공부 벌레가 되고 싶다...🐛
참고한 교재의 chapter 3-2에 해당됩니다.
참고 자료
📕 교재: 혼자 공부하는 머신러닝+딥러닝
💻 유튜브 강의: https://youtu.be/0mrLRkgbjA0
🔗 Linear Regression 온라인 교재
단순 선형 회귀
단순 선형 회귀식은 아래와 같습니다.
즉 가 얼마나 변하냐에 따라 의 변화량을 추정할 수 있습니다.
은 절편, 은 의 기울기 또는 계수라고 부릅니다.
여기서의 목표는 데이터를 가장 그럴듯하게 나타내줄 수 있는 기울기와 절편을 찾는 것입니다!
회귀 분석에서 가장 중요한 개념이 적합값과 잔차(residual)입니다. 따라서 회귀식은 명시적으로 오차항 를 포함합니다.
오차항은 측정상의 오차나 모든 정보를 파악할 수 없는 점 등 현실적인 한계로 인해 발생하는 다양한 불확실성이 여기에 포함됩니다.
이것은 일종의 ‘잡음(noise)’이라고 합니다. 이런 잡음은 이론적으로 보면 평균이 0이고 분산이 일정한 정규 분포를 띄는 성질이 있습니다.
잔차(residual)는 회귀 모델의 예측값(적합값)과 실측값 차이를 의미합니다.
이는 우리가 가정한 오차항()의 조건을 충족하는지 확인하는 것입니다.
*적합값은 예측값을 의미합니다.
식은 위와 같습니다.
선형 회귀 모델이란?
선형 회귀 모델을 만들기 위해 4가지의 가정을 만족해야 한다고 합니다.
- 선형성: 선형성은 예측하고자 하는 종속변수 Y와 독립변수 X 사이 선형성을 만족하는 특성을 의미합니다.
- 선형성을 만족하지 않는 경우❓
선형성을 만족하지 않는 경우, 데이터를 변환하는 방법이 필요합니다.
그 종류로는
- 로그 변환
- 지수 변환
- 루트 변환
이 있다고 합니다.
다중 선형회귀를 진행하고 있다면 다른 새로운 변수를 추가하거나, 선형성을 만족하지 않는 변수를 제거하는 방법도 있습니다.
혼공머 책에서는 다른 변수를 추가하는 경우가 소개되었습니다.
- 독립성: 독립성이란 독립변수 X간의 상관관계 없이 독립성을 만족하는 특성입니다.
독립변수들 간의 상관관계가 있는 경우를 다중공선성이라 부르며, 제거할 필요가 있습니다.
하지만 단순 선형 회귀와 같이 변수가 1개인 경우에는 해당되지 않습니다.
- 등분산성: 분산이 동일한 경우를 의미합니다. 어떠한 특정한 패턴이 없이 고르게 분포해야 하는 특성이고, 주체는 잔차입니다.
- 잔차가 서로 상관관계가 있다면❓
추정된 회귀식으로 설명되는 않은 부분에서 서로 관계가 있는 경우를 의미하고, 이는 회귀식의 설명력을 약하게 만듭니다.
- 정규성: 잔차가 정규성을 만족하는지에 대한 특성
잔차가 정규 분포 모양을 분포하고 있다면 좋은 선형 회귀 모델이라고 말할 수 있습니다.
산점도, scatter
X, Y의 관계를 파악하기 위한 방법으로 산점도가 있습니다.
책에서도 plt.scatter()을 통해 그래프를 계속 불러오고 있습니다.
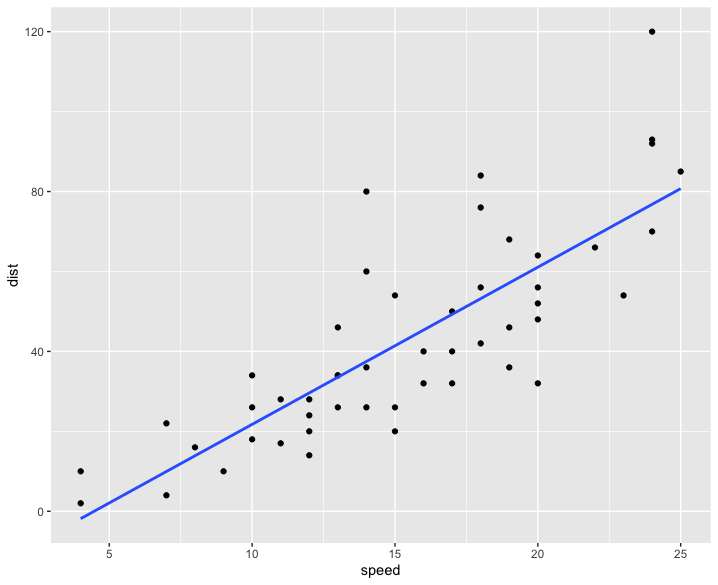
여기서는 speed(x축)가 증가할 수록 dist(y축)도 증가함을 알 수있고, 어느 정도 선형성을 만족한다고 볼 수 있습니다.
회귀 모델 생성
회귀를 만들기 위해서 필요한 값이 두 가지 있습니다.
- 절편
- x의 기울기
LinearRegression 클래스가 값을 찾아 줍니다. 이 부분에서 헷갈렸던 용어가 있었는데요.
기울기와 절편을 알려주는 lr 객체의 coef_와 intercept_ 의 속성이 존재합니다.
여기서 두 가지의 속성 의미가 헷갈렸습니다.
머신러닝에서 기울기를 coefficient 또는 가중치(weight)라고 부른다고 합니다.
더 찾아보니 , 를 회귀 계수(Regression coefficient)라고 부른다고 합니다.
결론적으로 coef가 기울기, intercept가 절편입니다.
그리고 이 두 가지의 값은 알고리즘이 찾은 값이라는 의미로 모델 파라미터(model parameter)라고 합니다.
머신러닝 알고리즘 훈련 과정은 최적의 모델 파라미터를 찾는 과정이기 때문입니다.
K-NN 에는 모델 파라미터가 없습니다. 여기서 파라미터(Parameter)와 하이퍼 파라미터(Hyper parameter)의 개념 차이를 정확히 알고 있는 것이 좋겠다는 생각이 들었습니다.
다항 회귀(Polynomial Regression)
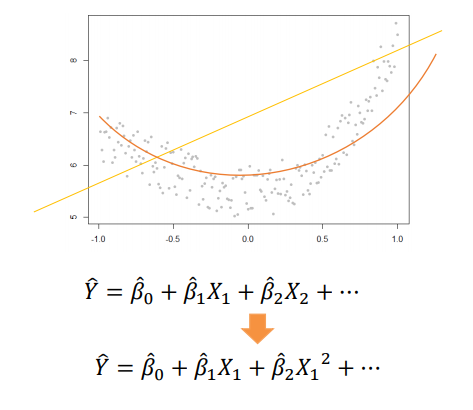
선형 회귀는 직선인 노란색 선, 다항 회귀는 주황색 선으로 볼 수 있습니다.
-
다항 회귀는 이름 그대로 독립 변수가 다항식으로 구성되는 회귀 모델입니다. (=독립변수의 차수를 높이는 형태)
-
항이 여러 개인 가설 함수로 결과를 예측하는 회귀 분석 방법을 의미합니다.
-
항은 제곱근이나 2차항, 3차항 등 다양하게 있으며 함수의 형태가 비선형이라는 특징이 있습니다.
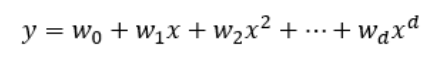
위의 그래프처럼 다차원인 회귀식이 단순 선형 모델의 한계를 어느 정도 극복할 수 있습니다.
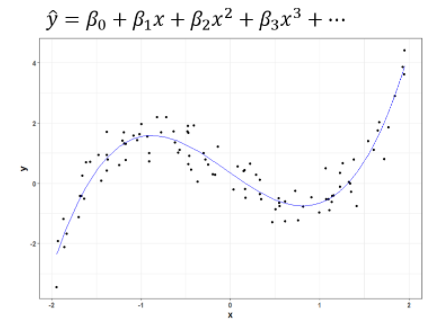
위 그림처럼 만약 종속변수인 와 독립변수인 가 선형 관계가 아닌 곡선 형태를 갖는다면 독립변수에 지수승을 붙여서 여러 개의 변수로 만들어 회귀 모델을 구성하는 기법을 말합니다.
책에서는 농어의 길이에 제곱을 더해 () 변수를 추가해주었습니다.
*2차 방정식은 비선형(non-linear) 아닌가요? 선형 회귀라고 부를 수 있을까요?
책에 설명을 빌리자면, 길이의 제곱도 하나의 feature가 되기 때문에 무게는 길이와 의 선형 관계로 표현할 수 있다고 합니다!
예시
부동산에서 집값을 예측하는 경우입니다.
땅의 가로, 세로 길이가 주어졌을 때 면적(=가로*세로)으로 만들어서 면적에 따른 결과를 예측할 수 있습니다.
새 feature 에 대해 그래프를 그렸을 때 데이터를 잘 표현하는 비선형 함수를 찾는 것입니다.
새 feature 에 대해서도 feature scaling 을 적절히 해주어야 한다.
특히, 실수의 곱이나 범위가 큰 두 feature의 곱은 너무 0에 가깝거나 너무 큰 수가 되버릴 수 있습니다.
또한, feeature가 추가될수록 overfitting이 일어날 가능성이 커서 고차항을 추가 시에는 신중히 해야 합니다.
그래서 저는 다항회귀가 선형(linear)이냐, 비선형(non-linear)인가? 에 대한 의문이 아직 풀리지 않았는데요.🤔
책에서는 함수의 형태가 비선형일 수 있지만, 여전히 선형 관계로 표현할 수 있다고 합니다.
회귀 모델에서 선형과 비선형을 구분할 때는 독립 변수와 종속 변수의 관계를 기준으로 생각하면 안 되고,
변수가 아닌 회귀 계수로 결정해야 한다고 합니다.
앞서 말했듯이, 회귀 계수는 , 등의 절편과 기울기를 의미합니다.(parameter, weight를 의미)
정리하자면, 회귀 모델은 모델링 대상을 회귀 계수의 선형 결합만으로 표현할 것인지 여부에 따라 ‘선형’ 회귀 모델과 ‘비선형’ 회귀 모델로 구분된다고 합니다.
한 번 다시 정리하는 시간이 개인적으로 필요할 것 같습니다.
👉 Linear Regression에서 'Linear'의 의미에 대해 설명한 영상! https://youtu.be/qvLOauLWsfo
