공부하는 Velog이니 참고용으로만 사용해주시고 틀린 개념이 있다면 알려주시기 바랍니다!
오늘은 배치 정규화에 대해 공부해보려고 한다. 딥러닝의 기본중 기본이라고 한다..
특히 CNN에서 최근 모델들은 배치 정규화를 사용한다고 한다.
📚 Batch Normalization(배치 정규화)
배치 정규화의 개념은 2015년에 아래 논문에서 나온 개념이다.
https://arxiv.org/pdf/1502.03167.pdf
모델을 학습시에 정규화를 시키는 이유는 학습시간을 줄이는 용도, Local optimum에 빠지는 가능성을 줄이기 위해서다.
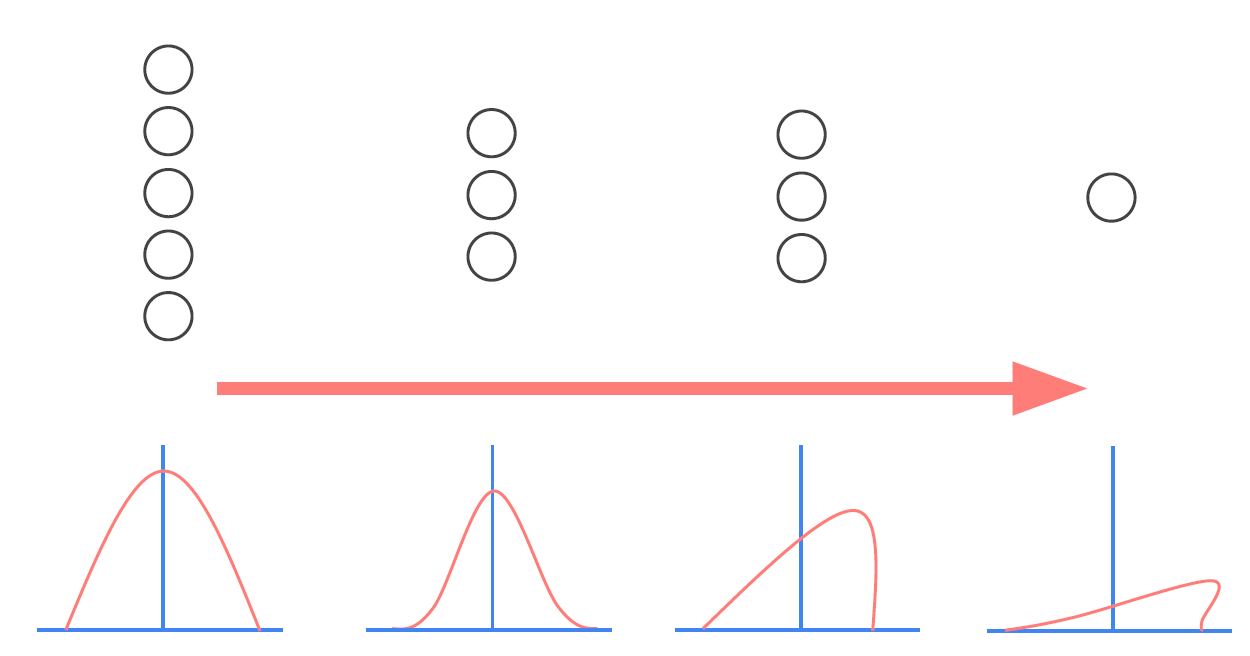
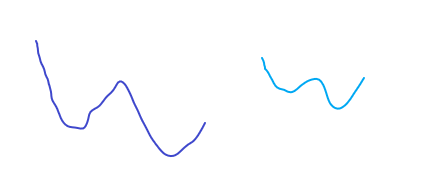
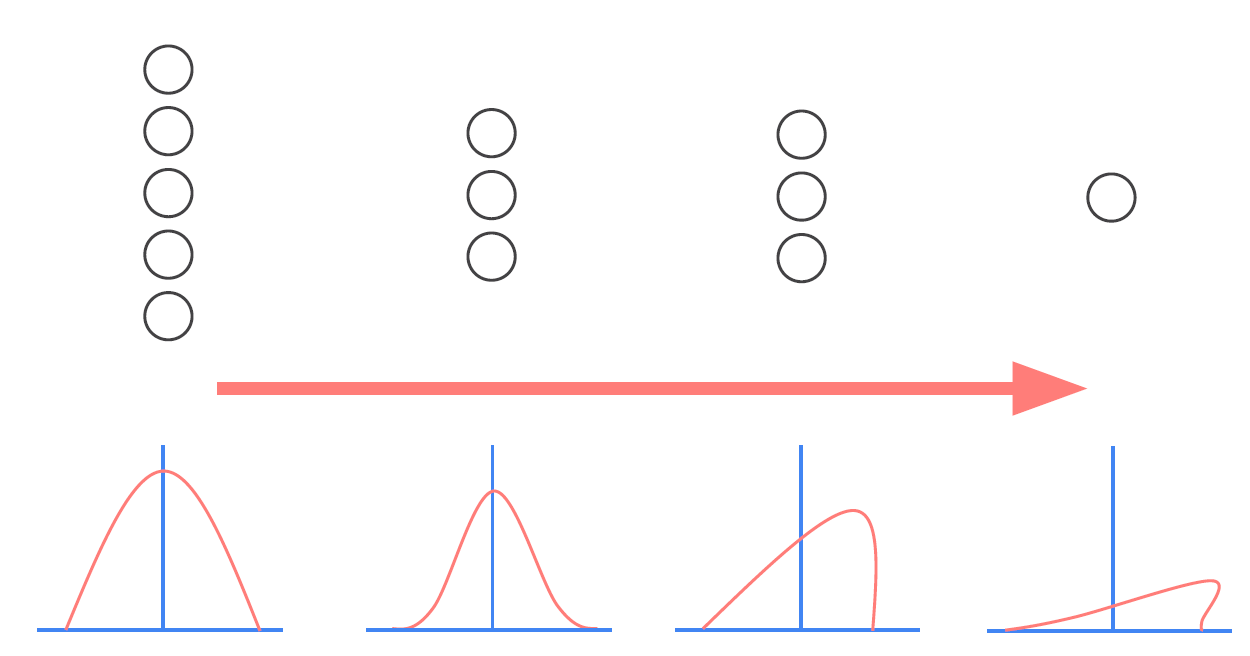
아래에서 왼쪽은 정규화를 시키기 이전이고, 오른쪽은 정규화를 시킨 후이다.
✅ Internal Covariance Shift
Internal Covariance Shift란 Input데이터가 Model의 layer를 통과하면서 분산이 달라지는 것을 뜻한다. layer를 지나갈수록 데이터가 왜곡된다는 의미다.
Input 데이터 x1이 들어왔을 때 가중치 w1을 곱하면 x1w1이 된다. 이 Output은 다음 layer의 Input이 되고 (x1w1)*w2가 된다. Activation Function은 없다고 가정하겠다. 그럼 w1이 변경되면 이후의 layer에도 영향이 있게된다.
이처럼 w1값이 너무 많이 수정되면 분포가 달라지게 된다.
우리는 training dataset을 이용해 학습한 Model을 통해 test dataset을 예측하고 싶어한다. 하지만 training dataset을 이용해 학습할 때 분포가 test dataset과 달라지면 좋은 결과를 낼 수 없다. 흔히 말하는 Overfitting이 발생하게 된다.
✅ Internal Covariance Shift 해결방법
그럼 Internal Covariance Shift를 어떻게 해결할 수 있을까?
위에서 그려진 왜곡된 분포를 다시 원래 형태로 바꿔주면 된다. 분포의 위치와 크기를 바꿔주면 된다. 바로 이 '분포의 위치와 크기를 바꿔주는 작업'이 배치 정규화(Batch Normalization)다.
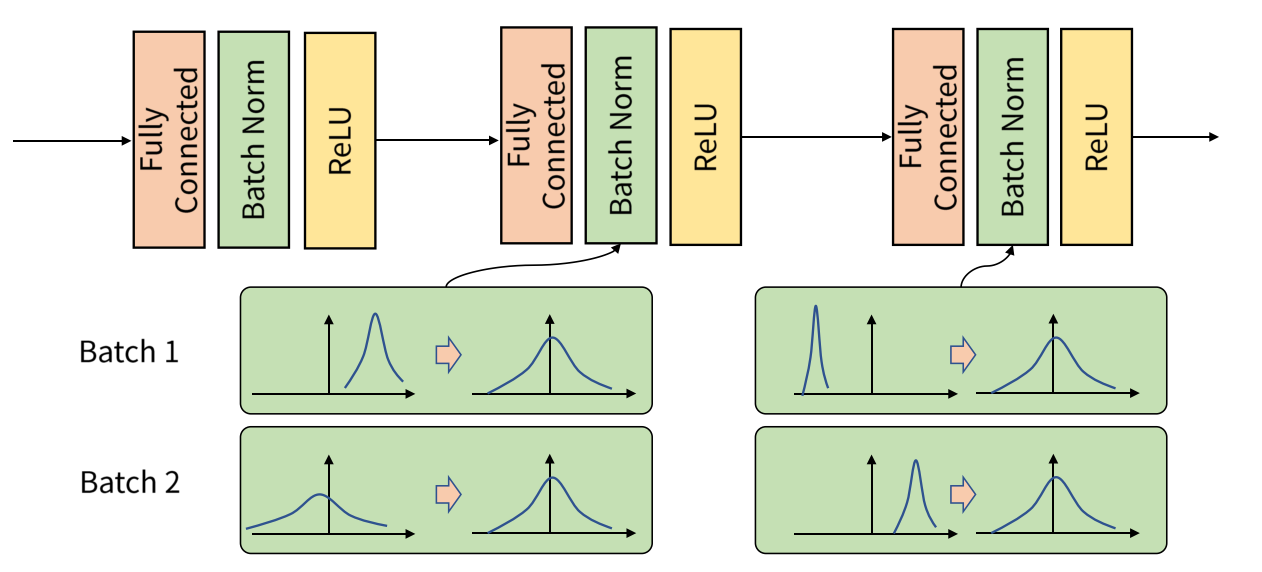
배치 정규화는 아래와 같은 공식으로 이루어진다.
배치 정규화는 Output으로 나온 미니 배치의 평균과 분산을 이용해서 정규화한 뒤에 scale과 shift를 감마(γ) 값, 베타(β)값을 통해 실행한다.
이때 감마(γ) 값, 베타(β)값은 학습 가능한 변수다. 즉, Backpropagation을 통해 학습이 된다.

✅ Batch Normalization 순서
그럼 배치 정규화는 Model에서 어떤 순서로 들어갈까?
CNN기준으로 설명하자면 Conv2D layer에서 Activation layer를 바로 통과시키지 말고 Conv2D -> Batch Normalizatin -> Activation layer 순서라고 보면 된다.(Framework는 keras다)
텐서플로우로 Batch Normalization을 표현하면 다음과 같다.
from tensorflow.keras.layers import Input, Conv2D, Activation, BatchNormalization
from tensorflow.keras.models import Model
input_tensor = Input(shape=(32, 32, 3))
x = Conv2D(filters=32, kernel_size=(3, 3), padding='same')(input_tensor)
x = Activation('relu')(x)
output = BatchNormalization()(x) # Batch Normalization(배치 정규화)
model = Model(inputs=input_tensor, outputs=output)
model.summary()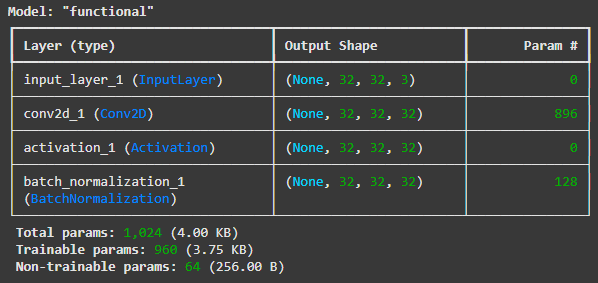
✅ 정리
- Batch Normalization은 Overfitting 문제점을 해결하려고 만들어낸 기법이다.
- Overfitting중에서도 Internal Covariance Shift를 해결하기 위한 기법이다.
- 최근 대부분의 CNN Model은 Batch Normalization 기법을 사용한다.
- Batch Normalization은 CNN기준 일반적으로 Conv2D -> Batch Normalization -> Activation 순서로 사용한다.
📜 Reference
[Deep Learning] Batch Normalization (배치 정규화)
10. Batch Normalization (배치 정규화)
Batch Normalization
