Object Detection 시리즈
0️⃣ 딥러닝 Object Detection(1) - 개념과 용어 정리
1️⃣ 딥러닝 Object Detection(2) - Localization 개념 정리
2️⃣ 딥러닝 Object Detection(3) - Sliding Window, Convolution
3️⃣ 딥러닝 Object Detection(4) - Anchor Boxes, NMS(Non-Max Suppression)
4️⃣ 딥러닝 Object Detection(5) - Architecture - 1 or 2 stage detector
오늘 주제를 포스팅하기 앞서 참고한 자료를 첨부합니다. 그럼 오늘도 열공🐣!
- 추천 하는 강의: cs231n의 Lecture 11 | Detection and Segmentation
- 슬라이드: Slide 바로보기
Object detection
Object detection이란 이미지 내에서 물체의 위치와 그 종류를 찾아내는 것입니다. Object detection은 이미지 기반의 문제를 풀기 위해서 다양한 곳에서 필수적으로 사용되는 중요한 기법입니다. 대표적으로는 자율 주행을 위해서 차량이나 사람을 찾아내거나 얼굴 인식을 위해 사람 얼굴을 찾아내는 경우를 생각해 볼 수 있으며, 그 외에도 다양한 방식으로 이용되고 있습니다.
Object Localization
Object detection은 object의 class를 classification 할 뿐만 아니라 localization까지 함께 수행하는 작업입니다.
Localization이란 이미지 내에 하나의 object가 있을 때 그 object의 위치를 특정하는 것인데, Detection은 여러 개의 object가 존재할 때 각 object의 존재 여부를 파악하고 위치를 특정하여 classification을 수행하는 것입니다.
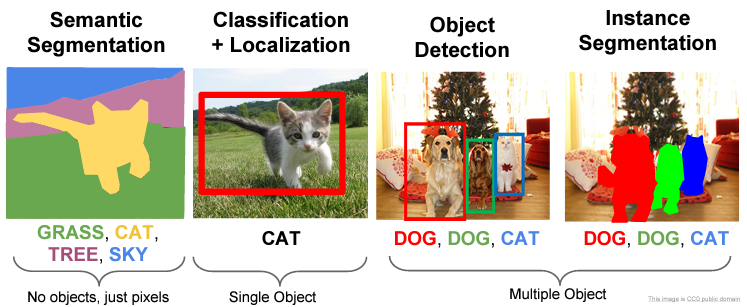
해당 슬라이드를 참고하면 Object Detection에서 여러 개의 object를 찾고 box를 통해 위치를 특정했다는 것을 알 수 있습니다.
기본적으로 object 한 개의 위치를 찾아내어 반복 과정을 거쳐 여러 object를 찾아낼 수 있다고 접근하면 좋습니다.
또한, 이해를 위해 간단히 용어를 정리하고 넘어가겠습니다.
용어 정리
1) Classification
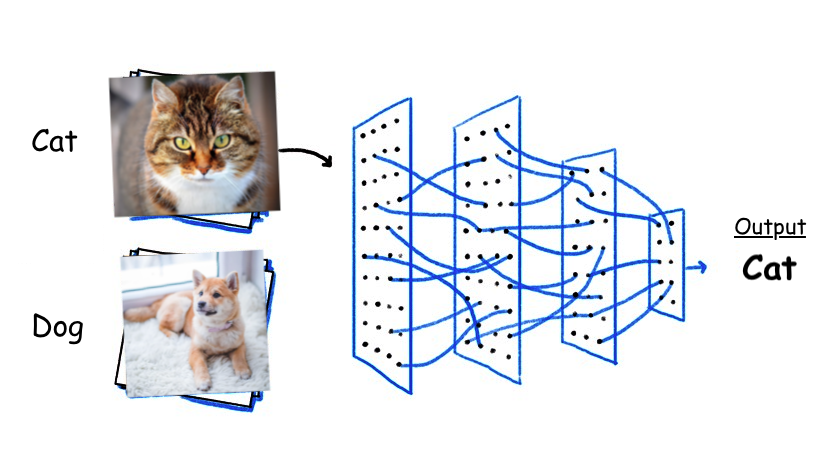
이미지 출처: 이곳
위 이미지처럼 고양이의 사진을 보고 Cat, 강아지 사진을 보고 Dog로 분류해주는 것이 classification입니다.
이미지를 다루는 딥러닝에서 입력으로 주어진 이미지 안에 어떤 object가 있는 지에 따라 class(label)을 구분하는 행위를 뜻합니다.
2) Localization
이미지 출처: 이곳
Localization은 위에서도 간단히 설명하였습니다. 위의 고양이 사진의 경우 이미지 안의 object가 어느 위치에 있는지 정보를 출력해주는 것입니다.
주로 Bounding box를 사용하고, 이 box의 좌표값의 정보를 뜻합니다. 대신 box의 꼭지점 pixel 정보가 아닌 left top, right bottom 좌표를 출력합니다.
3) Object Detection
Object Detection은 위에서 설명한 classification과 localizaion을 동시에 수행하는 것을 의미하고, 여러 개의 object를 찾을 수 있어야 합니다.
위의 슬라이드에서 단순 classification+localizaion과는 차이점이 있습니다. 서로 다른 object가 섞여 있어도 찾을 수 있습니다.
4) Object Recognition
Object recognition은 대체로 Object detection과 같은 의미로 쓰입니다. 그러나 detection은 object의 존재 유무만 의미하고 recognition은 이 object의 종류를 아는 것이라 해석하여 Object detection이 Object Recognition보다 작은 개념이 될 수도 있다고 합니다.
5) Object Segmentation
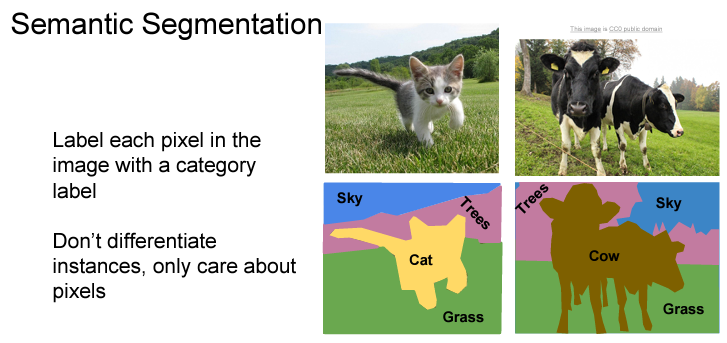
Object Segmentation이란 위 이미지와 같이 검출된 object의 형상에 따라 영역을 표시하는 것입니다. 보통 이미지의 pixel을 classification 하여 위와 같은 결과를 도출합니다. 단순히 foreground와 background를 구분하는 용도로 쓰이기도 합니다.
6) Semantic Segmentation
Semantic segmentation이란 Object segmentation 을 하면서, 같은 class인 object 들은 같은 영역 혹은 색으로 분할하는 것입니다.
7) Instance Segmentation
Instance segmentation이란 semantic segmentation 에서 한발 더 나아가서, 같은 class이어도 서로 다른 instance 들을 구분해주는 것입니다.
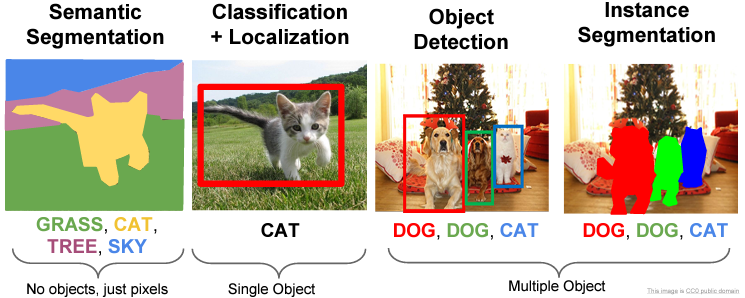
다시 한 번 슬라이드를 보고 개념 정리에 이해가 되셨으면 좋겠습니다!
Bounding Box
Bounding Box는 바운딩 박스, Bbox라는 용어로 불립니다.
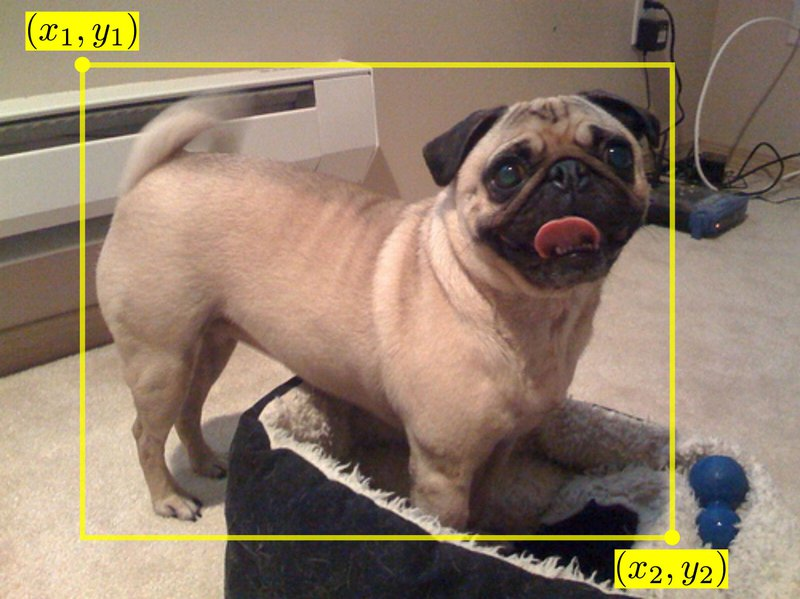
Bbox는 이미지 내에서 물체의 위치를 사각형으로 감싼 형태의 도형으로 정의하고 꼭짓점의 좌표로 표현하는 방식입니다.
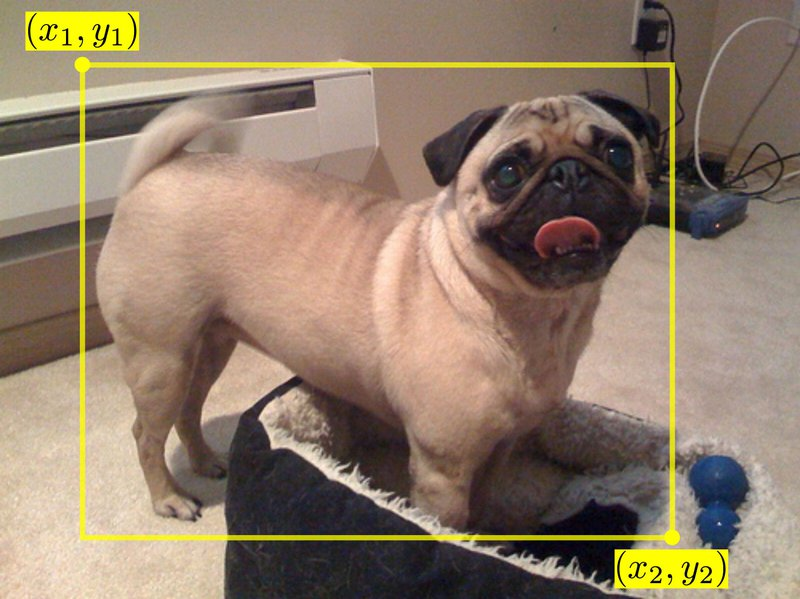
이 이미지로 보면 좌표가 left top과 right bottom 부분의 좌표로 표현되어 있습니다. 해당 방법 이외에 Bbox의 width와 height로 정의하는 방식이 있습니다. 이 경우 left top의 점에 대한 상대적인 위치로 물체의 위치를 정의할 수 있습니다.
직접 Bbox를 만들 수도 있습니다.

이미지 출처: 이곳
해당 이미지로 한 번 인물을 찾아보겠습니다.
from PIL import Image, ImageDraw
import os
img_path='' # 파일 경로 지정
img = Image.open(img_path)
draw = ImageDraw.Draw(img)
draw.rectangle((130, 30, 670, 450), outline=(0,255,0), width=2)
img코드를 실행하면

이런 결과가 나옵니다.
딱 얼굴만 나오게 변경하고 싶다면 코드의 좌표를 수정하면 됩니다.
from PIL import Image, ImageDraw
import os
img_path='' # 파일 경로 지정
img = Image.open(img_path)
draw = ImageDraw.Draw(img)
draw.rectangle((250, 30, 550, 400), outline=(0,255,0), width=2)
img
Intersection over Union
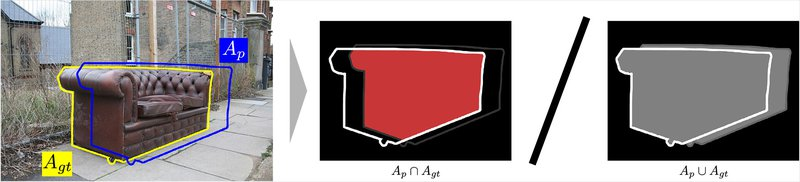
이미지 출처: 이곳
위에서 정의한 Bbox가 있을 때 우리가 만든 localization 모델이 인식한 결과를 평가하려면 지표(metric)를 사용해야 합니다.
각 좌표값의 차이를 L1이나 L2로 정의할 수도 있겠지만, 이는 박스가 크면 그 값이 커지고 작아지면 그 값이 작아져 크기에 따라 달라지는 문제가 생깁니다.
이렇게 면적의 절대적인 값에 영향을 받지 않도록 두 개 박스의 차이를 상대적으로 평가하기 위한 방법 중 하나가 IoU(Intersection over Union)입니다. 영문 그대로, 교차하는 영역을 합친 영역으로 나눈 값입니다.
IoU는 Bbox와 Ground Truth(정답) 영역으로 나눈 값인데, 만약 완전 동일하게 일치한다면 IoU의 값은 몇이 될까요?
동일한 값을 서로 나누면 1이 되기 때문에 IoU는 1이 됩니다.
