참고
이전 Object Detection에 대해 정리한 포스팅이 있습니다.😃

이번에 리뷰할 논문은 2016년에 발표된 'You Only Look Once: Unified, Real-Time Object Detection'입니다.
첫 논문 리뷰라서 떨리네요.😉 퍼실님께 논문 스터디 방법을 여쭤봤습니다. 팁을 주셨는데요. 제가 공부할 주제인 Object Detection이라는 task에서 어떻게 알고리즘이 발전해왔는지 보여주는 survey paper을 보고, 중요 논문 선정 및 스터디 방향을 설정하면 좋다고 하네요.
제가 참고한 survey paper는 Deep Learning for Generic Object Detection: A Survey 이것입니다.
1 or 2 Stage Detector
시작하기 앞서 Object Detection이란 이미지가 주어지면 background와 object를 구분하고 어떤 object인지 detect하는 것을 말합니다.

[1] YOLO v1을 이용해 실제로 object와 그림 안의 object를 classification한 결과
그리고 Object Detection에는 두 가지 접근법이 있습니다.
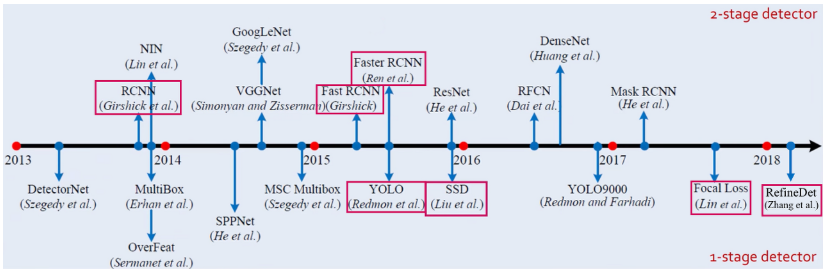
[2]
위 이미지를 참고하면, 중앙 직선을 기준으로 위가 2-Stage Detector이고 아래가 1-Stage Detector입니다.
2-stage Detector
Regional Proposal과 Classification이라는 두 가지 과정을 순차적으로 거쳐 Object Detection이 이루어지는 과정입니다. 역할을 분담하여 문제를 처리하므로 정확도는 높지만, 속도가 느리다는 단점이 있습니다.
2-Stage Detector에는 대표적으로 R-CNN 계열, OverFeat, DPM 등이 있습니다.
Regional Proposal
기존에는 이미지에서 object detection을 위해 sliding window 방식을 이용했었습니다. sliding window 방식(연산량이 많음)의 비효율성을 개선하기 위해 'object'가 있을만한 영역을 빠르게 찾아내는 알고리즘이 Regional Proposal입니다.
대표적으로 Selective search, Edge boxes 등이 있습니다.
즉, Regional Proposal은 object의 위치를 찾는 localization 문제입니다.
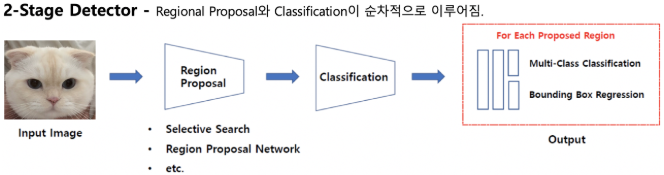
이미지 출처: [2]
위 그림을 통해 과정을 더 쉽게 이해할 수 있습니다. Input Image에 regional proposal과 classification이 순차적으로 이루어지며 localization 문제를 해결합니다.
1-stage Detector
2-stage Detector는 Regional Proposal과 Classification의 과정이 순차적으로 이루어졌지만, 1-stage Detector는 Regional Proposal과 Classification를 동시에 해결합니다.
전체 이미지에서 Class Probabilities 및 Bbox offset을 직접 예측하는 구조입니다. 이 접근방식은 region proposal 생성 및 feature resampling 단계를 완전히 제거하여, 모든 계산을 캡슐화하여 빠르다는 특징을 갖습니다.
즉, classification과 localization 문제를 동시에 해결하는 방법입니다.
1-stage Detector에는 대표적으로 Yolo 계열, SSD 계열이 속해 있습니다.
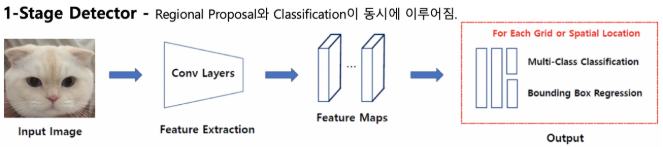
[2]
위 그림을 보면 ROI(Region of Interest: 관심 영역)를 먼저 추출하지 않고 전체 이미지에 대해 single neural network로 classification, box regression을 수행합니다.
특정 object 하나만 담고 있는 ROI에서 classification과 localization를 수행하는 것보다 여러 noise, 즉 여러 object가 섞여 있는 전체 image에서 이를 수행하는 것이 정확도는 떨어지지만 간단한만큼 속도가 빠르다는 장점이 있습니다.
둘의 차이점은 속도와 정확도입니다.
1-stage Detector는 비교적 빠르지만 정확도가 낮고, 2-stage Detector는 비교적 느리지만 정확도가 높습니다.
오늘 리뷰할 YOLO의 등장 이전에 DPM과 R-CNN이 존재했고, YOLO는 이미지에 neural network를 실행한 1-Stage-Detecter로, 더 높은 정확도 보다 더 많은 양의 이미지를 보다 빠르게 처리할 수 있는 real-time detection을 하고자 등장했습니다!
YOLO는 version에 따라 YOLOv[number] 이름으로 논문이 존재합니다.
1. Abstract
- You Only Look Once!
본격적으로 학습 전 YOLO의 이름을 따와 이 모델의 특징을 살펴보고 가겠습니다. 논문에서 설명하는 특징도 이와 같습니다.
- You Only Look Once
이미지 전체를 단 한 번만 본다는 의미입니다. 이전 모델이었던 R-CNN과 비교하자면 R-CNN은 이미지에서 일정한 규칙으로 이미지를 여러 장 쪼개 CNN 모델을 통과시키기 때문에, 한 장의 이미지에서 object detection을 수행해도 실제로는 수 천장의 이미지를 모델에 통과시킵니다. 반면, YOLO는 이미지 전체를 단 한 번만 봅니다!
- Unified
다른 object detection 모델은 다양한 전처리 모델과 neural network를 결합해서 사용하지만, YOLO는 단 하나의 (single) neural network에서 전부 처리합니다. 위에서 설명한 1-stage Detector의 설명과 같습니다.
- Real-time Object Detection
실시간으로 객체를 탐지합니다. YOLO가 높은 성능을 가진 모델은 아니지만, 실시간으로 여러 장의 이미지를 탐색하는 빠른 속도를 가졌습니다.
이전 작업이었던 R-CNN은 5초, Fast R-CNN도 0.5프레임, Faster R-CNN도 7프레임이 최대였습니다. YOLO는 45프레임입니다. 더 빠른 버전의 경우 155프레임을 기록했습니다. 게다가 성능도 FasterR-CNN에 비해 크게 떨어지지 않아서 주목을 받았습니다.
2. Introduction
YOLO는
- 속도가 빠르다.(45 FPS-Frame Per Seconds)
- network는 General Representation을 지닌다.
- natural image로 학습한 후 artwork에서 test를 진행해도 다른 모델보다 좋은 성능을 보여준다.
- single neural network를 통해 class probabilities와 Bbox를 예측한다.
- 이미지를 전역적으로 파악한다.
- 기존의 sliding window와 region proposal과 다르게 이미지의 전체를 보기 때문에
- class의 문맥적인(Contextual) 정보를 추론할 뿐만 아니라, appearance를 encode하여 Yolo가 많은 localization error를 만들지만, background에서 오탐지(false positive)할 경우는 적다고 한다.

[1] YOLO Detection System
위 그림은 구조를 간략하게 보여주긴 하지만 중요한 점은 YOLO의 Detection System은 Conv network를 한 번만 통과시킨다는 점입니다.
결과로 Bbox를 통해 각 object가 무엇인지와 class probabilities를 출력합니다. 최종적으로 이 값을 Non-max suppression을 통해 Region을 결정합니다.
※ Non-max suppression(NMS)은 Input image가 object detection 알고리즘을 통과하며 한 object에 많은 bbox가 생겼을 때, 가장 높은 score인 box만 남기고 나머지를 제거하는 것을 의미합니다.
3. Unified Detection
YOLO는 높은 정확도를 유지하면서 end-to-end training과 real-time speeds를 가능하게 했습니다.
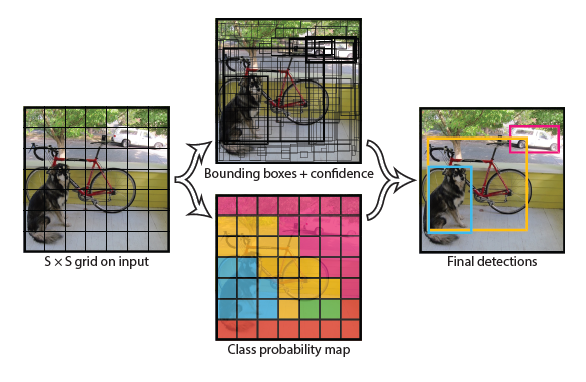
[1]
위 이미지처럼 시스템은 이미지를 SxS grid로 나눕니다. 그리고 grid cell 안에 object가 있다면, grid cell은 object를 탐지합니다!
각각의 grid cell은 Bbox와 각 box의 신뢰도(confidence score)를 예측합니다. confidence score은 모델에서 box가 object를 포함하고 있는지와 box가 얼마나 정확히 예측했는지를 반영합니다. 이를 아래의 수식으로 정의를 하였는데요.
Pr(Object) ∗ IOU
※ IOU는 두 영역의 교집합인 intersection 영역의 넓이를 두 영역의 합집합인 union 영역으로 나누어준 값입니다. 이를 통해 찾고자 하는 물건의 절대적인 면적과 상관없이, 영역을 정확하게 잘 찾아내었는지의 상대적인 비율을 구할 수 있으므로 모델이 영역을 잘 찾았는지 비교하는 지표입니다.
cell에 object가 없다면 IOU는 0입니다. confidence score는 predicted box(예측)과 ground truth(정답) 사이의 IOU(intersection over union)와 같기를 원합니다.
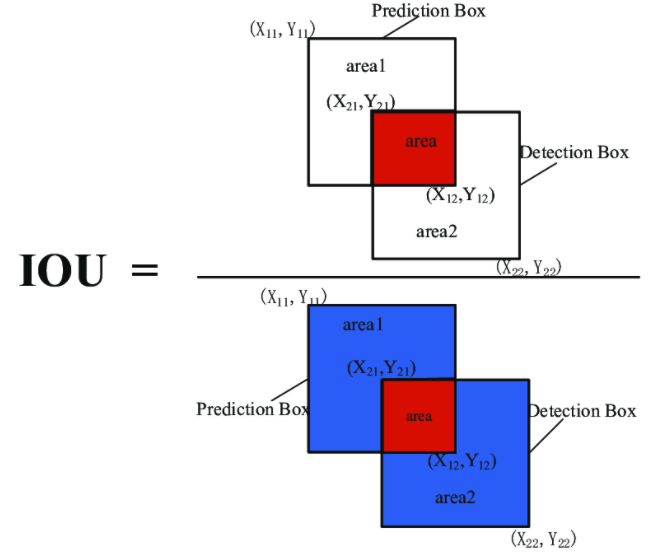
각각의 Bbox는 5개의 predictions를 가집니다.
x, y, w, h and confidence
이미지를 SxS의 grid cell로 나눈다면 grid cell 중 object의 중앙과 가장 가까운 cell이 object detection을 하게 됩니다. 그리고 각각의 grid cell은 class의 확률인 C를 예측합니다. 식으로는
즉, grid cell은 Bounding Box B와 class의 확률인 C를 예측합니다.
Pr(Class_i|Object).
이와 같이 표현하며 B가 background가 아닌 object를 포함하는 경우의 각 class별 확률인 조건부 확률입니다.

결론적으로 class probabilities와 각 box의 신뢰도를 곱하면 class별 Confidence Score가 나옵니다.
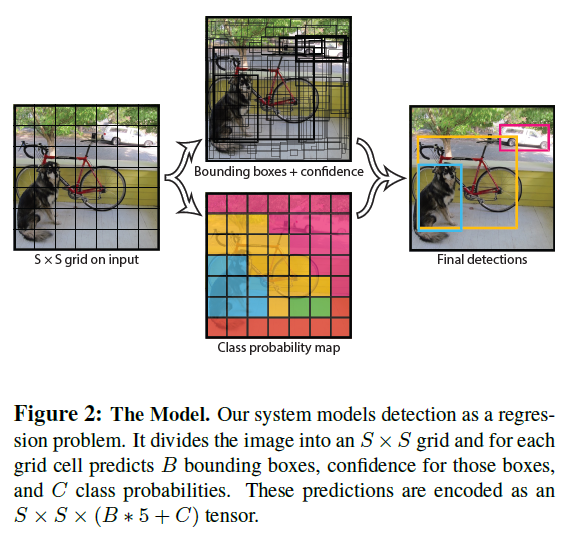
[1]
해당 이미지를 다시 참고하여, 위는 7x7 grid이며, 각각의 grid cell이 B와 C를 예측합니다. 이 예측은 SxSx(B*5+C) tensor로 표현됩니다.
만약 PASCAL VOC를 예를 들면, S = 7, B =2, C = 20일 경우에 7x7x30 tensor로 결과를 추출합니다.
3.1. Network Design
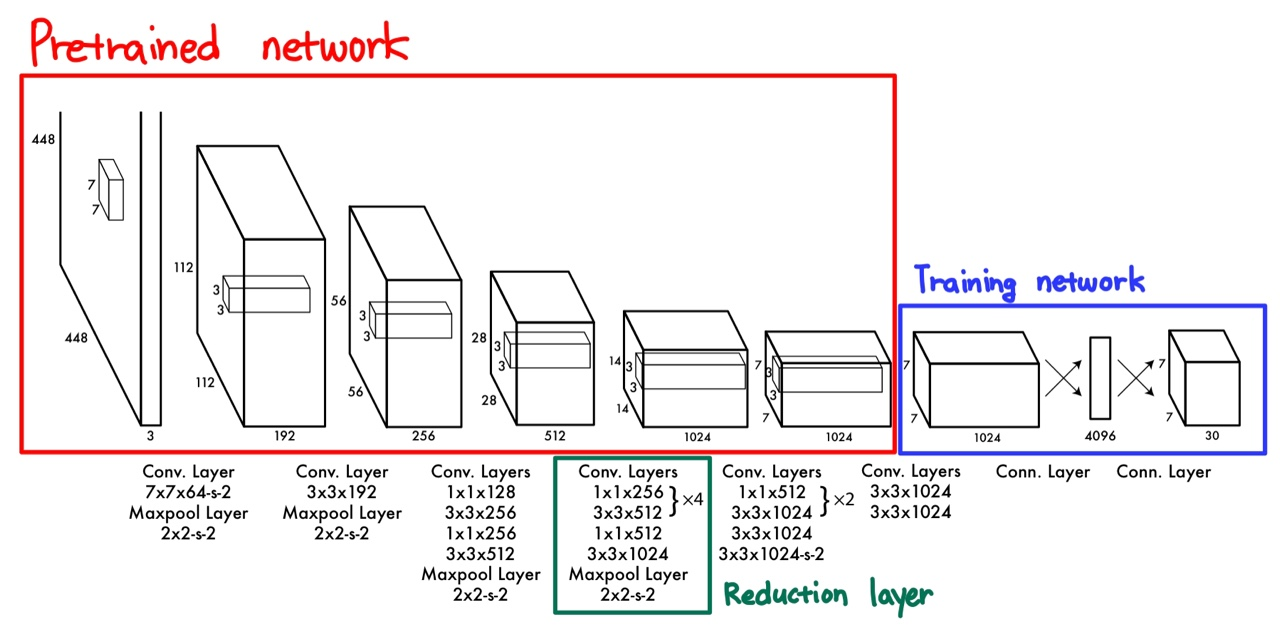
해당 파트에서는 YOLO의 network design을 보여주었습니다.
GoogLeNet 구조에 영감을 받아서 해당 network를 설계했고, 기존 GoogLeNet은 Inception module을 사용한 반면 YOLO는 Inception module을 일자로 이어둔 모델을 사용했습니다.
YOLO의 전체 네트워크 구조는 24개의 Conv layers와 2개의 Fully-Connected layer(FC layer)를 가집니다. 1x1의 layer는 이전 layer의 feature space를 줄여줍니다.
해당 논문에서는 Pre-trained Network, Training Network, Reduction Layer 영역을 나눠 설명하였습니다.
3.2. Training
(1) Pretrained Network
빨간색 네모 박스인 Pretrained Network는 사전에 GoogLeNet을 이용하여 ImageNet 1000-class dataset을 사전에 학습한 결과를 Fine-Tuning한 네트워크를 말합니다. 이 네트워크는 20개의 Conv layer로 구성되어 있고, 88%의 정확도를 사전에 달성했다고 합니다.

원래 ImageNet dataset의 이미지는 (224x224)인데 종종 detection에서는 더 세분화 된 시각 정보(fine-grained visual information)가 필요하므로 input resolution을 2배인 (448x448)로 높여주었습니다.
(2) Reduction Layer
network는 깊을 수록 더 많은 feature map을 학습하기 때문에 accuracy가 높아지는 경향이 있습니다. 하지만 Conv layer가 깊어질수록 이를 통과할 때 사용하는 filter 연산에서 시간이 많이 소요 됩니다.
이 문제를 해결하기 위해 ResNet, GoogLeNet 등의 기법이 제안되었고, 초록섹 네모 박스의 영역은 GoogLeNet의 기법을 응용하여 연산량은 감소시키고 layer를 깊게 쌓는 방식을 이용했습니다.
(3) Training Network
마지막 파란색 영역인 Training Network는 Pretrained Network에서 학습한 feature를 이용하여 C(class probabilities)와 B(Bounding box)를 학습하고 예측하는 network입니다.
YOLO 예측 모델은 SxSx(B*5+C)개의 parameter를 결과로 출력하는데, PASCAL VOC dataset은 20개의 class를 가졌고, grid cell은 7이므로 1470개의 값이 출력된다.
(4) Loss Function
- 네트워크 출력인 height와 width를 normalize를 통해 0~1사이로 정규화시킨다.
- Bbox의 좌표인 x,y 또한 parameterize를 통해 0~1의 값으로 만든다.
- activation function으로는 Leaky ReLU(0.1)을 사용하였다.
- optimize를 위해 sum-squared error를 사용한다.(SSE)
그러나 논문에서는 localization error와 classification error에게 동일한 weight를 주면 비이상적이라 하였다. 또한, object가 없는 grid cell이 많기 때문에 object가 존재하는 cell들에게 'confidence'가 0을 향하는 영향(gradient)을 미친다고 하였다.
그래서 YOLO는 마지막 Training Network를 학습하기 위해 몇 가지 원칙을 만들었다.
- 이미지 분류 문제를 Bbox를 만드는 Regression문제로 생각한다. 이를 위해 Loss function에서 SSE를 이용한다.
※ SSE는 오차의 제곱합이다. linear regression은 SSE를 최소화하는 방법으로 회귀 계수를 추정하며, SSE가 작을수록 좋은 모델이라 볼 수 있습니다.
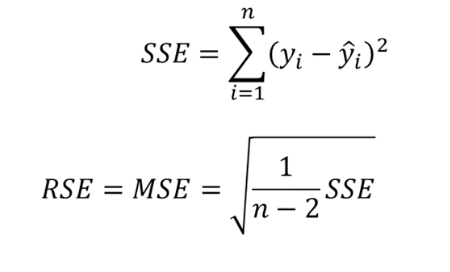
- localization error와 classification error에게 다른 penalty를 부여한다. 특히, box 안에 object가 없는 경우에는 Confidence Score가 0이 되도록 localization error에 더 높은 penalty를 부여한다.
이를 위해 두 parameter를 사용하는데 λ_coor, λ_noobj 두 변수를 사용한다. 논문에서는 λ_coor = 5, λ_noobj = .5로 설정했습니다.
- YOLO는 각 grid cell마다 많은 Bbox를 예측한다. 이중 object를 가장 잘 예측하는 단 하나의 Bbox를 원한다. 이를 선정하는 기준은 ground truth에 대해 IOU가 가장 높은 예측값을 가진 Bbox이다.
학습을 잘 하는 Bbox에겐 높은 confidence score를 주고, 나머지 cell은 Bbox를 잘 못 만들더라도 Non-max suppression을 통해 최적화 하기 위함입니다.

[1]
loss function을 더 자세히 보겠습니다.
앞에서 언급했던 기호지만 정리를 하자면
- S: grid cell의 크기
- B: S_i cell의 Bbox
- x, y, w, h: Bbox의 좌표 및 크기
- C: each grid cell의 class
- λ_coor: localization error에 5배 더 높은 penalty 부여
- 주황색 형광펜: 각 object마다 IOU가 가장 높은 Bbox에만 λ_coor가 곱해진다.
- λ_noobj: 해당 셀에 object가 없는 경우(no object;noobj) Bbox 학습에 영향을 끼치지 않도록 0.5를 곱해준다.
- 초록색 형광펜: box에 object가 없는 경우에만 수행한다.
- 하늘색 형광펜: 첫 번째 박스는 Bbox와 cell마다 class에 따른 error이며, 이 수식에는 weight를 곱하지 않는 것을 볼 수 있다. 두 번째 박스는 Bbox와 상관 없이 cell마다의 class를 분류하기 위한 error이다.

Loss function을 이용해 network training하면 위 사진처럼 많은 Bbox가 생깁니다.
object가 center로 잡은 Bbox가 높은 confidence score가 나오므로

최종적으로는 Non-max suppression 과정을 거쳐 이미지 object를 탐지하게 됩니다.
참고
논문에서는 해당 방법으로 모델을 학습시켰습니다.
- Epoch = 135, batch size = 64, momentum = 0.9, decay = 0.0005
- learning rate scheculing: 첫 epoch에서 10^-3에서 75 epoch까지 10^−2으로 학습
- 이후 30 epochs 동안 10^−3으로 학습, 마지막 30 epochs 동안 10^−4으로 학습
- overfitting을 막기 위해 dropout과 data augmentation을 활용
3.3. Inference
train과 마찬가지로 test image에 대한 detection을 위해서도 network evaluation이 한 번만 필요합니다.
YOLO는 a single network evaluation만 필요로 하므로 test time이 매우 빠릅니다.
grid design은 Bbox를 예측하는데 spatial deiversity를 적용합니다. object가 어느 grid cell에 있는지, 하나의 box만 예측합니다.
그러나 일부 큰 객체(large object)나 여러 개의 cell의 경계 근처에 있는 object는 여러 cell에 의해 localize됩니다.
3.4. Limitations of YOLO(한계점)
- 각각의 grid cell에서 2개의 Bbox를 얻고, 하나의 class만 가질 수 있으므로 근접해 있는 작은 object를 잘 감지 못하는 문제가 있습니다.
Loss Function에서 Bbox를 고를 때, 사물이 큰 object는 Bbox간의 IOU의 값이 크게 차이나지만, 작은 object는 약간의 차이로도 IOU가 크게 달라집니다. - 1과 이어지는 개념입니다. loss function을 training하는 동안, 작은 Bbox와 큰 Bbox의 경계에서 error를 동일하게 적용합니다.
large Bbox의 error가 small Bbox error의 IOU에 큰 영향을 주기 때문에 localization이 부정확한 경우가 발생합니다. - YOLO 모델은 data에서 Bbox를 예측하는 방법이기 때문에 새롭거나 비율이 특이한 object가 들어오면 generalize하는데 어려움이 있습니다.
또한, input image에서 여러 downsampling이 있기 때문에 Bbox를 예측하기 위해 coarse features을 이용해 예측해야 합니다.
4. Experiments
Performance
YOLO의 논문에서는 object detection을 수행하는 모델인 DPM, R-CNN, Fast R-CNN, Faster R-CNN과 YOLO 원래 네트워크에서 설계를 간소화 해서 사용하여 accuracy를 포기하고 성능을 높인 Fast-YOLO 등의 모델의 정확도(mAP)와 초당 프레임 수(FPS)를 비교하였습니다.
여기서 mAP는 mean Average Precision의 약자로 객체 탐지 분야에서 성능을 평가하기 위해 사용하는 수치이다.
아래의 표는 PASCAL VOC 2007의 데이터 셋을 학습하여 mAP와 FPS를 나타낸 수치입니다.
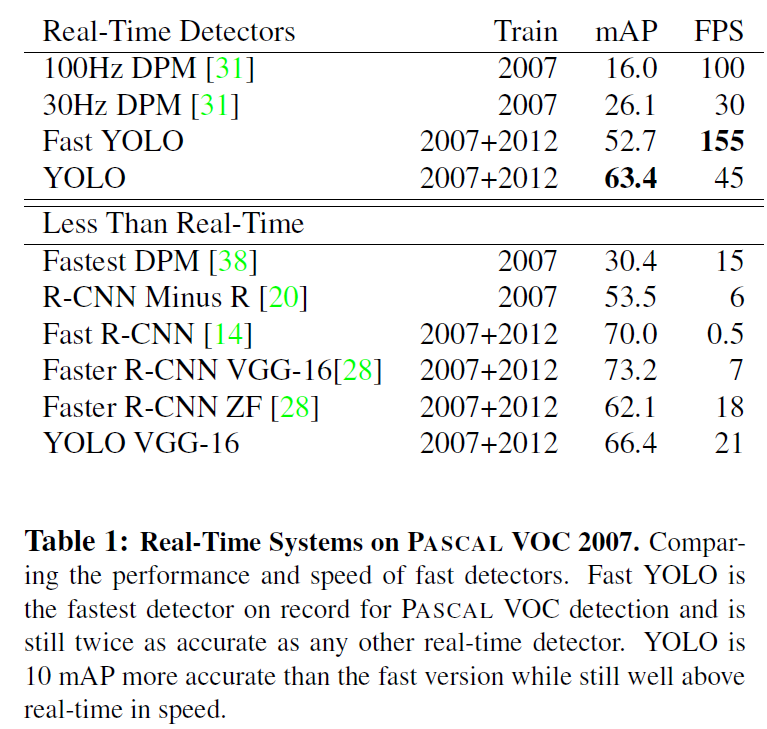
YOLO는 63.4 mAP를 가지며 초당 45라는 프레임을 갖습니다. (FPS: Frame per second) 그리고 더 빠른 Fast YOLO는 mAP(성능)은 떨어지지만, FPS는 155로 굉장히 빠른 처리 속도를 가집니다. 이는 streaming video도 처리할 수 있다고 합니다.
출처: https://youtu.be/MPU2HistivI
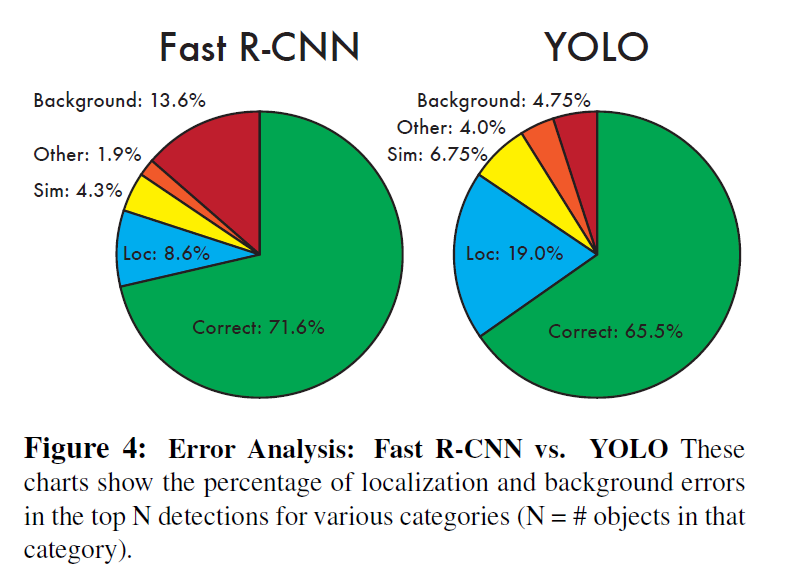
YOLO와 Fast-YOLO는 해당 그래프로 비교해보시길 바랍니다.
5. Real-Time Detection In The Wild
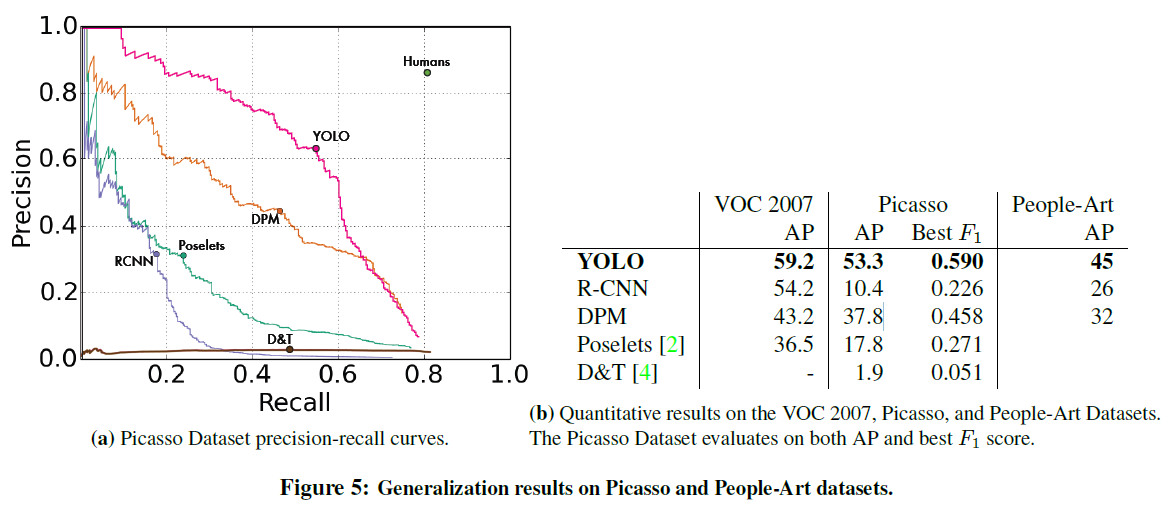
[1]
위의 그래프와 표는 피카소와 사람들의 미술 그림 dataset을 활용하여 object detection을 수행한 것이고, 성능 지표입니다.
YOLO가 Recall과 Precision이 가장 뛰어난 모델임을 알 수 있습니다.

실제로 이렇게 찾아냈다고 합니다.
6. Conclusion
YOLO는 구성이 간단하고 전체 이미지를 학습합니다. 또한, 기존에는 접근 방식의 classifier이었다면 YOLO는 loss function을 train하며 detection performance에 직접적으로 대응하고, 전체 모델을 학습합니다.
YOLO v1, YOLO v2, YOLO v3
해당 논문은 YOLO version 1입니다. v4부터는 저자가 다르다고 합니다. v1~v3는 같은 저자입니다.
YOLO v1 의 단점
획기적이었던 YOLO v1에도 단점은 있었습니다. 우선 각각 grid cell이 하나의 class만 예측 가능하므로 작은 object에 대해 예측이 어려웠습니다.
bbox의 형태가 training data를 통해 학습되었기 때문에 bbox 분산이 너무 넓어 새로운 형태의 bbox 예측이 잘 안되었습니다.
또한, 모델 구조상 backbone만 거친 feature map을 대상으로 bbox 정보를 예측하기 때문에 localization이 다소 부정확했습니다. 그래서 2017년 YOLO v2이 나오게 됩니다.
YOLO v2

YOLO v2는 2017년 CVPR 컨퍼런스에서 “YOLO9000: Better, Faster, Stronger”라는 이름으로 논문이 발표되었습니다.
YOLO2는 요약하자면 Batch Normalization, Direct Location Prediction, Multi-Scale Training기법을 도입해서 FPS와 mAP를 높였습니다.
YOLO2 발표 논문의 제목처럼 YOLO2의 목적은 아래와 같았습니다.
- Make it better
- Do it faster
- Makes us stronger
Make it better은 정확도를 올리기 위한 방법이었습니다. 이를 위해 Batch Normalization, High Resolution Classifier, Convolutional with Anchor boxes, Dimension Clusters, Direct location prediction, Fine-Grained Features, Multi-Scale Training를 사용하였습니다.
Do it faster는 detection 속도를 향상시키기 위한 방법이었습니다. 이를 위해 Darknet-19, Training for classification, Training for detection를 사용했죠.
Makes us stronger은 는 더 많은 범위의 class를 예측하기 위한 방법이었습니다. 이를 위해 Hierarchical classification, Dataset combination with WordTree, Joint classification and detection를 사용했습니다.
YOLO v1이 20개의 이미지를 분류하는 모델을 소개했지만 v2는 9000개의 이미지를 탐지하면서 분류할 수 있는 모델을 개발하였습니다.
자세한 설명은 해당 링크를 참고 부탁드립니다.
YOLO v3
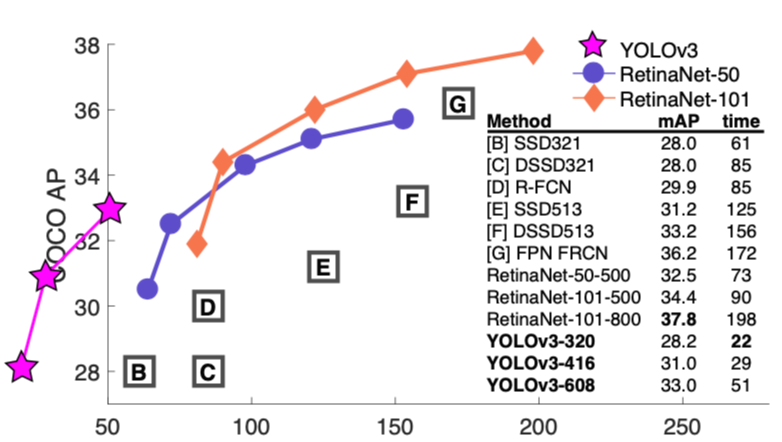
[3]
YOLO v3는 v2버전을 더욱 개량한 것입니다. 현재는 거의 모든 영역에서 사용되는 ResNet의 Residual Block이 v2버전에서는 존재하지 않았습니다. 그래서 레이어 신경망 층이 최근에 나온 연구보다는 상대적으로 얇았는데, v3에서는 이 기법을 사용해서 106개의 신경망 층을 구성하였다고 합니다.
참고: [4]
Reference
[1] https://arxiv.org/pdf/1506.02640.pdf
[2] https://www.slideshare.net/JinwonLee9/pr132-ssd-single-shot-multibox-detector
[3] https://arxiv.org/pdf/1804.02767.pdf
[4] https://bit.ly/3vbIH3p

너무 잘 봤습니다.
정리를 아주 잘하시네요!