👩🔬 이번에는 혼공머 책의 챕터 9-1 파트입니다.
참고 자료
📕 혼자공부하는머신러닝+딥러닝, 한빛미디어
순차 데이터
순차 데이터(sequential data)는 텍스트나 시계열 데이터(time series data)와 같이 순서에 의미가 있는 데이터를 말합니다.
'I am a boy'
'boy am a I'
의 차이를 보시면 이해가 되실 겁니다.
다른 예시로 일별 온도를 기록한 데이터에서 날짜 순서를 섞는다면 내일의 온도를 예상하기 어렵습니다.
지금까지 보았던 Data는 순서와 상관 없었습니다.
MNIST dataset 같은 경우도 random하게 sample을 섞은 후 train과 validation set으로 나누었습니다.
하지만 텍스트 데이터는 단어의 순서가 중요한 순차 데이터입니다. context가 있다고도 표현합니다.
Fully-Connected neural network나 Convolution neural network는 이런 기억 장치가 없습니다.
하나의 sample or batch를 사용해 forward pass를 수행하고 나면 그 sample은 버려지고 다음 sample을 처리할 때 재사용하지 않습니다.
이렇게 입력 데이터의 흐름이 앞으로만 전달되는 신경망을 feedforward neural network라고 했습니다.
이에 FC neural network와 conv neural network가 속합니다.
순환 신경망
순환 신경망(Recurrent neural network, RNN)은 일반적인 완전 연결 신경망과 비슷합니다. 여기서 이전 데이터의 처리 흐름을 순환하는 고리 하나만 추가하면 됩니다.
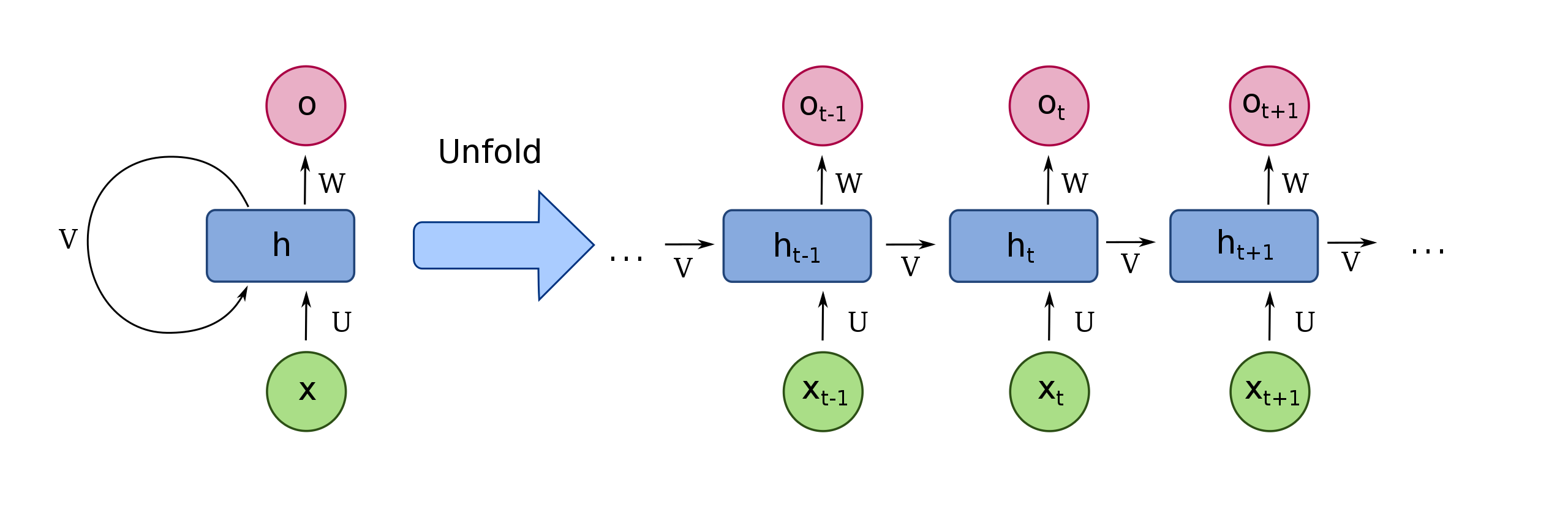
뉴런의 출력이 다시 자기 자신으로 전달됩니다.
어떤 샘플을 처리할 때 바로 이전에 사용했던 데이터를 재사용합니다.
만약 A, B, C 3개의 sample을 처리하는 순환 신경망의 뉴런이 있다고 가정하면,
- A를 처리한 출력 는 다시 뉴런으로 들어갑니다.
- 해당 출력에는 A에 대한 정보가 들어 있습니다.
- B를 처리할 때 앞에서 A를 사용해 만든 를 사용합니다.
- 는 와 B를 사용해서 만든 출력값이며 A에 대한 정보도 포함되어 있습니다.
- 다음 C를 처리하기 위해 를 사용합니다.
순환 신경망은 '이전 샘플에 대한 기억'을 갖고 있습니다. 이렇게 샘플을 처리하는 한 단계를 timestep이라고 합니다.
순환 신경망은 이전 timestep의 sample을 기억하지만, timestep이 오래될수록 순환되는 정보의 기억은 희미해집니다.
이런 과정을 이미지로 나타내면

이와 같습니다. 앞의 정보는 점점 희미해지기 마련입니다.
순환 신경망에서는 특별히 층(layer)를 셀(cell)이라 부릅니다.
한 셀에는 여러 개의 뉴런이 있지만 완전 연결 신경망과 달리 뉴런을 모두 표시하지 않으며, 하나의 셀로 층을 표현합니다.
그리고 셀의 출력을 은닉 상태(hidden_state)라고 합니다.
용어를 정리하자면
timestep: sample을 처리하는 한 단계
cell: 순환 신경망의 층
hidden state: 셀의 출력
합성곱 신경망처럼 신경망마다 부르는 이름이 정리된 곳마다 살짝 다르기도 합니다.
하지만 기본 구조는 같으니 개념이 잘 정리되었으면 합니다.
입력에 어떤 가중치를 곱하고 활성화 함수를 통과시켜 다음 층으로 보냅니다.
달라지는 것은 층의 출력(즉, hidden state)를 다음 timestep에 재사용한다는 점입니다.
일반적으로 hidden layer의 활성화 함수로는 하이퍼볼릭 탄젠트 함수인 를 많이 사용합니다.
또 차이점으로 순환 신경망의 뉴런에는 가중치가 하나 더 있습니다. 이전 타임스텝의 hidden state에 곱해지는 가중치입니다.
- 는 입력에 곱해지는 가중치
- 는 이전 타임스텝의 hidden state에 곱해지는 가중치
입니다.
그리고 뉴런 하나마다 절편(bias)가 포함됩니다.
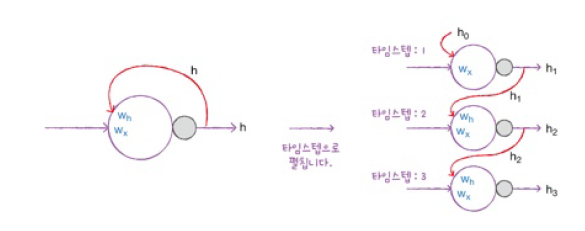
위의 그림으로 살펴보면 셀의 출력(hidden state)이 다음 timestep에 재사용되기 때문에 timestep으로 셀을 나누어 그릴 수 있습니다.
타입스텝 1에서의 셀의 출력 이 다음 타임스텝 2에 주입되고, 와 곱해집니다.
이런 과정이 반복되어 최종 hidden state 출력값이 나오게 되는 구조입니다.
또한, 여기서 알 수 있는 점은 모든 timestep에 사용되는 가중치 는 하나라는 점입니다.
가중치 는 timestep에 따라 변화되는 뉴런의 출력을 학습합니다.
셀의 가중치와 입출력
hidden state:
output cell
RNN의 hidden state 연산을 vector와 matrix의 연산으로 이해해보겠습니다.
RNN의 입력 는 대부분의 경우 단어 벡터로 생각할 수 있고, 단어 벡터의 차원을 라고 하고, hidden state의 크기를 라고 했을 때 각 벡터와 행렬의 크기는 아래와 같습니다.
배치 크기가 1이고, 와 두 값 모두를 4로 가정했을 때, RNN의 hidden state 연산을 그림으로 표현하면 아래와 같습니다.
이때 를 계산하기 위한 활성화 함수로는 주로 하이퍼볼릭탄젠트 함수(tanh)가 사용됩니다.
위의 식에서 각각의 가중치 의 값은 하나의 층에서는 모든 시점에서 값을 동일하게 공유합니다.
여기서 말하는 층은 timestep을 의미합니다.
하지만 hidden state가 2개 이상일 경우에는 각 hidden state에서의 가중치는 서로 다릅니다.
출력층은 결과값인 를 계산하기 위한 활성화 함수로는 푸는 문제에 따라서 다릅니다.
예를 들어, 이진 분류를 해야하는 경우라면 출력층에 로지스틱 회귀를 사용하여 시그모이드 함수를 사용합니다.
다중 클래스 분류를 해야하는 경우라면 출력층에 소프트맥스 회귀를 사용하여로 소프트맥스 함수를 사용할 수 있습니다.
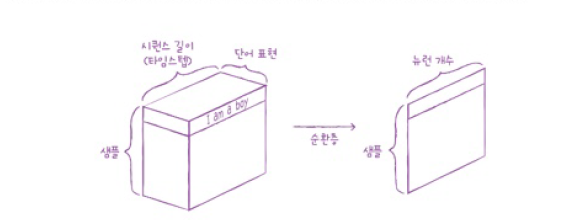
해당 그림을 살펴보면 하나의 샘플은 시퀀스 길이와 단어 표현을 가진 2차원 배열임을 알 수 있고, 순환층을 통과하여 1차원 배열로 바뀝니다.
1차원 배열의 크기는 순환층의 뉴런의 수에 따라 결정됩니다.
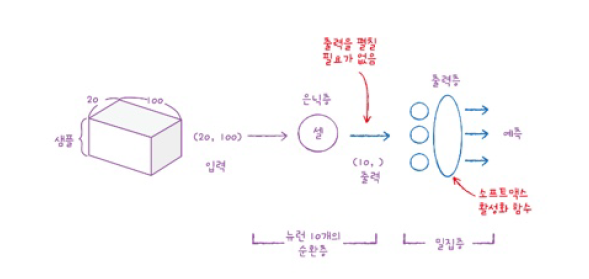
이 예에서 샘플은 20개의 타임스텝으로 이루어져 있고, 각 타임스텝은 100개의 표현 또는 특성으로 이루어지게 했습니다.
RNN cell을 통과하면 모든 타임스텝을 처리하고 난 후의 hidden state만 출력됩니다.
여기서 hidden state의 크기는 cell에 있는 뉴런의 수이므로 (10,)이 됩니다.
샘플마다 셀이 1차원 배열을 출력하여 바로 출력층에 연결할 수 있고, 다중 분류의 경우이므로 출력층에 3개의 뉴런과 소프트맥스 함수를 사용했습니다.
여기까지가 아주 기초적인 RNN 내용을 다룬듯합니다.
순환 신경망의 경우 기존에 배웠던 완전연결신경망이나 합성곱 신경망과 용어가 많이 달라서 혼란스러운 점도 있는 것 같습니다.
다들 정리하는데 도움되었으면 좋겠습니다. 감사합니다.
