Object Detection 시리즈
0️⃣ 딥러닝 Object Detection(1) - 개념과 용어 정리
1️⃣ 딥러닝 Object Detection(2) - Localization 개념 정리
2️⃣ 딥러닝 Object Detection(3) - Sliding Window, Convolution
3️⃣ 딥러닝 Object Detection(4) - Anchor Boxes, NMS(Non-Max Suppression)
4️⃣ 딥러닝 Object Detection(5) - Architecture - 1 or 2 stage detector
Anchor Boxes
이번 개념도 앤드류 응의 강의를 보고 정리를 해보겠습니다!
- 참고 영상: 앤드류 응의 Anchor Boxes
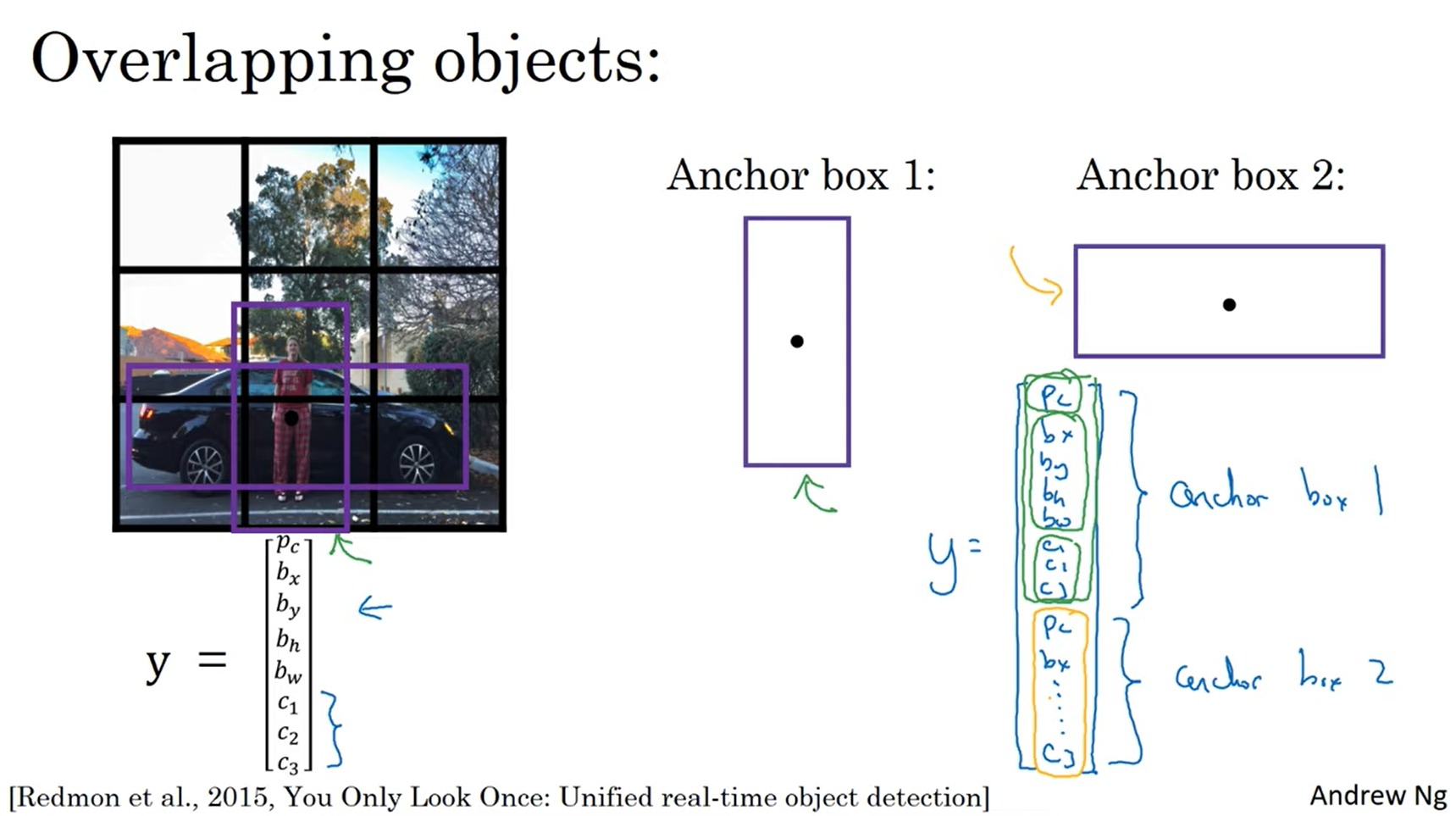
지금껏 본 Object Detection의 문제점 중 하나는 각각의 grid cell이 오직 하나의 object만 감지할 수 있느냐였습니다.
만약 grid cell이 여러 개의 object를 감지하고 싶다면 어떻게 해야 할까요? 그때 사용하는 것이 Anchor Boxes입니다!

[출처: https://unsplash.com/photos/I4pHtQX23k0/]
해당 이미지를 예시로 보면 자동차와 사람이라는 object가 겹쳐 있습니다. 이 경우를 Overlapping object라 부릅니다.
만약 사람, 자동차, 오토바이 세 가지의 class를 가진 vector y가 있다면 여기서 2개의 class를 분류하는데 어려움이 있을 것입니다.
그래서 Anchor box이라 부르는 두 개의 다른 모양을 가지고 할 일은 두 개 또는 일반적으로 많은 Anchor box를 이용하여 두 개의 class를 예측합니다.
[출처: http://datahacker.rs/deep-learning-anchor-boxes/]
Anchor box algorithm
-
training image에서 각각의 object는 object의 중심점을 포함하는 grid cell이 배정됩니다.
-
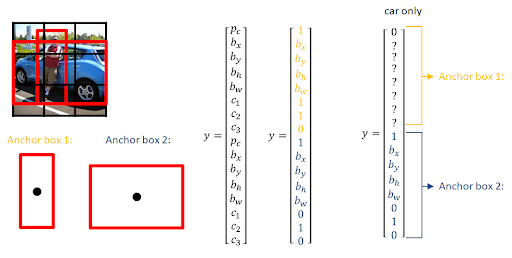
각 object는 이전과 같이 중심점이 있는 cell에 배정되고, 실제 ground truth와 object 사이 가장 높은 IOU를 갖는 grid cell과 Anchor box에 배정된다.
Anchor box Example
[출처: http://datahacker.rs/deep-learning-anchor-boxes/]
y가 무엇인지 살펴봅시다.
Anchor box 1은 y 벡터의 윗부분을 담당하고, Anchor box 2는 벡터 y의 아랫부분을 담당합니다.
Anchor box 1은 사람을 위해 설정한 크기, Anchor box 2는 차를 위해 설정한 크기입니다.
Anchor box 정리
-
y의 label을 보면 Anchor box가 2개가 됨에 따라서 output dimension이 두 배가 되었음을 알 수 있습니다. 그리고 각각은 정해진 Anchor box에 매칭된 object를 책임지게 됩니다.
-
한 grid cell에서 Anchor box에 대한 object 할당은 IoU로 할 수 있습니다. 인식 범위 내에 object가 있고 두 개의 Anchor box가 있는 경우 IoU가 더 높은 Anchor box에 object를 할당하게 됩니다.
Bounding Box와 Anchor box 차이
-
네트워크가 predict한 object의 위치가 표현된 박스로서, 네트워크의 출력이다.
-
네트워크가 detect해야 할 object의 shape에 대한 가정(assumption)으로서, 네트워크의 입력이다.
Quiz
차와 사람을 Detection하기 위한 모델의 output이 4x4 grid이고 각 cell에 Anchor box를 9개씩 정의한 경우 output의 dimension은 어떻게 될까요?
- 4x4x63
Output dimension은 [Batch size, 4, 4, 9x(1+4+2)]이 됩니다.
아 저는 여기서 잠깐 이해를 못해서 계속 😑 이 표정으로 살펴보았는데요. y 벡터가 있는 위의 자료를 같이 보시면 이해가 되실 것 같아요.
b_x, b_y, b_w, b_h 의 Bounding Box의 좌표 4개, 확률 p_c, class의 갯수가 됩니다.
NMS(Non-Max Suppression)
만약 2x2 또는 더 큰 Grid cell에서 object가 있는지에 대한 결과를 받게 되면 매우 많은 object를 받게 됩니다.
Anchor box를 사용하지 않더라도 2x2격자에 모두 걸친 object가 있는 경우 하나의 object에 대해 4개의 Bounding box를 얻게 되죠. 이렇게 겹친 여러 개의 박스를 하나로 줄여줄 수 있는 방법 중 하나가 NMS(non-max suppression) 입니다.
NMS는 겹친 박스들이 있을 경우 가장 확률이 높은 박스를 기준으로 기준이 되는 IoU 이상인 것들을 없앱니다.
이때 IoU를 기준으로 없애는 이유는 어느 정도 겹치더라도 다른 물체가 있는 경우가 있을 수 있기 때문입니다. 이때 Non-max suppression은 같은 class인 물체를 대상으로 적용하게 됩니다.
- 참고 영상: 앤드류 응의 Nonmax Suppression
해당 개념은 알고리즘이 같은 object를 여러 번 감지해서 어떤 object를 한 번이 아니라 여러 번 detect한다는 문제에서 나왔습니다.
Non-Max Suppression은 알고리즘이 각 object를 한 번씩만 감지하게 보장합니다.

해당 사진을 보면 같은 object에 여러 box가 생겼고, p_x가 나타나 있습니다. Non-Max Suppression는 각 detect의 확률을 살펴보고 가장 큰 값을 고릅니다. 그리고 그 가장 큰 값이 object를 가장 잘 찾았다고 생각하는 것입니다.
그리고 0.6, 0.7의 값이 있다면 서로 찾은 object가 겹치는 영역이 비슷할 것입니다. 최댓값이 아닌 이런 값들을 억제 시켜주는 역할을 합니다.
Non-Max Suppression algorithm

아직 버려지지 않고 남은 Bbox가 있다면 반복적으로 가장 높은 확률 Pc 가지는 것을 고르고, 그것을 예측의 결과로 내놓습니다.
직사각형 중 예측값이 아니거나 이전에 버려지지 않은 것을 버립니다. 즉, 이전 단계에서 도출된 직사각형과 많이 겹처서 높은 IOU를 가지는 Bbox를 버립니다.
Quiz
NMS(Non-max suppression)는 IoU를 기준으로 박스를 없애게 됩니다 NMS의 IoU기준이 0.3인것과 0.5인 것중 어떤 것이 박스가 많이 남게 될까요?
- IoU기준이 일정 이상인 경우를 NMS연산을 통해서 가장 높은 score인 하나를 남기게 됩니다. 그렇다면 문턱이 낮은 것이 많은 박스를 없애게 되겠죠. 따라서 NMS의 IoU기준이 0.3인 경우가 더 많은 박스가 사라지고, 0.5인 경우가 많은 박스가 남게 됩니다.
