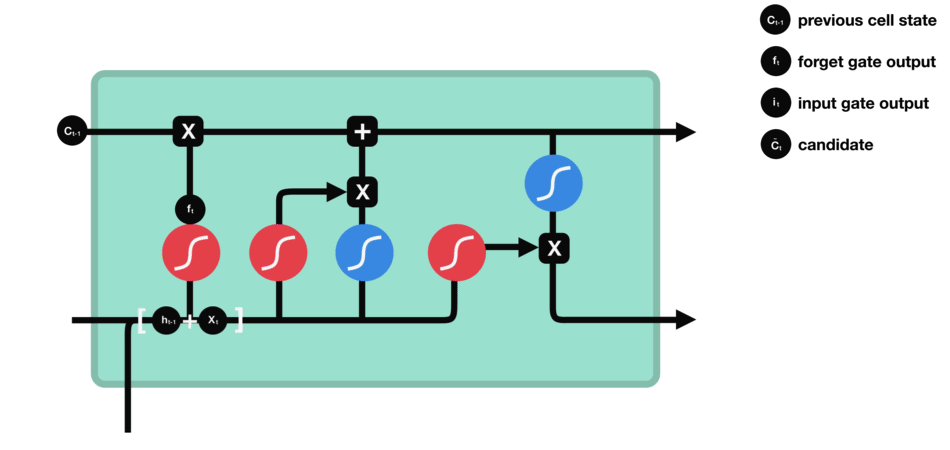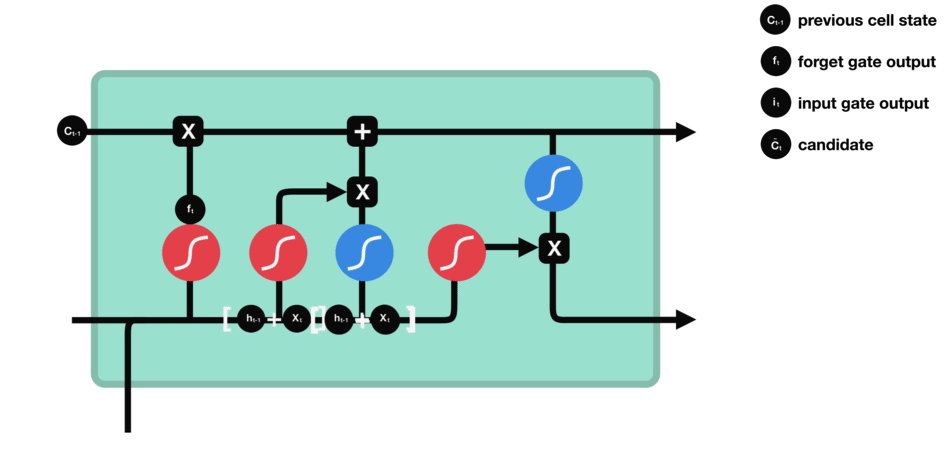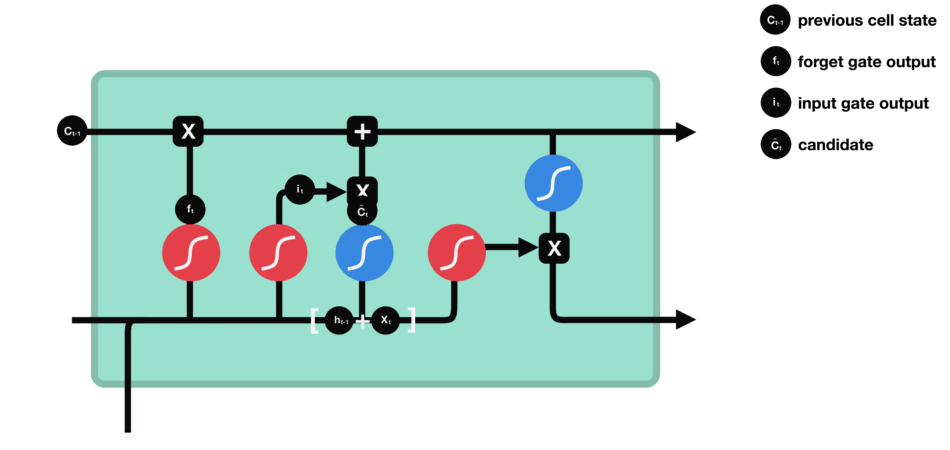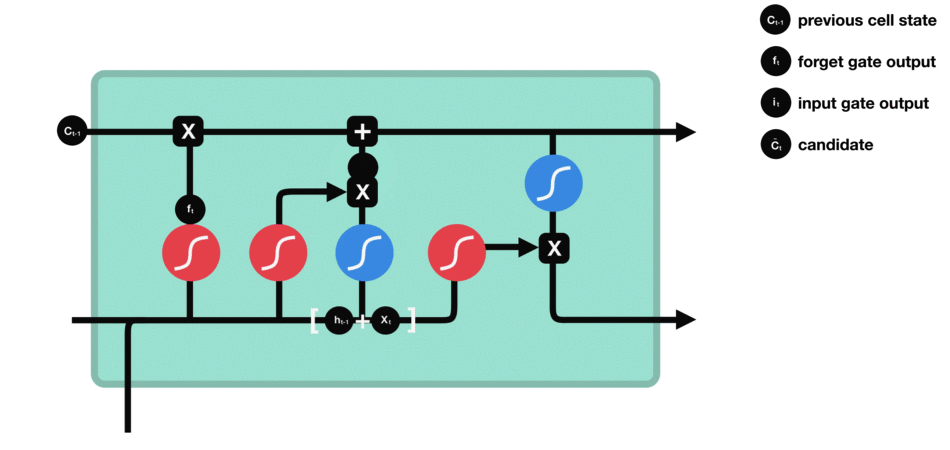
cell state를 update하기 위해 input gate가 있습니다.
input gate는 각 cell이 추가되는 정보로써의 가치가 얼마나 큰지를 판단합니다.
먼저 이전 hidden state와 현재 입력을 sigmoud function에 전달하여 값을 0과 1 사이로 변환하여 upate할 값을 결정합니다.
- 0에 가까울수록 중요하지 않고, 1에 가까울 수록 중요하다고 판단합니다.
또한, hidden state와 현재 입력을 tanh에 전달합니다. [-1, 1] 로 squash된 값은 네트워크를 조절하는데 도움이 됩니다.
그 다음 tanh의 출력과 sigmoud의 출력값을 곱합니다.
sigmoud가 tanh 출력에서 어떤 정보를 유지하는 것이 중요한지 결정합니다.
ⅴ) Cell State
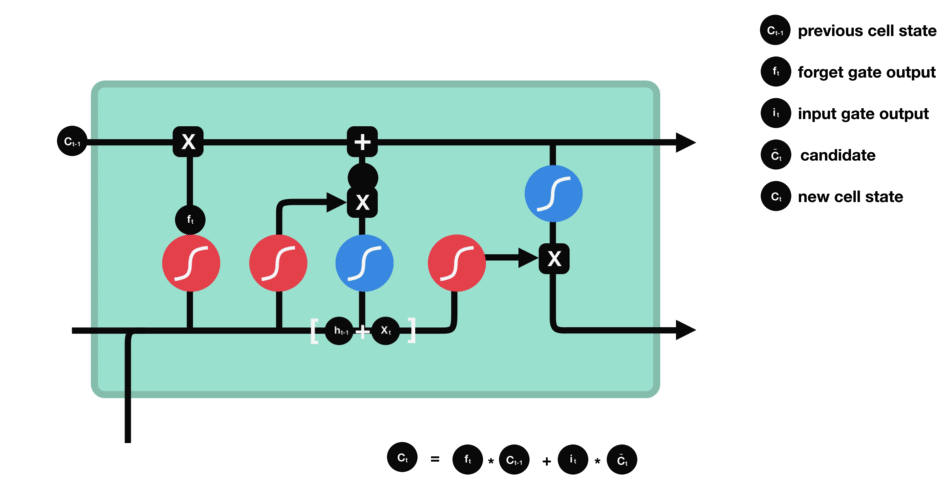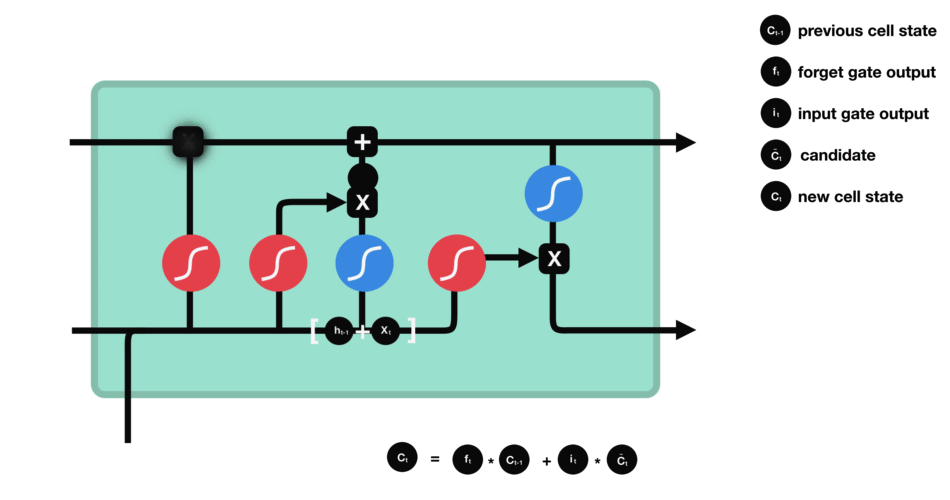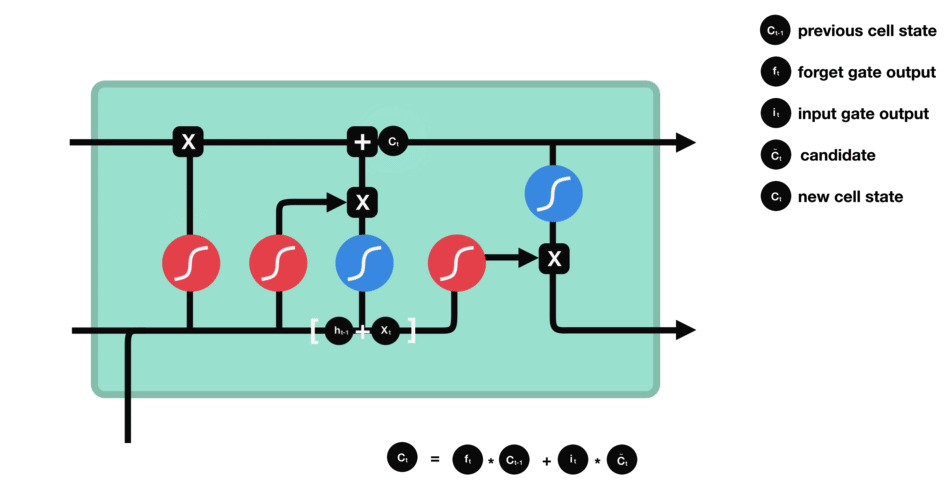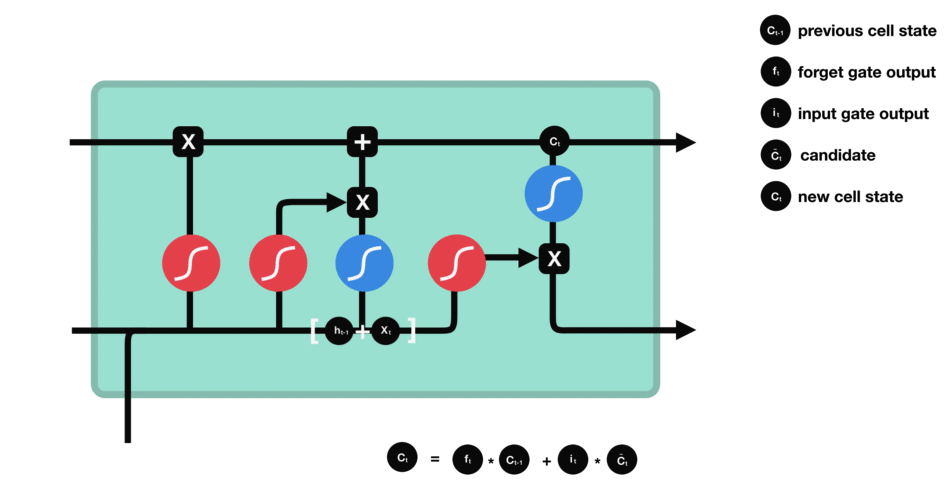
이제 cell state를 계산하기 위해 충분한 정보가 필요합니다.
cell state에 필요한 정보를 추가하여 new cell state를 만듭니다.
cell state에 forget vector를 곱합니다.
만약 0에 가까운 값을 곱하면 값이 떨어질 가능성이 있습니다. 그 다음 input gate에서 output을 가져오고 neural network에서 관련성이 있는 새 값으로 cell state를 update하는 pointwise를 수행합니다.
이 과정을 통해 새로운 cell state가 제공됩니다.
ⅵ) Output Gate
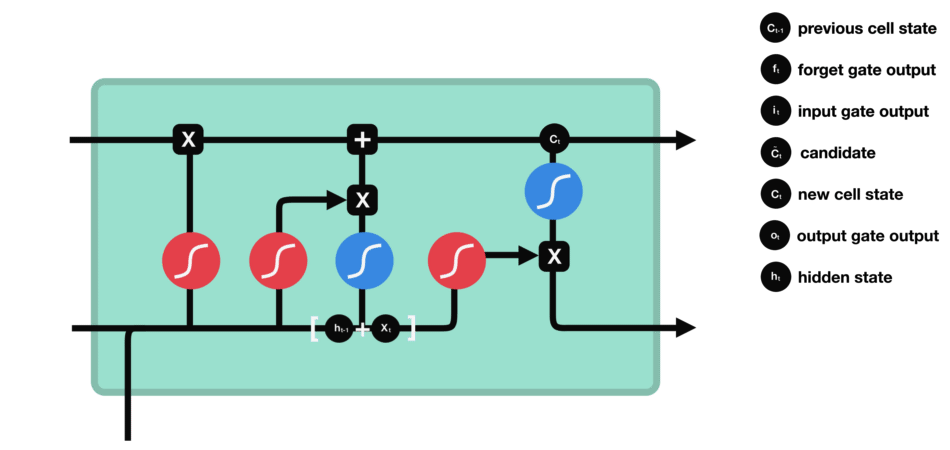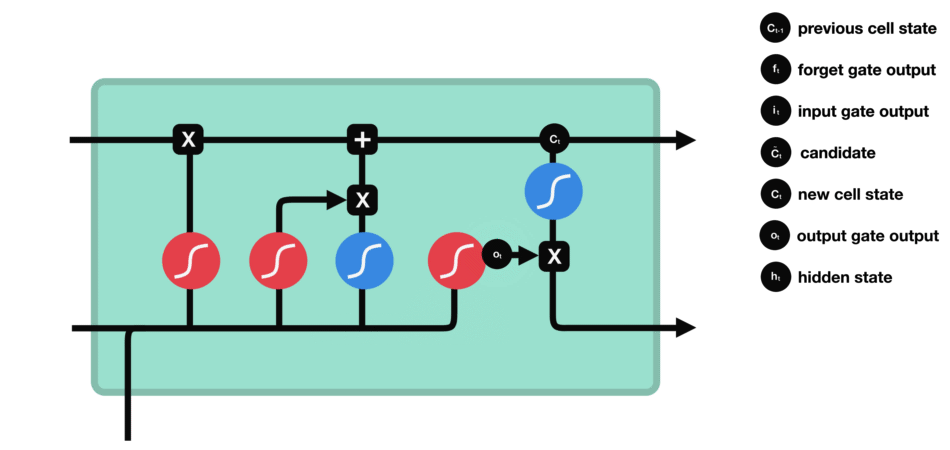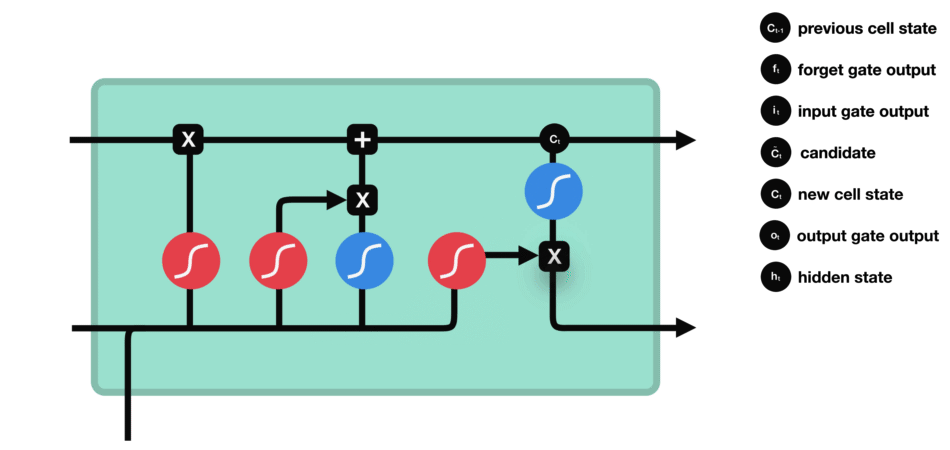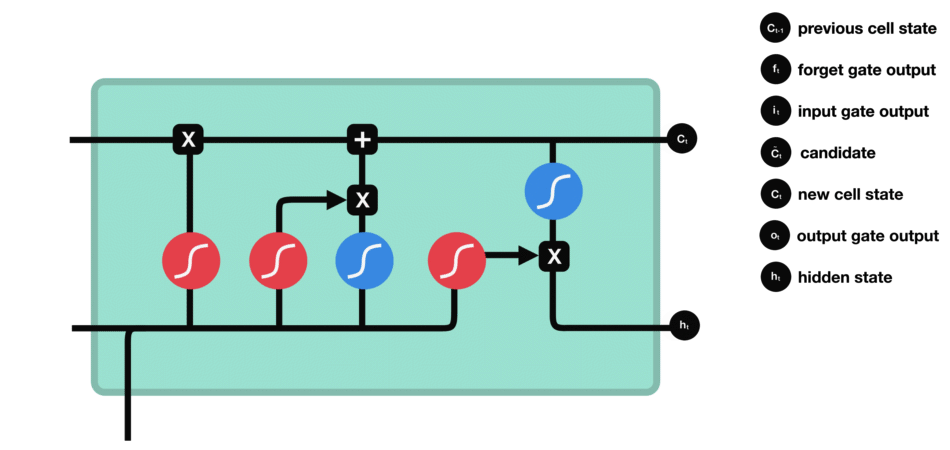
output gate는 다음 hidden state가 어떠해야 하는지를 결정합니다.
tanh가 각 원소에 대해 그것이 다음 hidden state에 대해 얼마나 중요한지를 조절하고,
output gate는 다음 hidden state의 출력을 담당하는 gate입니다.
hidden statae에는 이전 입력에 대한 정보를 포함하고 있습니다. 예측에도 사용되기 때문에, 이전 hidden state와 현재 입력을 sigmoid에 전달합니다.
그 다음 새로 수정된 cell state를 tanh에 전달합니다.
hidden state가 전달해야 하는 정보를 결정하기 위해 tanh 출력과 sigmoid 출력을 곱하고, 이 출력값은 hidden state가 됩니다.
그 다음 new cell state가 다음 time step으로 넘어갑니다.
이 과정을 코드로 살펴보겠습니다.
def LSTMCELL (prev_ct, prev_ht, input):
combine= prev_ht + input
ft = forget_layer(combine)
candidate = candidate_layer(combine)
it = input_layer(combine)
Ct = prev_ct + ft + candidate * it
ot = output_layer(combine)
ht = ot * tanh(Ct)
return ht, Ct
ct = [0, 0, 0]
ht = [0, 0, 0]
for input in inputs:
ct, ht = LSTMCELL (ct, ht, input)GRU
GRU에 대해서는 간단히 살펴보겠습니다. LSTM과 매우 유사하다고 합니다
GRU는 cell state를 제거하고 hidden state를 이용해 정보를 전달합니다.
또한, reset gate와 update gate의 두 가지 gate가 있습니다.
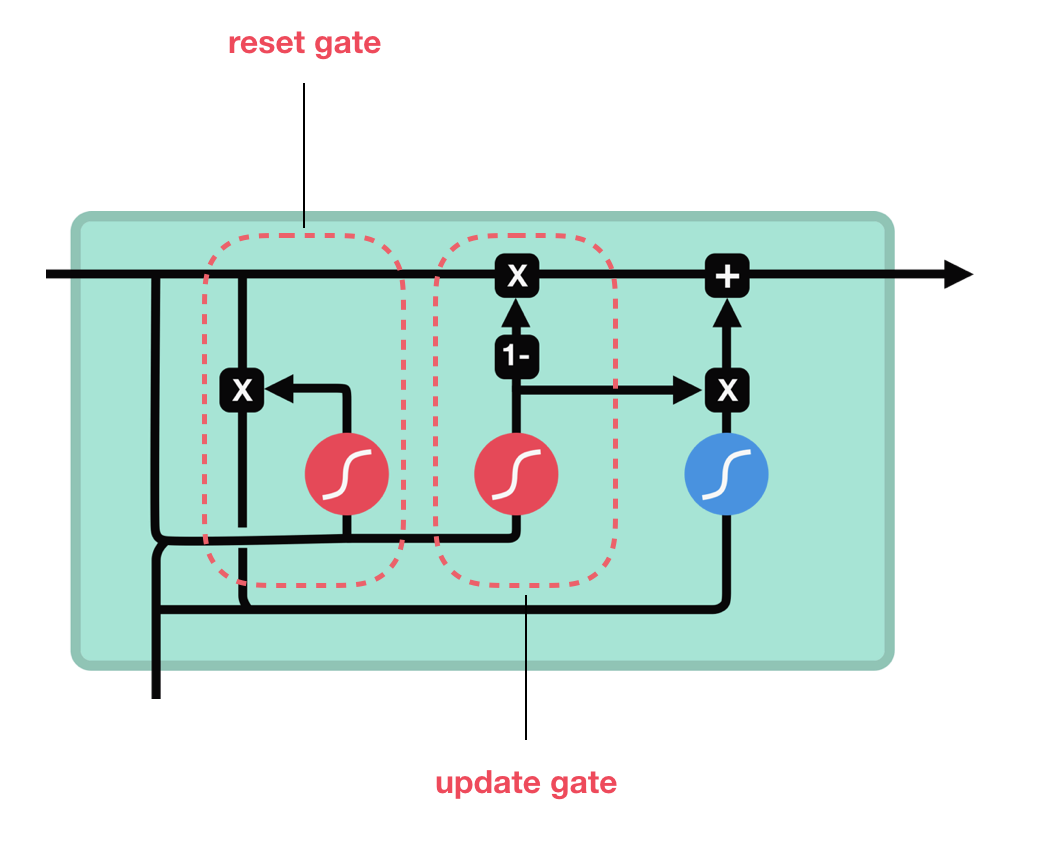
update gate는 LSTM의 forget, input gate와 유사하게 작동합니다.
버릴 정보와 추가할 새로운 정보를 결정합니다.
reset gate는 잊어버릴 이전 정보의 양을 결정하는데 사용됩니다
GRU는 tensor 연산이 더 적어서 LSTM보다 훈련 속도가 조금 더 빠르다고 합니다. 어느 쪽이 더 낫다는 건 없다고 합니다.
Summary
- RNN은 예측을 위한 sequence data를 처리하는데는 좋지만, short-term memory 문제가 있습니다.
- LSTM 및 GRU는 gate라는 mechanism을 사용하여 short-term memory를 완화합니다.
- gate는 sequence chain을 통해 정보 흐름을 제어하는 neural network입니다
- LSTM과 GRU는 음성 인식, 음성 합성, 자연어 이해와 같은 deep learning application에 사용됩니다.
gate가 추가된 RNN이 LSTM, GRU라고 볼 수 있다. 가장 단순한 vanilla RNN에서 vanishing or Exploding gradient가 문제가되었는데, 그것을 대신하는 layer로써 gate가 추가되어 효과를 보았습니다.
이 layer에서는 gate라는 구조가 사용되며, gate는 데이터와 gradient 흐름을 적절히 제어하는 mechanism입니다.
이상 여기까지 LSTM과 GRU에 대한 간단 정리를 마치겠습니다.
Illustrated Guid Series

ct = prev_ct ft candidate it
-> ct = prev_ct ft + candidate * it
ft와 it 는 + 연산을 해야 합니다.
그리고 같은 코드에서 출력은 Ct를 하는데 변수는 ct로 하셨네요
수정하셔야겠습니다.