Object Detection 시리즈
0️⃣ 딥러닝 Object Detection(1) - 개념과 용어 정리
1️⃣ 딥러닝 Object Detection(2) - Localization 개념 정리
2️⃣ 딥러닝 Object Detection(3) - Sliding Window, Convolution
3️⃣ 딥러닝 Object Detection(4) - Anchor Boxes, NMS(Non-Max Suppression)
4️⃣ 딥러닝 Object Detection(5) - Architecture - 1 or 2 stage detector
오늘 주제를 포스팅하기 앞서 참고한 자료를 첨부합니다. 그럼 오늘도 열공🐣!
- 추천 하는 강의: cs231n의 Lecture 11 | Detection and Segmentation
- 슬라이드: Slide 바로보기
- 이전 포스팅: 딥러닝 Object Detection 개념과 용어 정리
Object Localization
Object Detection을 구성하기 위해, Object Localization을 알아야 합니다.

해당 이미지를 통해
- Image classification
- Classification with localization
- Detection
의 개념을 대충 파악할 수 있습니다.
단순히 이미지를 분류하는 것이 classification, 그리고 이미지 내에 car라는 object의 위치를 알아내는 것이 Classification with localization이고, localization을 통해 이미지에서 하나의 object가 아닌 여러 object를 인식하는 것을 Detection이라고 합니다.
Classification with localization
Detection을 위해서 classification과 localizaion을 동시에 수행해야 합니다. 이미지가 input으로 들어왔을 때, 동시에 처리할 수 있는 방법은 위와 같습니다.
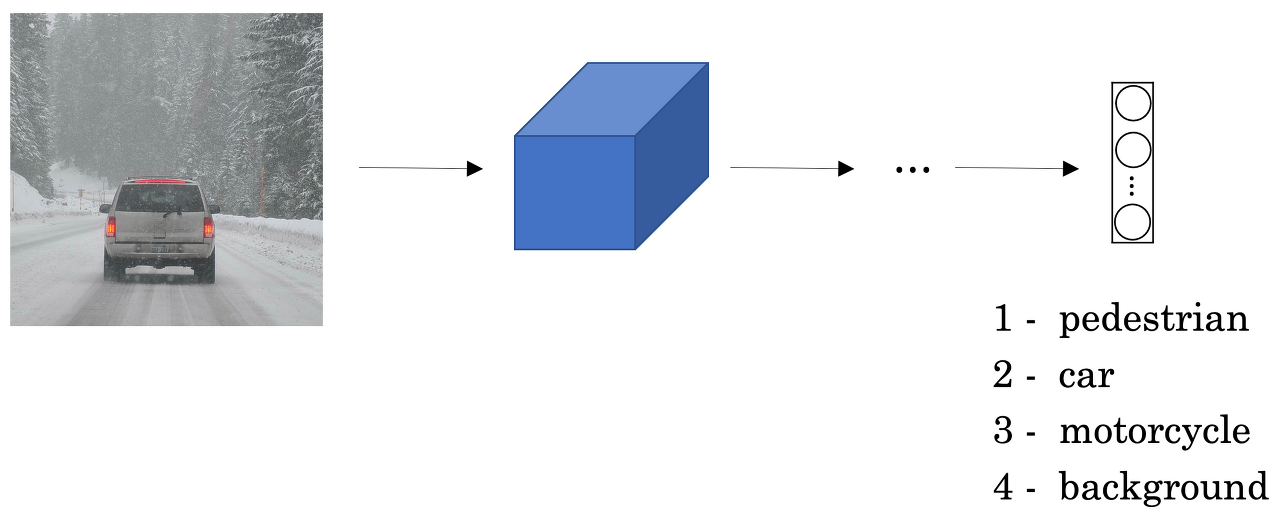
여러 layer를 가진 ConvNet에 Image를 입력하면, softmax를 적용한 Output Vector를 통해 이미지를 class별로 분류할 수 있었습니다.
이때, Output Vector에 분류 뿐만 아니라 위치까지 출력을 해주고 싶다면, Bounding Box의 좌표를 추가해주면 됩니다.
이미지 출처: 이곳
Bounding Box는 위 사진에서 보이는 것처럼 object의 경계선을 의미합니다.
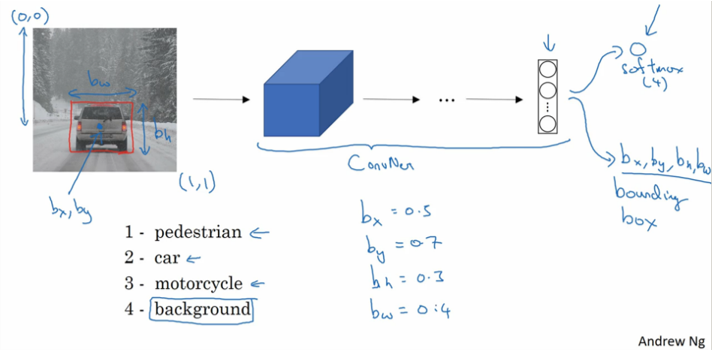
위 그림에는 Bounding Box의 좌표를 bx, by, bh, bw로 표기했습니다.
- bx : bounding box의 중심점 x좌표
- by : bounding box의 중심점 y좌표
- bh : bounding box의 높이
- bw : bounding box의 너비
- 위 예시에서 (bx, by, bh, bw)는 (0.5, 0.7, 0.3, 0.4)입니다.
neural network의 Training Set에 기존의 class 뿐만 아니라 Bounding Box의 좌표 4개를 추가해 training한다면 supervised learning을 통해 classification과 localization을 예측할 수 있습니다.
Target Label
Classification 모델을 만들 때는 convolution layer로 구성된 백본 네트워크(backbone network)를 통해서 이미지의 특성을 추출한 다음에, 클래스 간 분류를 위한 fully connected layer를 추가했습니다.
Classification 문제를 풀 때는 표현해야 할 class에 따라 최종 결과 노드의 개수가 정해졌습니다.
localization을 위해서는 박스의 위치를 표현할 output 노드 4개를 convolution layer로 구성된 backbone network 다음에 추가해야 합니다.

이미지 출처: 여기
라벨은 위와 같습니다.
- p_c: object가 있을 확률
- c1, c2, c3: class 1,2,3에 속할 확률
- p_c가 0일 경우: back ground일 때
필요에 따라, c1, c2, c3와 p_c를 분리하여 activation function을 적용하고 loss를 계산할 수 있음
Bbox(bounding box)를 정의하기 위한 4개의 노드
- b_x: left top
- b_y: right bottom
- b_h: Bbox의 높이
- b_w: Bbox의 폭
단, b_x, b_y, b_h, b_w는 모두 입력 이미지 너비 w, 높이 h로 각각 Normalize된 상대적인 좌표와 height/weight로 표시된다.
Classification 모델 대신 output을 추가한 localization 모델을 구성하는 방법
import tensorflow as tf
from tensorflow import keras
output_num = 1+4+3
# object_prob 1, bbox coord 4, class_prob 3
imput_tensor = keras.layers.Input(shape=(224,224,3), name='image')
base_model = keras.applications.resnet.ResNet50(
input_tensor=input_tensor,
include_top=False,
weights='imagenet',
pooling=None,
)
x = base_model.output
preds = keras.layers.Conv2D(output_num, 1,1)(x)
localize_model=keras.Model(inputs=base_model.input, outputs=preds)
localize_model.summary()위에서 만든 모델에는 위에서 설명한 y가 target label로 제공됩니다.
Quiz
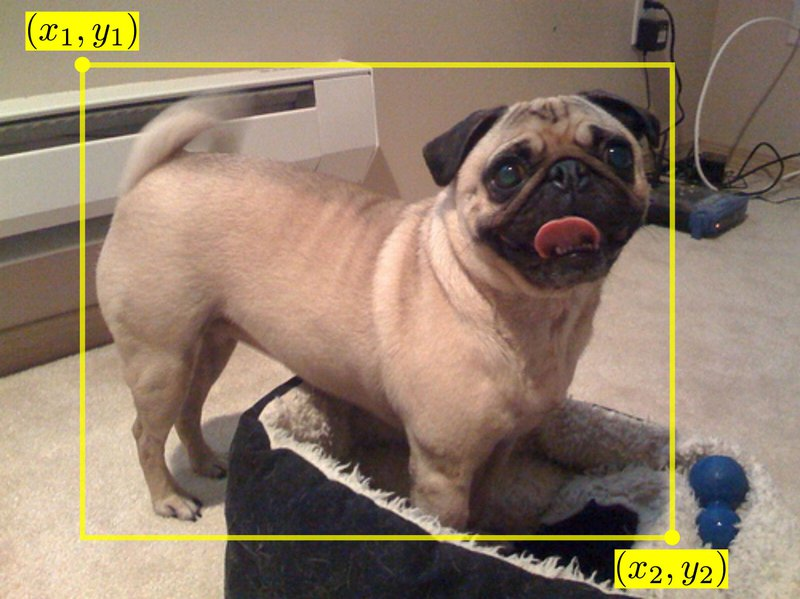
이미지 출처: 이곳
위에 제공된 입력 이미지에서 object detection을 위한 target label y를 직접 만들어보세요. 단, 이 경우엔 개(dog)에 대한 단일 object detection이므로 class label은 고려하지 않습니다. Ground Truth가 되는 bounding box의 좌표(position)은 위 그림에서와 같이 x1, y1, x2, y2입니다. 그리고 입력 image의 너비(width)는 w, 높이(height)는 h로 주어집니다.
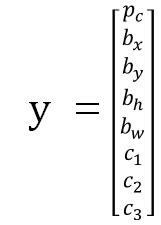
[참고 사진]
Target label y = [1, x1/w, y1/h, (y2-y1)/h, (x2-x1)/w] 입니다.
