
오늘은 텍스트 분석에 대해 공부하려고 합니다.
텍스트 분석 분야는 솔직히 저도 잘 모르는 분야입니다.(저는 컴퓨터 비전을 집중적으로 공부합니다.😊)
최선을 다해 공부해봤습니다.
📚 NLP vs Text Analytics
우선 텍스트 분석에 대해 공부하기 전에 NLP(National Language Processing)와 차이점에 대해서 알아보겠습니다.
사실 머신러닝이 보편화되면서 이 둘을 구분하는게 의미가 없어지긴 했습니다.
✅ NLP(National Language Processing)
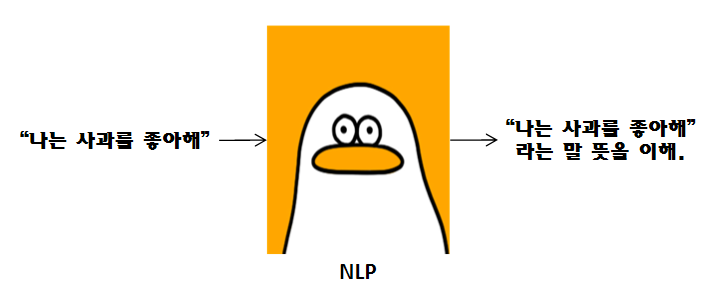
NLP는 인간의 언어를 이해하고 해석하는 데 중점을 두고 기술이 발전했습니다.
예를들어, "나는 사과를 좋아해."라는 문장이 있으면 그 자체의 문장을 이해하고 해석하는 것입니다.
✅ Text Analytics(텍스트 분석)
텍스트 분석은 Text Mining(텍스트 마이닝)이라는 표현이 더 잘 어울립니다.
텍스트 분석은 비정형 텍스트에서 의미 있는 정보를 추출하는 것에 더 중점을 두고 발전했습니다.
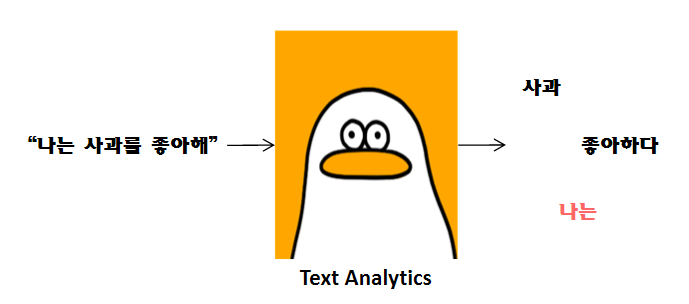
텍스트 분석은 머신러닝, 언어 이해, 통계 등을 활용해 모델을 수립하고 정보를 추출해 Business Intelligence(비즈니스 인텔리전스)나 예측 분석 등의 분석 작업을 주로 수행합니다.
텍스트 분석은 다음과 같은 기술에 집중해왔습니다.
- Text Classification(텍스트 분류)
- Sentiment Analysis(감성 분석)
- Summarization(텍스트 요약)
- Clustering(텍스트 군집화)
- Text Similarity(유사도 측정)
요약하자면, NLP의 발전에 따라 텍스트 분석 기술도 발전했습니다.
언어 분석의 기반이 되는 언어 이해가 발전하기 때문입니다.
또한, 현재 머신러닝이 발전한 시대에서 NLP와 텍스트 분석을 구분하는 것은 의미가 없습니다.
📚 Text Preprocessing
분류나 회귀, 혹은 이외의 모델을 작동시킬 때, 모델에 데이터를 넣어주면 모델은 비지도 학습이나 지도 학습의 알고리즘대로 학습합니다.
마찬가지로, 텍스트 분석에서 모델에 입력되는 데이터를 만들어줘야 합니다.
실제 문서나 문장을 그대로 넣을 수 없기 때문에 우리는 이런 데이터를 정제해줘야 합니다.
이를 Text Preprocessing(텍스트 전처리)한다고 합니다.
✅ Cleansing(클렌징)
텍스트 전처리에서 클렌징 기법은 feature selection이라고 생각해도 됩니다.
모델에 데이터를 입력하기 전에 불필요한 문자 데이터를 제거해 줍니다.
예를들어, HTML/XML 태그, 기호가 있습니다.
✅ Text Tokenization(텍스트 토큰화)
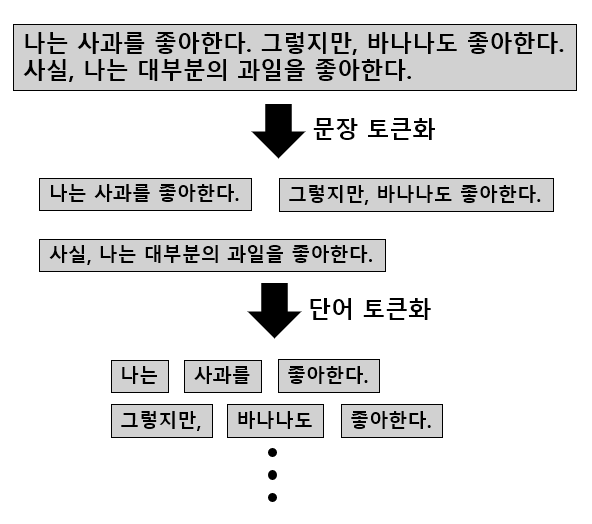
텍스트 토큰화는 텍스트를 덩어리로 단위화(토큰화) 시키는 과정입니다.
텍스트 토큰화는 문단에서 문장 단위로 나누는 문장 토큰화, 문장에서 단어 단위로 나누는 단어 토큰화가 있습니다.
nltk 툴을 사용하면 다음처럼 코드를 작성할 수 있습니다.
from nltk import sent_tokenize
import nltk
# 개행문자 다운로드
nltk.download('punkt_tab')
text_sample = 'The Matrix is everywhere its all around us, here even in this room. \
You can see it out your window or on your television. \
You feel it when you go to work, or go to church or pay your taxes.'
# 문장 토큰화
sentences = sent_tokenize(text=text_sample)
print(type(sentences), len(sentences))
print(sentences)
from nltk import word_tokenize
sample = 'The Matrix is everywhere its all around us, here even in this room.'
# 단어 토큰화
words = word_tokenize(sample)
print(type(words), len(words))
print(words)
✅ Stop Word(스톱 워드) 제거
스톱 워드는 문장에서 별 의미가 없는 단어를 의미합니다.
예를 들어, the, a, an, is, I, my 등과 같이 문장에서는 꼭 필요한 요소지만 문맥적으로 큰 의미가 없는 단어가 있습니다.
이런 단어들을 제거하는 이유는 문법적인 특성으로 인해 텍스트에 빈번하게 나타나므로 이것들을 사전에 제거하지 않으면 오히려 중요한 단어로 인식할 수 있습니다.
다음은 텍스트 토큰화와 스톱워드를 이용해 텍스트 전처리를 하는 코드입니다.
import nltk
nltk.download('stopwords')
# 토큰화와 스톱 워드 제거하는 함수.
stop_words = nltk.corpus.stopwords.words('english')
def text_preprocess(text_sample):
sentences = sent_tokenize(text=text_sample)
new_sentences = []
for sentence in sentences:
words = word_tokenize(sentence)
new_words = []
for word in words:
if word not in stop_words:
new_words.append(word)
new_sentences.append(new_words)
return new_sentences
text_preprocess(text_sample)
결과를 보면 알겠지만, 스톱 워드에 포함된 단어는 제거되었음을 알 수 있습니다.
✅ Stemming / Lemmatization
Stemming과 Lemmatization은 문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것입니다.
두 기능 모두 원형 단어를 찾는다는 목적은 유사하지만, 일반적으로 Lemmatization이 Stemming보다 성능이 뛰어납니다.
Stemming은 원형 단어로 변환 시 상대적으로 단순화된 방식을 이용합니다.
그에 반해, Lemmatization은 단어의 품사와 같은 문법적인 요소와 더 의미적인 부분을 감안합니다. 따라서 Lemmatization이 일반적으로 성능이 좋습니다.
하지만, Lemmatization이 변환에 더 오랜 시간이 걸립니다.
from nltk.stem import LancasterStemmer
# Stemming 방식을 이용해서 amuse 원형 찾기
stemmer = LancasterStemmer()
print(stemmer.stem('amusing'))
print(stemmer.stem('amused'))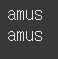
from nltk.stem import WordNetLemmatizer
import nltk
nltk.download('wordnet')
lemma = WordNetLemmatizer()
print(lemma.lemmatize('amusing', 'v'))
print(lemma.lemmatize('amused', 'v'))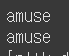
보시는 바와 같이 Lemmatization방식이 더 좋은 성능을 냄을 알 수 있습니다.
Lemmatization은 문법적인 요소도 같이 고려하기 때문에 인자로 (단어, 품사)가 들어갑니다.
품사는 다음과 같이 나뉩니다.
- n : nouns(명사)
- v : verbs(동사)
- a : adjectives(형용사)
- r : adverbs(부사)
- s : satellite adjectives(?)
satellite adjectives가 무엇을 의미하는 지는 잘 모르겠습니다.(영어를 잘 못해서..)
추측하기로는 인공적으로 만든 형용사(?) 느낌일 것 같은데 Document에도 별다른 설명이 없네요.. 아시는 분 있으시면 댓글 남겨주시면 감사하겠습니다.😊
📜 Reference
