오늘은 클러스터링 알고리즘 중에서도 GMM(Gaussian Mixture Model)과 DBSCAN에 대해 공부하려고 합니다.
사실 기존 Clustering1에서 여기까지 내용을 다루려고 했지만, 너무 루즈해질 것 같아서 이렇게 나누게 되었습니다.😊
📚 GMM(Gaussian Mixture Model)
GMM 군집화는 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정하에 군집화를 수행하는 방식입니다.
가우시안 분포란, 좌우 대칭형의 종 모양으로 생긴 연속 확률 함수입니다.
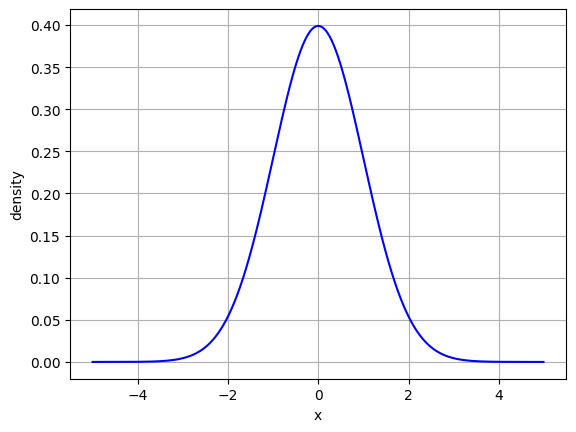
GMM은 데이터가 여러개의 가우시안 분포가 섞인 것으로 간주합니다.
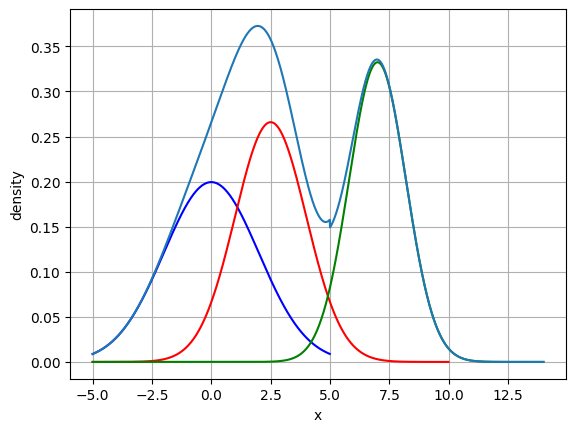
즉, 전체 데이터셋은 서로 다른 정규 분포 형태를 가진 여러가지 확률 분포 곡선으로 구성될 수 있습니다. 이렇게 만들어진 정규 분포에 속하는 데이터를 나누는 것이 GMM의 원리입니다.
이런 방식은 GMM에서 모수 추정이라고 합니다.
모수 추정의 목적은 대표적으로 다음 두 가지 입니다.
- 개별 정규 분포의 평균과 분산
- 각 데이터가 어떤 정규 분포에 해당되는지의 확률
✅ GaussianMixture Class
사이킷런에서는 EM 방식을 통한 GMM을 지원하기 위해 GaussianMixture 클래스를 지원합니다.
K-Means는 거리 기반 알고리즘이며, GMM은 확률 기반 알고리즘이기 때문에 이 두개의 방법을 비교해 보겠습니다.
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris_data = load_iris()
features = iris_data.data
targets = iris_data.target
iris_df = pd.DataFrame(data=features, columns = ['ftr1', 'ftr2', 'ftr3', 'ftr4'])
iris_df['target'] = targets
# KMeans와 GMM 비교하기 위해 두 모델 모두 적용해봄.
kmeans = KMeans(n_clusters=3)
kmeans.fit(features)
gmm = GaussianMixture(n_components=3, random_state=0)
gmm.fit(features)
iris_df['gmm_cluster'] = gmm.predict(features)
iris_df['kmeans_cluster'] = kmeans.predict(features)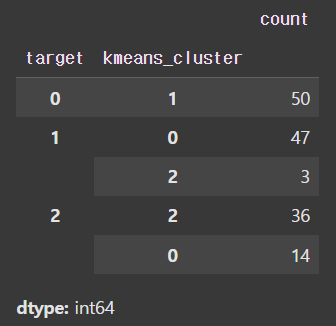
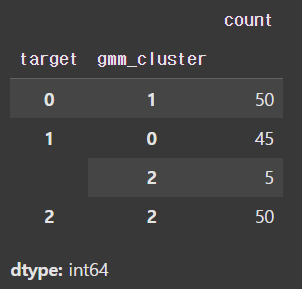
붓꽃 데이터의 경우 GMM이 KMeans보다 좋은 성능을 냈음을 알 수 있습니다.
✅ K-Means vs GMM
거리 기반 알고리즘 K-Means와 확률 기반 GMM의 차이에 대해 살펴보겠습니다.
K-Means 알고리즘은 데이터가 원형으로 군집화 되어있을 때, 좋은 성능을 냅니다.
하지만, 데이터가 원형이 아닌 다른 분포로 되어있을 때, 성능이 안 좋아질 수 있습니다.
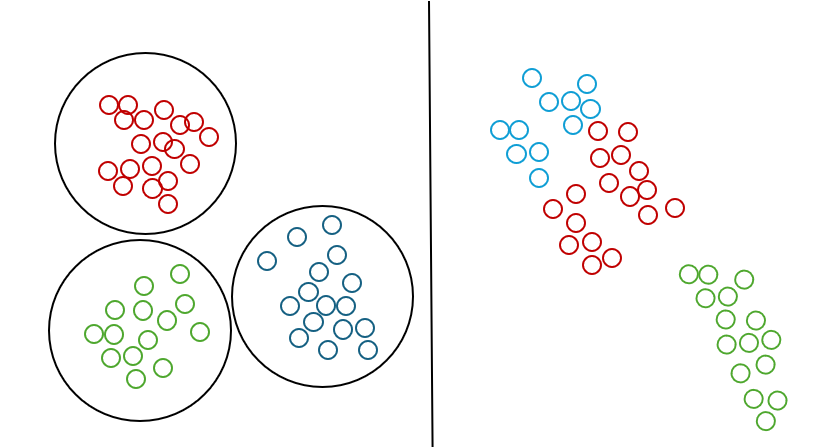
하지만, 확률 기반 GMM은 이런 데이터에서 예측을 잘할 수 있습니다.
📚 DBSCAN
DBSCAN은 밀도기반 군집화 알고리즘 입니다.
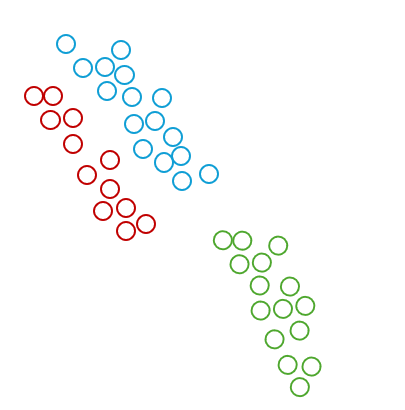
우리가 어떤 데이터셋에 대해서 군집한다고 하면 그 근거는 밀도를 기반으로 할 것입니다.
예를들어, 다음과 같은 데이터가 있을 때 우리는 일반적으로 왼쪽이 아닌 오른쪽으로 군집화를 수행할 것입니다.
이렇게 데이터가 원형 분포를 가지는 경우 기존의 거리기반 알고리즘으로 해결하기 힘들 수 있습니다.
DBSCAN은 간단하고 직관적인 알고리즘으로 돼있음에도 데이터의 분포가 기하학적으로 복잡한 데이터 세트에도 효과적인 군집화가 가능합니다.
DBSCAN은 특정 공간 내에 데이터 밀도 차이를 기반 알고리즘으로 하고있습니다.
DBSCAN을 구성하는 중요한 두 가지 파라미터는 다음과 같습니다.
1. epsilon(입실론 주변 영역)
개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역.
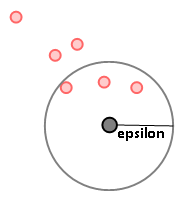
2. min points(최소 데이터 개수)
입실론 영역에 포함되는 타 데이터의 최소 개수.
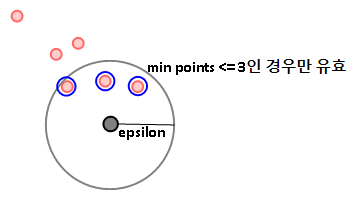
DBSCAN에서는 데이터를 입실론 주변 영역에 최소 데이터 개수를 충족시키는가에 의해 다음과 같이 정의 합니다.
- Core Point(핵심 포인트): 입실론 주변 영역에 최소 데이터 개수를 가지고 있는 데이터
- Neighbor Point(이웃 포인트): 주변 영역에 위치한 타 데이터
- Border Point(경계 포인트): 핵심 포인트는 아니지만, 핵심 포인트를 이웃으로 가진 데이터
- Noise Point(잡음 포인트): 핵심 포인트, 이웃 포인트, 경계 포인트 모두가 아닌 데이터
✅ DBSCAN 작동원리
DBSCAN의 작동원리에 대해 알아보겠습니다.
DBSCAN은 핵심 포인트를 직접 이동하면서 구간을 확장하게 됩니다.
각 데이터에 대해 핵심 포인트인지 확인합니다. 만약 핵심 포인트라면, 그 구간에 속해있는 데이터를 군집화 시키게 됩니다.
이로인해, 복잡한 기하학적 모양으로 생긴 데이터 세트에 대해서도 잘 예측할 수 있게 됩니다.
그림의 설명을 따라 읽으면 이해가 되실 겁니다.
(입실론은 그림으로 나타내며 최소 데이터 개수는 5개라고 가정했습니다.)
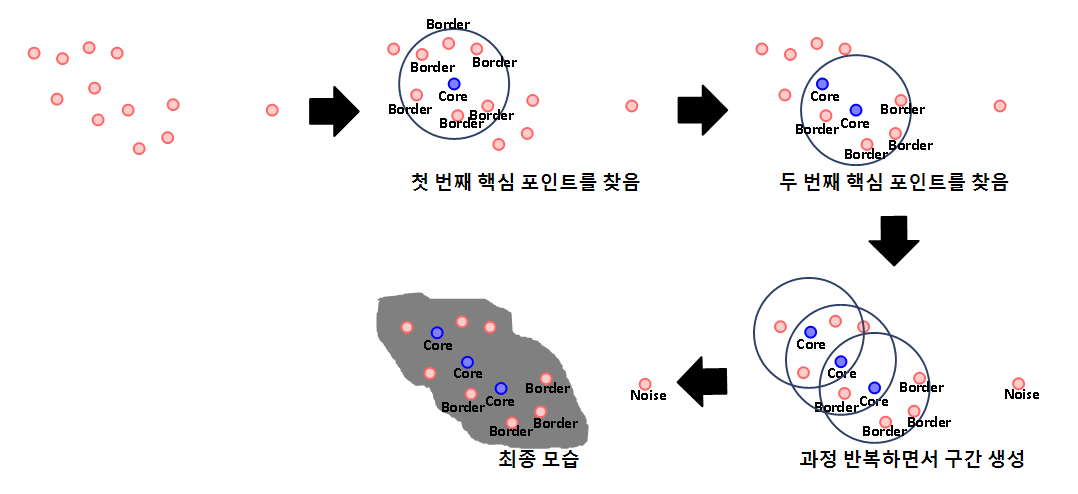
✅ DBSCAN Class
사이킷런은 DBSCAN 클래스를 제공합니다.
from sklearn.datasets import load_iris
from sklearn.cluster import DBSCAN
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris_data = load_iris()
iris_df = pd.DataFrame(iris_data.data, columns =['ftr1', 'ftr2', 'ftr3', 'ftr4'])
iris_df['target'] = iris_data.target
dbscan = DBSCAN(eps=0.5, min_samples=5)
preds = dbscan.fit_predict(iris_df.iloc[:, :-1])
iris_df['dbscan'] = preds
pca = PCA(n_components=2)
pca_data = pca.fit_transform(iris_df.iloc[:, :-1])
iris_df['pca_1'] = pca_data[:, 0]
iris_df['pca_2'] = pca_data[:, 1]
plt.scatter(x=iris_df[iris_df['dbscan']==-1]['pca_1'], y=iris_df[iris_df['dbscan']==-1]['pca_2'], marker='*', c='b', label='-1')
plt.scatter(x=iris_df[iris_df['dbscan']==0]['pca_1'], y=iris_df[iris_df['dbscan']==0]['pca_2'], marker='s', c='r', label='0')
plt.scatter(x=iris_df[iris_df['dbscan']==1]['pca_1'], y=iris_df[iris_df['dbscan']==1]['pca_2'], marker='^', c='g', label='1')
plt.title('eps=0.5, min_samples=5')
plt.legend()
plt.show()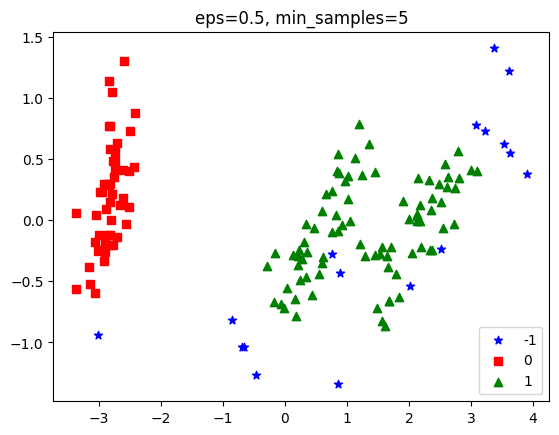
DBSCAN도 다른 군집화 알고리즘처럼 fit_predict를 통해 군집화를 수행할 수 있습니다.
주의할 점은, DBSCAN은 n_cluster를 지정하지 않는다는 점입니다.
즉, 몇 개의 군집으로 나누어질 지는 사용자가 아니라 모델이 정하는 것입니다.
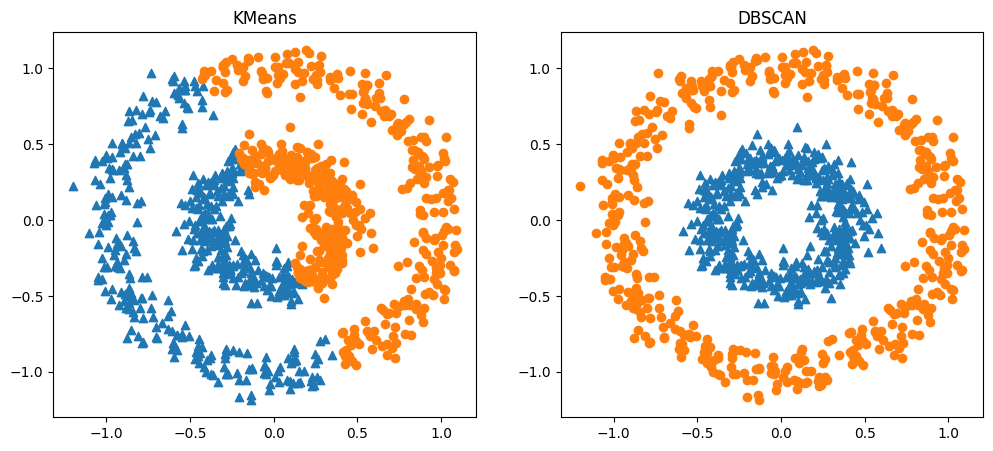
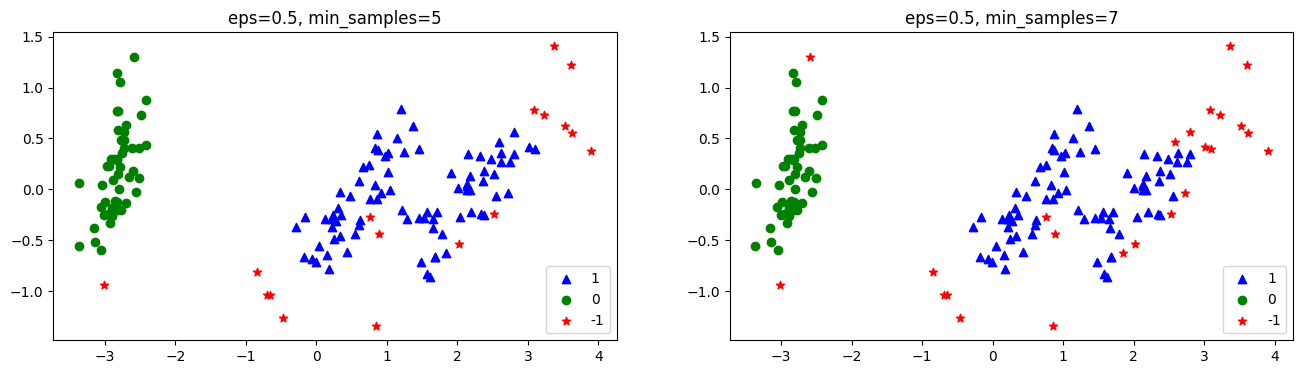
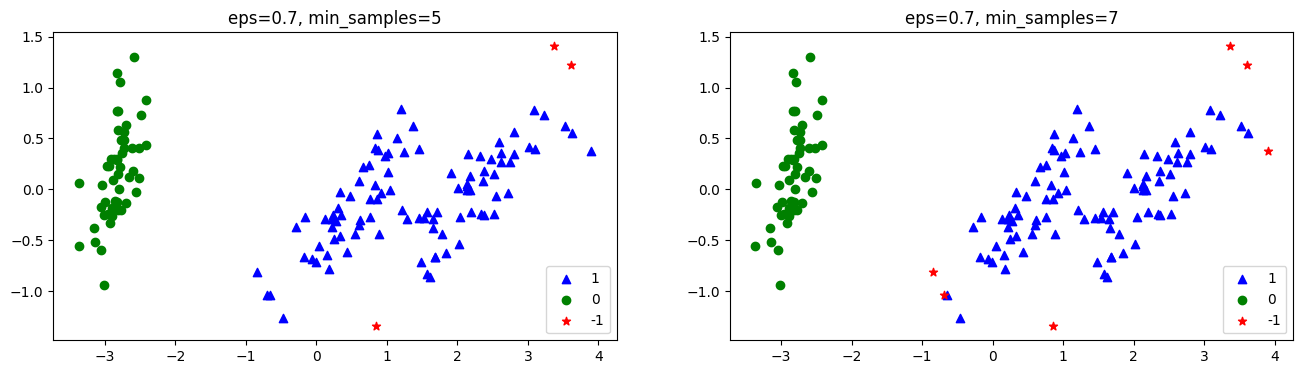
붓꽃 데이터의 경우 eps=0.5, min_samples=5인 경우(default 값) noise가 17개 입니다.
일반적으로 다른 군집화 알고리즘보다 성능이 조금 떨어지긴 했습니다.
다음은 epsilon과 min_samples 파라미터에 따라 군집화가 어떻게 수행되는지 나타낸 것입니다.
markers = ['^', 'o', '*', 's', 'D', '+']
colors = ['b', 'g', 'r', 'c', 'm', 'y']
epses = [0.3, 0.5, 0.7]
samples = [5, 7]
for i in range(3):
for j in range(2):
model = DBSCAN(eps=epses[i], min_samples=samples[j])
preds = model.fit_predict(iris_df[['ftr1', 'ftr2', 'ftr3', 'ftr4']])
iris_df['eps={0}, min_samples={1}'.format(epses[i], samples[j])] = preds
for i in range(3):
fig, axs = plt.subplots(figsize=(16, 4), ncols=2)
for j in range(2):
column_name = 'eps={0}, min_samples={1}'.format(epses[i], samples[j])
values = iris_df[column_name].value_counts().index.tolist()
for k, value in enumerate(values):
axs[j].scatter(x=iris_df[iris_df[column_name]==value]['pca_1'], y=iris_df[iris_df[column_name]==value]['pca_2'], marker=markers[k], c=colors[k], label=value)
axs[j].legend()
axs[j].set_title(column_name)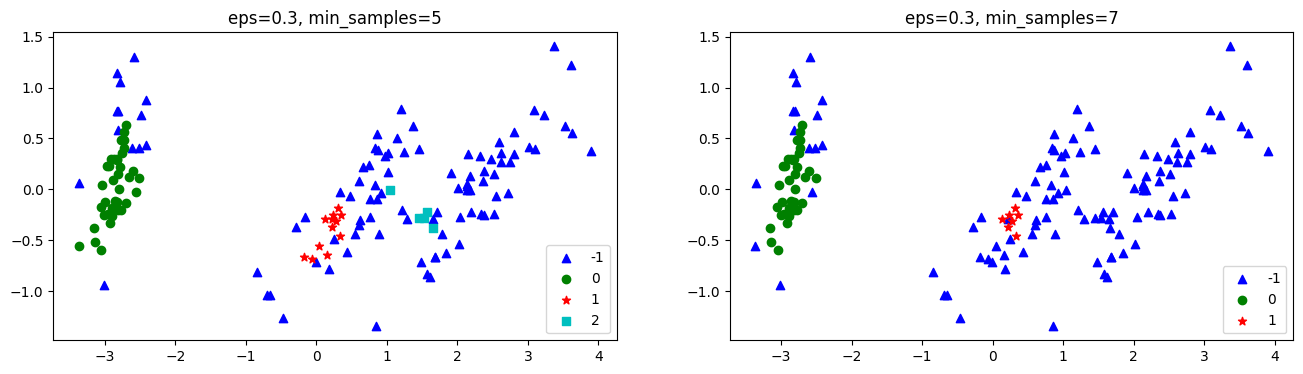
Reference
[개정판] 파이썬 머신러닝 완벽 가이드
GMM(Gaussian Mixture Model,가우시안 혼합모델) 원리
