본 프로젝트는 멋쟁이사자처럼 AI School 6기 8팀이 함께 진행했습니다.





<사용 코드>
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import cufflinks as cf
import json
cf.go_offline(connected=True)def get_font_family():
"""
시스템 환경에 따른 기본 폰트명을 반환하는 함수
"""
import platform
system_name = platform.system()
if system_name == "Darwin" :
font_family = "AppleGothic"
elif system_name == "Windows":
font_family = "Malgun Gothic"
else:
# Linux(colab)
!apt-get install fonts-nanum -qq > /dev/null
!fc-cache -fv
import matplotlib as mpl
mpl.font_manager._rebuild()
findfont = mpl.font_manager.fontManager.findfont
mpl.font_manager.findfont = findfont
mpl.backends.backend_agg.findfont = findfont
font_family = "NanumBarunGothic"
return font_family
# style 설정은 꼭 폰트설정 위에서 합니다.
# style 에 폰트 설정이 들어있으면 한글폰트가 초기화 되어 한글이 깨집니다.
plt.style.use("seaborn")
# 폰트설정
plt.rc("font", family=get_font_family())
# 마이너스폰트 설정
plt.rc("axes", unicode_minus=False)
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'df = pd.read_csv("data/서울시_우리마을가게_상권분석서비스(신_상권_추정매출)_2021년.csv", encoding="cp949")
df1 = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(상권영역).csv", encoding="cp949", usecols=['상권_코드_명',"시군구_코드",'엑스좌표_값','와이좌표_값'])
df = df.merge(df1, on="상권_코드_명", how="left")
k = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(상권영역).csv", encoding="cp949", usecols=["엑스좌표_값","와이좌표_값"])
k["엑스좌표_값"] = pd.to_numeric(k["엑스좌표_값"], errors="coerce")
k["와이좌표_값"] = pd.to_numeric(k["와이좌표_값"], errors="coerce")
k = k.dropna()
k.index=range(len(k))
k.tail()
from pyproj import Proj, transform
import folium
import pyproj
def project_array(coord, p1_type, p2_type):
"""
좌표계 변환 함수
- coord: x, y 좌표 정보가 담긴 NumPy Array
- p1_type: 입력 좌표계 정보 ex) epsg:5181
- p2_type: 출력 좌표계 정보 ex) epsg:4326
"""
p1 = pyproj.Proj(init=p1_type)
p2 = pyproj.Proj(init=p2_type)
fx, fy = pyproj.transform(p1, p2, coord[:, 0], coord[:, 1])
return np.dstack([fx, fy])[0]
coord = np.array(k)
coord
p1_type = "epsg:5181"
p2_type = "epsg:4326"
# project_array() 함수 실행
result = project_array(coord, p1_type, p2_type)
result
k["위도"] = result[:,1]
k["경도"] = result[:,0]
df = df.merge(k, on="엑스좌표_값", how="left")df2 = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(자치구별 상권변화지표).csv", encoding="cp949", usecols=["시군구_코드","시군구_코드_명"])df = df.merge(df2, on="시군구_코드", how="left")df.shape(147665, 85)
subset2 = df[['상권_구분_코드_명','시군구_코드_명','분기당_매출_금액']]
subset2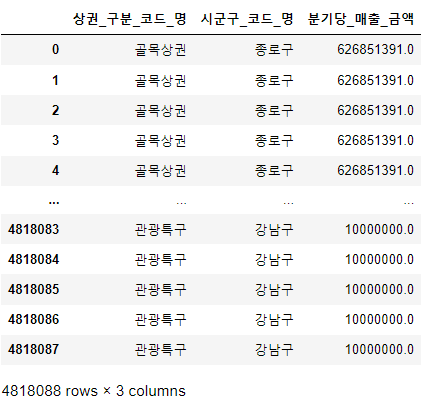
golmok = subset2.groupby(['시군구_코드_명','상권_구분_코드_명'])['분기당_매출_금액'].sum()
golmok.iplot(kind='bar')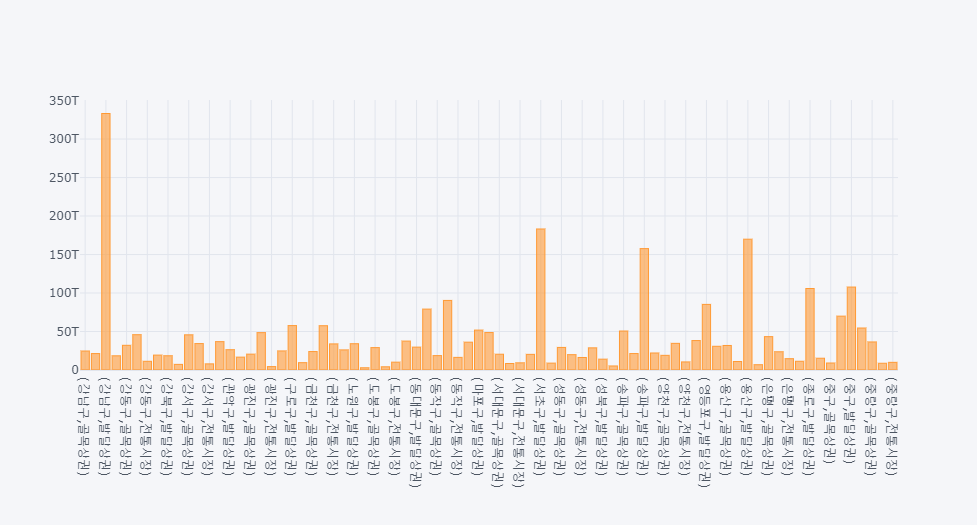
subset = df[['기준_분기_코드','분기당_매출_금액','시군구_코드_명']]subgb = subset.groupby(['시군구_코드_명','기준_분기_코드'])['분기당_매출_금액'].sum().sort_index()df2 = pd.read_excel('data/상권분석_인구수_2021.xlsx')
df2.info()
df2['지역'] = df2['지역'].astype(str).str.strip()
subset = df2.groupby(["지역"])['길단위 유동인구'].sum().sort_values()
subset.iplot(kind="bar",color='blue',title='유동인구')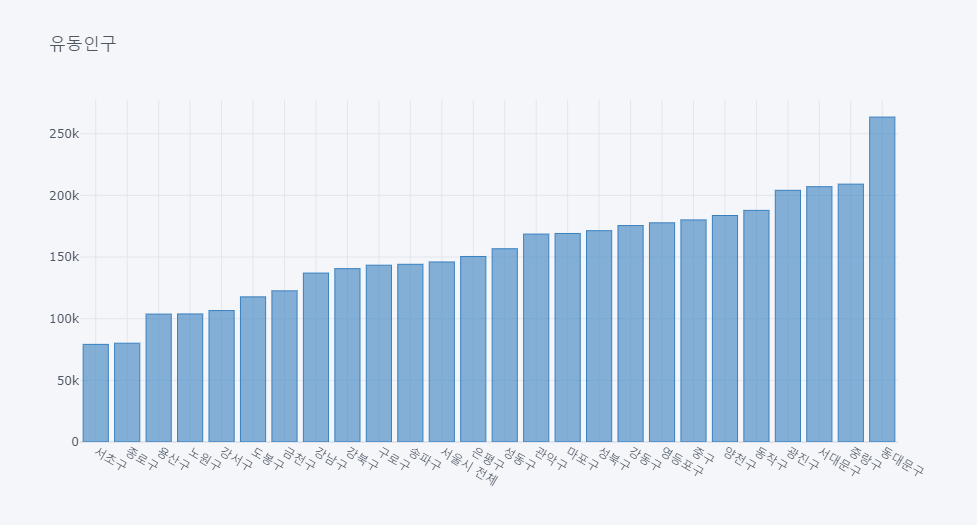
subgb2 = df.groupby(['시군구_코드_명'])['분기당_매출_금액'].sum().sort_values()
subgb2.iplot(kind="bar")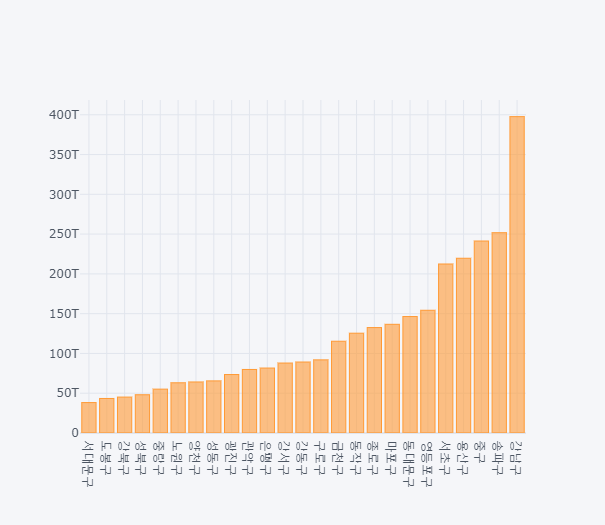
subgb.iplot(kind="bar",title='분기당 매출 금액')
subset.iplot(kind="bar",color='blue',title='유동인구')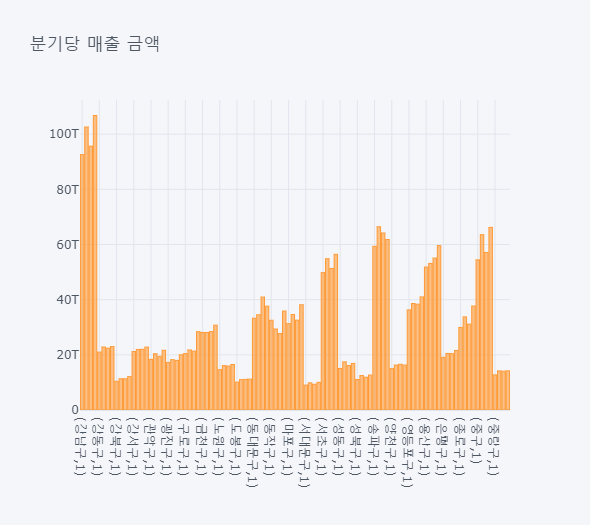
df=pd.read_csv("data/인구_점포_개폐업_통합_2021.csv")데이터 형태 파악
df.shape(104, 12)
쉼표를 없애주고 데이터 타입을 올바르게 변환
object_list=['전체 점포수','프랜차이즈 점포수','일반 점포수','길단위 유동인구', '개업수', '폐업수']
for i in object_list:
df[i]=df[i].str.replace(',', '').astype('int64')
df['지역'] = df['지역'].str.strip()서울의 점포수와 개/폐업, 주거인구, 직장인구 분석
서울 구별 전체 점포수, 개업수, 폐업수, 주거 인구, 직장 인구 비교하기
- 서울시 전체에 대한 행은 전부 드랍 후 진행
서울시 각 구별 전체 점포수 살펴보기
df_a = df[df['지역'] != '서울시 전체']
plt.figure(figsize=(12, 10))
sns.barplot(data=df_a.sort_values('전체 점포수'),x='전체 점포수',y='지역', ci=None)
_ = plt.title('서울시 구별 21년도 전체 점포수')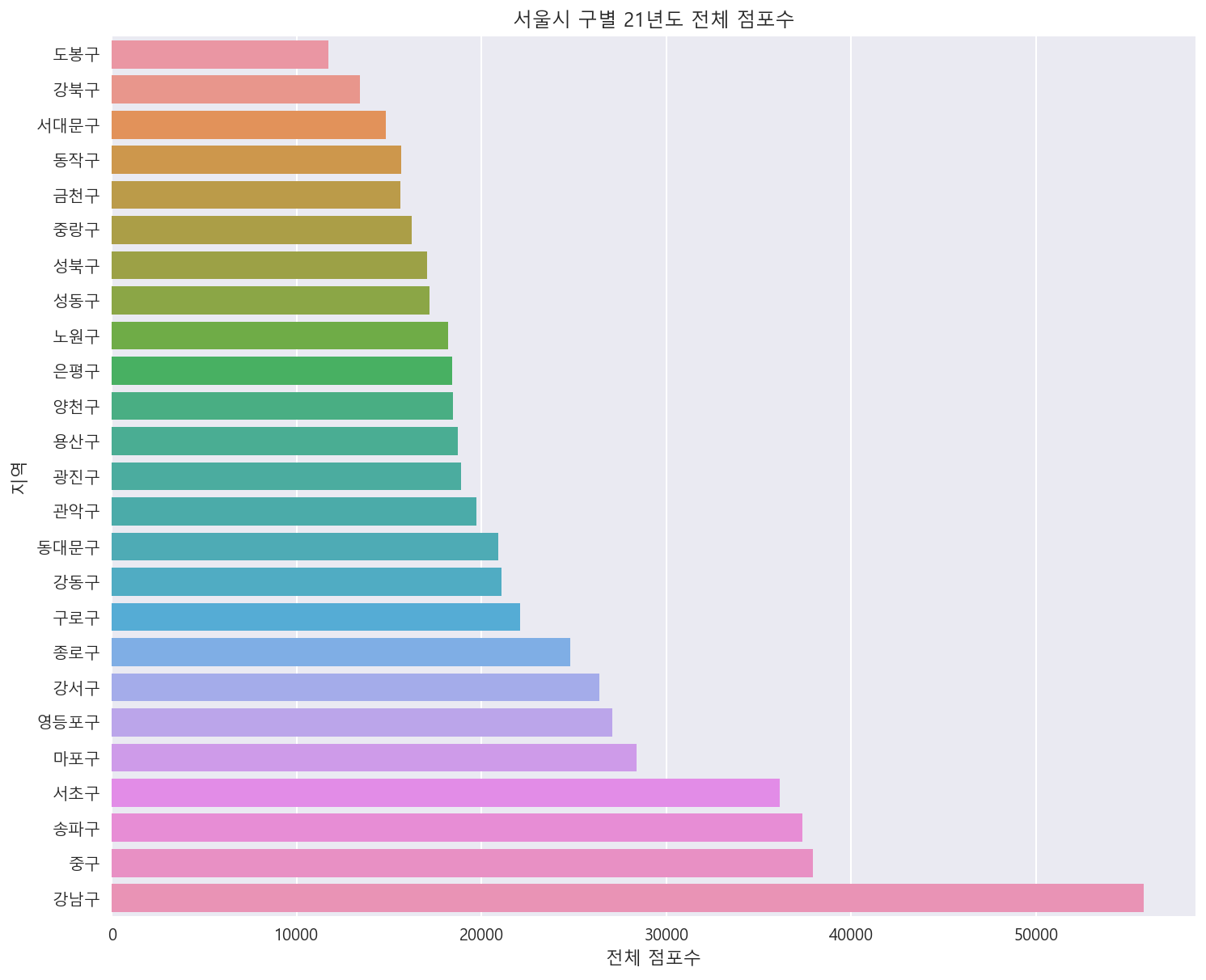
서울시 각 구별 전체 개업수 살펴보기
plt.figure(figsize=(12, 10))
sns.barplot(data=df_a.sort_values('개업수'),x='개업수',y='지역', ci=None)
_ = plt.title('서울시 구별 21년도 개업수')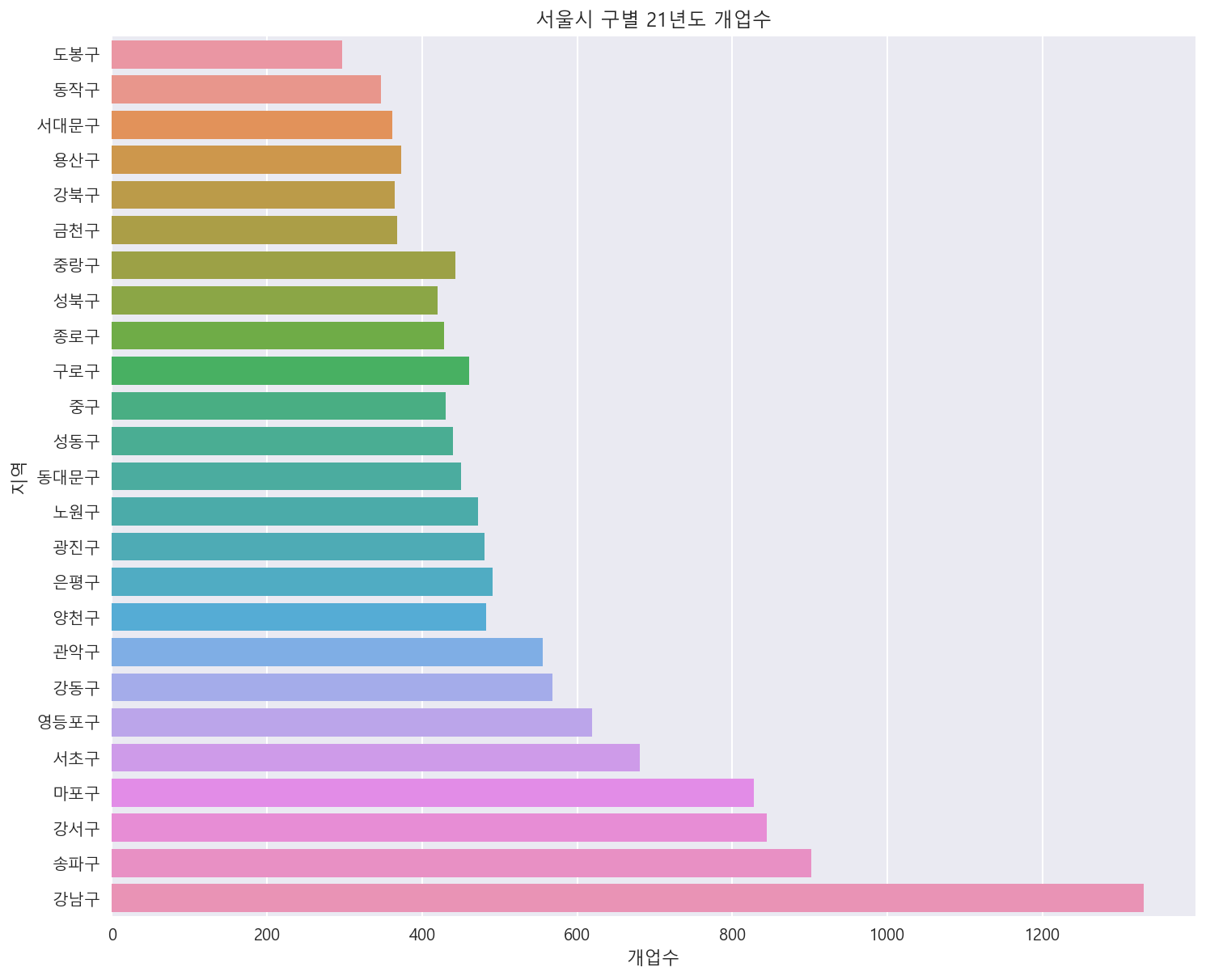
서울시 각 구별 전체 폐업수 살펴보기
plt.figure(figsize=(12, 10))
sns.barplot(data=df_a.sort_values('폐업수'),x='폐업수',y='지역', ci=None)
_ = plt.title('서울시 구별 21년도 폐업수')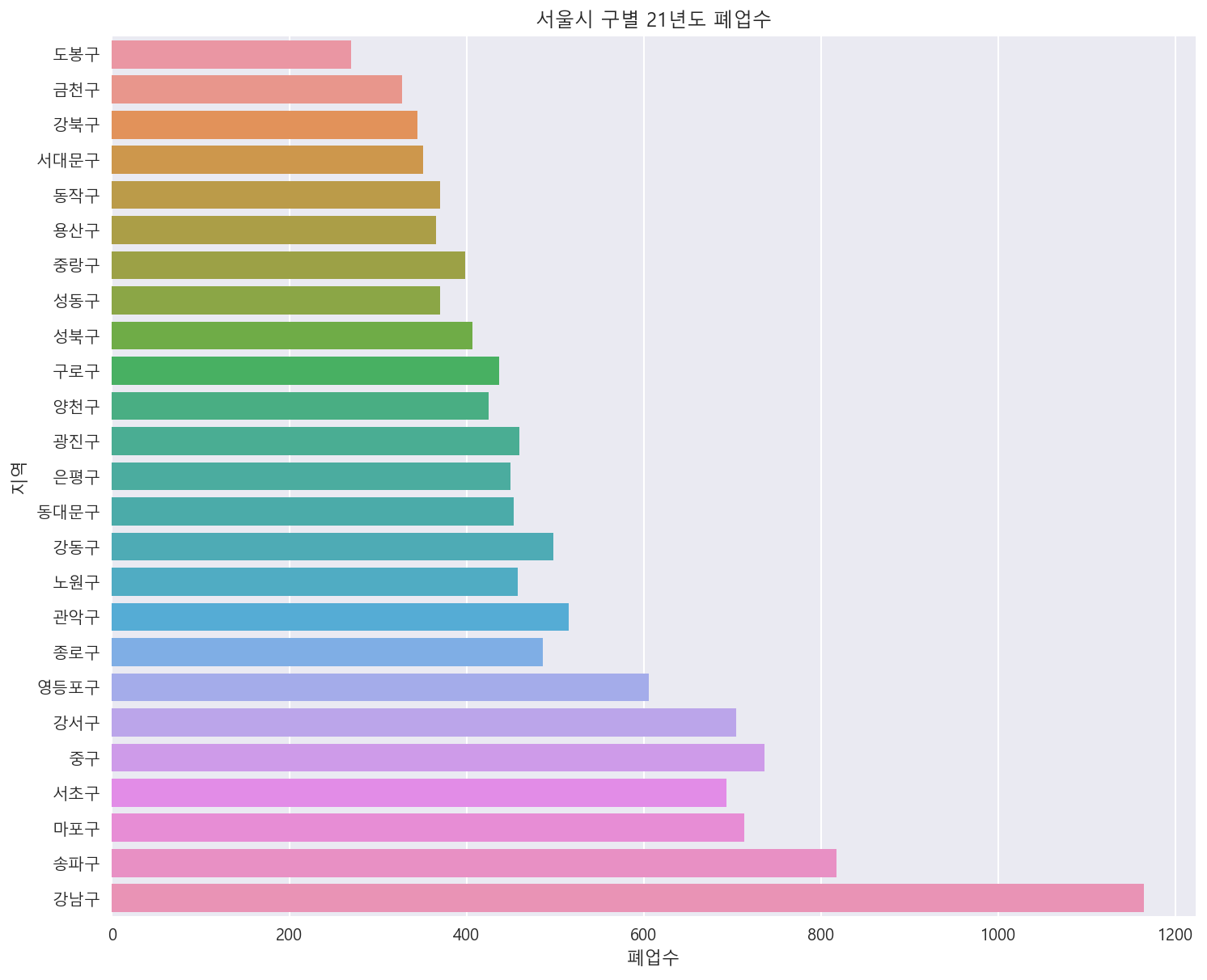
서울시 각 구별 주거인구 살펴보기
plt.figure(figsize=(12, 10))
sns.barplot(data=df_a.sort_values('주거 인구'),x='주거 인구',y='지역', ci=None)
_ = plt.title('서울시 구별 21년도 주거인구')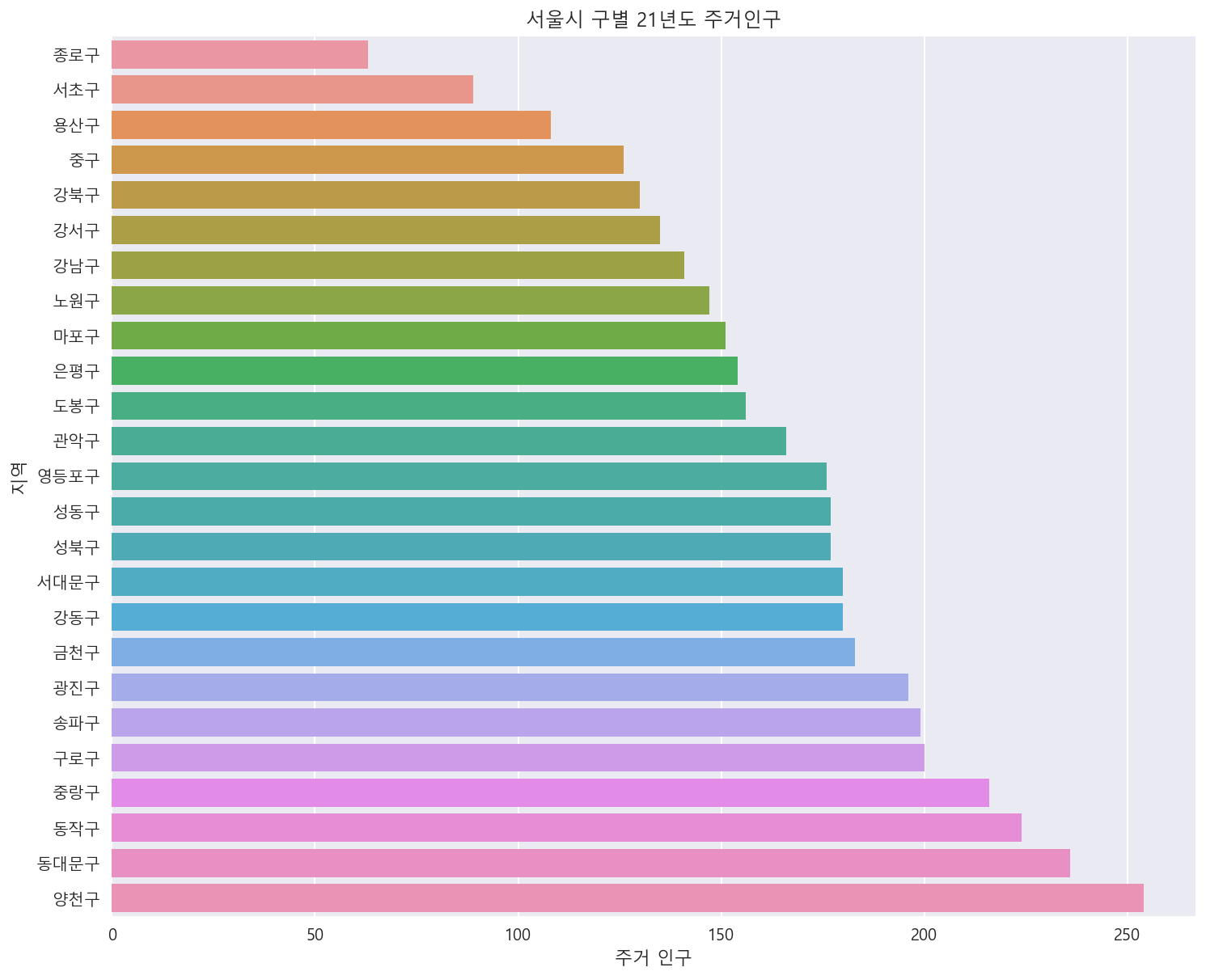
서울시 각 구별 직장인구 살펴보기
plt.figure(figsize=(12, 10))
sns.barplot(data=df_a.sort_values('직장 인구'),x='직장 인구',y='지역', ci=None)
_ = plt.title('서울시 구별 21년도 직장인구')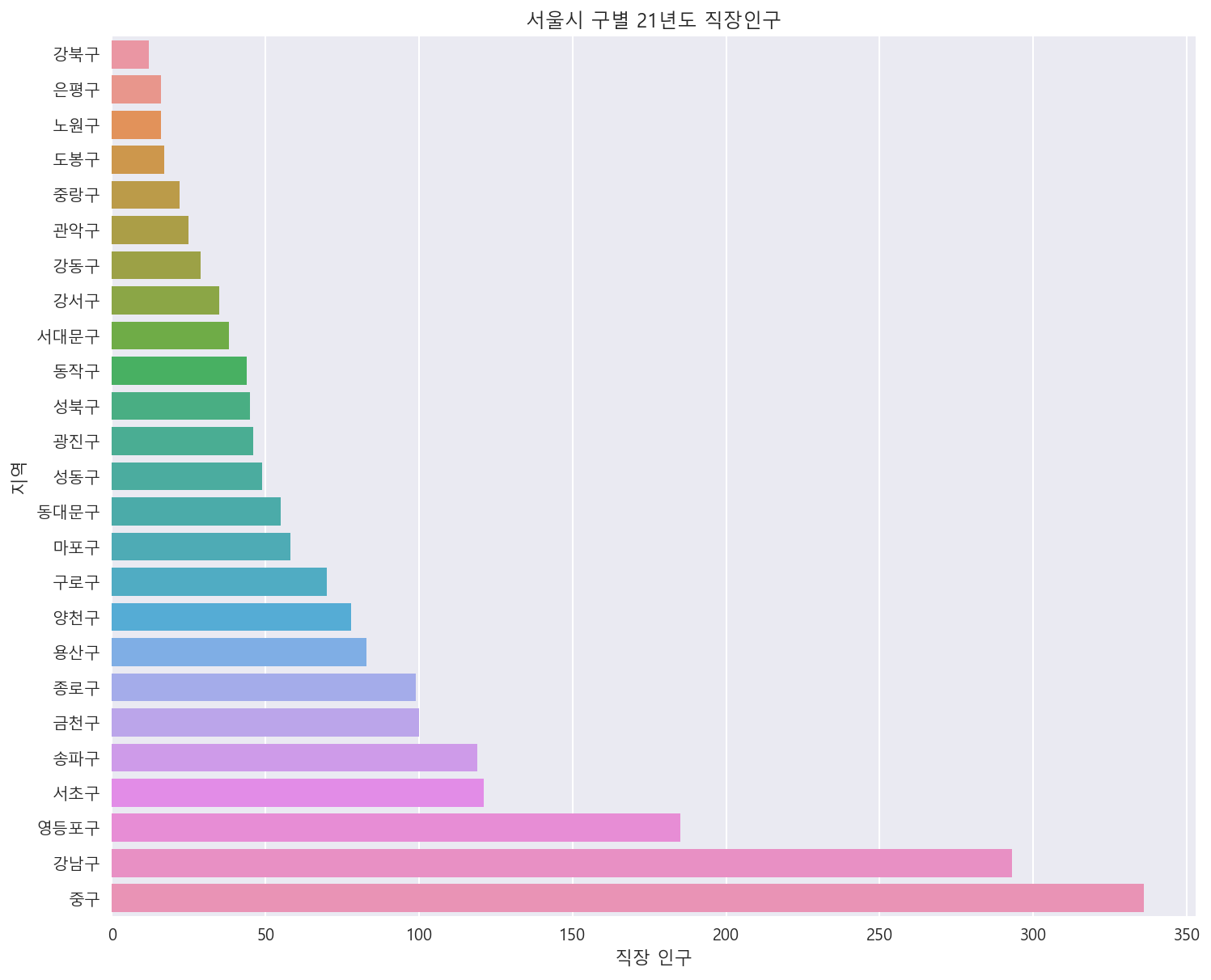
구별 전체 점포수 중 프렌차이즈 점포수와 일반 점포수 비율 비교
출처:출처
# 지역별로 그룹화하여 프랜차이즈와 일반 점포수의 평균으로 만든 데이터 프레임
df_a_nf = df_a.groupby('지역')['프랜차이즈 점포수', '일반 점포수'].mean()# 틀만들기
fig, axs = plt.subplots(ncols=2, sharey=True,
figsize=(10, 8), gridspec_kw={"wspace":0})
c_f = "green"
c_n = "darkorange"
#바 그래프 생성하기
axs[0].barh(df_a_nf.index, df_a_nf["프랜차이즈 점포수"], color=c_f)
axs[1].barh(df_a_nf.index, df_a_nf["일반 점포수"], color=c_n)
#단위 맞쳐주기
xmax = 5500
x2max=65000
axs[0].set_xlim(xmax, 0)
axs[1].set_xlim(0, x2max)
#제목 설정하기
for ax,title in zip(axs,['프랜차이즈 점포수','일반 점포수']):
ax.set_title(title, color="gray", fontweight="bold", pad=16)
#꾸미기
for ax in axs:
for i, p in enumerate(ax.patches):
w = p.get_width()
if ax == axs[0]:
ha = "right"
c = c_f
else:
ha = "left"
c = c_n
ax.text(w, i, f" {format(w, ',')} ",
c=c, fontsize=13, va="center", ha=ha,
fontweight="bold", alpha=0.5)
fig.suptitle("구별 프랜차이즈, 일반 점포수 비교", fontweight="bold")
fig.tight_layout()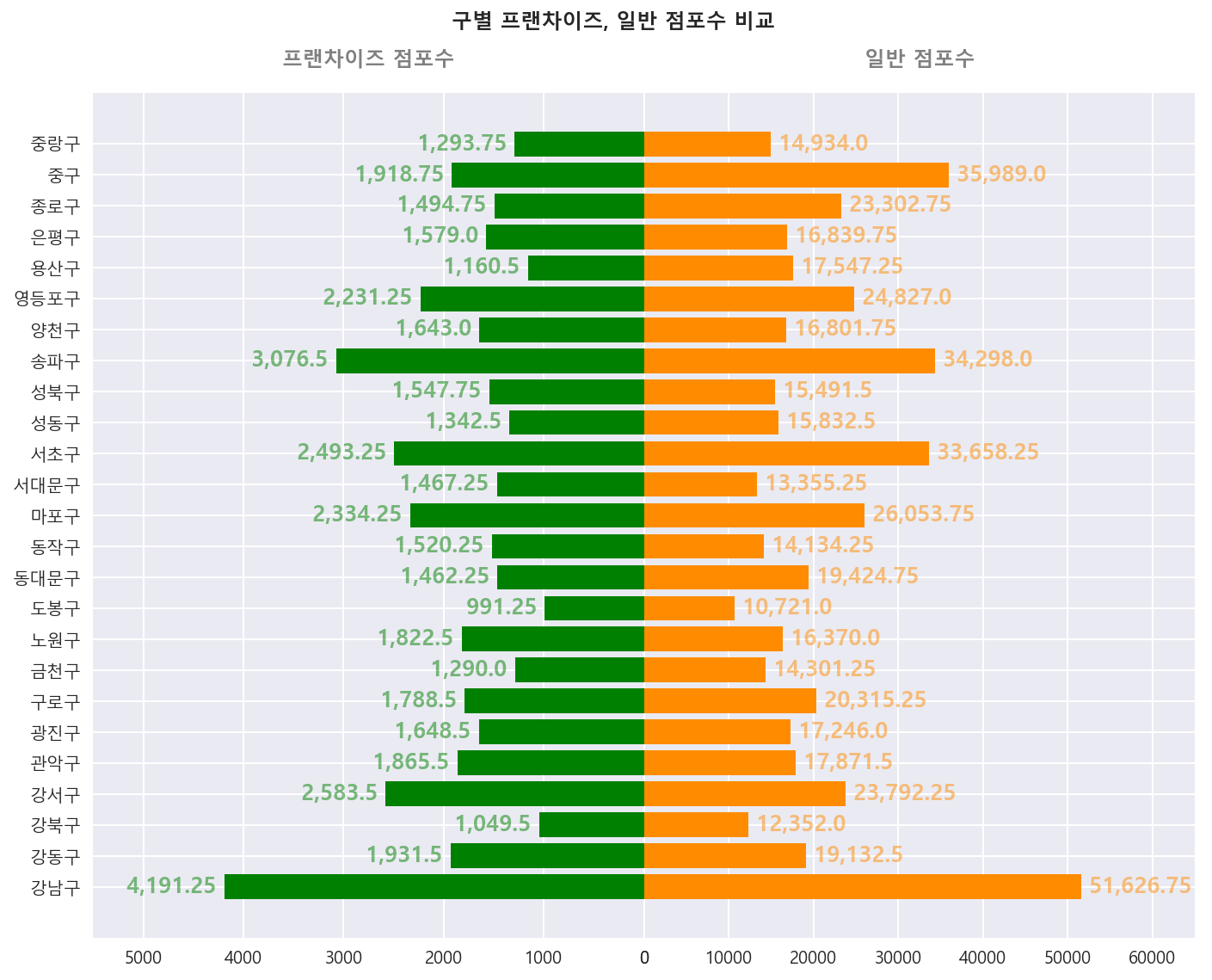
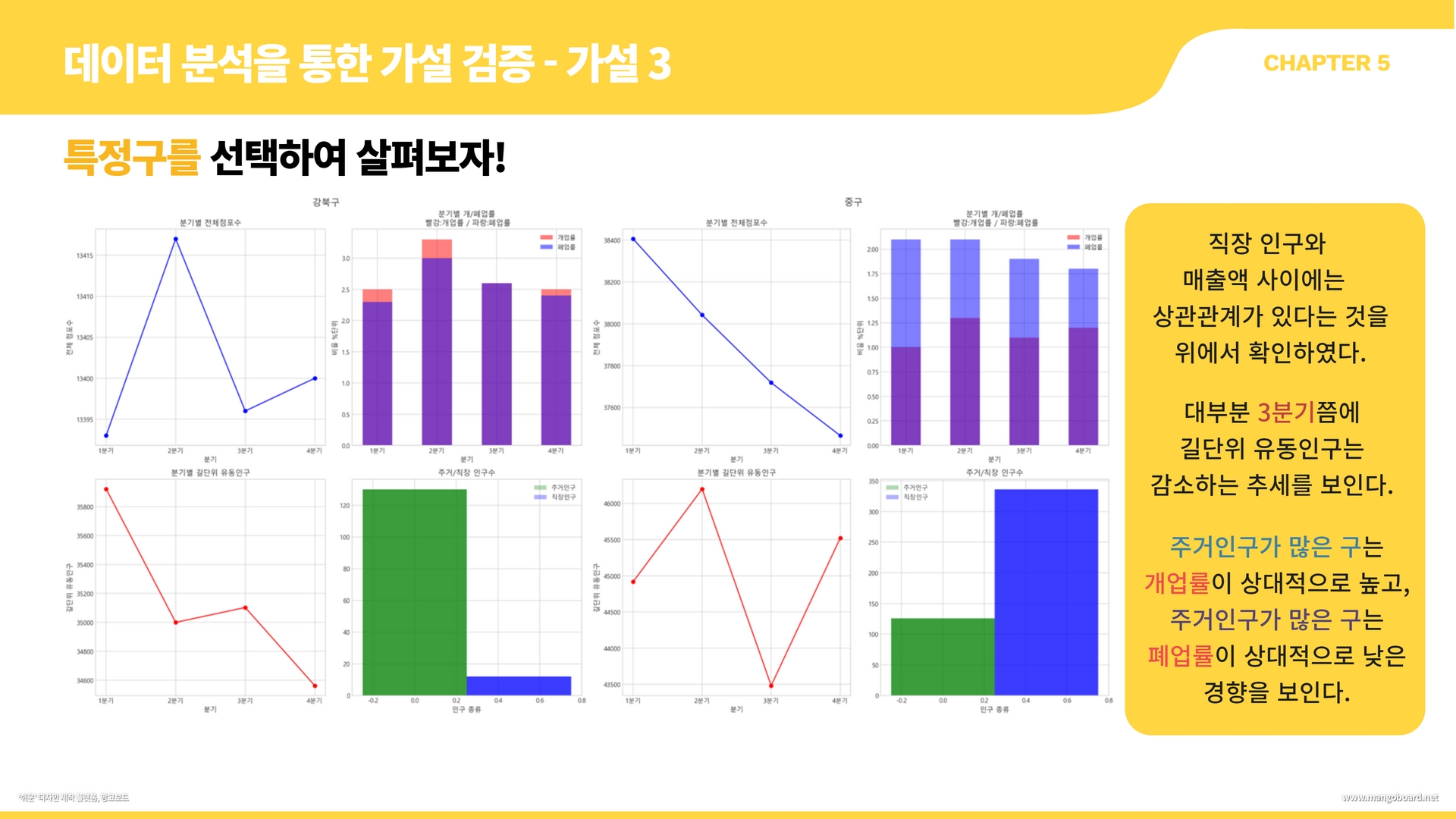
특정 구의 분기별 전체 점포수, 개업률, 폐업률, 길단위 유동인구, 주거/직장 인구수 시각화
종로구만 우선 살펴보기
f, axes = plt.subplots(2, 2)
f.set_size_inches((12, 12))
plt.subplots_adjust(wspace = 0.15, hspace = 0.15)
#figure 전체 제목
f.suptitle('종로구', fontsize=15)
#분기별 전체 점포수 변화 선 그래프
df_x=df[df['지역']=='종로구']
axes[0, 0].plot(df_x['분기'],df_x['전체 점포수'], color='blue', marker='o')
axes[0, 0].set_xlabel('분기', fontsize = 11)
axes[0, 0].set_ylabel('전체 점포수', fontsize = 11)
axes[0, 0].set_title('분기별 전체점포수', fontsize = 12)
#분기별 개폐업률 막대 그래프 비교
l1=axes[0,1].bar(df_x['분기'],df_x['개업률'],width=0.5,alpha=0.5, color='red')
l2=axes[0,1].bar(df_x['분기'],df_x['폐업률'],width=0.5,alpha=0.5, color='blue')
axes[0,1].legend([l1,l2],['개업률','폐업률'])
axes[0, 1].set_xlabel('분기', fontsize = 11)
axes[0, 1].set_ylabel('비율 %단위', fontsize = 11)
axes[0, 1].set_title('분기별 개/폐업률\n 빨강:개업률 / 파랑:폐업률', fontsize = 12)
#길단위 인구수
axes[1, 0].plot(df_x['분기'],df_x['길단위 유동인구'], color='red', marker='o')
axes[1, 0].set_xlabel('분기', fontsize = 11)
axes[1, 0].set_ylabel('길단위 유동인구', fontsize = 11)
axes[1, 0].set_title('분기별 길단위 유동인구', fontsize = 12)
#주거, 직장 인구
bar_width = 0.5
index = np.arange(1)
label=['']
l3=axes[1,1].bar(index,df_x['주거 인구'],width=0.5,alpha=0.3, color='green')
l4=axes[1,1].bar(index+bar_width,df_x['직장 인구'],width=0.5,alpha=0.3, color='blue')
axes[1,1].legend([l3,l4],['주거인구','직장인구'])
axes[1, 1].set_xlabel('인구 종류', fontsize = 11)
axes[1, 1].set_ylabel('', fontsize = 11)
axes[1, 1].set_title('주거/직장 인구수', fontsize = 12)
plt.tight_layout()
plt.show()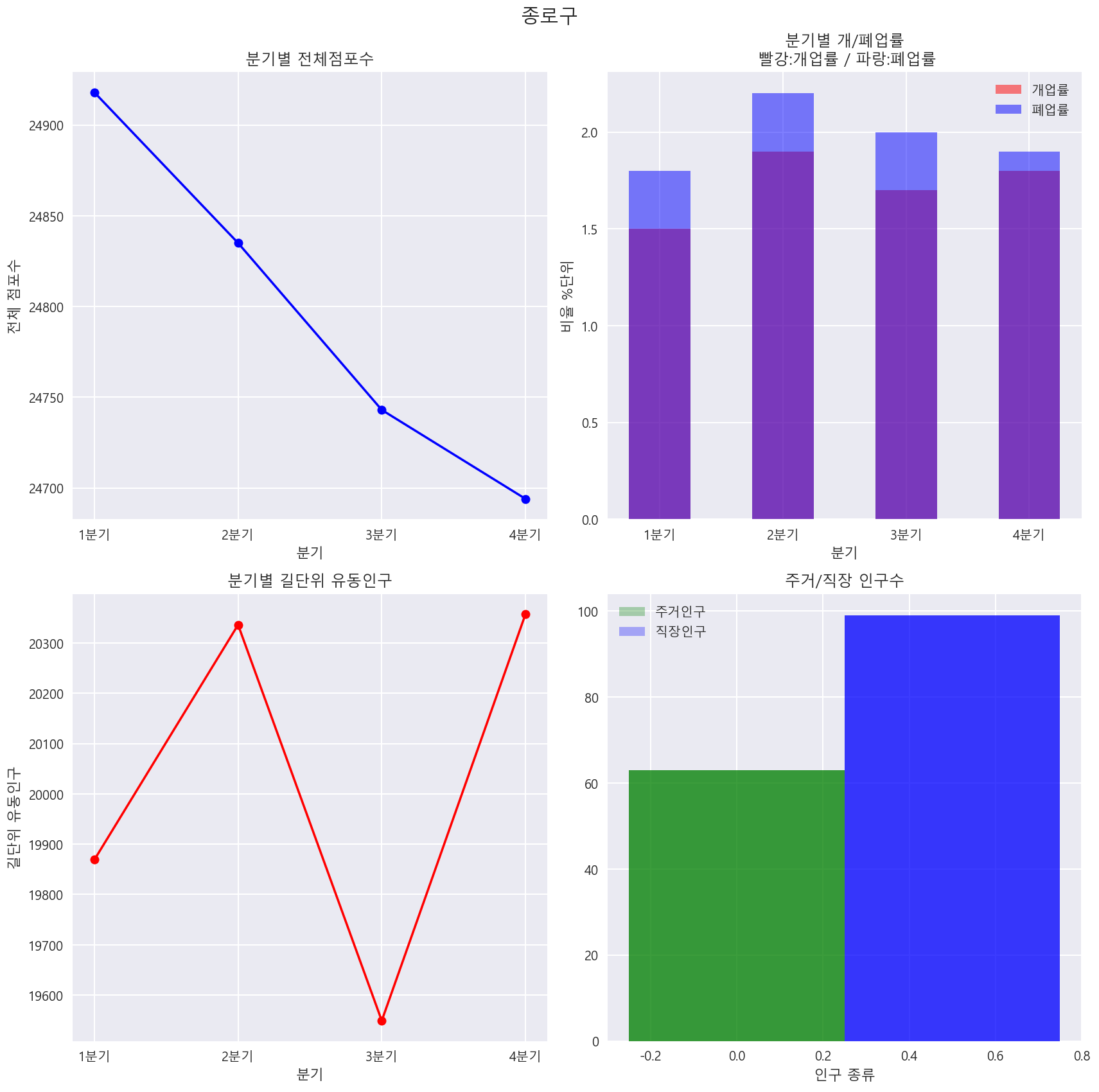
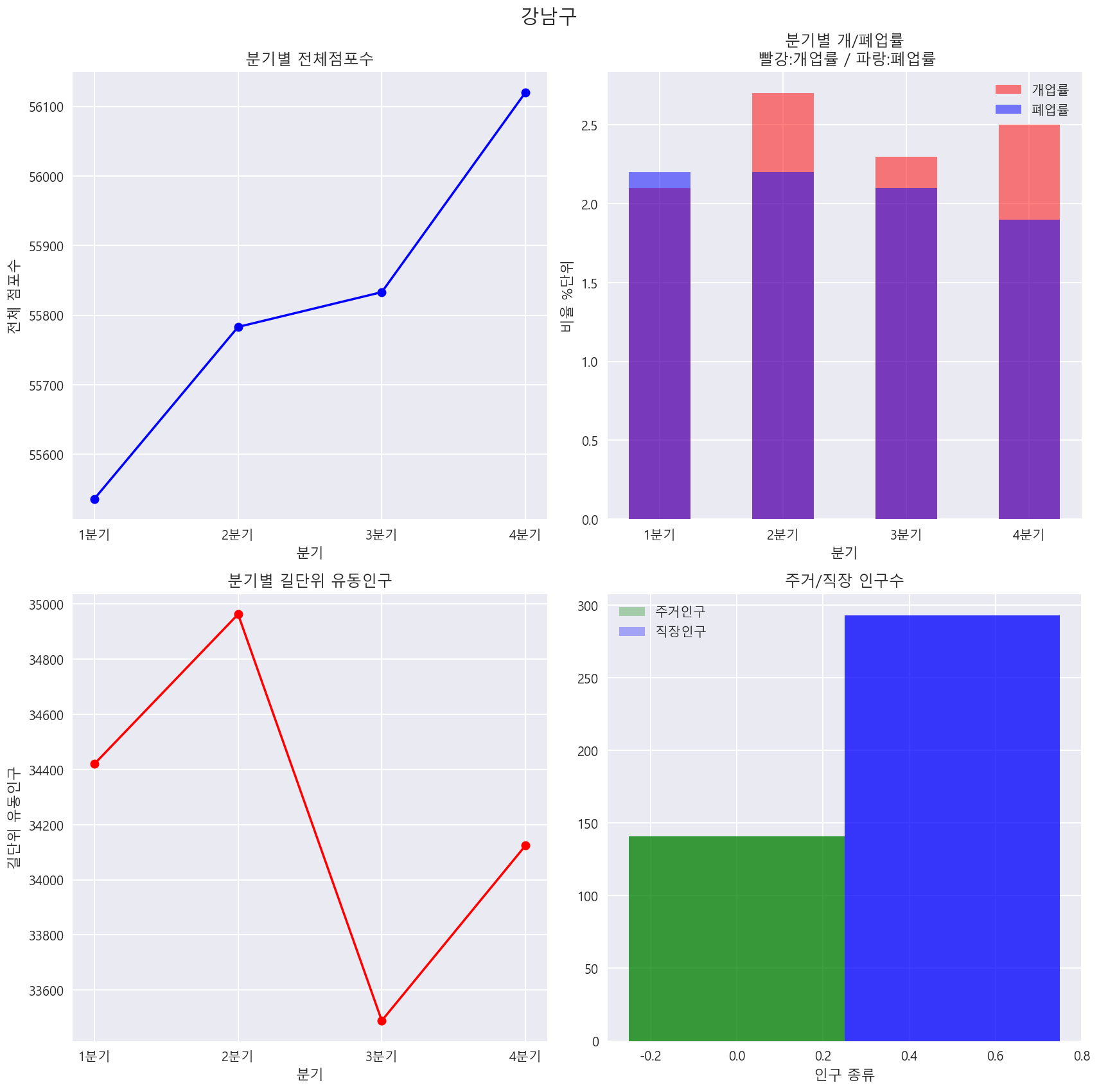
위의 코드를 이용하여 함수를 만들어 검색이 가능하도록 작성하기
def total_graph(gu):
f, axes = plt.subplots(2, 2)
f.set_size_inches((12, 12))
plt.subplots_adjust(wspace = 0.15, hspace = 0.15)
#figure 전체 제목
f.suptitle( gu , fontsize=15)
#분기별 전체 점포수 변화 선 그래프
df_x=df[df['지역']==gu]
axes[0, 0].plot(df_x['분기'],df_x['전체 점포수'], color='blue', marker='o')
axes[0, 0].set_xlabel('분기', fontsize = 11)
axes[0, 0].set_ylabel('전체 점포수', fontsize = 11)
axes[0, 0].set_title('분기별 전체점포수', fontsize = 12)
#분기별 개폐업률 막대 그래프 비교
l1=axes[0,1].bar(df_x['분기'],df_x['개업률'],width=0.5,alpha=0.5, color='red')
l2=axes[0,1].bar(df_x['분기'],df_x['폐업률'],width=0.5,alpha=0.5, color='blue')
axes[0,1].legend([l1,l2],['개업률','폐업률'])
axes[0, 1].set_xlabel('분기', fontsize = 11)
axes[0, 1].set_ylabel('비율 %단위', fontsize = 11)
axes[0, 1].set_title('분기별 개/폐업률\n 빨강:개업률 / 파랑:폐업률', fontsize = 12)
#길단위 인구수
axes[1, 0].plot(df_x['분기'],df_x['길단위 유동인구'], color='red', marker='o')
axes[1, 0].set_xlabel('분기', fontsize = 11)
axes[1, 0].set_ylabel('길단위 유동인구', fontsize = 11)
axes[1, 0].set_title('분기별 길단위 유동인구', fontsize = 12)
#주거, 직장 인구
bar_width = 0.5
index = np.arange(1)
label=['']
l3=axes[1,1].bar(index,df_x['주거 인구'],width=0.5,alpha=0.3, color='green')
l4=axes[1,1].bar(index+bar_width,df_x['직장 인구'],width=0.5,alpha=0.3, color='blue')
axes[1,1].legend([l3,l4],['주거인구','직장인구'])
axes[1, 1].set_xlabel('인구 종류', fontsize = 11)
axes[1, 1].set_ylabel('', fontsize = 11)
axes[1, 1].set_title('주거/직장 인구수', fontsize = 12)
plt.tight_layout()
return plt.show()gu=input("원하시는 구를 입력해주세요: ")
total_graph(gu)원하시는 구를 입력해주세요: 강남구
df = pd.read_csv("data/서울시_우리마을가게_상권분석서비스(신_상권_추정매출)_2021년.csv", encoding="cp949")
df1 = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(상권영역).csv", encoding="cp949", usecols=['상권_코드_명',"시군구_코드",'엑스좌표_값','와이좌표_값'])
df = df.merge(df1, on="상권_코드_명", how="left")
k = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(상권영역).csv", encoding="cp949", usecols=["엑스좌표_값","와이좌표_값"])
k["엑스좌표_값"] = pd.to_numeric(k["엑스좌표_값"], errors="coerce")
k["와이좌표_값"] = pd.to_numeric(k["와이좌표_값"], errors="coerce")
k = k.dropna()
k.index=range(len(k))
k.tail()
from pyproj import Proj, transform
import folium
import pyproj
def project_array(coord, p1_type, p2_type):
"""
좌표계 변환 함수
- coord: x, y 좌표 정보가 담긴 NumPy Array
- p1_type: 입력 좌표계 정보 ex) epsg:5181
- p2_type: 출력 좌표계 정보 ex) epsg:4326
"""
p1 = pyproj.Proj(init=p1_type)
p2 = pyproj.Proj(init=p2_type)
fx, fy = pyproj.transform(p1, p2, coord[:, 0], coord[:, 1])
return np.dstack([fx, fy])[0]
coord = np.array(k)
coord
p1_type = "epsg:5181"
p2_type = "epsg:4326"
# project_array() 함수 실행
result = project_array(coord, p1_type, p2_type)
result
k["위도"] = result[:,1]
k["경도"] = result[:,0]
df = df.merge(k, on="엑스좌표_값", how="left")df2 = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(자치구별 상권변화지표).csv", encoding="cp949", usecols=["시군구_코드","시군구_코드_명"])
df2 = df2.drop_duplicates()
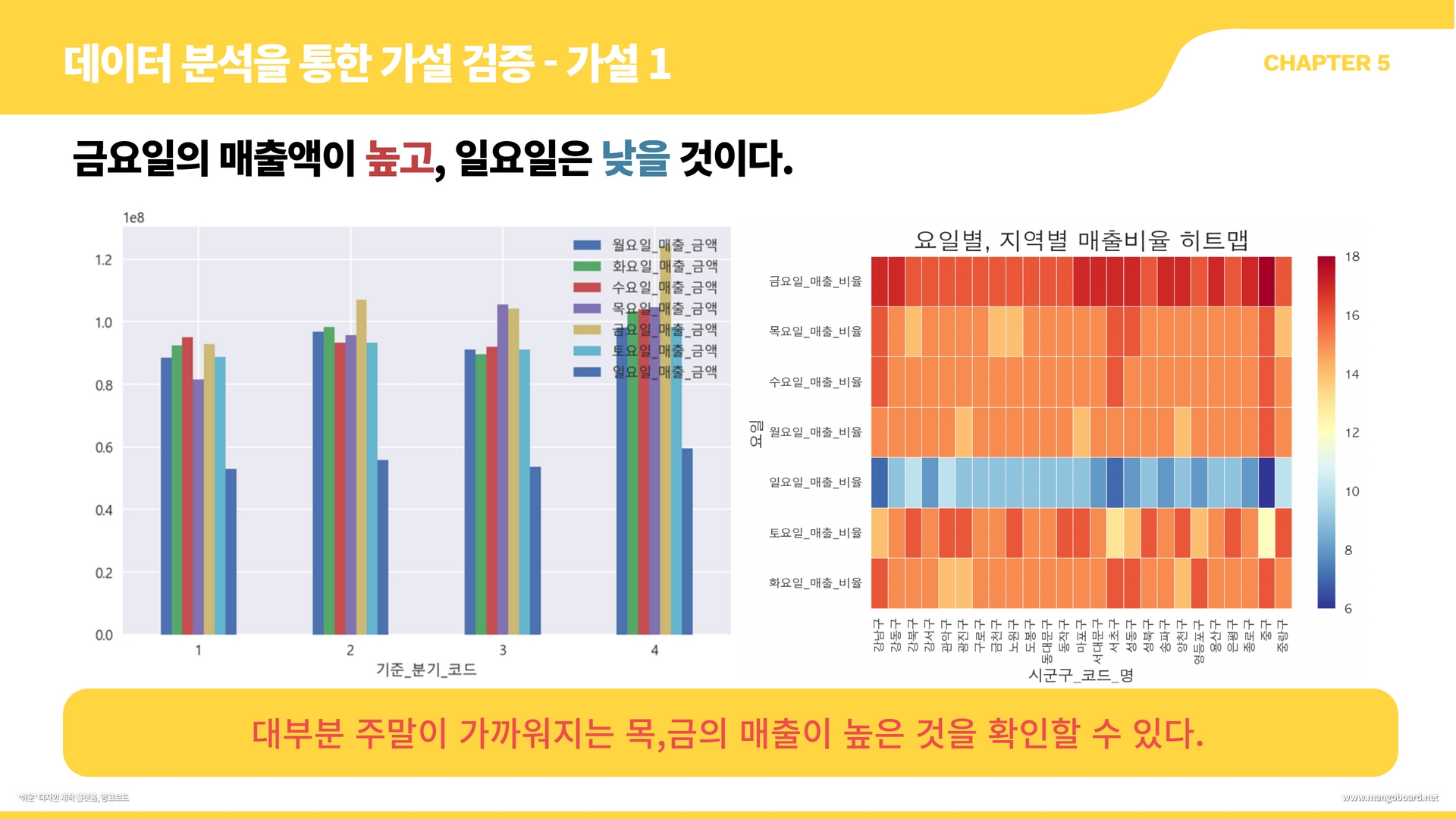
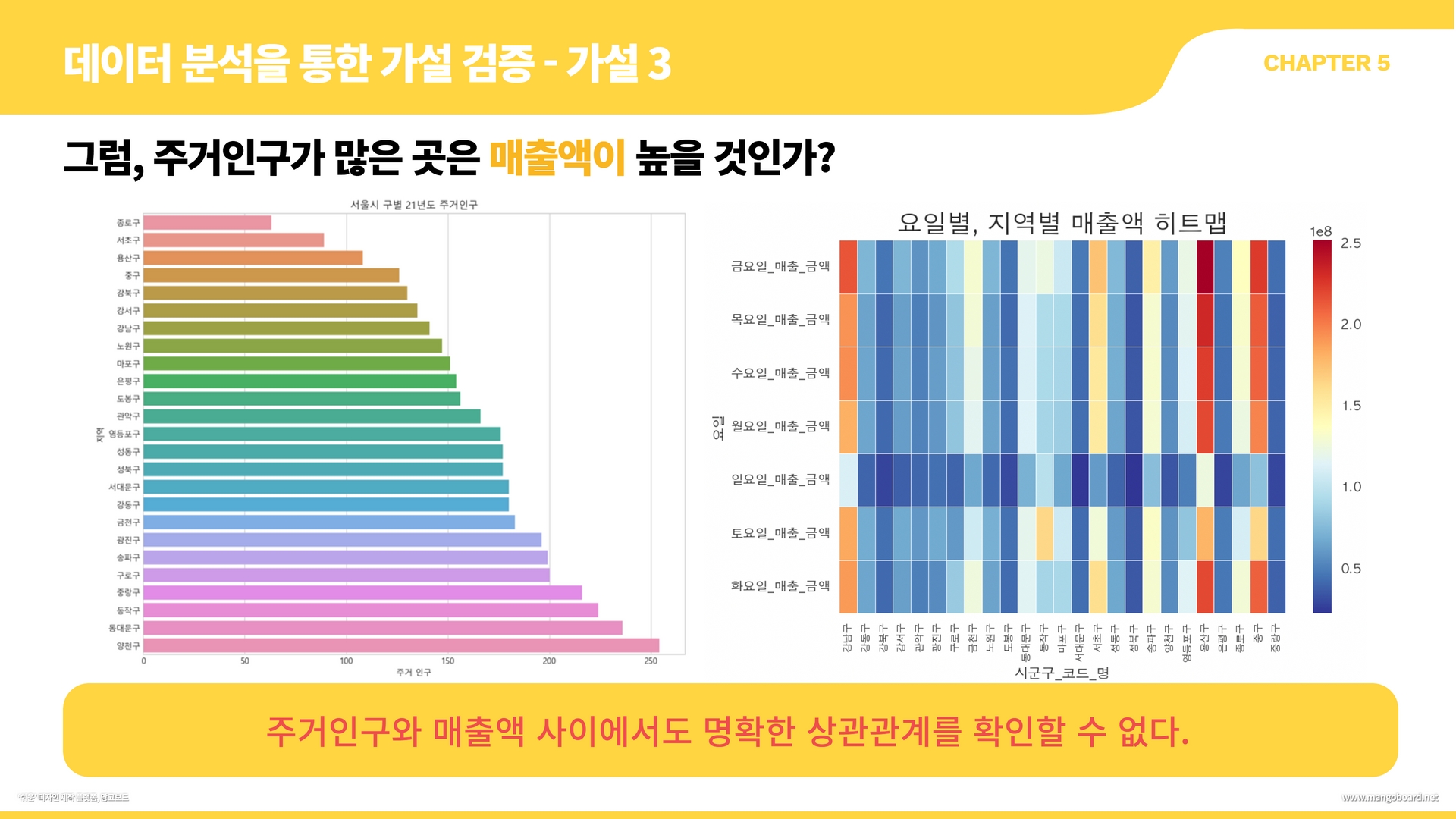
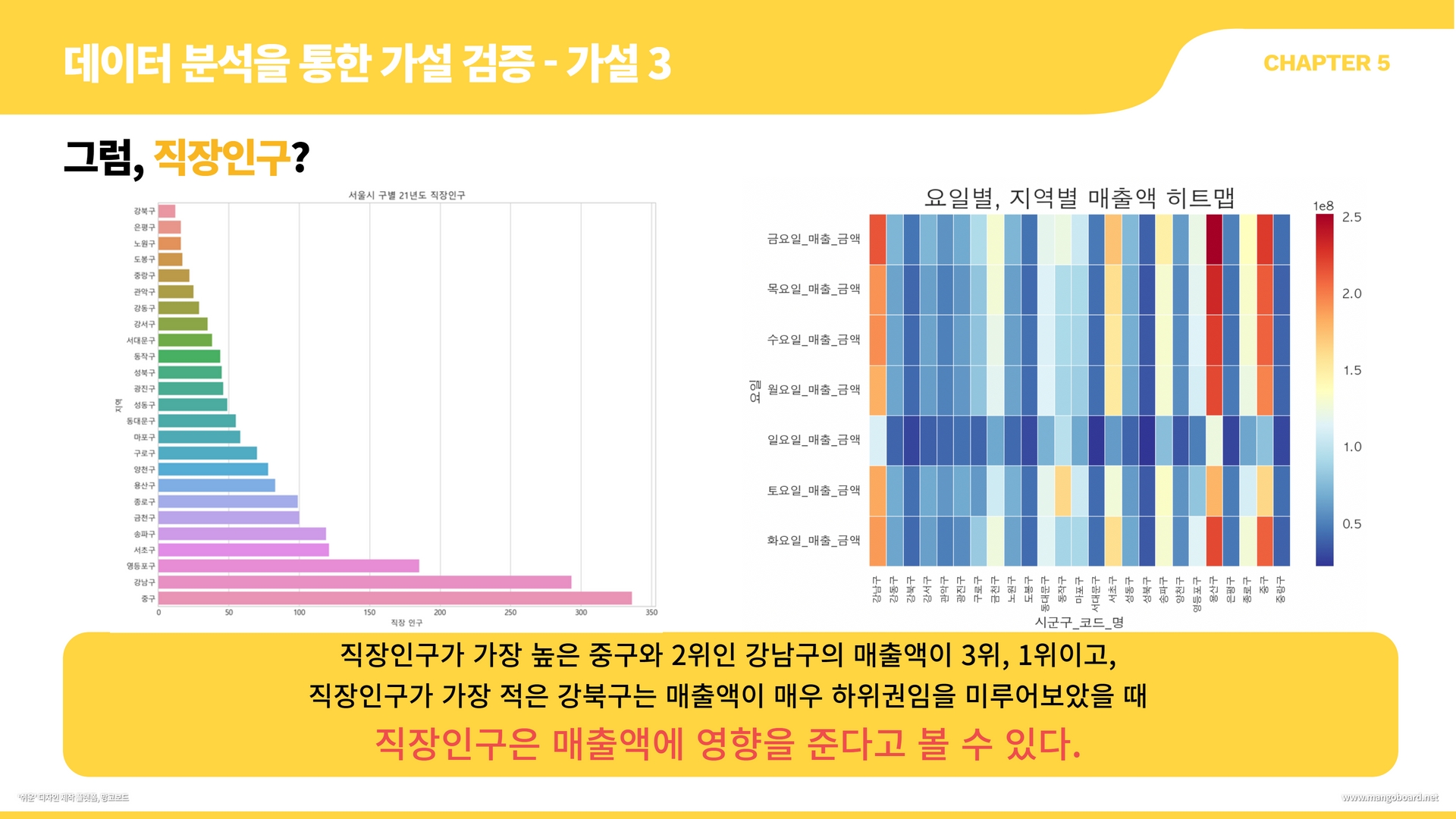
df = df.merge(df2, on="시군구_코드", how="left") #시구군 코드와 시구군명 컬럼을 합침#지역, 요일별 매출액 추이
df_gu_day = df[["시군구_코드_명","월요일_매출_금액","화요일_매출_금액","수요일_매출_금액","목요일_매출_금액","금요일_매출_금액","토요일_매출_금액","일요일_매출_금액"]]
df_gu = df_gu_day.melt(id_vars ="시군구_코드_명", var_name="요일", value_name="매출액")
df_gu
plt.figure(figsize=(16, 12))
sns.lineplot(data=df_gu, x="요일", y="매출액", hue='시군구_코드_명', markers=True, ci=None, style="시군구_코드_명")
plt.title('서울시 지역구, 요일별 매출액 추이')
plt.legend(bbox_to_anchor=(1,1))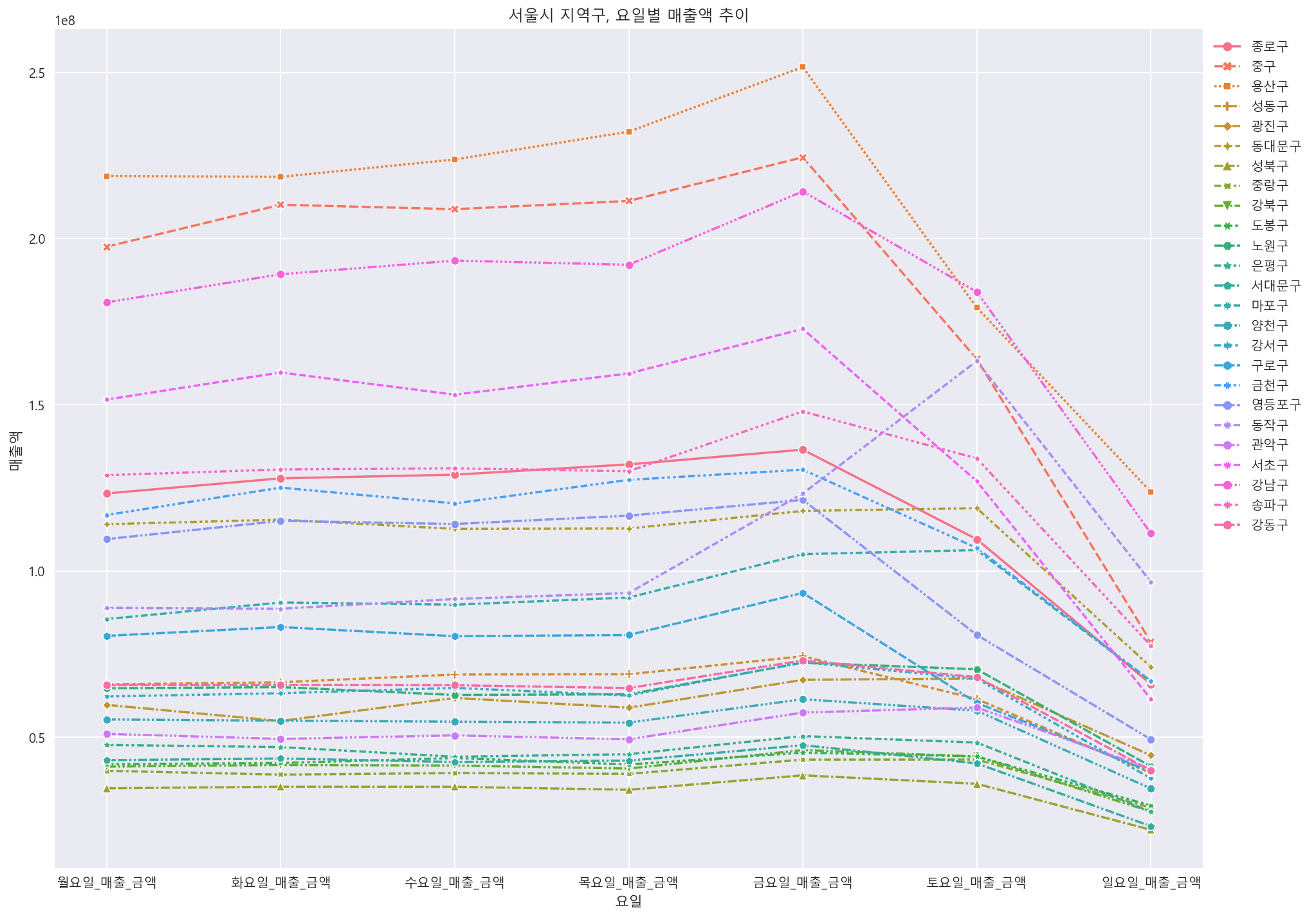
#지역,요일별 매출비율 추이
df_gu_ratio = df[["시군구_코드_명","월요일_매출_비율","화요일_매출_비율","수요일_매출_비율","목요일_매출_비율","금요일_매출_비율","토요일_매출_비율","일요일_매출_비율"]]
df_gu_ratio = df_gu_ratio.melt(id_vars ="시군구_코드_명", var_name="요일", value_name="매출비율")
df_gu_ratio
plt.figure(figsize=(16, 12))
sns.lineplot(data=df_gu_ratio, x="요일", y="매출비율", hue='시군구_코드_명', markers=True, ci=None, style="시군구_코드_명")
plt.title('서울시 지역구, 요일별 매출비율 추이')
plt.legend(bbox_to_anchor=(1,1))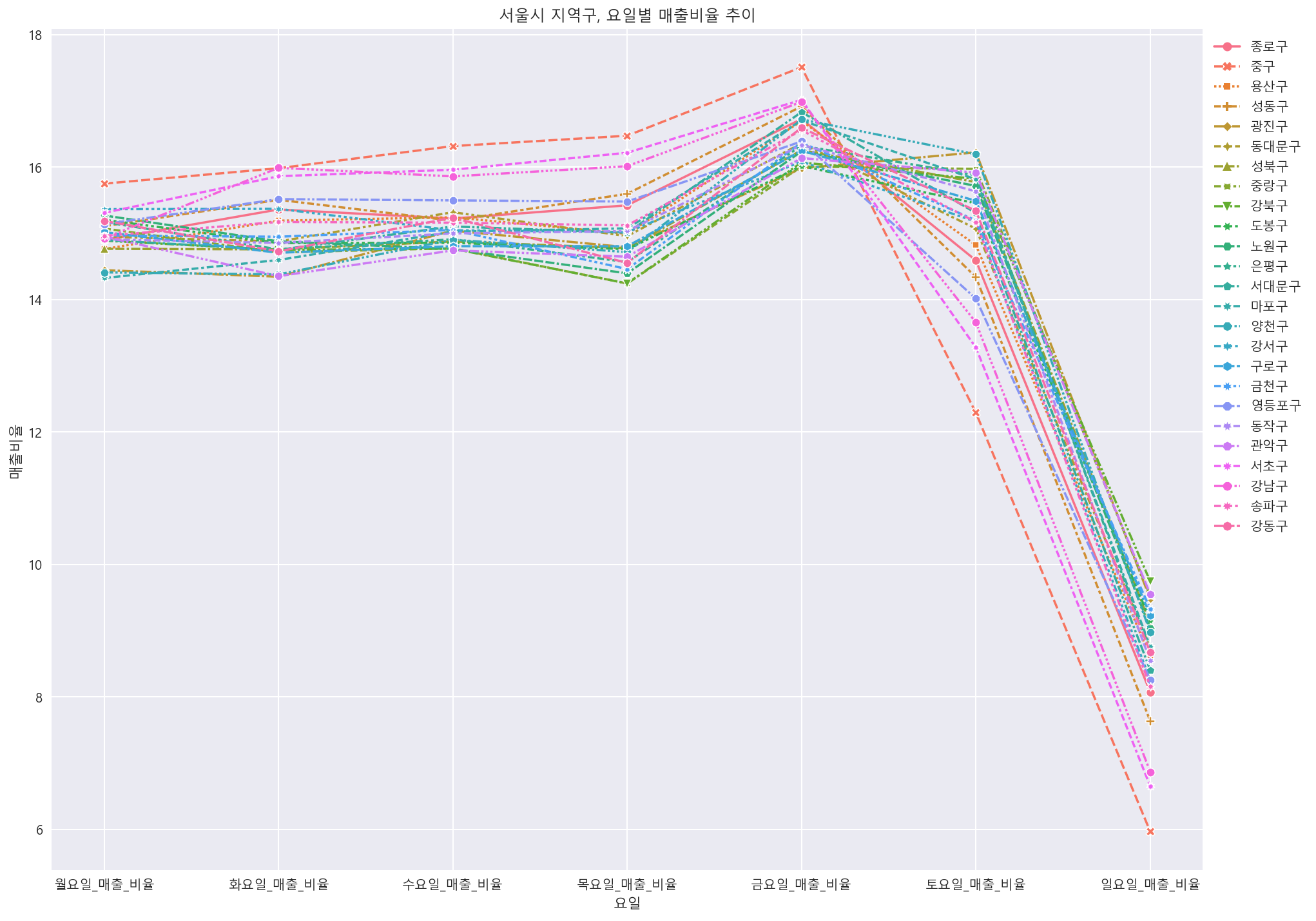
#지역, 요일별 매출 건수 추이
df_gu_count = df[["시군구_코드_명","월요일_매출_건수","화요일_매출_건수","수요일_매출_건수","목요일_매출_건수","금요일_매출_건수","토요일_매출_건수","일요일_매출_건수"]]
df_gu_count = df_gu_count.melt(id_vars ="시군구_코드_명", var_name="요일", value_name="매출건수")
df_gu_count
plt.figure(figsize=(16, 12))
sns.lineplot(data=df_gu_count, x="요일", y="매출건수", hue='시군구_코드_명', markers=True, ci=None, style="시군구_코드_명")
plt.title('서울시 지역구, 요일별 매출건수 추이')
plt.legend(bbox_to_anchor=(1,1))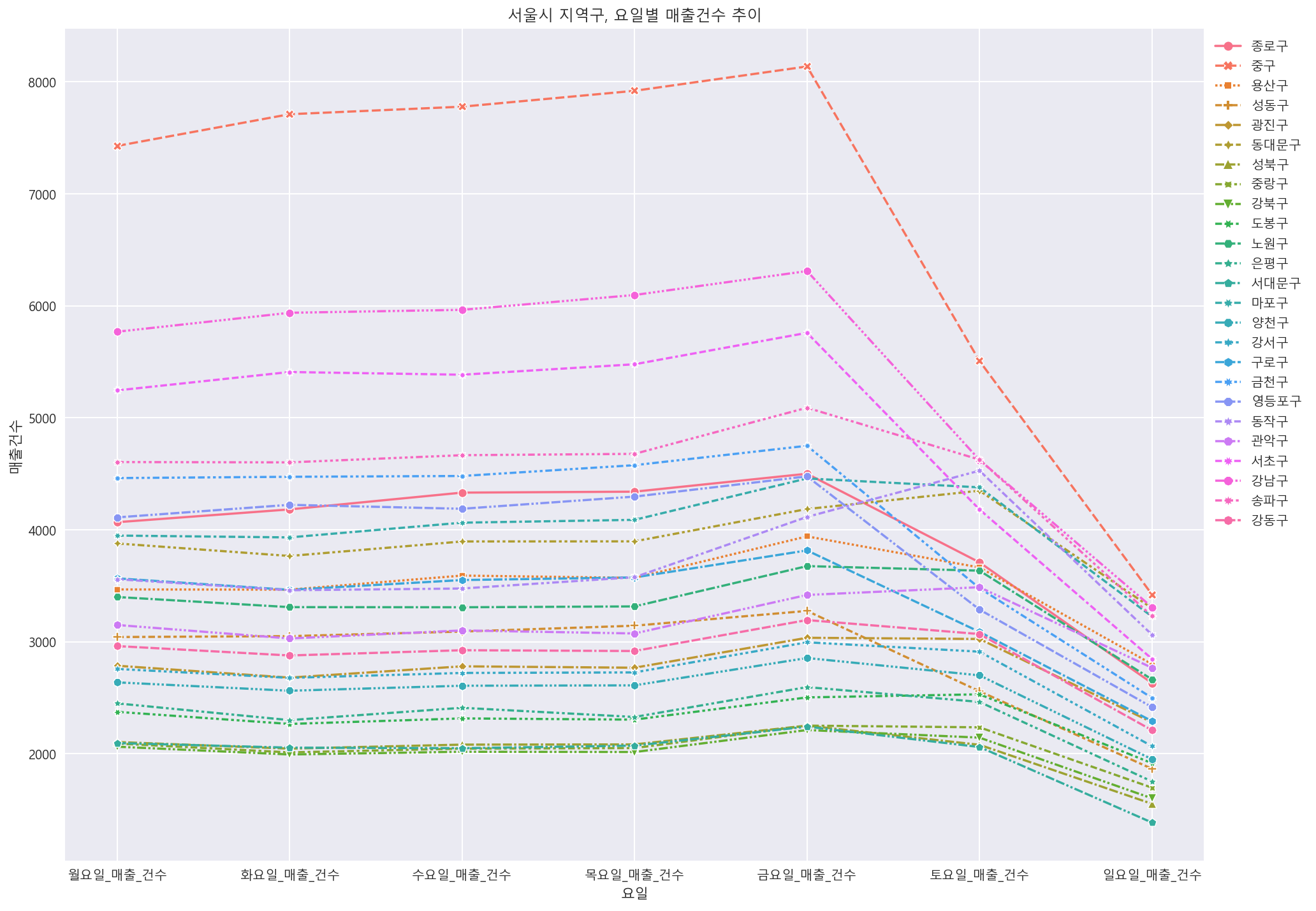
m = pd.pivot_table(df_gu_count, index = "요일", columns="시군구_코드_명", values = "매출건수").round()
plt.figure(figsize=(28,8))
sns.heatmap(m, linewidths = 0.4, # 선의 굵기
linecolor = 'white', # 선의 색깔
annot = True, # 실제 값 화면에 나타내기
cmap = 'RdYlBu_r', # Red, Yellow, Blue 색상으로 표시
# 소수점 포맷팅 형태
)
plt.xticks(fontsize=8,rotation= 0)
plt.title('요일별, 지역별 매출건수 히트맵', fontsize=20)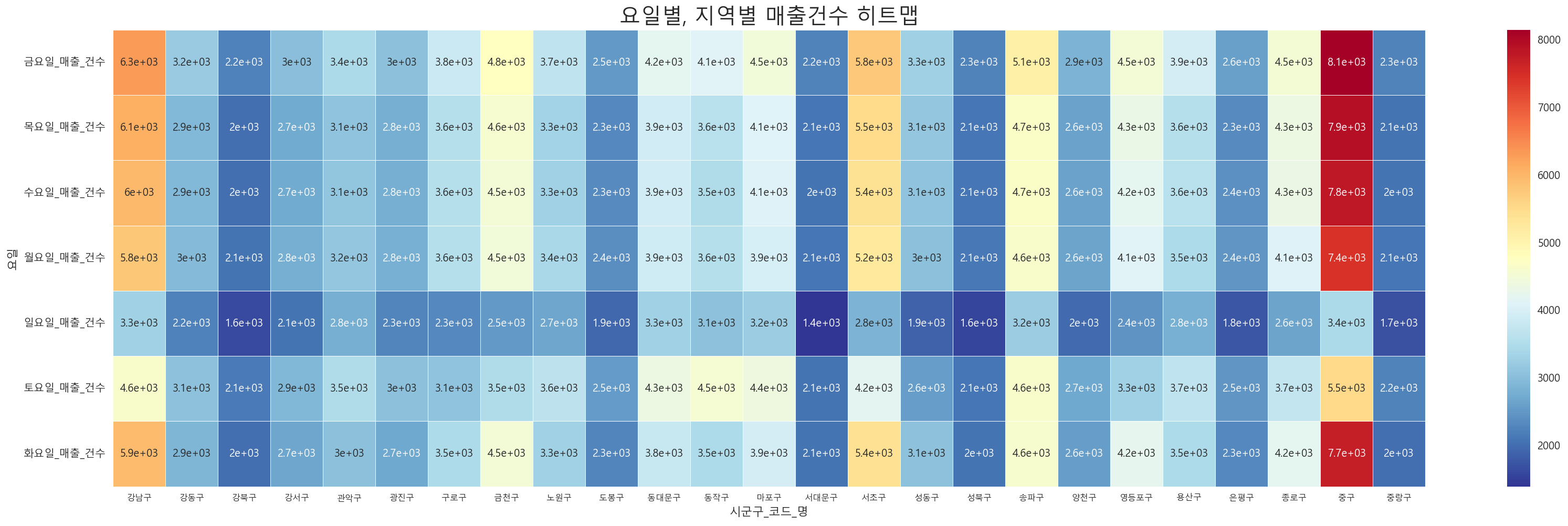
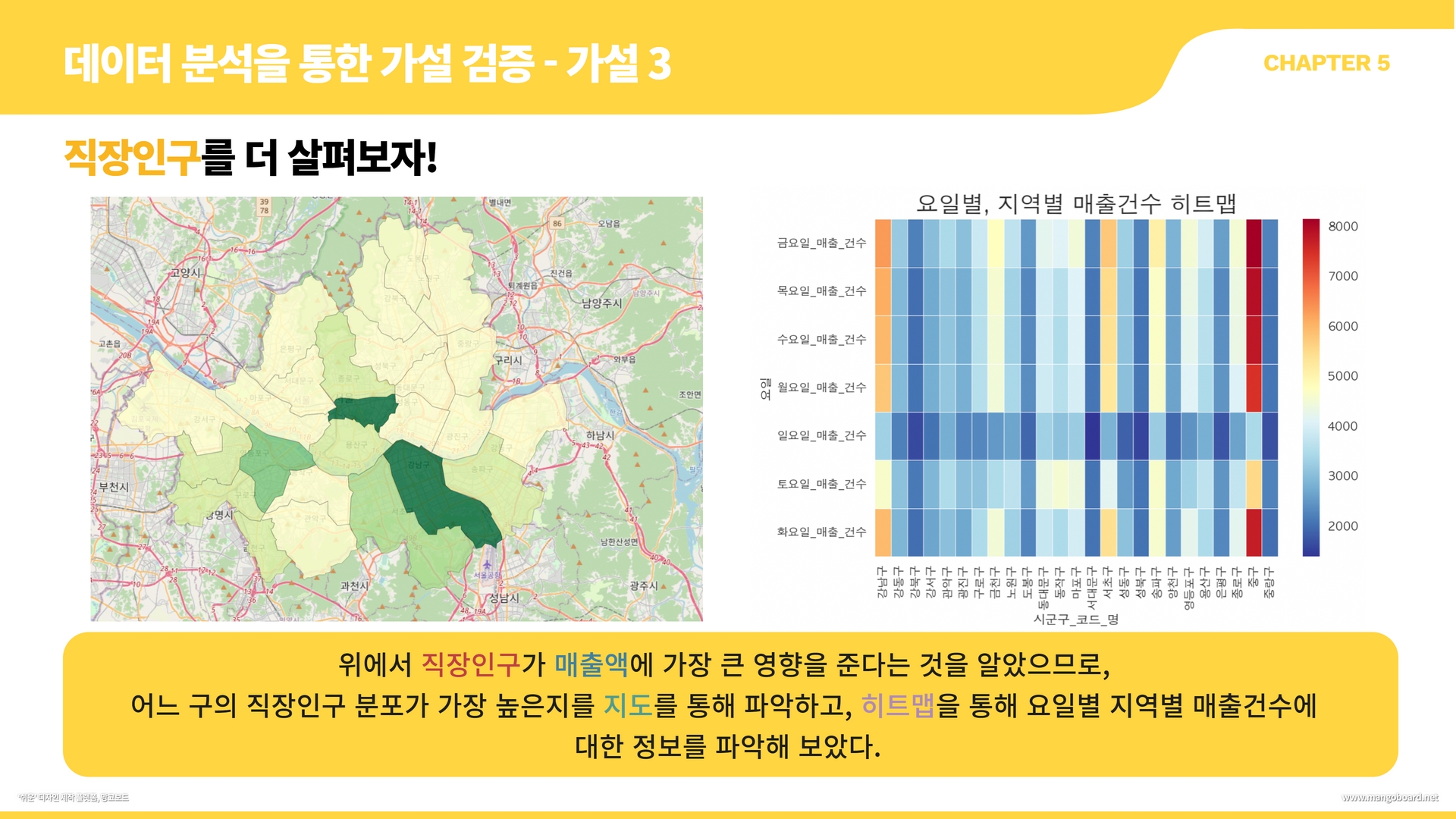
geo_path = 'data/seoul_municipalities_geo_simple.json'
print(geo_path)
geo_json = json.load(open(geo_path, encoding="utf-8"))
df_pop = pd.read_csv("data/인구_점포_개폐업_통합_2021.csv",encoding = 'UTF-8') #인구수 파일이어서 변수명을 popular의 Pop으로
df_pop
df_popular= df_pop.groupby("지역")["직장 인구"].sum().reset_index()
df_popular['지역']=df_popular['지역'].str.strip() #인구수 csv 파일에서 지역명앞에 한칸 띄어져있어서 strip해줌m = folium.Map(location=[df["위도"].mean(), df["경도"].mean()], zoom_start=12)
folium.Choropleth(
geo_data=geo_json,
name="choropleth",
data=df_popular,
columns=["지역","직장 인구"],
key_on="feature.properties.name",
fill_color = "YlGn",
fill_opacity=0.8,
line_opacity = 0.2,
legend_name="직장인구 수",
).add_to(m)
m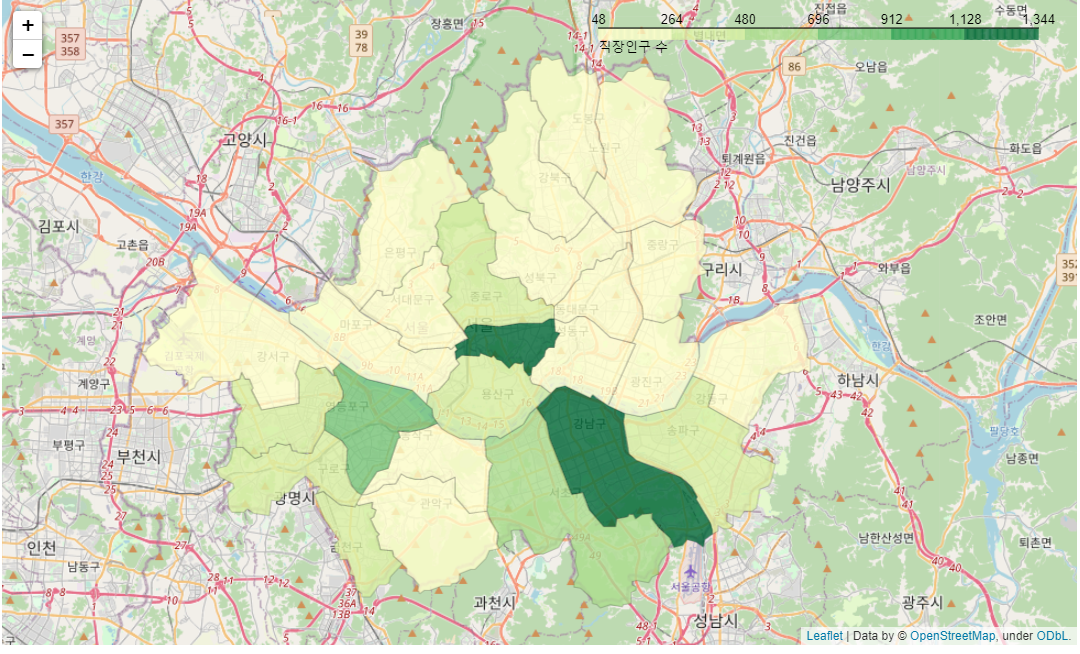
df = pd.read_csv("data/인구_점포_개폐업_통합_2021.csv")
# 서울 구별 면적 데이터
df2 = pd.read_csv("data/행정구역_구별__20220610170356.csv", encoding='cp949')
df2=df2[["자치구","2019"]]
df2.columns=["지역","면적"]# 지역에 있는 \xa0 제거
df['지역'] = df['지역'].apply(lambda x: str(x).replace(u'\xa0', u''))
# 쉼표 삭제하고 int로 형변환
def remove_comma(x):
return x.replace(',', '')
columns = ["전체 점포수", "프랜차이즈 점포수","일반 점포수","길단위 유동인구", "개업수", "폐업수"]
for column in columns:
df[column]=df[column].apply(remove_comma).astype(int)
# 분기 숫자로 바꾸기
def make_qt(x):
return x.replace("분기","")
# df["분기"] = df["분기"].apply(make_qt).astype(int)
# 분기 바꿀 필요가 없어보여서 삭제
# 면적 데이터 추가
df = pd.merge(df,df2,on="지역",how="left")
# 점포수를 인구수처럼 면적당으로 바꿔줌
df["전체 점포수"] = df["전체 점포수"] / df["면적"]df["총인구"]=df["길단위 유동인구"]+df["주거 인구"]+df["직장 인구"]
# 서울 전체 평균 확인해보기
df_seoul = df[df["지역"] == "서울시 전체"][["분기","전체 점포수","총인구"]]
df_seoul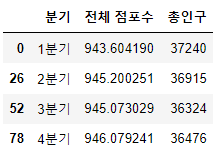
def df_corr(data, col):
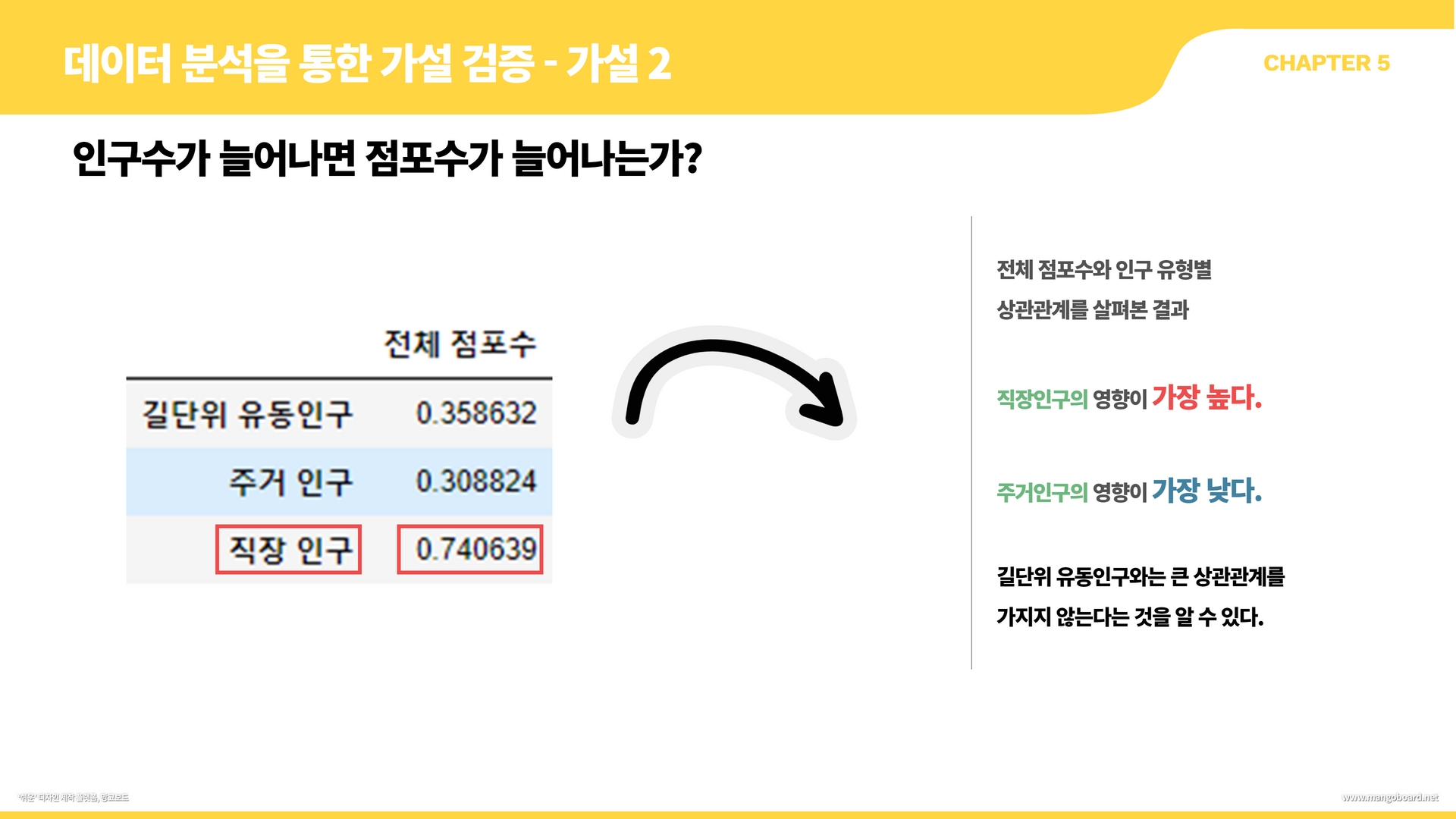
corr = data[["전체 점포수", "총인구"]].corr()
corr_df = corr[[col]].drop([col], axis=0)
return corr_df# 유동인구 비율 데이터 추가
df["유동인구 비율"] = df["길단위 유동인구"] / df["총인구"] *100
df["직장인구 비율"] = df["직장 인구"] / df["총인구"] *100
df["주거인구 비율"] = df["주거 인구"] / df["총인구"] *100# 구별 평균값 plot
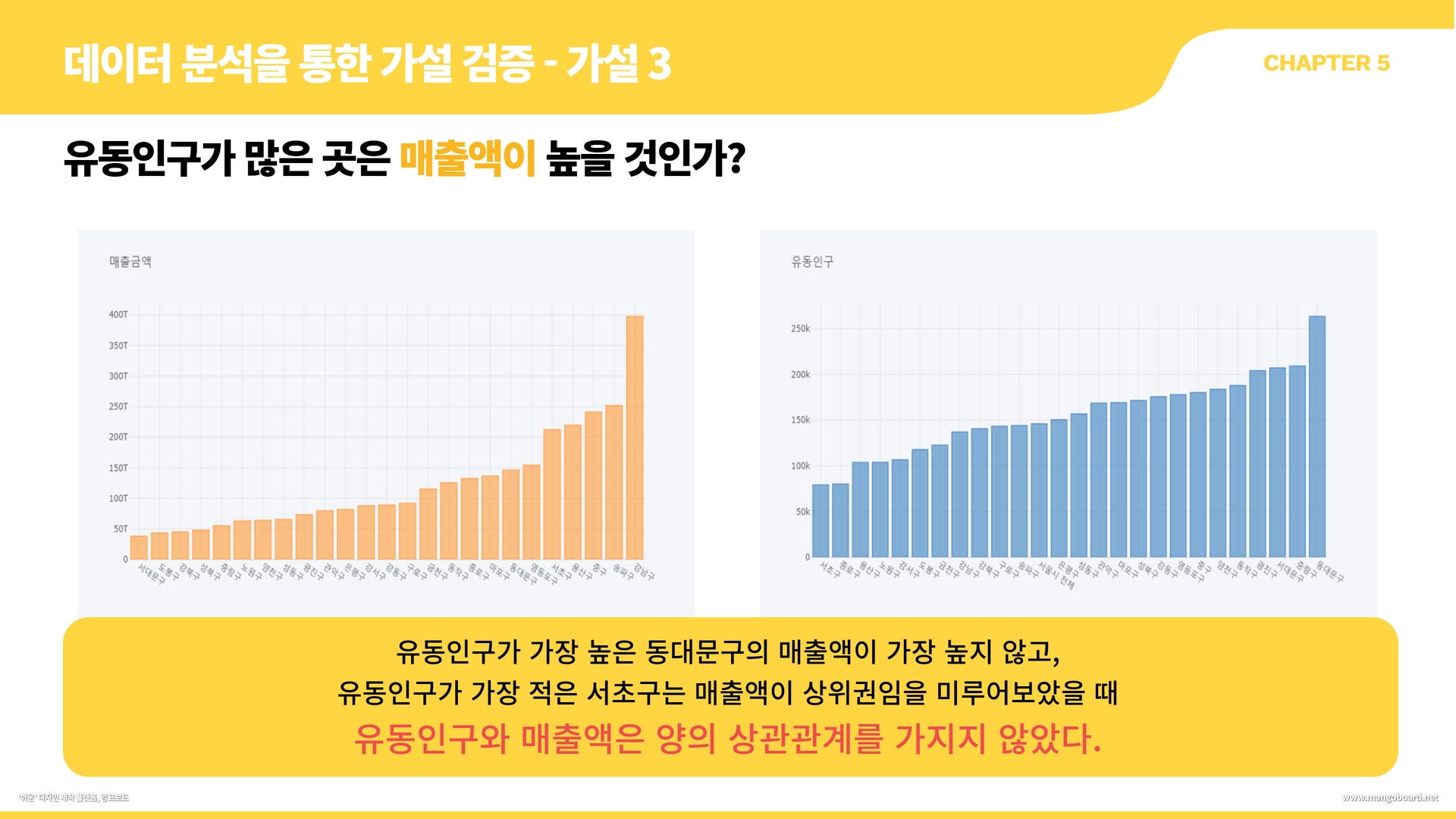
df_per=df["유동인구 비율"].groupby(df["지역"]).mean().sort_values()
colors= ['orange' if x == "서울시 전체" else 'blue' for x in df_per.index]
df_per.plot.barh(title="구별 유동인구 비율",figsize=(12,10), color = colors)
plt.xlabel('%')
plt.xlim(98,100)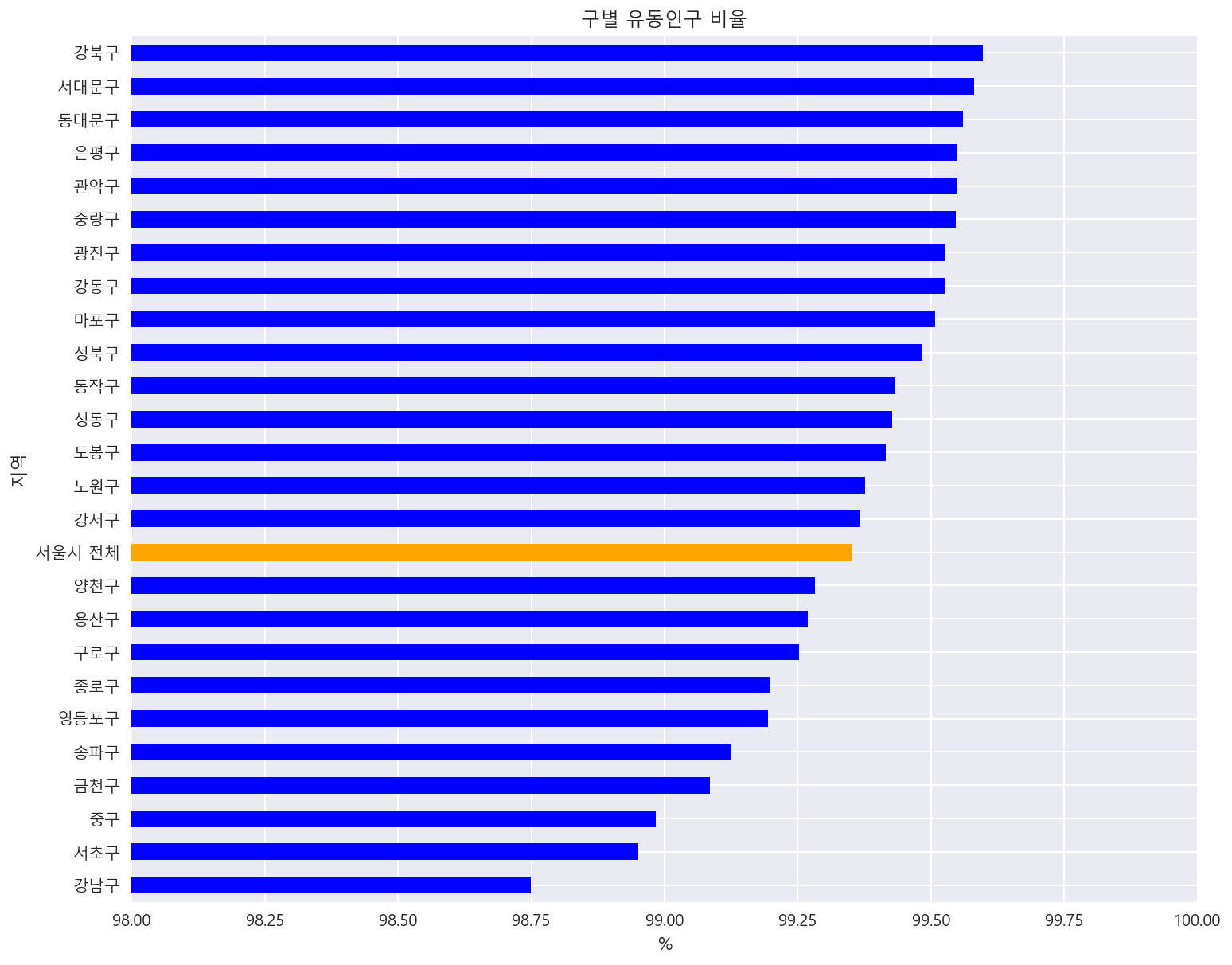
# 지역별 인구별 비율
df[["지역","유동인구 비율", "직장인구 비율","주거인구 비율"]].groupby(df["지역"]).mean().plot.bar(figsize = (12,10),
stacked=True,
rot=30)
plt.ylim(98,100)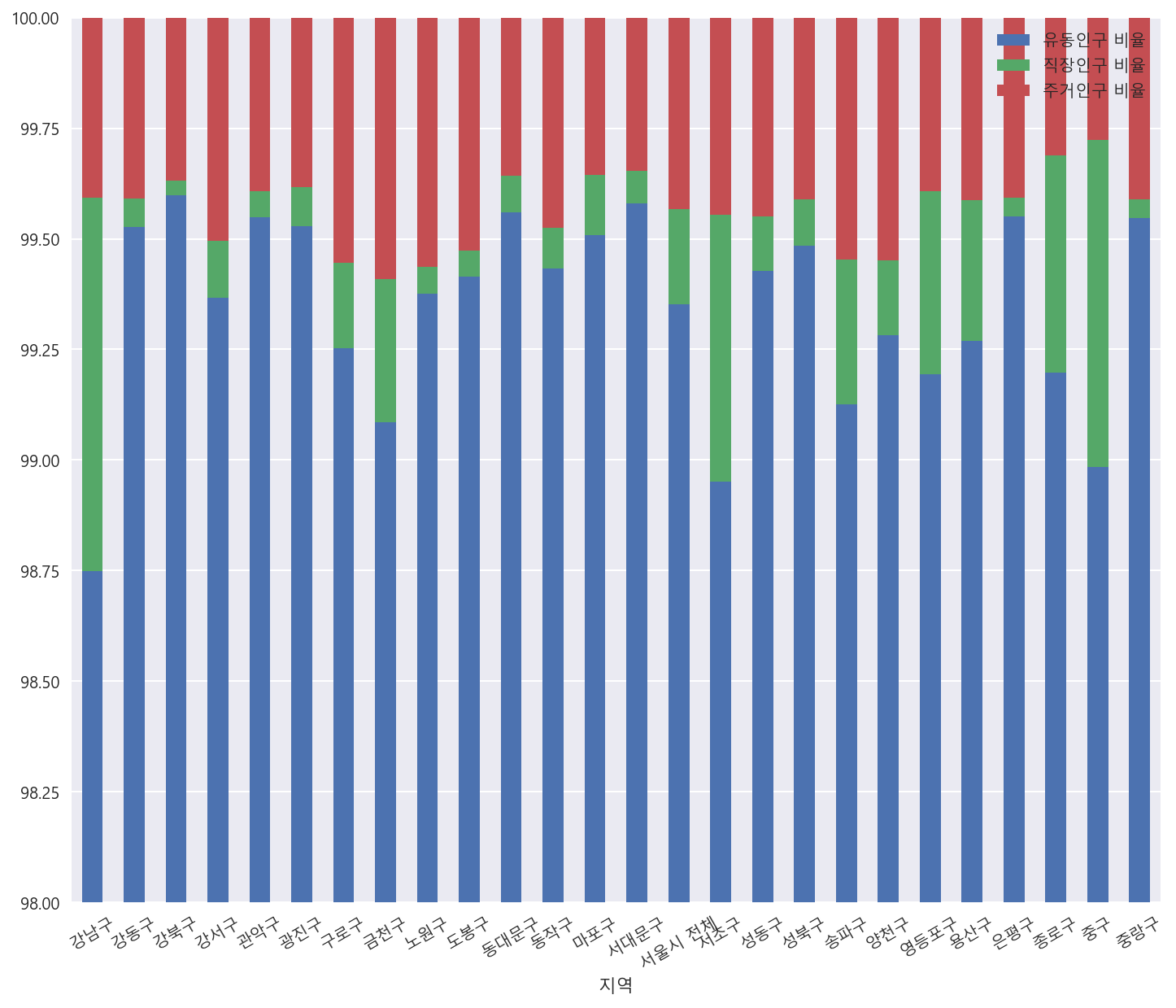
s=df[(df["지역"] == "강남구") | (df["지역"] =="서울시 전체") | (df["지역"] == "종로구")][["분기","지역","길단위 유동인구"]]
# s.groupby(s["지역"]).plot(x="분기", y="길단위 유동인구", figsize=(12,4))
X=s["분기"].unique()
Y1=s[s["지역"]=="서울시 전체"]["길단위 유동인구"]
Y2=s[s["지역"]=="강남구"]["길단위 유동인구"]
Y3=s[s["지역"]=="종로구"]["길단위 유동인구"]
plt.figure(figsize=(14,8))
plt.plot(X, Y1, label='서울시 평균')
plt.plot(X, Y2, label='강남구')
plt.plot(X, Y3, label='종로구')
plt.legend()
plt.show()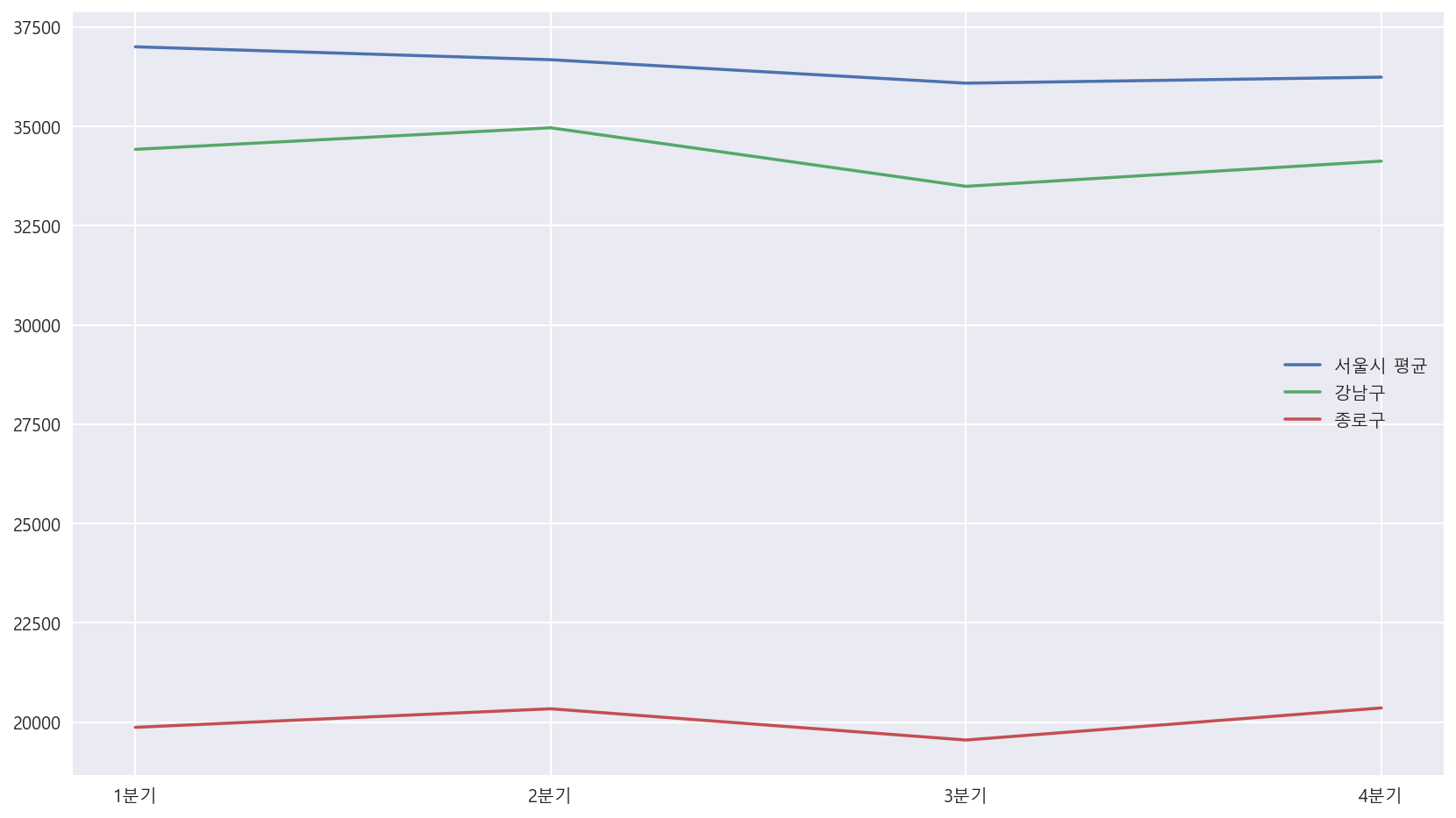
df = pd.read_csv("data/서울시_우리마을가게_상권분석서비스(신_상권_추정매출)_2021년.csv", encoding="cp949")
df1 = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(상권영역).csv", encoding="cp949", usecols=['상권_코드_명',"행정동_코드","시군구_코드",'엑스좌표_값','와이좌표_값'])
df = df.merge(df1, on="상권_코드_명", how="left")
k = pd.read_csv("data/서울시 우리마을가게 상권분석서비스(상권영역).csv", encoding="cp949", usecols=["엑스좌표_값","와이좌표_값"])
k["엑스좌표_값"] = pd.to_numeric(k["엑스좌표_값"], errors="coerce")
k["와이좌표_값"] = pd.to_numeric(k["와이좌표_값"], errors="coerce")
k = k.dropna()
k.index=range(len(k))
k.tail()
from pyproj import Proj, transform
import folium
import pyproj
def project_array(coord, p1_type, p2_type):
"""
좌표계 변환 함수
- coord: x, y 좌표 정보가 담긴 NumPy Array
- p1_type: 입력 좌표계 정보 ex) epsg:5181
- p2_type: 출력 좌표계 정보 ex) epsg:4326
"""
p1 = pyproj.Proj(init=p1_type)
p2 = pyproj.Proj(init=p2_type)
fx, fy = pyproj.transform(p1, p2, coord[:, 0], coord[:, 1])
return np.dstack([fx, fy])[0]
coord = np.array(k)
coord
p1_type = "epsg:5181"
p2_type = "epsg:4326"
# project_array() 함수 실행
result = project_array(coord, p1_type, p2_type)
result
k["위도"] = result[:,1]
k["경도"] = result[:,0]
df = df.merge(k, on="엑스좌표_값", how="left")
for col in df.columns :
dtype_name = df[col].dtypes.name
if dtype_name.startswith("int"):
df[col] = pd.to_numeric(df[col], downcast = "unsigned")
elif dtype_name.startswith("float"):
df[col] = pd.to_numeric(df[col], downcast = "float")
elif dtype_name == "bool":
df[col] = df[col].astype("int8")df = df.dropna()
# 골목상권에 업종들이 많이 있는 것을 확인.
df["상권_구분_코드_명"].value_counts().plot(kind="bar", rot=0)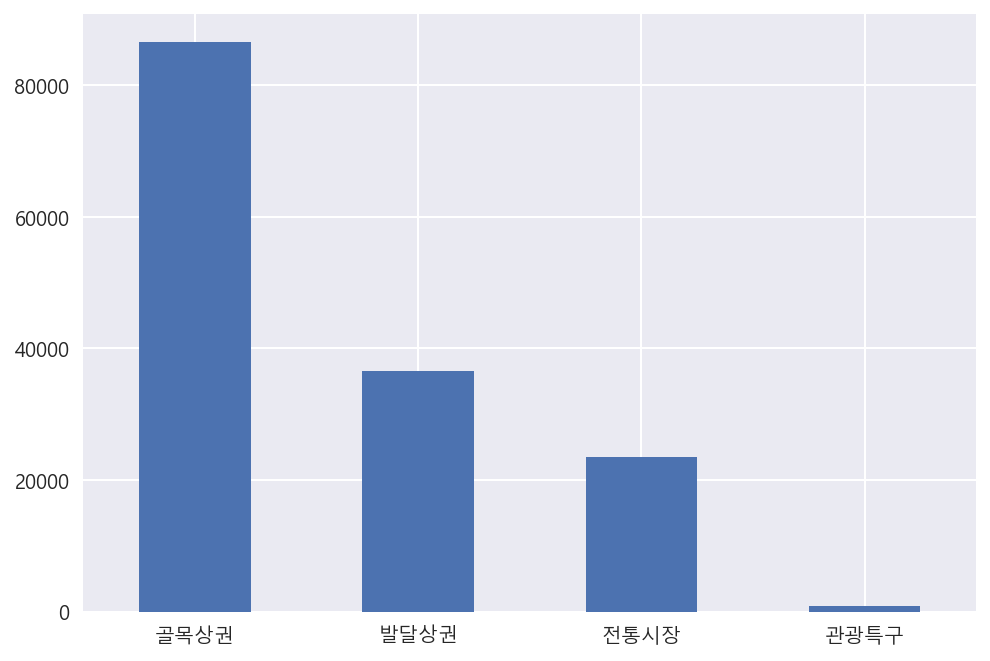
df.groupby("기준_분기_코드")[["월요일_매출_금액","화요일_매출_금액","수요일_매출_금액","목요일_매출_금액","금요일_매출_금액","토요일_매출_금액","일요일_매출_금액"]].mean().plot(kind="bar", rot=0)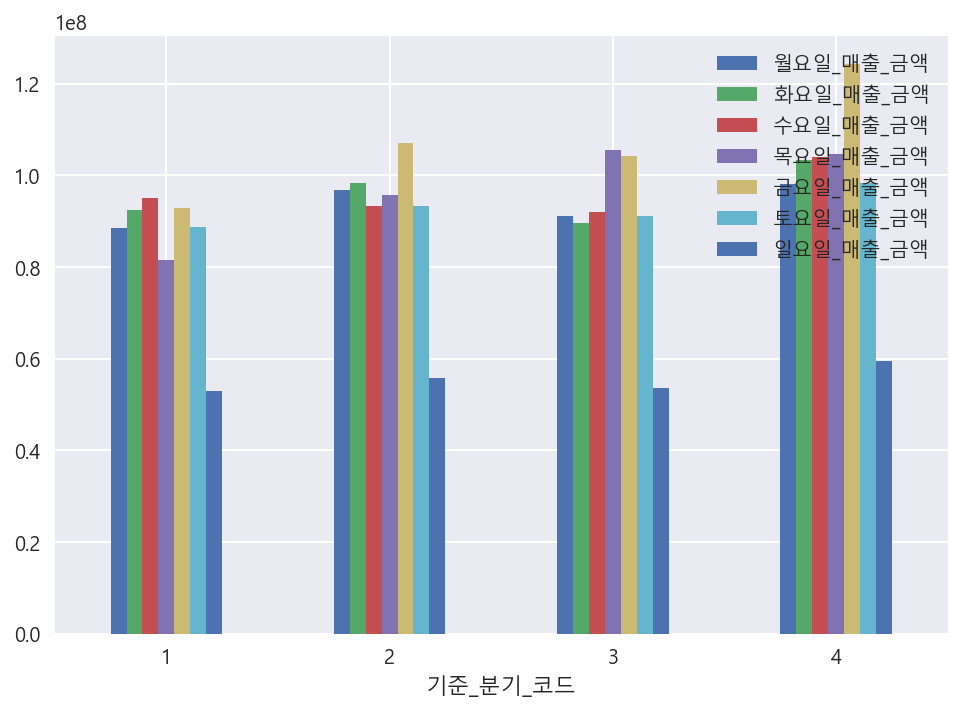
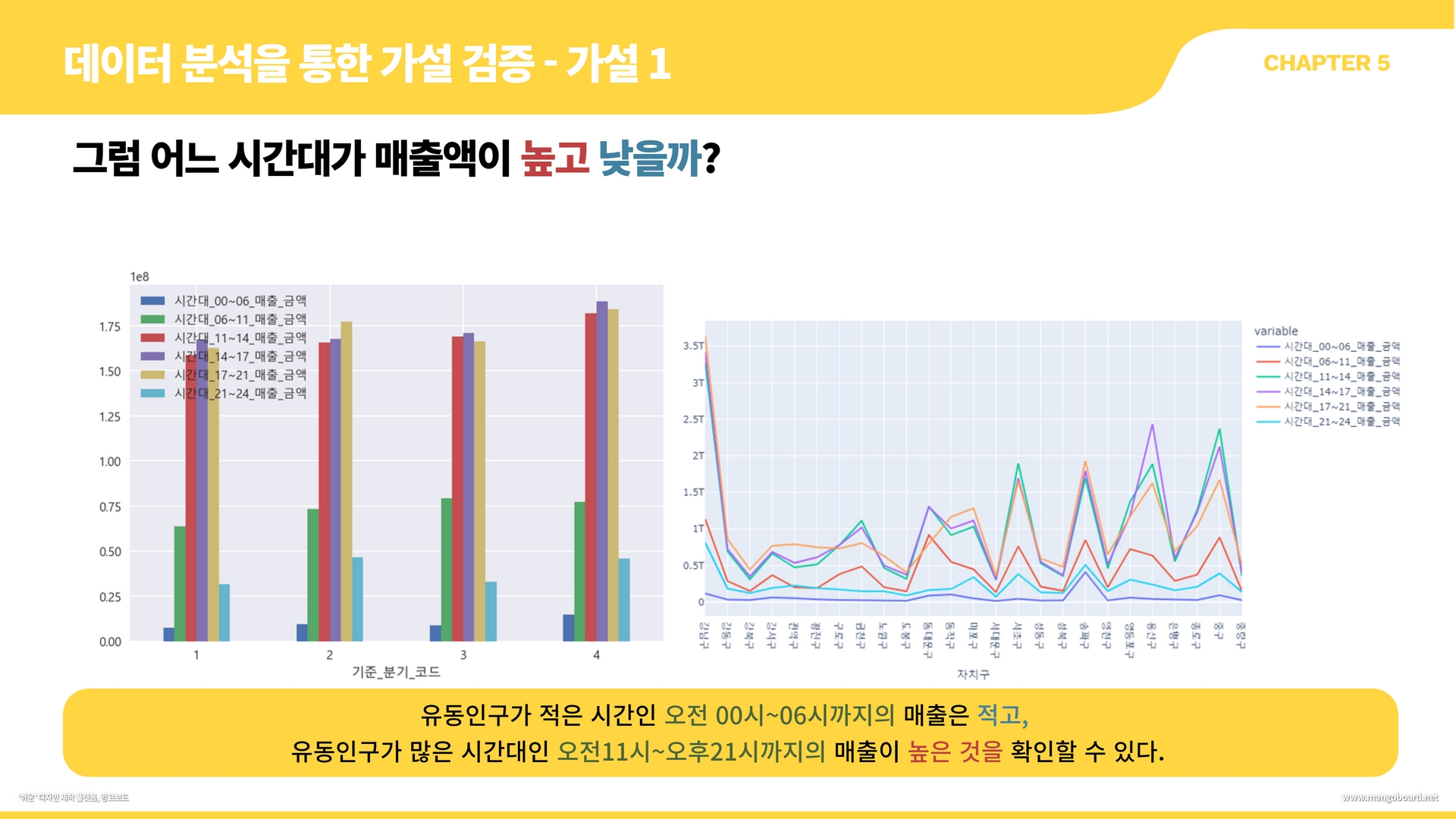
df.groupby("기준_분기_코드")[['시간대_00~06_매출_금액','시간대_06~11_매출_금액','시간대_11~14_매출_금액','시간대_14~17_매출_금액','시간대_17~21_매출_금액','시간대_21~24_매출_금액']].mean().plot(kind="bar", rot=0)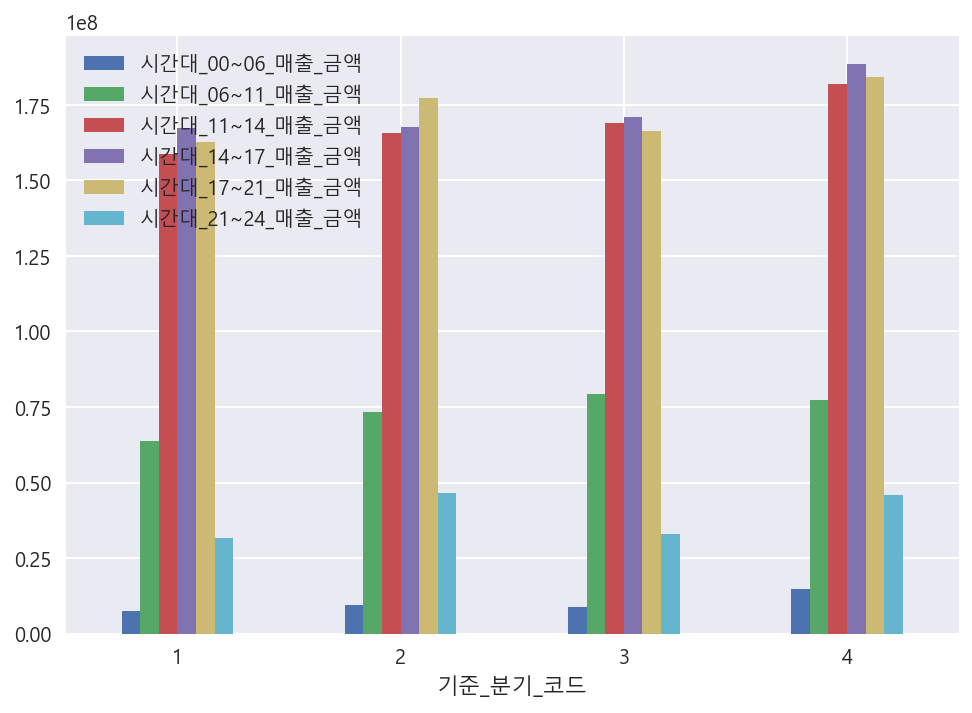
df.groupby("기준_분기_코드")[['남성_매출_금액','여성_매출_금액']].mean().plot(kind="bar", rot=0)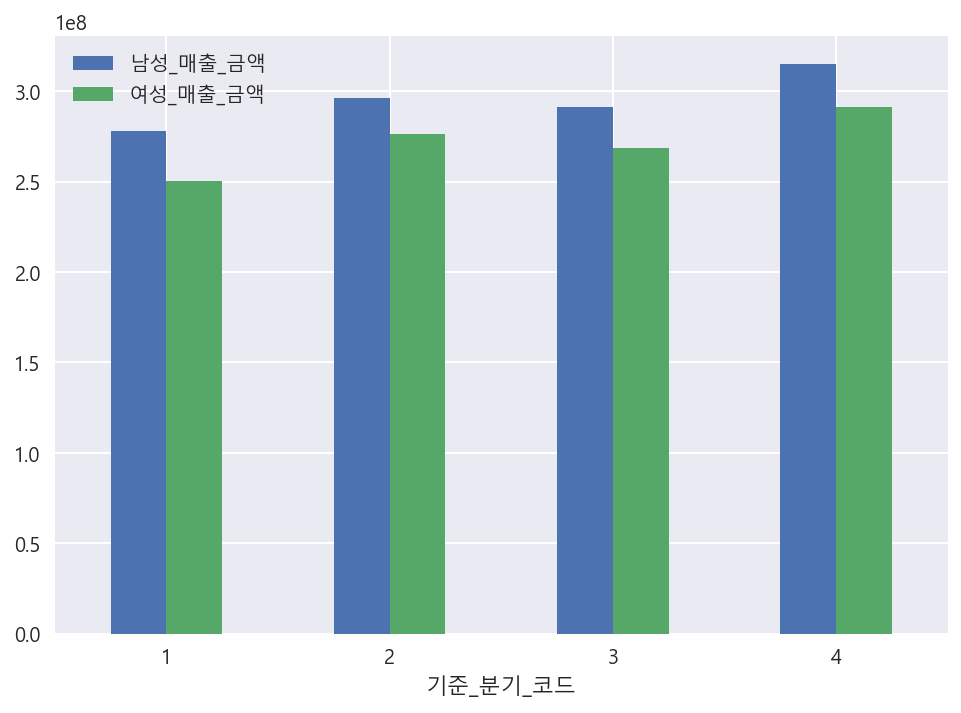
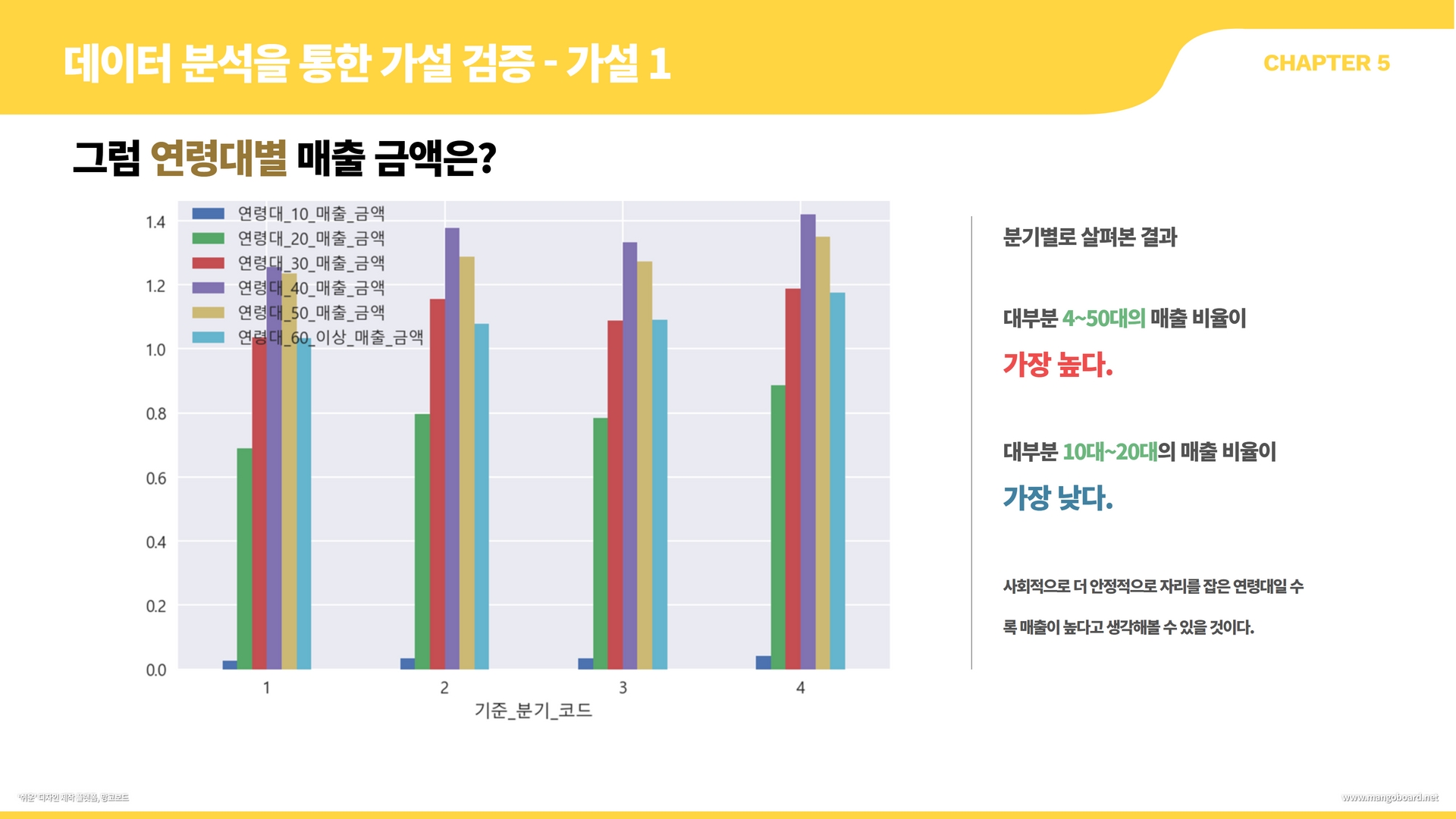
df.groupby("기준_분기_코드")[['연령대_10_매출_금액','연령대_20_매출_금액','연령대_30_매출_금액','연령대_40_매출_금액','연령대_50_매출_금액','연령대_60_이상_매출_금액']].mean().plot(kind="bar", rot=0)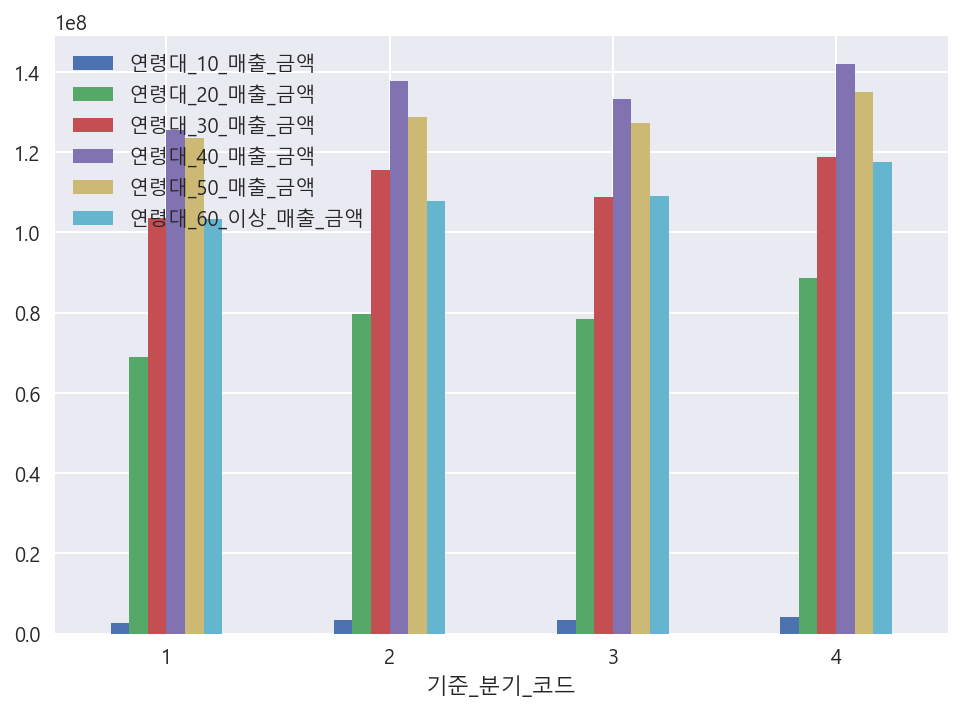
week_ratio = df[["자치구","월요일_매출_비율", "화요일_매출_비율" , "수요일_매출_비율", "목요일_매출_비율", "금요일_매출_비율","토요일_매출_비율" ,"일요일_매출_비율"]]
a = pd.pivot_table(data=week_ratio,index="자치구", aggfunc=np.sum)
px.line(a)
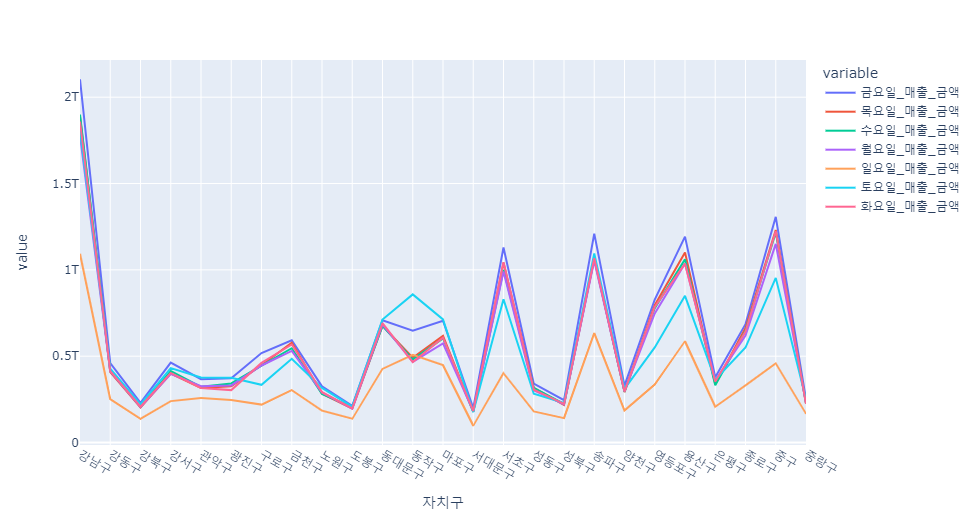
week_sale=df[["자치구","월요일_매출_금액","화요일_매출_금액","수요일_매출_금액","목요일_매출_금액","금요일_매출_금액","토요일_매출_금액","일요일_매출_금액"]]
e = pd.pivot_table(data=week_sale, index="자치구", aggfunc=np.sum)
px.line(e)
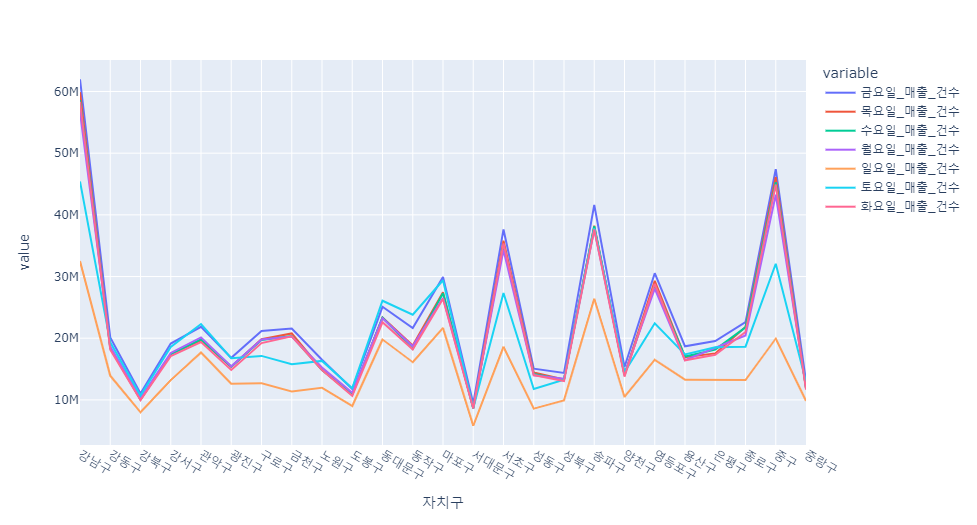
week_sale_count = df[["자치구",'월요일_매출_건수','화요일_매출_건수','수요일_매출_건수','목요일_매출_건수','금요일_매출_건수','토요일_매출_건수','일요일_매출_건수']]
i = pd.pivot_table(data=week_sale_count, index="자치구", aggfunc=np.sum)
px.line(i)
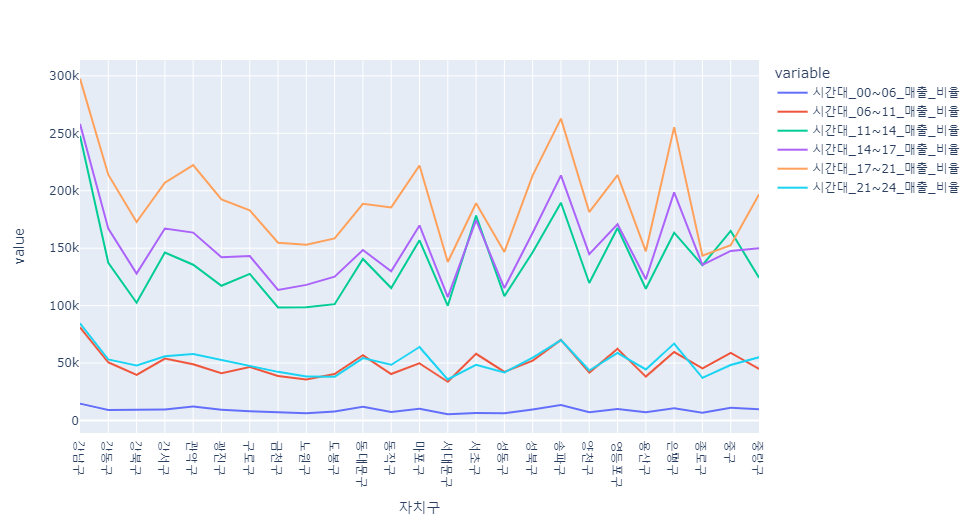
time_ratio = df[["자치구","시간대_00~06_매출_비율","시간대_06~11_매출_비율","시간대_11~14_매출_비율","시간대_14~17_매출_비율","시간대_17~21_매출_비율","시간대_21~24_매출_비율"]]
b = pd.pivot_table(data=time_ratio, index="자치구", aggfunc=np.sum)
px.line(b)
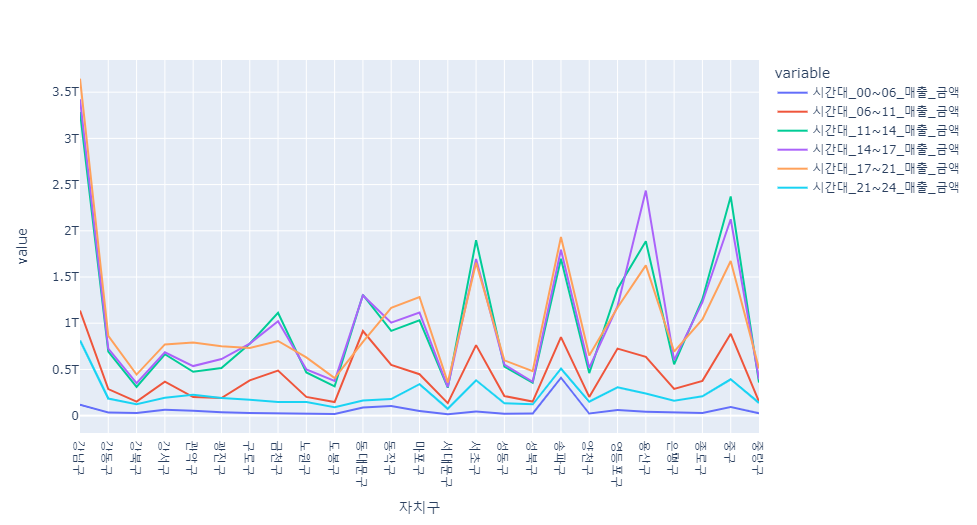
time_sale = df[["자치구",'시간대_00~06_매출_금액','시간대_06~11_매출_금액','시간대_11~14_매출_금액','시간대_14~17_매출_금액','시간대_17~21_매출_금액','시간대_21~24_매출_금액']]
f = pd.pivot_table(data=time_sale,index="자치구", aggfunc=np.sum)
px.line(f)
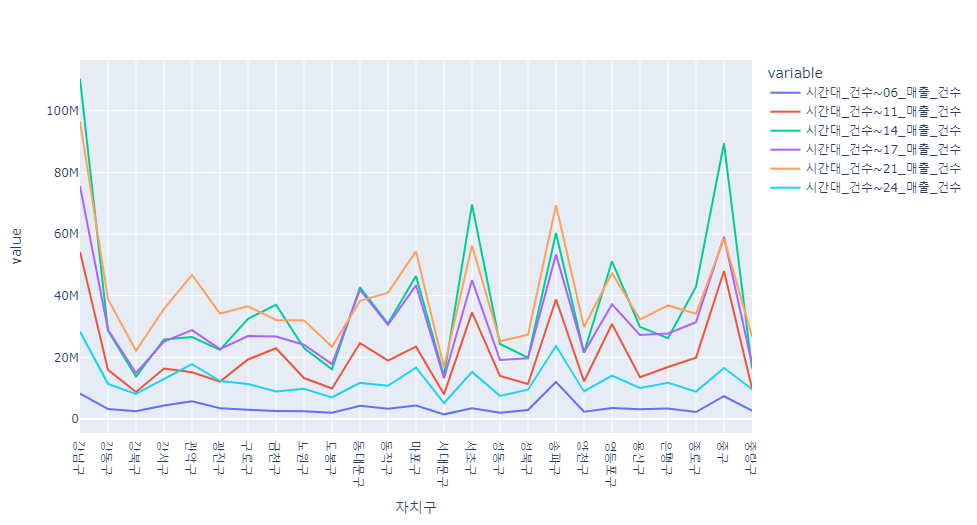
time_sale_count = df[["자치구",'시간대_건수~06_매출_건수','시간대_건수~11_매출_건수','시간대_건수~14_매출_건수','시간대_건수~17_매출_건수','시간대_건수~21_매출_건수','시간대_건수~24_매출_건수']]
j = pd.pivot_table(data=time_sale_count, index="자치구", aggfunc=np.sum)
px.line(j)
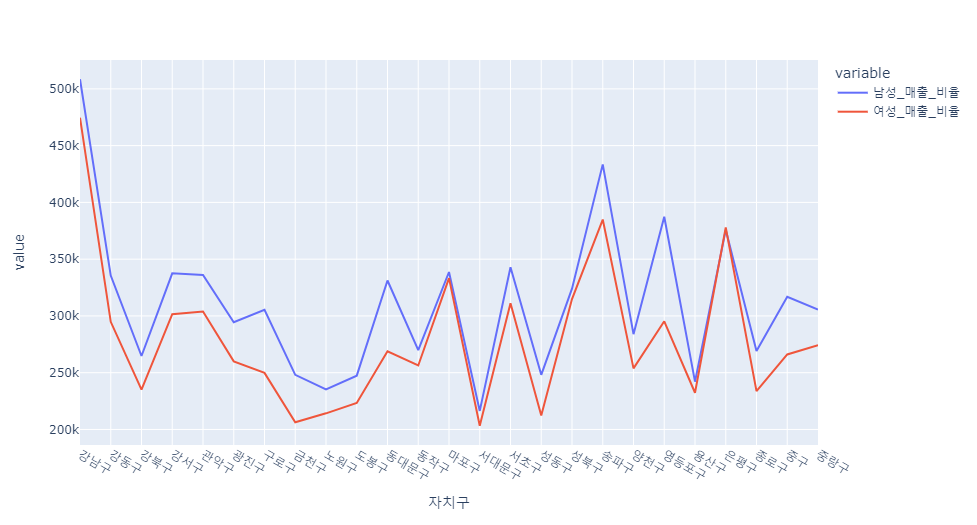
gender_ratio = df[["자치구","남성_매출_비율","여성_매출_비율"]]
c = pd.pivot_table(data=gender_ratio, index="자치구", aggfunc=np.sum)
px.line(c)
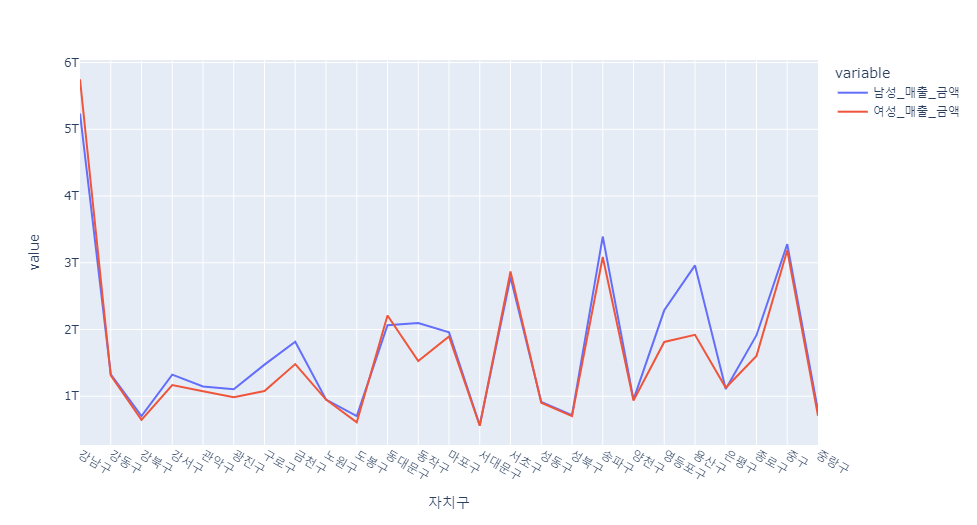
gender_sale = df[["자치구",'남성_매출_금액','여성_매출_금액']]
g = pd.pivot_table(data=gender_sale, index="자치구", aggfunc=np.sum)
px.line(g)
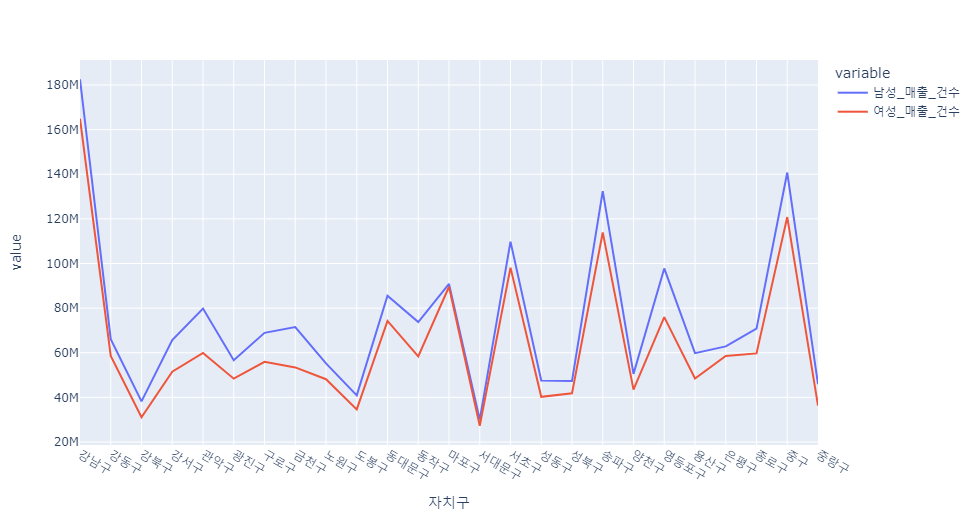
gender_sale_count = df[["자치구",'남성_매출_건수','여성_매출_건수']]
k = pd.pivot_table(data=gender_sale_count, index="자치구", aggfunc=np.sum)
px.line(k)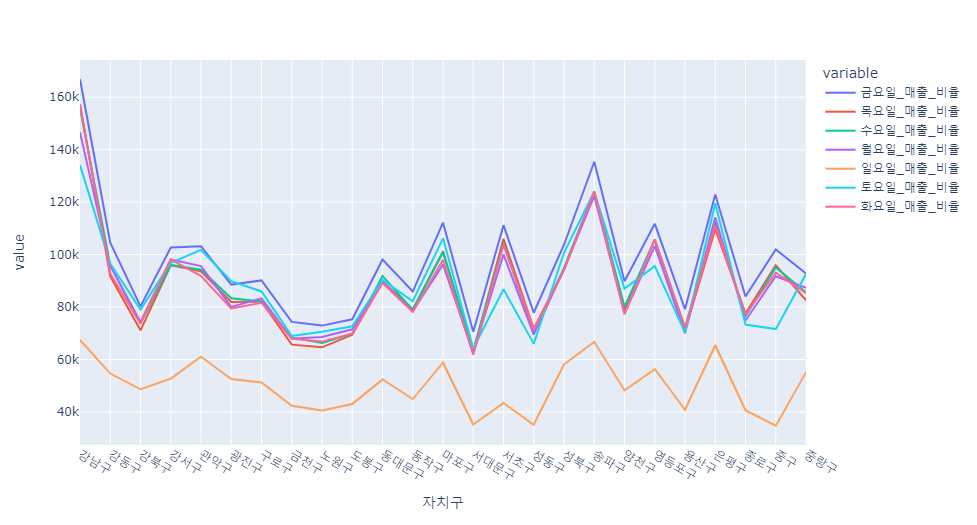

데이터 꿈나무 (시리즈로 들어가면 글이 정리되어있습니다!)