오늘은 추천 시스템에 대해 공부하려고 합니다.
아마 이번 장에서는 다른 장과는 다르게 코드가 많이 나올텐데, 개념만 공부하고 싶으시면 코드 부분은 설명만 읽어도 무방합니다. 코드는 제가 나중에 다시 공부할 때, 읽어보려고 올려둔 것입니다.
📚 Recommendations
추천 시스템은 우리의 삶에 깊이 스며들어 있습니다.
예를 들어, 넷플릭스, 유튜브, 아마존 등 대부분의 회사는 추천 시스템을 사용합니다.
추천 시스템을 사용하면 사용자들에게 만족감을 줄 수 있으며, 자사 시스템에 묶어두는 역할을 하기 때문입니다.
또한, 좋은 추천 시스템은 회사 매출이 올라가는 선순환이 이루어지게 합니다.
추천 시스템의 묘미는 사용자 자신도 좋아하는지 몰랐던 취향을 시스템이 발견하고 그에 맞는 콘텐츠를 추천해주는 것입니다.
추천 시스템은 크게 Content based Filtering(콘텐츠 기반 필터링) 방식과 Collaborative Filtering(협업 필터링) 방식으로 나뉩니다.
협업 필터링 방식은 다시 Nearest Neighbor(최근접 이웃) 협업 필터링과 Latent Factor(잠재 요인) 협업 필터링으로 나뉩니다.
✅ Content based Filtering (콘텐츠 기반 필터링)
콘텐츠 기반 필터링 방식은 사용자가 특정한 아이템을 매우 선호하는 경우, 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천하는 방식입니다.
예를 들어, 사용자가 액션 영화에 높은 평점을 주면 액션, 영화 감독의 성향, 배우 등에서 비슷한 콘텐츠 유사도를 판단 후 비슷한 아이템을 추천하는 방식입니다.
아래는 콘텐츠 기반 필터링 실습 코드입니다.
책에서와 마찬가지로 장르 속성을 기반으로 진행합니다.
데이터는 여기에서 구하실 수 있습니다.
데이터는 아래처럼 장르와 키워드 컬럼이 있습니다.

literal_eval API를 이용해서 다음과 같이 장르와 키워드를 분리해 주었습니다.
from ast import literal_eval
import pandas as pd
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
movies_df['genres'] = movies_df['genres'].apply(lambda x: [y['name'] for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x: [y['name'] for y in x])
movies_df[['genres', 'keywords']][:1]
이렇게 리스트 형태로 만들어진 데이터를 공백으로 다시 분리해주고, CountVectorizer를 적용해주었습니다. 그 후 영화들마다 유사도를 측정하기 위해 코사인 유사도를 적용했습니다.
CountVectorizer에 대해 궁금하시다면 [ML] BOW Feature Vectorization를 참고해주세요.
코사인 유사도를 적용하면 모든 영화에 대한 유사도가 행렬 값으로 반환됩니다.(1일수록 유사합니다.)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x: ' '.join(x))
count_vect = CountVectorizer(min_df=1, ngram_range=(1, 2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
genre_sim = cosine_similarity(genre_mat, genre_mat)
print(genre_sim.shape)
print(genre_sim[:2])
이제 이렇게 만들어진 코사인 유사도 행렬을 기준으로 정렬합니다.
원하는 제목을 인자로 넣어주고, 원하는 개수를 넣어주면 데이터가 나오게 되는 함수를 구현했습니다.
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, top_n]
print(similar_indexes)
similar_indexes = similar_indexes.reshape(-1)
return df.iloc[similar_indexes]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather', 10)
similar_movies[['title', 'vote_average']]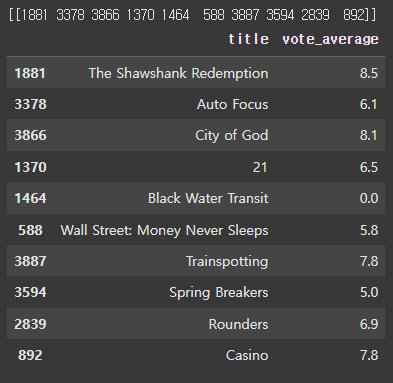
이렇게 만들어진 결과는 The Godfather이라는 영화와 The Shawshank Redemption, Auto Focus, ... 순으로 유사도가 있음을 알려줍니다.
그렇다면, 이것이 과연 최고의 결과일까요?
우리가 활용하고 있는 데이터를 살펴보면 다음처럼 많은 사람들이 평가한 영화가 있는 반면, 소수의 인원만 평가한 영화가 있습니다.
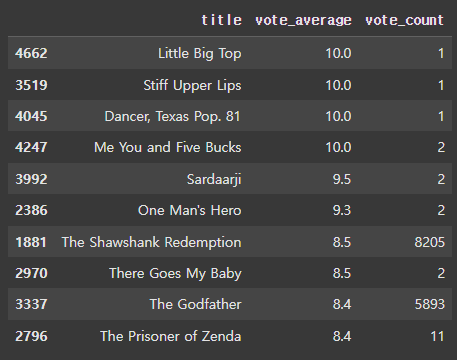
당연히, 평가한 인원이 많은 영화의 vote_average가 더 신뢰성이 있을 겁니다.
✔ Weighted Rating (가중 평점)
이런 신뢰성을 표현하기 위해 가중 평점 방식을 사용합니다.
(여기서 말하는 가중 평점은 IMDB 영화 평점 사이트에서 사용하는 방식을 말합니다.)
가중 평점의 공식은 다음과 같습니다.

여기서 최소 투표 수(m)은 상황에 따라 다릅니다.
우리가 사용하고 있는 데이터에 적용하면 다음과 같습니다.
percentile = 0.6
m = movies_df['vote_count'].quantile(percentile)
C = movies_df['vote_average'].mean()
def weighted_vote_average(record):
v = record['vote_count']
R = record['vote_average']
return ( (v/(v+m)) * R ) + ( (m/(m+v)) * C )
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)
movies_df[['title','vote_average','weighted_vote','vote_count']].sort_values('weighted_vote', ascending=False)[:10]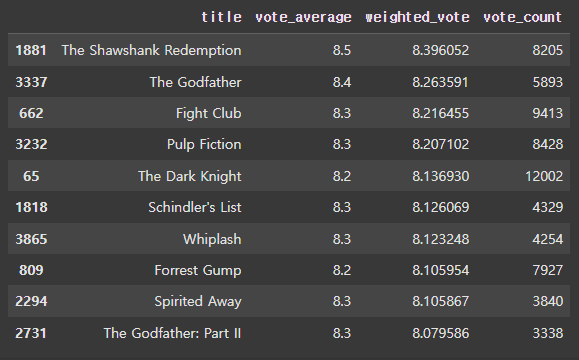
이를 토대로 다시 유사도를 표현하면 다음과 같습니다.
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n*2)]
similar_indexes = similar_indexes.reshape(-1)
similar_indexes = similar_indexes[similar_indexes != title_index]
return df.iloc[similar_indexes].sort_values('weighted_vote', ascending=False)[:top_n]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather',10)
similar_movies[['title', 'vote_average', 'weighted_vote']]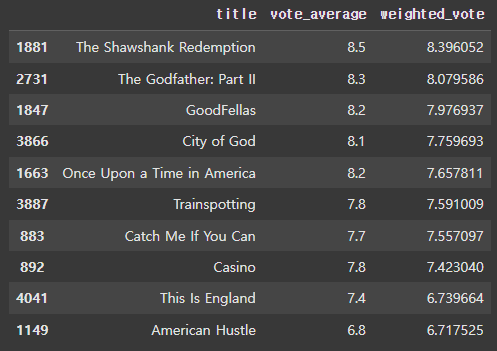
위 예제를 예로 들어 설명하자면, 콘텐츠의 장르로 영화들간의 유사도를 측정할 수 있었습니다. 또한, 유사도가 높은 것들 중에 가중 평점이 높은 순으로 재배열 해서 사용자에게 어울리는 영화를 추천해줄 수 있습니다.
✅ Collaborative Filtering (협업 필터링)
영화를 보기 전 취향이 비슷한 친구에게 해당 영화에 어땠는지 물어보는 것처럼, 사용자가 아이템에 매긴 평점 정보나 상품 구매 이력과 같은 사용자 행동 양식만을 기반으로 추천을 수행하는 것이 협업 필터링 방식입니다.
협업 필터링의 주요 목표는 사용자-아이템 평점 매트릭스와 같은 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가하는 것입니다.
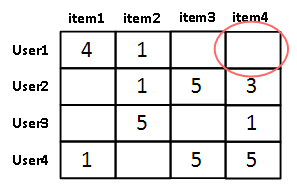
여기서는 영화에 대한 사용자들의 평점을 사용자 행동 데이터로 정의하겠습니다.
협업 필터링 방식을 이용하기 위해서는 사용자 행동 데이터를 가지고 있어야 합니다.
하지만, 대부분의 데이터는 레코드 레벨로 되어있으므로 판다스의 pivot_table() API를 이용해 변환해줘야 합니다.
user_item_df = row_df.pivot_table(values='Rating', index='UserID', columns='ItemID')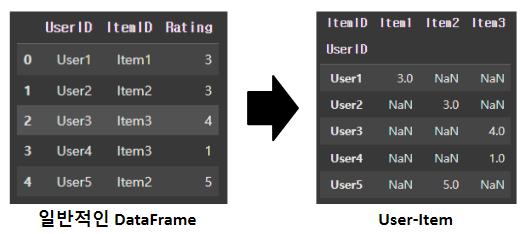
이렇게 변환된 데이터는 희소 행렬 특성을 가지고 있습니다.
협업 필터링 기반의 추천 시스템은 최근접 이웃 방식과 잠재 요인 방식으로 나뉩니다.
✔ 최근접 이웃 협업 필터링
최근접 이웃 협업 필터링은 다시 사용자 기반과 아이템 기반으로 나뉠 수 있습니다.
User-User(사용자 기반)
사용자 기반 최근접 이웃 협업 방식은 특정 사용자와 유사한 다른 사용자를 Top-N으로 설정해 다른 사용자가 좋아하는 아이템을 추천하는 방식입니다.
즉, 사용자들간의 유사도를 측정한 다음, 그들이 선호하는 아이템을 추천하는 것입니다.
Item-Item(아이템 기반)
아이템 기반 최근접 이웃 협업 방식은 아이템이 가지는 속성과는 상관없이 사용자들이 그 아이템을 좋아하는지/싫어하는지의 평가 척도가 유사한 아이템을 추천하는 기준이 되는 알고리즘입니다.
즉, 사용자들의 평가를 기준으로 아이템들간의 유사도를 측정합니다.
특정 사용자가 평점을 높게 준 아이템과 유사한 분포도를 가지는 아이템을 추천하게 됩니다.
따라서 사용자 기반이냐, 아이템 기반이냐에 따라 데이터를 transpose해서 생각하는 것이 편합니다.
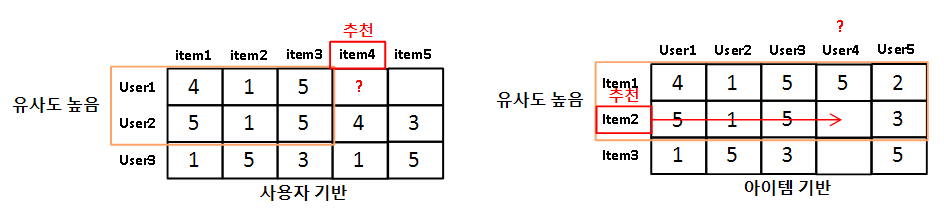
최근접 이웃 필터링을 적용할 때, 대부분 아이템 기반의 알고리즘을 적용합니다.
✔ 잠재 요인 협업 필터링
잠재 요인 협업 필터링은 사용자-아이템 평점 매트릭스 속에 숨어 있는 잠재 요인을 추출해 추천 예측을 할 수 있게 하는 기법입니다.
잠재 요인 협업 필터링의 주요 원리는 다차원 희소 행렬을 저차원 밀집 행렬 두개로 나누는 행렬 분해 입니다. 행렬 분해에 대해서는 여기에서 자세하게 설명했습니다.
일반적으로 행렬 분해는 SVD 방식을 많이 사용합니다.
즉, 다차원 희소 행렬을 행렬 분해함으로써 잠재 요인을 도출합니다.
행렬 분해에 의해 추출되는 '잠재 요인'이 정확히 어떤 것인지는 알 수 없습니다.
하지만, 직관적으로 이해해 볼 수는 있습니다.
사용자-아이템 매트릭스에서 아이템을 영화라고 가정하겠습니다.
그러면 여기서 행렬 분해를 통해 만들어진 '잠재 요소'를 '영화 장르'라고 생각해보겠습니다.
이때, M x N이던 원본 행렬이 M x L과 L x N으로 행렬 분해가 됩니다.
행렬 분해로 만들어진 첫 번째 행렬은 사용자-장르 행렬이며, 두 번째 행렬은 장르-아이템 행렬이 됩니다. 사용자-장르 행렬은 각 사용자가 선호하는 장르가 나타나며, 장르-아이템 행렬은 아이템(여기서는 영화)의 장르가 어디에 더 속해있는 지를 나타내는 지표가 된다고 이해할 수 있습니다.
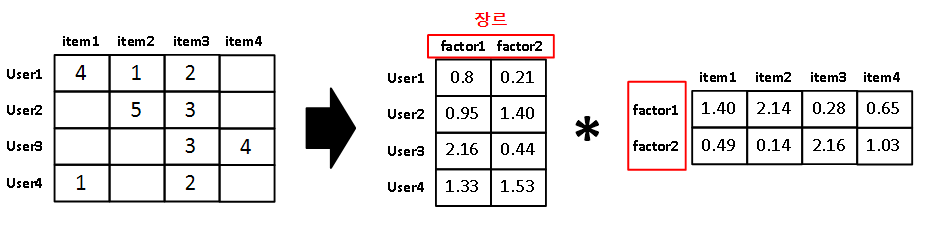
위 그림에서도 알 수 있듯이 원본 행렬에서 채워지지 않은 값들은 행렬 분해를 통해 얻은 행렬의 내적 곱을 이용해 구할 수 있습니다.
원본 행렬을 R, 행렬 분해를 통해 얻어진 행렬을 각각 P, Q라고 한다면 복원된 원본 행렬 R'=P*Q입니다.(책에서는 R'=P*Q.T로 나와있지만, Q를 왜 트랜스포즈 하는지 이해할 수 없었습니다. 애초에 행렬 분해를 진행하면 M x N = (M x K) * (K x N) 형식으로 나오는데 말이죠. 혹시라도 제가 틀렸다면 알려주시면 감사하겠습니다!)
즉, R' 행렬의 u행 사용자와 i열 아이템 위치에 있는 평점 데이터를 r(u,i), P행렬에서 u행 사용자의 벡터를 Pu, Q행렬에서 i행 벡터를 Qi라고 한다면, 새로 만들어지는 각 요소의 식은 다음과 같습니다.
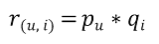
앞에서도 언급했듯이 대부분의 행렬 분해는 SVD 방식을 이용합니다.
하지만, SVD는 원본 행렬에 NULL값이 없어야 합니다.
따라서 원본 행렬에 NULL값이 존재하는 경우 SGD(확률적 경사 하강법)를 활용해서 SVD방식을 수행합니다.
경사 하강법에 대해서는 앞에서 공부했습니다. [[ML] 회귀와 Gradient Descent(경사 하강법)]
협업 필터링에 관해서는 소스코드를 작성하지 않았습니다. 공부를 하면서 작성하긴 했으나.. 여기에 적기에는 너무 더러웠습니다. 아래 제가 공부한 소스코드 링크를 넣어놓겠습니다.
📜 Reference
[개정판] 파이썬 머신러닝 완벽 가이드
09-10. 피벗생성_스프레드시트 기반 (pivot_table)
9.6 아이템 기반 인접 이웃 협업 필터링 실습.ipynb
9.7 행렬 분해 기반의 잠재 요인 협업 필터링 실습.ipynb
