
본 프로젝트는 멋쟁이사자처럼 AI School 6기 9팀이 함께 진행했습니다.
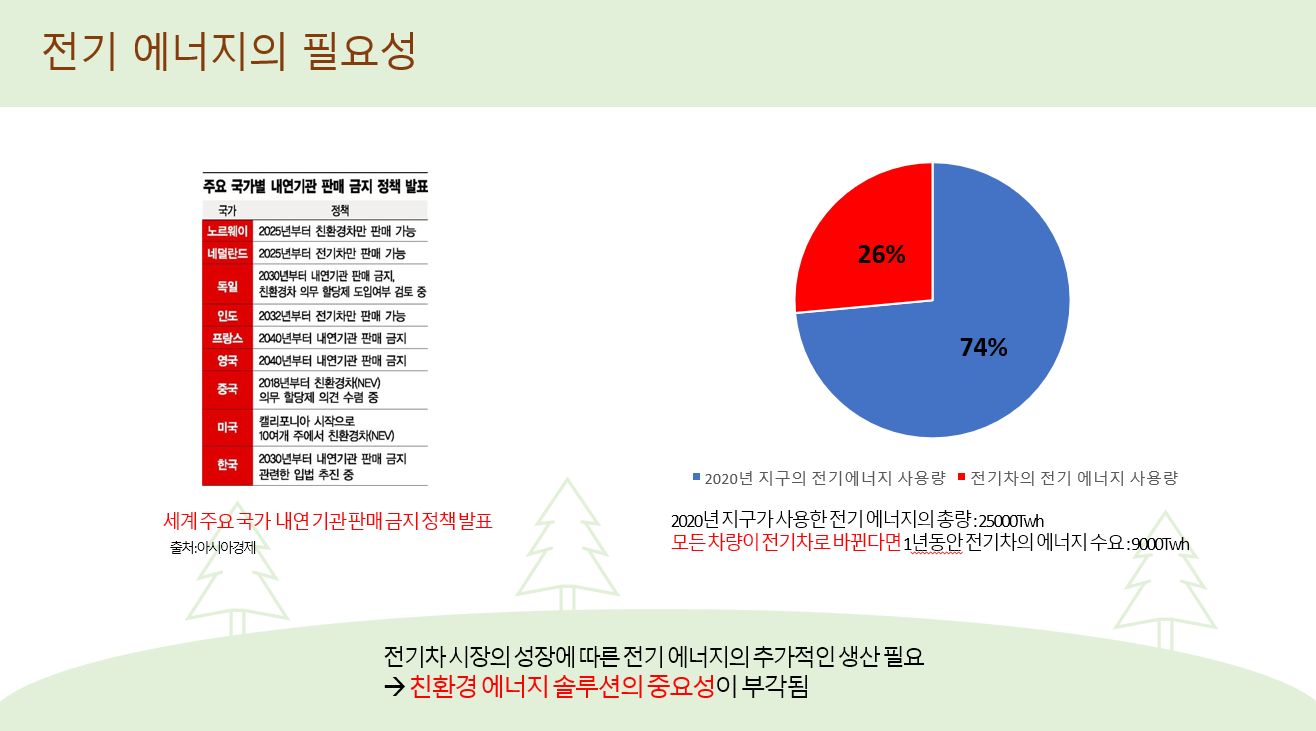
주제 선정 이유 및 개요
신재생 에너지 관련 공공 데이터들을 가지고 팀원들 각자 데이터 전처리와 EDA를 진행하며 나름의 의미를 도출하고 종합하였습니다.

기본 설정
필요한 모듈 불러오기
## 기본 도구
import pandas as pd
import numpy as np
from datetime import datetime
from sklearn import preprocessing
## 웹 스크래핑 도구
import requests
from bs4 import BeautifulSoup as bs
## 시각화 도구
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
import matplotlib.pyplot as plt
%matplotlib inlinematplotlib 한글 사용을 위한 폰트설정
# 시각화 한글폰트 설정
def get_font_family():
"""
시스템 환경에 따른 기본 폰트명을 반환하는 함수
"""
import platform
system_name = platform.system()
# colab 사용자는 system_name이 'Linux'로 확인
if system_name == "Darwin" :
font_family = "AppleGothic"
elif system_name == "Windows":
font_family = "Malgun Gothic"
else:
!apt-get install fonts-nanum -qq > /dev/null
!fc-cache -fv
import matplotlib as mpl
mpl.font_manager._rebuild()
findfont = mpl.font_manager.fontManager.findfont
mpl.font_manager.findfont = findfont
mpl.backends.backend_agg.findfont = findfont
font_family = "NanumBarunGothic"
return font_family
plt.style.use("seaborn-whitegrid")
# 폰트설정
plt.rc("font", family=get_font_family())
# 마이너스폰트 설정
plt.rc("axes", unicode_minus=False)
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'# 서울특별시 신재생에너지 허가 및 사업개시 정보 분석
> 출처: 서울시 열린데이터 광장에서 신재생에너지 https://data.seoul.go.kr/dataList/OA-15522/S/1/datasetView.do데이터 불러오기(공통)
- API를 통해 json 형식의 데이터 불러오기
import sys
sys.path.append('config')
from api_key import api_keys
api_key = api_keys.seoul_data["key"]url = f"http://openapi.seoul.go.kr:8088/{api_key}/json/renewableEnergyInfo/1/1000"
print(url)
response = requests.get(url)
df_common1 = pd.DataFrame(response.json()['renewableEnergyInfo']['row'])
df_common1.shape(309, 11)
데이터 전처리 및 수치 분석
df_basic = df_common1.copy()
df_basic.head()df_basic.info()
# 전부 object 형식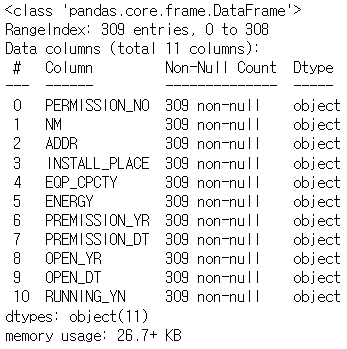
df_basic.describe(include="object")
# PERMISSION_NO, NO : 키 데이터
# INSTALL_PLACE, ENERGY, RUNNING_YN : 각각 건물옥상, 태양광, 가동중이 데이터값의 대부분을 차지
# ADDR : 구 별로 정제할 것
# PREMISSION_DT, OPEN_DT : 형식을 알 수 없으므로 무의미한 데이터
# PREMISSION_YR, OPEN_YR : 연도별로 정리 가능한 데이터
# EQP_CPCTY : 수치형 데이터로 변환하여 사용- 설치 장소의 약 94%가 건물 옥상
df_basic["INSTALL_PLACE"].value_counts(normalize=True) * 100
- 에너지원의 약 98%가 태양광
df_basic["ENERGY"].value_counts(normalize=True) * 100
- 설치된 발전소의 100%가 가동중
df_basic["RUNNING_YN"].value_counts(normalize=True) * 100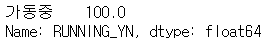
# ADDR 구 별로 정제
df_basic["ADDR_GU"] = df_basic["ADDR"]
gu_list = df_basic["ADDR_GU"].to_list()
gu_listgu_list = [gu.split()[1] for gu in gu_list]
gu_listdf_basic["ADDR_GU"] = gu_list
df_basic["ADDR_GU"]# EQP_CPCTY 수치형 데이터로 정제
df_basic["EQP_CPCTY"] = df_basic["EQP_CPCTY"].astype(float)df_basic.info()# 데이터 분석에 필요한 자료들 위주의 데이터프레임 생성
# 기타 자료가 너무 적으므로, 서울시의 '건물옥상'에 있는 '태양광' 발전소 한정으로 데이터 분석 (전부 '가동중')
df = df_basic[(df_basic["INSTALL_PLACE"] == "건물옥상") & (df_basic["ENERGY"] == "태양광")]
df.shape(289,12)
# RUNNING_YN과 INSTALL_PLACE, ENERGY의 데이터값이 전부 '가동중'인 "건물옥상"과 "태양광"으로 동일하므로 삭제
df = df.drop(columns = ["RUNNING_YN", "INSTALL_PLACE", "ENERGY"], axis=1)
df.shape(289,9)
#PREMISSION_DT와 OPEN_DT는 해석할 수 없는 무의미한 데이터이므로 삭제
df = df.drop(columns = ["PREMISSION_DT", "OPEN_DT"], axis=1)
df.shape(289,7)
# 데이터 분석 과정에서, ADDR_GU가 ADDR을 대체하므로 ADDR 삭제
df = df.drop(columns = "ADDR", axis=1)
df.shape(289, 6)
# 서울시 건물옥상에서 가동중인 태양광 발전소의 데이터프레임
df.head()데이터 시각화에 사용할 최종 데이터 : EQP_CPCTY, PREMISSION_YR, OPEN_YR, ADDR_GU (4개)
각각의 데이터를 확인 후 정제. ex)결측치 정리
df["PREMISSION_YR"].value_counts()
# 전부 연도별로 깔끔하게 정리되어 있는 걸 확인df["OPEN_YR"].value_counts()
# 이상 데이터 발견. 연도를 나타내는 범주형 데이터이므로 우선 '연도 자료 없음'으로 처리df["OPEN_YR"] = df["OPEN_YR"].replace("-", "연도 자료 없음")
df["OPEN_YR"].value_counts()df.corr()
# 수치형 데이터가 하나뿐이라 무의미데이터 시각화
연도 기준
- 허가년도. 2013년에 가장 허가가 많이 났고, 2013년 이전보다 2013년 이후에 허가가 많이 남.
premission_list = [str(a) for a in range(2005,2019)]
fig = sns.countplot(data=df, x="PREMISSION_YR", order=premission_list)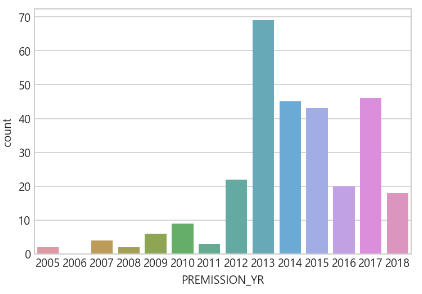
- 설비용량은 0~200 사이에 집중되어 있다는 걸 알 수 있다.
- 큰 규모의 발전소의 양이 상당히 적다는 걸 알 수 있다.
# hist()를 통해 전체 수치변수에 대한 히스토그램 그리기
df.hist(bins=30)
plt.show()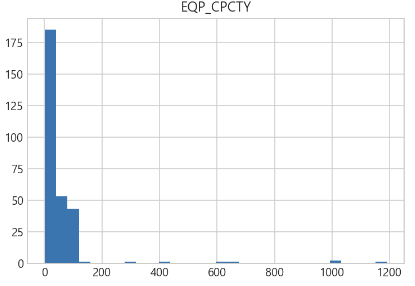
- 2012, 2013, 2015, 2017년에 독보적으로 설비용량이 많은 발전소의 설치가 허가됨
- 설비용량이 많은 발전소의 대부분이 2013 ~ 2016년도 사이에 사업을 개시함
# relplot 으로 범주형 변수에 따라 서브플롯을 그립니다.
# relplot 의 default는 scatterplot
sns.relplot(data=df, x="PREMISSION_YR", y="EQP_CPCTY", hue="OPEN_YR", hue_order=df["OPEN_YR"].sort_values())
plt.show()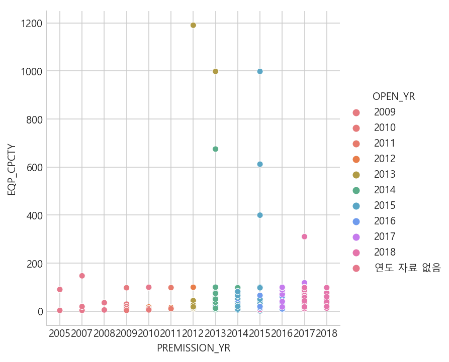
- 사업개시년도. 2014년에 가장 사업 시행이 많이 됐고, 2014년 이전보다 2014년 이후에 사업이 많이 개시됨
open_list = [str(a) for a in range(2009,2019)]
open_list.append("연도 자료 없음")
sns.countplot(data=df, x="OPEN_YR", order=open_list)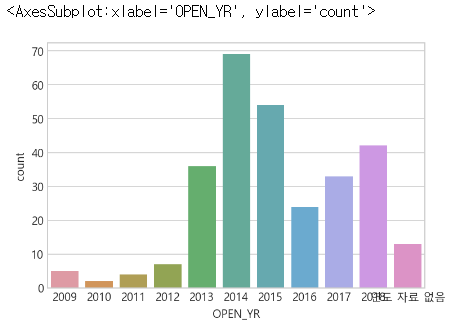
- 사업개시년도의 연도 자료가 없는 발전소들은 전부 2011년 이전에 허가가 난 발전소라는 걸 알 수 있다
# 허가년도와 사업개시년도 간의 관계
pd.crosstab(df["PREMISSION_YR"], df["OPEN_YR"])- 2013년에 사업을 개시한 발전소들이 평균적으로 가장 높은 설비용량을 가지고 있다
df.groupby("OPEN_YR")["EQP_CPCTY"].agg(["mean", "count", "sum"]).sort_values("mean")# barplot 으로 평균 값 구하기
sns.barplot(data=df, x="OPEN_YR", y="EQP_CPCTY", estimator=np.mean, ci=None, order=open_list)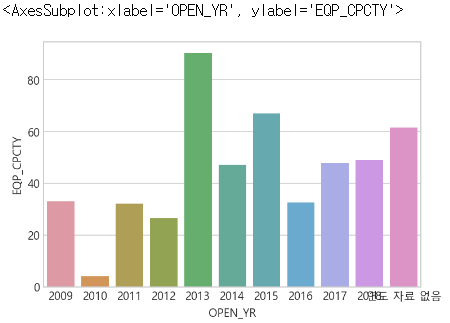
- 2013 ~ 2015 년도에 집중해서 큰 규모로 태양광 에너지 발전소 사업을 개시함
# barplot 으로 합계 값 구하기
sns.barplot(data=df, x="OPEN_YR", y="EQP_CPCTY", estimator=np.sum, ci=None, order=open_list)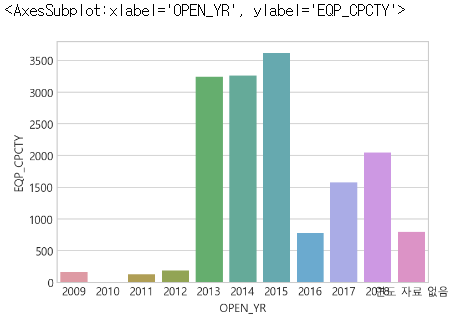
구 기준
- 광진구에 가장 많은 태양광 발전소가, 종로구에 가장 적은 태양광 발전소가 설치됨
#범주형 데이터끼리의 비교 필요
px.bar(df, x="ADDR_GU", title="구별 발전소 수")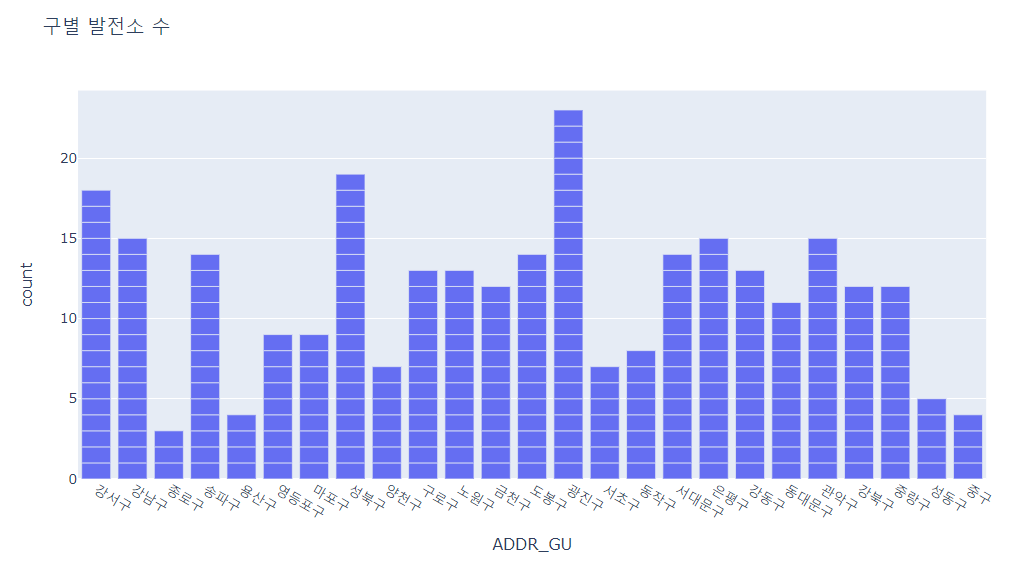
- 강서구의 총 설비용량이 가장 많고, 종로구의 총 설비용량이 가장 적음
- 강서구, 강남구, 광진구, 강동구, 성동구에 큰 규모의 태양광 발전소가 설치되었다는 걸 알 수 있음
px.bar(df, x="ADDR_GU", y="EQP_CPCTY", title="구별 설비용량")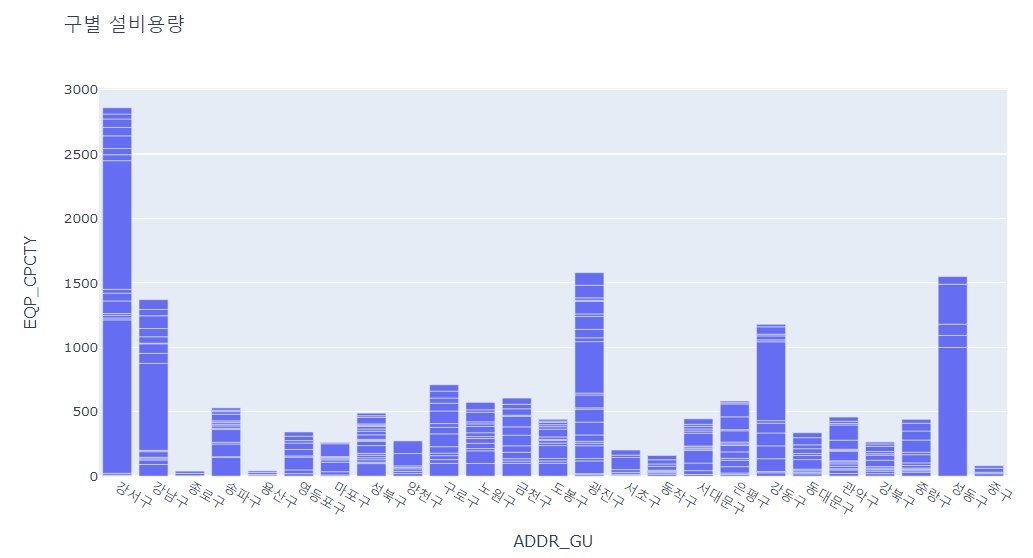
# 연도에 따른 구별 발전소 설치 허가 추이 분석
df_P_GU = pd.crosstab(df["PREMISSION_YR"], df["ADDR_GU"])
fig = px.line(df_P_GU)
fig.update_xaxes(rangeslider_visible=True)
fig.show()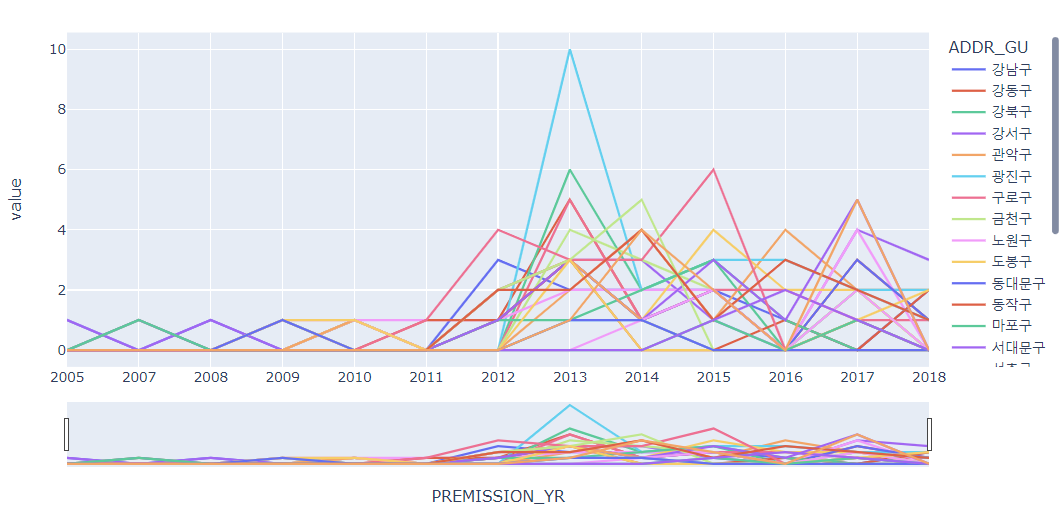
# 연도에 따른 구별 발전소 사업 개시 추이 분석
df_O_GU = pd.crosstab(df["PREMISSION_YR"], df["ADDR_GU"])
fig = px.line(df_O_GU)
fig.update_xaxes(rangeslider_visible=True)
fig.show()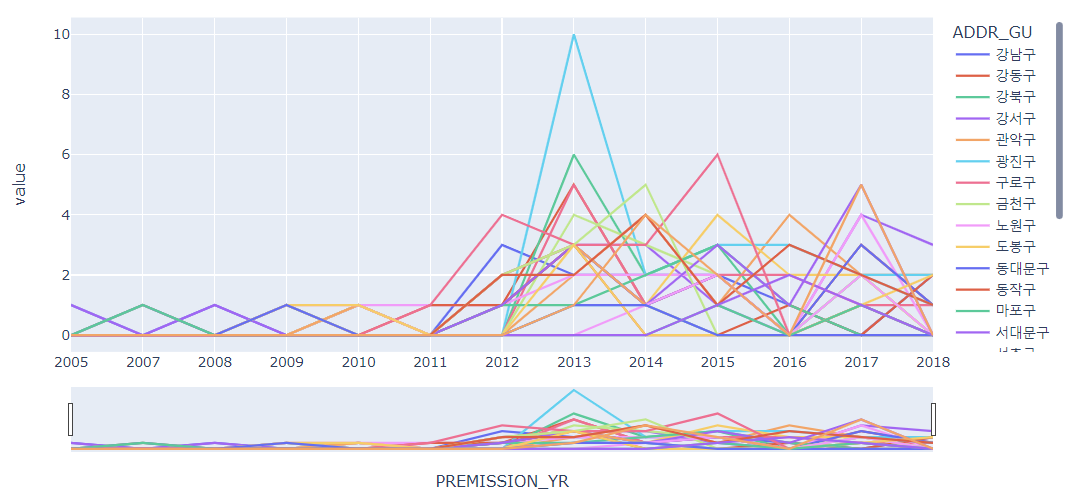
데이터 전처리
df = df_common1.copy()df.columns = df.columns = ["허가번호", "상호(발전소명)", "발전소주소", "설치장소", "설비용량", "에너지원", "허가년도", "허가일자", "사업개시년도", "사업개시일자", "가동여부"]
# 빈값 데이터가 "-"로 표기가 되어있어서 빈값으로 처리를 해주었다.
df = df.replace("-", np.NaN)주소를 자치구 형태로 뽑아 올 수 있도록 했다.
# 신재생에어지 허가 상황을 자치구별로 구분하고 싶어서 주소를 공백으로 구분하여 "서울시,00구,00로"로 나눠서 각 컬럼에 저장했다.
# 그 중 서울시와 00로는 필요없어서 삭제. 그리고 기존의 데이터프레임에 옆으로 합쳤다.
area = df["발전소주소"].str.split(" ", expand=True)
area.columns = ["서울특별시", "자치구", "로"]
del area["로"]
del area["서울특별시"]
df = pd.concat([df, area], axis=1)EDA 시각화
-
신재생에너지를 각 연도별로 허가가 난 비율과, 사업이 개시된 년도를 확인해 보았다.
- 허가년도가 가장 높은 년도는 2013년도인것을 확인할 수 있다.
_ = df["허가년도"].value_counts().sort_index().plot(kind="bar",
rot = 60, title = "연도별 신재생 에너지 발전 허가 수", ylabel = "허가 수")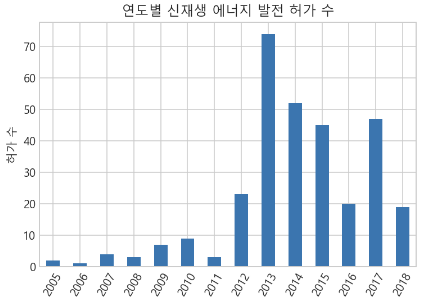
- 사업개시년도가 가장 높은 년도는 2014년도인것을 확인할 수 있다.
_ = df["사업개시년도"].value_counts().sort_index().plot(kind="bar",
rot = 60, title = "연도별 신재생 에너지 사업개시 수", ylabel = "사업개시 수")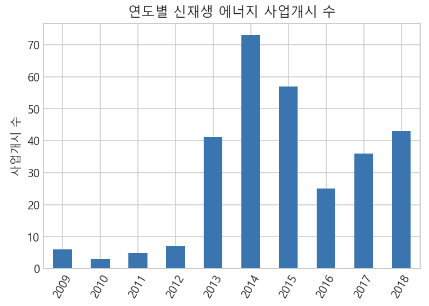
- px를 활용해서 허가받은 년도의 사업이 언제 사업개시되었는지 비교했다.
y = pd.crosstab(df["허가년도"], df["사업개시년도"])
px.bar(y, title="신재생 에너지 발전 허가년도별 사업개시년도")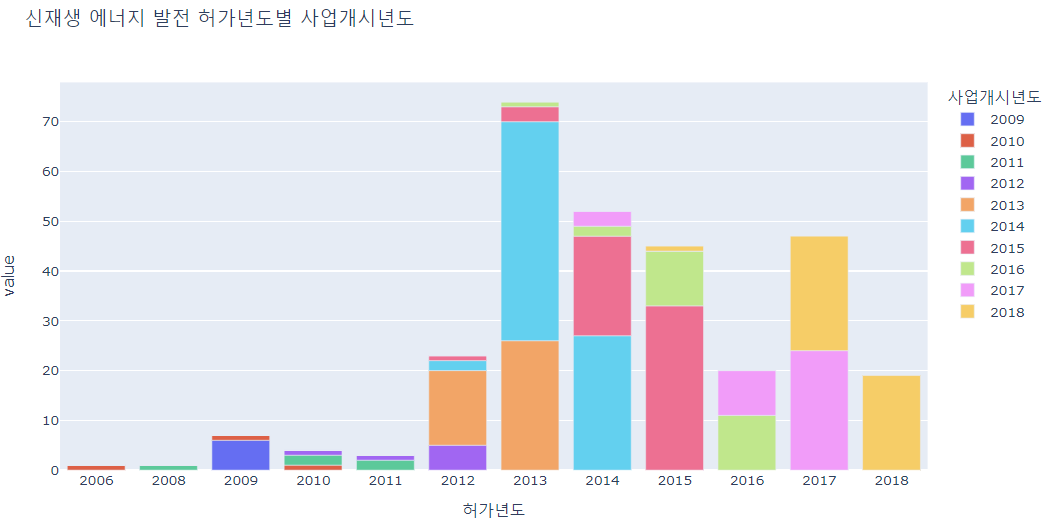
- 자치구별로 사업개시년도를 살펴보았다.
region = pd.crosstab(df["자치구"], df["사업개시년도"])
px.bar(region, title="자치구별 사업개시년도")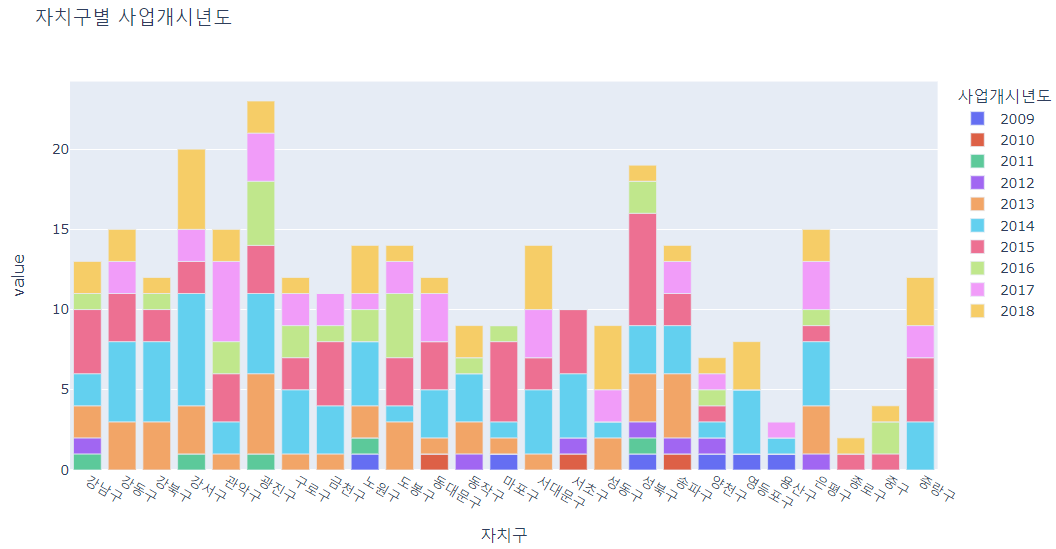
re = pd.crosstab(df["자치구"], df["허가년도"])
# 자치구별로 허가년도를 살펴보았다.
px.bar(re, title="자치구별 허가년도")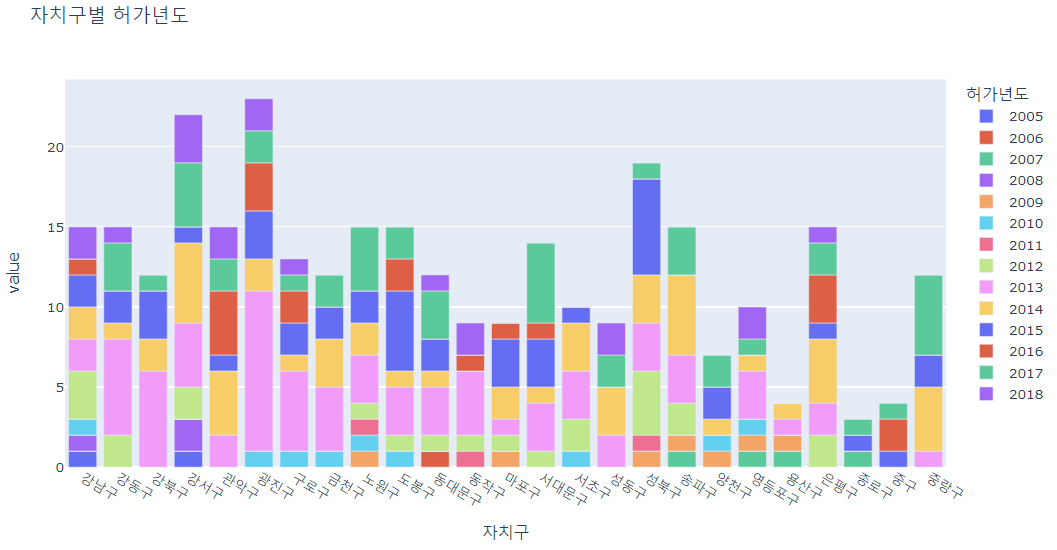
gu = df["자치구"].value_counts()- 자치구별로 신재생에너지 설치 비율을 살펴보았다.
# 자치구별로 신재생에너지 사용 비율을 살펴보았다.
gu.plot.bar(figsize=(12,4), title="자치구별 신재생에너지 설치 상황", rot=60)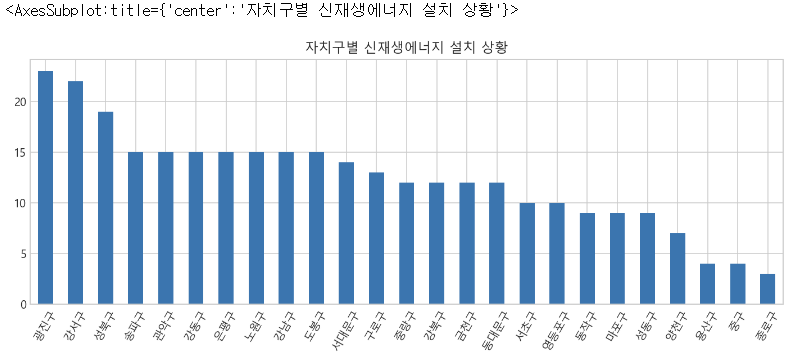
# 신재생에너지 종류의 비율을 살펴보았다.
power_sort = px.pie(df, values="허가년도", names="에너지원", title="서울시에서 사용중인 신재생에너지 종류")
power_sort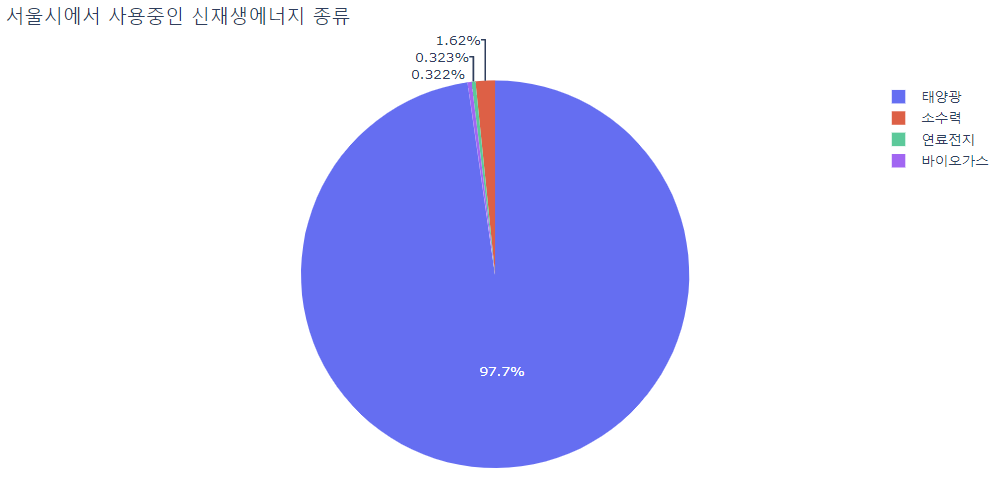
# 신재생에너지 설치장소 비율을 살펴보았다.
px.pie(df, values="허가년도", names="설치장소", title="신재생에너지 설치장소")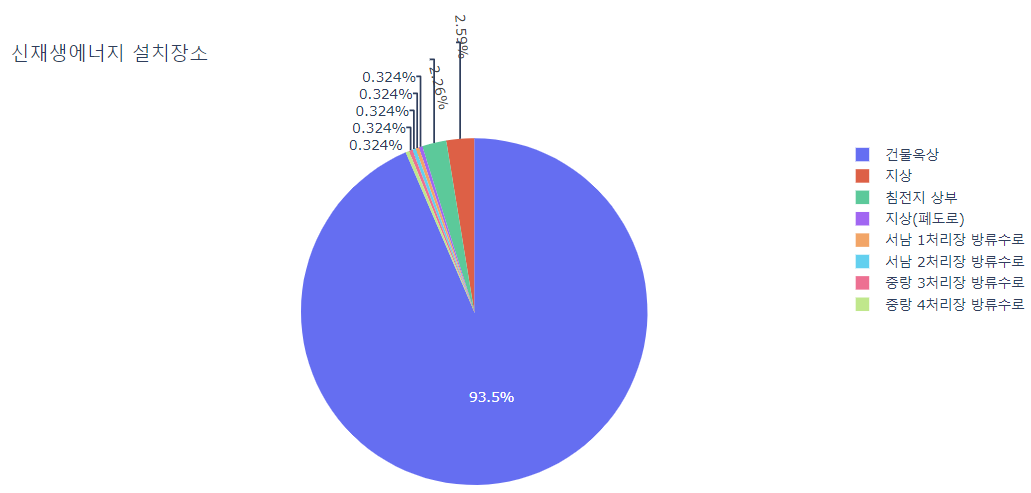
school = df.loc[df["상호(발전소명)"].str.contains("학교")]
school["구분"] = "학교"
power_station = df.loc[df["상호(발전소명)"].str.contains("발전소")]
power_station["구분"] ="발전소"
etc = df[~df["상호(발전소명)"].str.contains("학교") & ~df["상호(발전소명)"].str.contains("발전소")]
etc["구분"] = "기타"
df1 = pd.concat([school, power_station, etc])# 설치된 상호들을 보니 크게 학교, 발전소, 교회 등으로 나눠져있는 것을 확인하였고, 이것을 파이차트로 구분헸다.
px.pie(df1, values="허가년도", names="구분", title="신재생에너지 설치 상호 비교")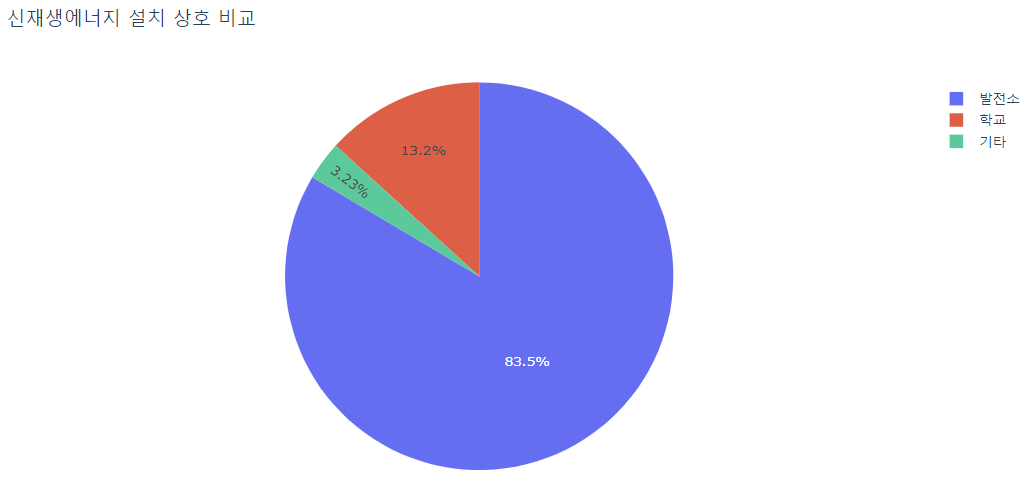
- 데이터 살펴보기
df_seoul = df_common1.copy()
columns = ['허가번호','상호(발전소명)','발전소 주소','설치장소', '설비용량','에너지원',
'허가년도','허가일자','사업개시년도','사업개시일자','가동여부'] # 한글로 컬럼명 변경
df_seoul.columns = columnsdf_seoul.head(5)- 데이터 형식 확인
df_seoul.info()데이터 전처리
- 설비용량을 숫자 형식으로 변경
df_seoul["설비용량"] = df_seoul["설비용량"].astype('float')- "허가년도", "허가일자", "사업개시일자"의 날짜 형식 변경
df_seoul["허가년도"] = pd.to_datetime(df_seoul["허가년도"]).dt.year
df_seoul["허가일자"] = pd.to_timedelta(df_seoul["허가일자"].astype('float'), unit = 'D') + pd.to_datetime('1900-01-01')
df_seoul["사업개시일자"] = pd.to_timedelta(df_seoul["사업개시일자"].replace('-', 0).astype('float'), unit = 'D') + pd.to_datetime('1900-01-01')
df_seoul["사업개시일자"][df_seoul["사업개시일자"] == '19000101'] = None- 변환된 데이터 형식 확인
df_seoul.sample(5)df_seoul.info()서울시 지역구 및 에너지원 별 설비용량
- 발전소 주소에서 지역구를 분리해내어 '지역' 칼럼에 저장
def get_district(address):
return address.split()[1]df_seoul['지역'] = [get_district(address) for address in df_seoul["발전소 주소"]]- 서울시 전체 지역에서 신재생 에너지 발전 중 태양광의 비중이 매우 높음.
# 지역과 에너지원 별 설비용량을 구했을 때, 지역별로 존재하지 않는 에너지원 항목도 포함시키기 위해 지역과 에너지원의 모든 경우의 수를 고려하여 multiindex를 생성하고 데이터프레임에 적용
index = pd.MultiIndex.from_product((set(df_seoul["지역"]), set(df_seoul["에너지원"])), names=["지역", "에너지원"])
df_seoul_gr = df_seoul.groupby(["지역","에너지원"]).sum()[["설비용량"]]
df_seoul_gr = df_seoul_gr.reindex(index, fill_value = 0) ## 존재하지 않는 에너지원에 대한 설비용량을 0으로 채워넣음
df_seoul_gr = df_seoul_gr.reset_index().set_index("지역") ## 지역만 index로 재지정
df_seoul_gr- 신재생 에너지 발전 중 태양광은 서울 지역 전반에서 이뤄지는 반면, 다른 에너지원 들은 특정 지역에서만 이뤄지는 경우가 많음.
## pivot table을 활용한 plotting
_ = pd.pivot_table(df_seoul_gr,
index = df_seoul_gr.index,
columns = "에너지원",
values= "설비용량").plot.bar(subplots = "에너지원",
figsize = (12, 12),
title = "서울 지역구 및 에너지원 별 설비용량", ylabel = "설비용량", rot = 60)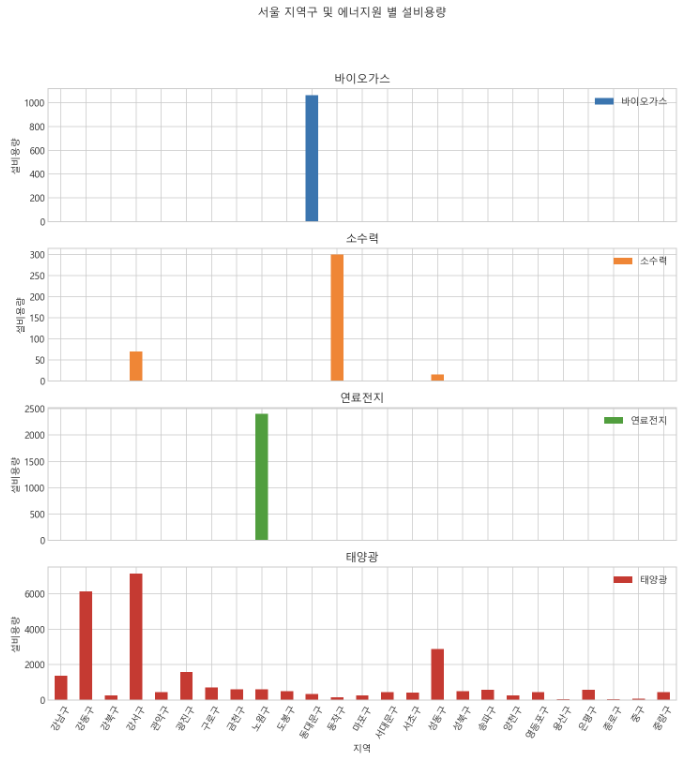
choropleth map에 표현한 지역 및 에너지원 별 설비용량
- 서울시 geojson을 활용하여 지역구별 시각화
South Korea (Github): https://github.com/southkorea
## choropleth map을 그리기 위해 서울시 geojson을 로드
geojson_seoul = requests.get("https://raw.githubusercontent.com/southkorea/seoul-maps/master/juso/2015/json/seoul_municipalities_geo_simple.json").json()- 지도 상으로 볼 때 전반적으로 서울시 중심부의 도심보다는 주변부에서 신재생 에너지 발전이 많이 이뤄지고 있음을 확인할 수 있음
fig = px.choropleth(df_seoul_gr, geojson = geojson_seoul, locations = df_seoul_gr.index, featureidkey='properties.SIG_KOR_NM',
color = "설비용량", facet_col = "에너지원", facet_col_wrap = 2, range_color= (0, 1000),
hover_data = ["설비용량"],color_continuous_scale = "thermal", title = "서울 자치구별 에너지원 설비용량")
fig.update_geos(fitbounds="locations", visible=True)
fig.update_xaxes(rangeslider_visible = True)
fig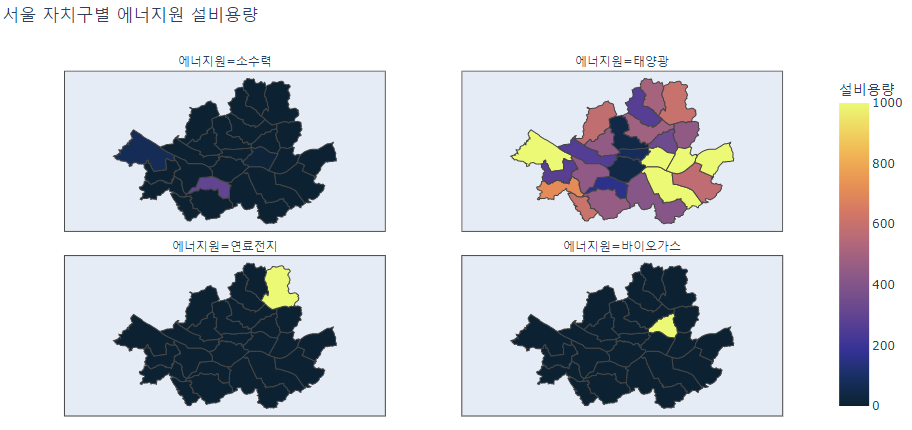
지역별 신·재생에너지 생산량(비재생폐기물 제외, 2019년 4/4분기~) 데이터
데이터 불러오기(공통)
- 다운로드 받은 csv 형식의 데이터 불러오기
df_common2 = pd.read_csv("data/지역별_신재생에너지_최종.csv", encoding = 'CP949') df_common2.shape(589, 22)
데이터 전처리
- 지역별 에너지원들의 소계만 뽑아놓은 데이터 프레임 만들기
- 필요없는 값들을 전부 드랍한다
energy_df = df_common2.copy() df_sogae=energy_df[df_common2['에너지원별(3)']=='소계'] df_sogae=df_sogae.drop(['에너지원별(3)','에너지원별(1)'], axis=1) df_sogae
- 소계 데이터프레임 전처리하기
df_sogae.groupby('에너지원별(2)')['에너지원별(2)'].count()# ① 재생에너지 합 ② 신에너지 합 이 두가지와 에너지원별(2) 의 소계 값 지우기 df_sogae=df_sogae[(df_sogae['에너지원별(2)'] != "① 재생에너지 합") & (df_sogae['에너지원별(2)'] != "② 신에너지 합") &(df_sogae['에너지원별(2)'] != "소계")]#컬럼 이름 바꾸기 에너지원별(2) --> 에너지원 df_sogae.rename(columns={'에너지원별(2)':"에너지원"}, inplace=True)#시점을 인덱스로 바꾸기 df_sogae.set_index('시점')#데이터 프레임 속 - 라는 값을 전부 0으로 치환 df_sogae=df_sogae.replace('-', 0) df_sogae#소계 데이터 프레임 속 값들의 타입을 str에서 int로 변환해주기 sogae_final= df_sogae.astype(dtype='int64',errors='ignore') sogae_final.info()시각화
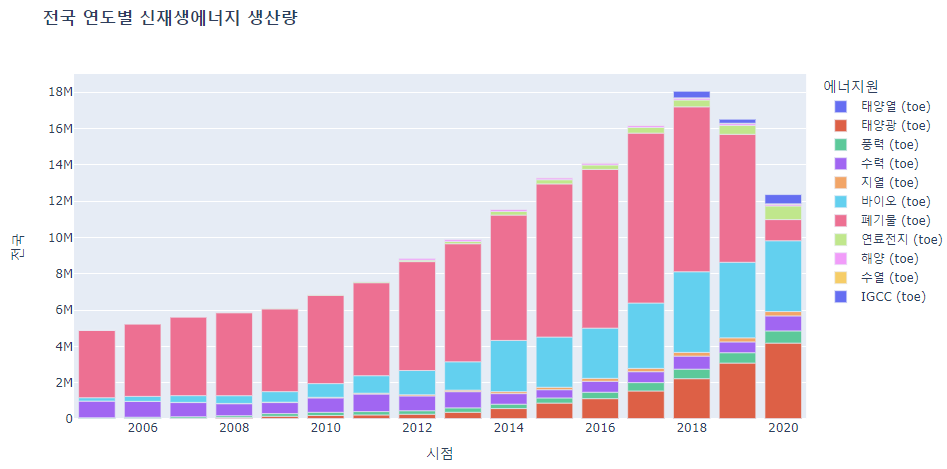
- 전국적으로 연도별로 신재생 에너지 생산량이 점점 늘어나는 추세가 나타남.
fig = px.bar(sogae_final,x='시점', y="전국",title='<b>전국 연도별 신재생에너지 생산량</b>',color='에너지원') fig.show()
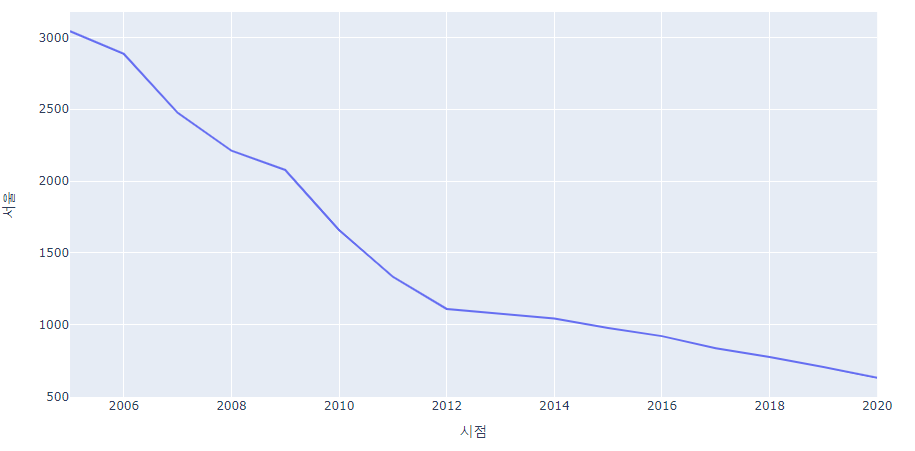
sun_energy_heat=sogae_final[sogae_final['에너지원']=='태양열 (toe)'] sun_energy_heat=sun_energy_heat.set_index('시점')
- 서울의 경우 태양열 발전의 경우 감소 추세가 나타남
px.line(sun_energy_heat, x = sun_energy_heat.index, y='서울')
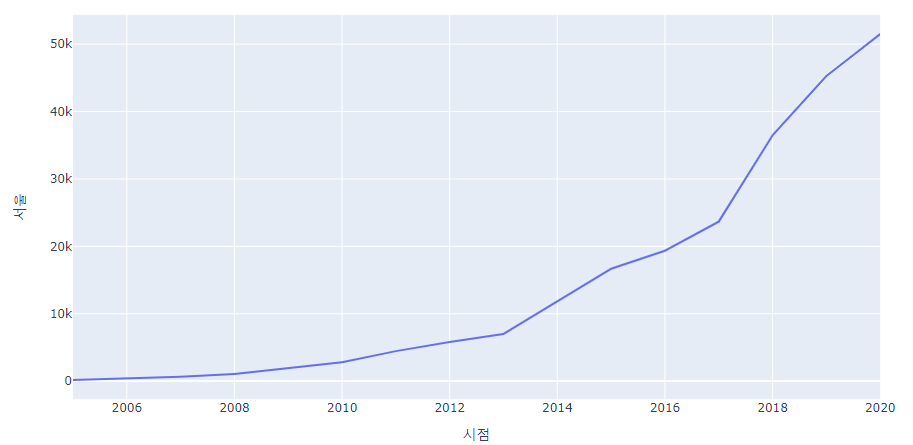
sun_energy_light=sogae_final[sogae_final['에너지원']=='태양광 (toe)'] sun_energy_light=sun_energy_light.set_index('시점')
- 반면 서울의 태양광 발전의 경우 증가 추세가 나타남
px.line(sun_energy_light, x = sun_energy_light.index, y='서울')
- 위의 두개의 그래프를 한번에 비교하기 위해 각가에 대해 min-max scaling 진행후 서울 태양광, 태양열 연도별 생산량 추세 비교
# 정규화 하기 def minmaxscaler(df): df=df.drop("에너지원", axis=1) x = df.values #numpy array 반환 min_max_scaler = preprocessing.MinMaxScaler() x_scaled = min_max_scaler.fit_transform(x) df = pd.DataFrame(x_scaled)
return df```python
# 서울의 태양열과 태양광의 정규화된 생산량만 모아놓은 데이터 프레임 만들기
df_heat_norm=minmaxscaler(sun_energy_heat)
df_light_norm=minmaxscaler(sun_energy_light)
df_final=pd.concat([df_heat_norm[0],df_light_norm[0]], axis=1)
df_final.columns=["태양열","태양광"]
fig = go.Figure()
fig.add_trace(go.Scatter(x=sun_energy_light.index,y=df_final['태양열'],
mode='lines+markers', name='태양광'))
fig.add_trace(go.Scatter(x=sun_energy_heat.index,y=df_final['태양광'],
mode='lines+markers', name='태양열'))
fig.update_layout(title='<b>서울 - 태양광, 태양열 추세 차이</b>')
fig.show()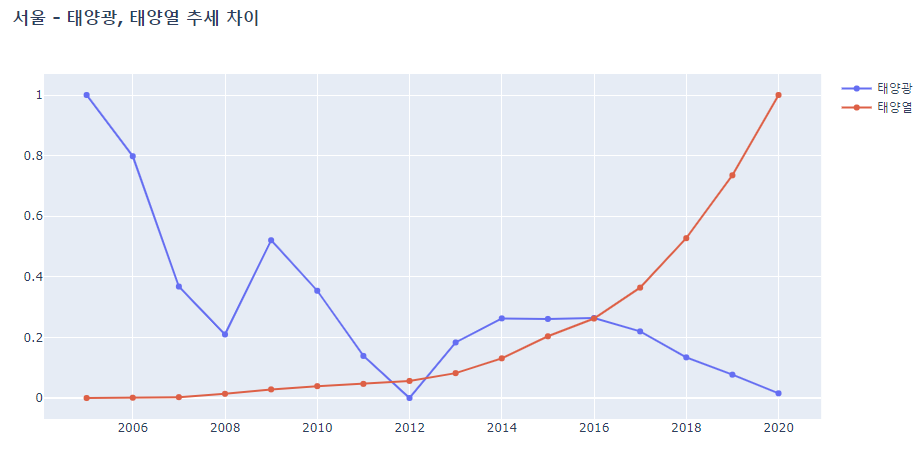
sogae_final=sogae_final.set_index('시점')
energy_year_mean=sogae_final.groupby('에너지원').mean()
energy_year_mean_all=energy_year_mean['전국']
energy_year_mean_all
- 전국적으로 폐기물과 바이오 발전량이 가장 많음
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 5}
plt.figure(figsize=(12,12))
plt.pie(energy_year_mean_all,normalize=True,labels=energy_year_mean_all.index,startangle=260, counterclock=False,wedgeprops=wedgeprops)
plt.show()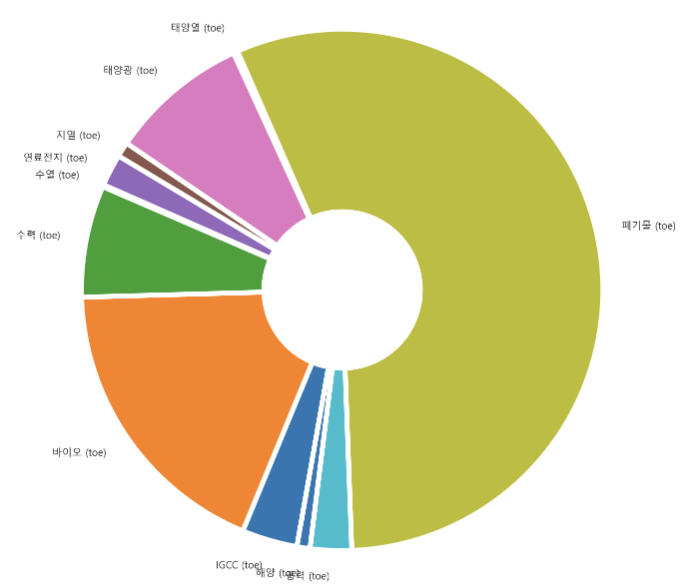
energy_year_mean_seoul=energy_year_mean['서울']
energy_year_mean_seoul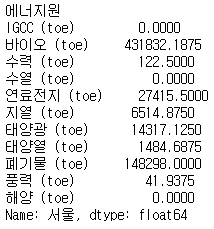
- 서울의 경우 폐기물과 바이오 발전에 더 의존하고 있음
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 5}
plt.figure(figsize=(12,12))
plt.pie(energy_year_mean_seoul,normalize=True,labels=energy_year_mean_seoul.index,startangle=260, counterclock=False,wedgeprops=wedgeprops)
plt.show()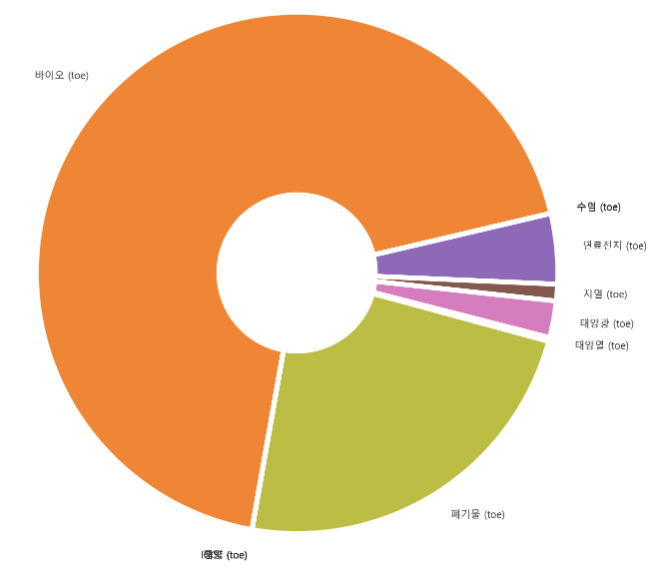
#전국은 랭킹에서 의미가 없으므로 드랍하기
df_for_rank=energy_year_mean.drop('전국',axis=1)
df_rank_final=df_for_rank.rank(axis=1)- 지역 및 에너지원 별 2005년부터 2020년까지 생산량의 평균 순위 확인
df_rank_final.style.background_gradient(cmap='brg',low=1, axis=0)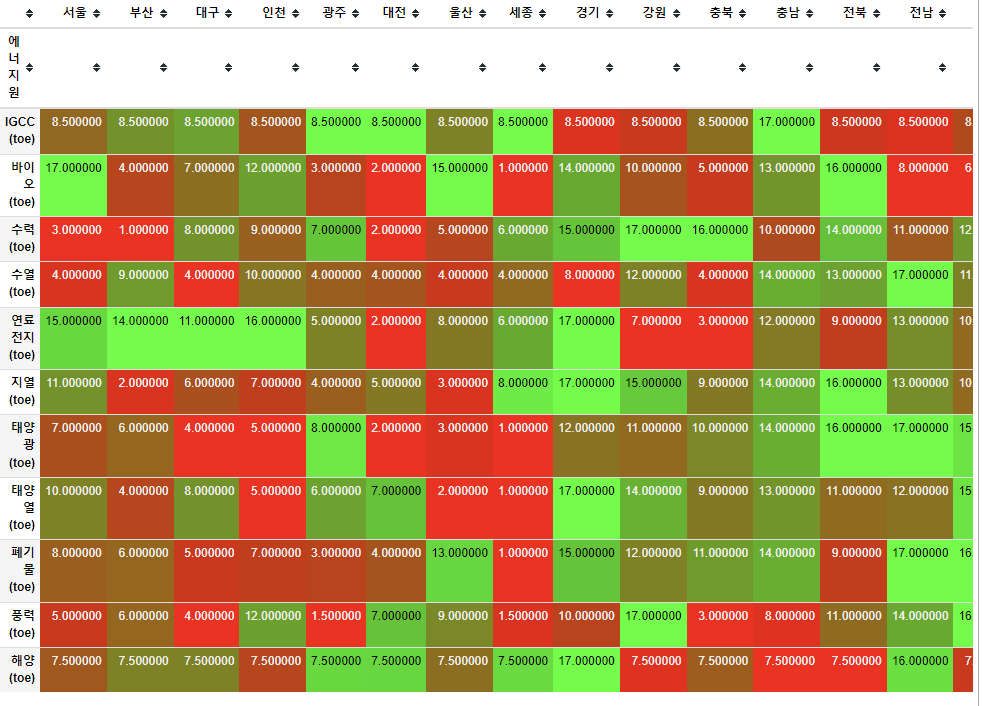
전국 시도별 신재생에너지 발전 총합
df_ntnl = df_common2.copy()
df_ntnl데이터 전처리
- 데이터 중 지역별 연도별 신재생 에너지 합계치만 추출
- 신재생 에너지 합계를 수치형으로 변경
- 결측치는 0으로 대체
df_ntnl_sum = df_ntnl[(df_ntnl["에너지원별(1)"] == "신·재생에너지 합계①+② (toe)") & (df_ntnl["에너지원별(2)"] == "소계")]
df_ntnl_sum.index = pd.to_datetime(df_ntnl_sum["시점"].astype(str)).dt.year
df_ntnl_sum = df_ntnl_sum.loc[:, "서울":]
df_ntnl_sum.replace('-', 0, inplace = True)
df_ntnl_sum = df_ntnl_sum.astype(int)
df_ntnl_sumchoropleth map에 표현한 지역 및 에너지원 별 설비용량
# https://github.com/southkorea/southkorea-maps
geojson_ntnl = requests.get("https://raw.githubusercontent.com/southkorea/southkorea-maps/master/kostat/2018/json/skorea-provinces-2018-geo.json").json()- 현재 데이터와 geojson 상의 시도명을 일치 시키기(예: "강원" -> "강원도")
# geojson 상의 시도명
sido_names_geo = [sido['properties']['name'] for sido in geojson_ntnl['features']]
sido_names_geo.sort()
sido_names_geo[5]# 데이터 상 시도명
sido_names = list(set(df_ntnl_sum.columns))
sido_names.sort()
sido_names[5]def change_sido_names(name):
return sido_names_geo[sido_names.index(name)]
change_sido_names('경기')df_ntnl_sum.columns = df_ntnl_sum.columns.map(change_sido_names)
df_ntnl_sum.head(2)- 데이터상 최초년도와 가장 최근년도의 신재생 에너지 합계를 비교하기 위해 데이터 재가공
df_part = df_ntnl_sum[(df_ntnl_sum.index.isin([2005, 2020]))]
df_part = pd.melt(df_part.reset_index(), id_vars = "시점", var_name = "지역", value_name="신재생 에너지 합계")
df_part.set_index("시점", inplace = True)- 지도를 살펴보면 2005년에 비해 2020년 신재생 에너지 생산량이 전국적으로 크게 상승하였음을 알 수 있음.
- 다만 서울과 5대 광역시의 경우 주변 지역에 비해 신재생 에너지 생산량이 크게 변하지 않았음.
fig = px.choropleth(df_part, geojson = geojson_ntnl, locations = "지역", featureidkey='properties.name',
range_color= (0, 1000000), color = "신재생 에너지 합계",
color_continuous_scale = "thermal", facet_col = df_part.index, facet_col_wrap = 1,
title = "시도별 신재생에너지 합계"
)
fig.update_geos(fitbounds="locations", visible=True)
fig.update_layout(margin=dict(l=60, r=60, t=50, b=50))
fig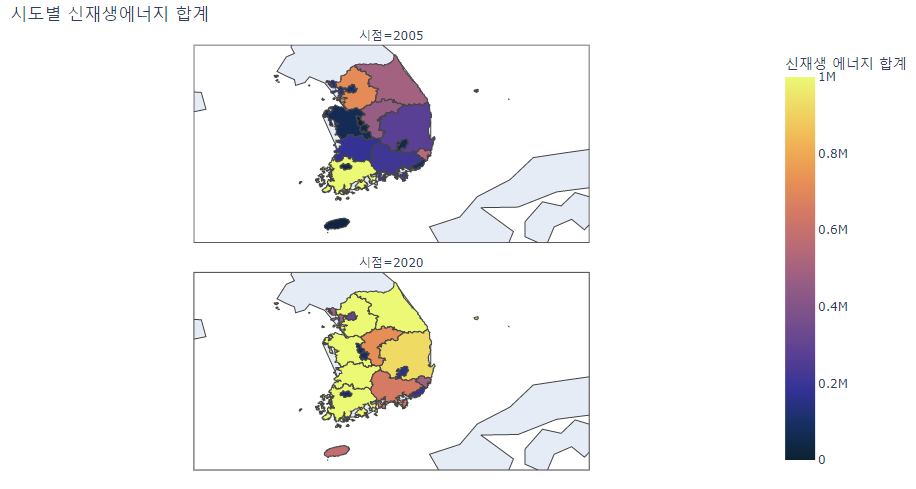
요약
서울의 경우
- 2013년을 기준으로 신재생 에너지 발전소 허가가 늘어났으며, 2013년에 사업을 개시한 발전소들이 평균적으로 가장 높은 설비용량을 보이고 있음
- 사업개시년도가 가장 높은 년도는 2014년도이며, 허가에서 사업개시까지 대략 1년 정도 소요되는 것으로 예상됨. - 신재생 에너지 생산은 광진구에서 최고, 종로구에서 최저를 보이며, 이는 광진구에 가장 많은 태양광 발전소가, 종로구에 가장 적은 태양광 발전소가 설치되어 있는 것과 관련이 있음. 지도상으로도 서울의 도심부보다 주변부에서 태양광 발전이 많이 이뤄지는 것을 확인할 수 있었음.
- 신재생 에너지 발전 비용에 지대가 영향을 미칠 가능성이 보이고, 토지 사용 목적(상업, 사무 혹은 주거)과도 관련이 있을 것으로 예상됨. - 첫번째 데이터에서는 신재생 에너지 설비용량의 약 98%에 해당하는 태양광이 가장 많은 비중을 차지하는 것으로 보이나, 두번째 데이터에서는 발전량 측면에서 바이오 발전에 더 의존하는 것으로 보임.
- 이는 단순히 첫번째 데이터에서 포함하고 있지 않은 에너지원들이 두번째 데이터에 포함되어 있기 때문일 수 있음.
- 태양광의 설비용량이 큼에도 실제 발전량이 바이오 보다 적음을 의미.
- 서울 전 지역적으로 설비가 갖추어져 있음에도, 시설이 집중되어 있는 바이오의 총 발전량이 더 높음.
- 정책(특정 신재생 에너지 지원)이나 환경(일조량)등 괴리를 설명할 변수가 요구됨. - 태양열 발전의 비중은 점점 줄어들고 있고, 태양광 발전의 비중은 점점 늘어나고 있음
- 각 발전 방식의 발전 단가(효율) 차이가 있을 것으로 예상
전국의 경우
- 전국적으로 연도별로 신재생 에너지 생산량이 점점 늘어나는 추세가 나타남.
- 전국적으로 폐기물과 바이오 발전량이 가장 많음
- 다만 서울과 5대 광역시의 경우 주변 지역에 비해 신재생 에너지 생산량이 크게 변하지 않았음.
- 높은 지대로 인해 도시 지역에서의 신재생 에너지 발전 단가가 주변 지역보다 높을 가능성이 있고, 인구에 비례하여 높은 전기 소요로 비신재생 발전(화력, 원자력)에 의존할 가능성이 높음.
미니 프로젝트를 진행하며 어려웠던 점
지역별 신·재생에너지 생산량(비재생폐기물 제외) 데이터셋을 받아서 주로 분석 및 시각화를 했는데, 데이터의 형태가 기존에 다룬 데이터셋과는 달라 전처리 하는 과정에서 많은 오류 사항이 있었다. 예를 들어 value 값 외 행의 인덱스로 쓰일 수 있을법한 변수가 총 세 칼럼이 존재했다. 전처리가 끝난 데이터셋을 보며 원하는 정보를 보여주기 위해 어떤 그래프를 쓰는 것이 가장 좋을지 고민이 많이 되었다.
미니 프로젝트를 통해 배운 내용과 의견
전처리의 중요성에 대해서 배울 수 있었다. 어떻게 전처리를 하느냐에 따라서 일의 속도가 확연히 달라질 수 있다는 것을 알게 되었다. 사람마다 바라보는 시각에 따라 같은 데이터에서도 서로 다른 아웃풋을 도출해낼 수 있다는 점이 흥미로웠다. 또한 내가 직접 찾은 데이터셋으로 나만의 해석을 해볼 수 있다는 것 또한 매력적인 프로젝트였다고 느껴졌다.
