
이 머신러닝 시리즈는 내 인공지능의 Base가 되어준 『파이썬 머신러닝 완벽 가이드 - 권철민』을 다시 곱씹어 읽어보며 작성하려고 한다.
이외에도 필요하거나 따로 공부하면서 알아낸 정보 출처는 reference에 넣어두겠다.
모든 환경설정은 google Colab pro에서 진행되지만 pro가 아니어도 된다.
혹시나 틀린 개념이 있거나 궁금한 점이 있으시면 알려주시면 감사하겠습니다.
Pandas
데이터가 저장되는 방식 대부분은 2차원 데이터다.
행과 열로 이루어진 데이터다.
파이썬의 Pandas 패키지는 2차원 이하의 데이터를 다루기에 용이하다.
앞서 다뤘던 Numpy도 데이터 핸들링을 할 수 있지만 사용자 친화적이진 않다.
Pandas는 Numpy 기반으로 만들어 졌으며, 일부는 Numpy와 다른 점도 있다.
보통 파이썬으로 데이터를 다룬다면 Pandas를 이용한다고 보면 된다.
DataFrame & Series
DataFrame은 Pandas를 공부하기 전 확실하게 알아야 할 개념이다.
DataFrame은 Pandas에서 사용하는 객체인데 데이터를 저장하는 틀(?)같은 개념이다.
DataFrame에 대해선 이후에 좀 더 알아보도록 하자.
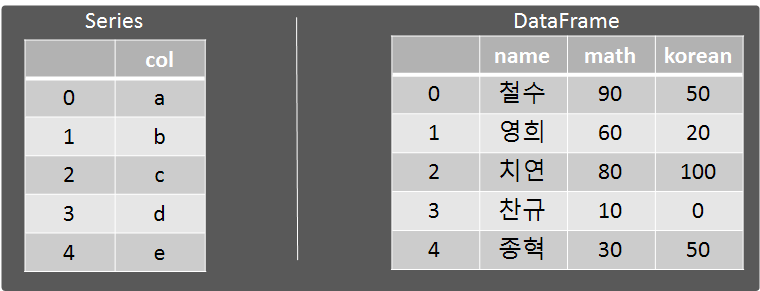
Series또한 DataFrame과 유사한 개념이다.
DataFrame과 다른 점은 컬럼이 1개일 뿐이다.
컬럼이 2개 이상이면 DataFrame이고, 컬럼이 1개면 Seires라고 생각하면 된다.
Coding📄
데이터 핸들링을 연습하려면 Data가 필요하다.
나는 여기서 연습용 데이터 titanic data를 가져올 생각이다.
titanic data는 kaggle에서 연습용 데이터로 많이 사용되며, 첫 데이터 분석시 국민 데이터라고 보면 된다.
다운로드 하는 방법은 구글링을 하면 많이 나오므로 생략하겠다.
1. Pandas를 이용해 데이터 가져오기.
import pandas as pdpandas 모듈을 불러올 때는 import pandas as pd로 해주는 것이 관례다.
pd.read_csv("/content/gdrive/MyDrive/Colab Notebooks/zz.ML Dataset/titanic_train.csv")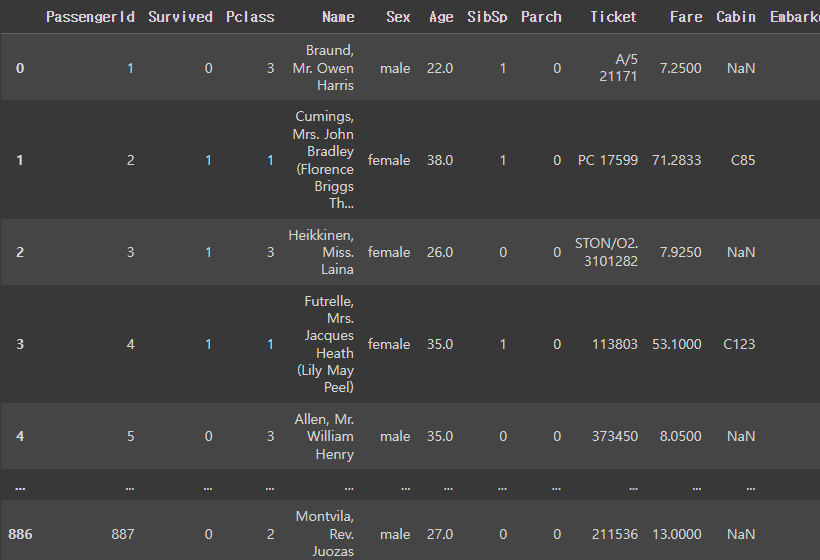
pandas에는 pd.read_csv( )같은 데이터 로드 API가 있다. 이름에서도 알 수 있듯이 csv(','로 분리된 데이터)형식의 파일을 로드할 수 있다.
파일명(파일의 경로)을 입력해주면 된다.
sep인자의 default값은 ','인데 sep을 어떻게 설정하느냐에 따라 다양한 형식의 데이터를 로드할 수 있다.
sep = \t로 설정하면 tab으로 분리된 데이터를 불러올 수 있다.
titanic_df = pd.read_csv("/content/gdrive/MyDrive/Colab Notebooks/zz.ML Dataset/titanic_train.csv")
titanic_df.head(3)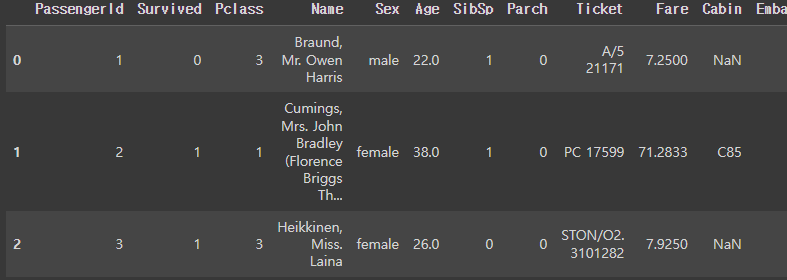
read_csv는 dataframe 객체를 반환한다.
dataframe 객체를 보고싶으면 dataframe 메소드 head( )를 부르면 된다.
head( )의 인자로는 몇 개의 행을 원하는지 숫자를 적을 수 있다.
default는 5다.
titanic_df.info()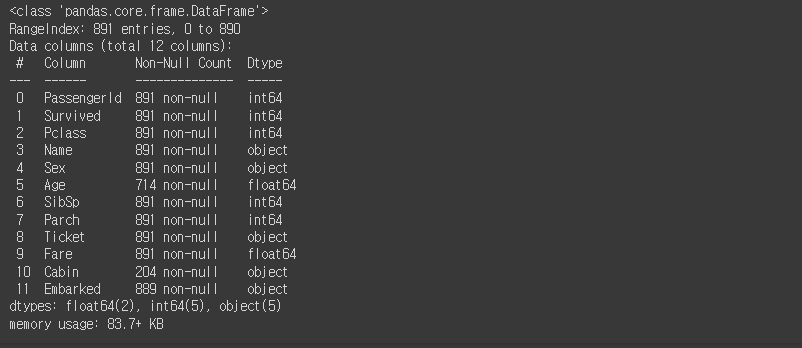
titanic_df.describe()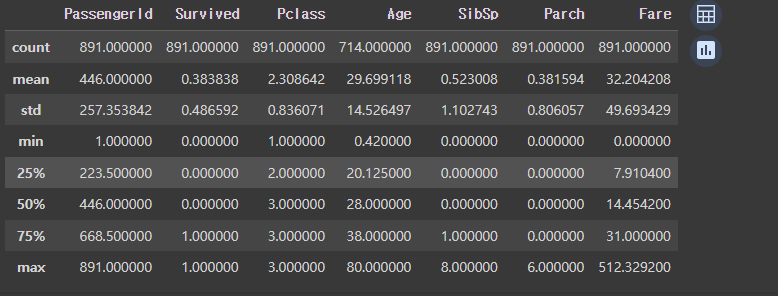
DataFrame 객체는 데이터를 간단하게 파악할 수 있도록 info( ), describe( )메소드를 제공한다.
info( )는 총 데이터 건수와 데이터 타입, NULL건수를 알 수 있게 해준다.
describe( )는 컬럼별 숫자형 데이터 값의 n-percentile분포도, 평균값, 최댓값, 최솟값을 알 수 있게 해준다.
describe( )사용 시 object 타입은 자동으로 제외시킨다.
titanic_df['Embarked'].value_counts()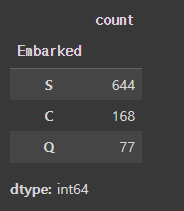
DataFrame/ Series의 value_counts( )메소드는 컬럼별 데이터 값의 분포도를 파악할 수 있게 해준다.
DataFrame과 Series 모두에서 사용할 수 있지만 Series에서 사용하는 경우가 더 많다.
titanic_df['Embarked'].value_counts(dropna=False)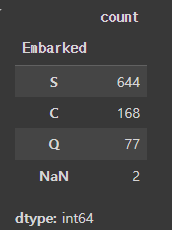
value_counts( )메소드는 아무런 입력값이 없으면 Null값을 자동으로 제외하고 카운트 해준다.
인자로 dropna=False로 설정해주면 Null값도 카운트 해준다.
2. 데이터 변환
- ndarray, list, dictionary => DataFrame
머신러닝 알고리즘 대부분의 Input은 Numpy의 ndarray로 받는 경우가 많다.
그래서 데이터 유형을 변형시켜주는 작업을 많이 하게 된다.
import numpy as np
# ndarray => DataFrame
ndarray = np.array([1, 2, 3])
col_name = ['test']
ndarray_df = pd.DataFrame(ndarray, columns=col_name)
# list => DataFrame
list1 = [1, 2, 3]
list_df = pd.DataFrame(list1, columns=col_name)
# dictionary => DataFrame
dic = {'test' : [1, 2, 3]}
dic_df = pd.DataFrame(dic)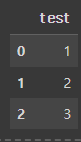
위 코드는 각각 ndarray, list, dictionary를 DataFrame으로 변형하는 코드다.
- DataFrame => ndarray, list, dictionary
# DaraFrame => ndarray
df_to_array = titanic_df['Pclass'].values
# DaraFrame => list
df_to_list = df_to_array.tolist()
# DaraFrame => dictionary
df_to_dic = titanic_df.to_dict('list')위 코드는 DataFrame을 각각 ndarray, list, dictionary로 변형하는 코드다.
values는 DataFrame과 Series 모두에서 사용할 수 있다.
이는 DataFrame이나 Series의 데이터 값을 ndarray로 반환해주는 역할을 한다.
3. 데이터 수정(삭제) 및 셀렉션
데이터 핸들링을 하다보면 데이터를 수정하거나 셀렉션 해야하는 경우가 있다.
Pandas는 컬럼 단위로 데이터 핸들링을 편리하게 해준다.
- 데이터 수정
titanic_df['Age_by_2'] = titanic_df['Age'] * 2 + 10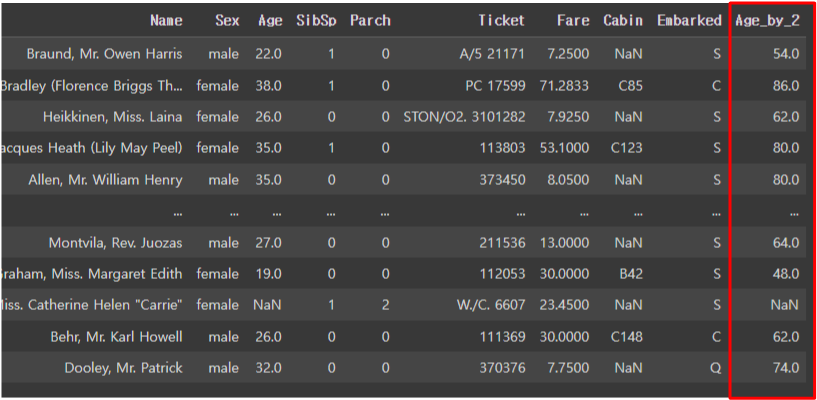
위처럼 사용자 친화적으로 내부 데이터 값을 바꿀 수 있다.
- 데이터 삭제
데이터 삭제는 DataFrame의 drop( )메소드를 이용한다.
drop( )메소드는 원형은 다음과 같다.
DataFrame.drop(labels=None, *, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
이중에서 labels, axis, inplace인자만 사용할 것이다.
drop_titanic_df = titanic_df.drop(['Pclass'], axis=1, inplace=False)
# inplace=False이므로 원본 데이터 유지
print(titanic_df)
# 반환값인 drop_titanic_df는 Pclass 컬럼이 삭제된 채로 존재.
print(drop_titanic_df)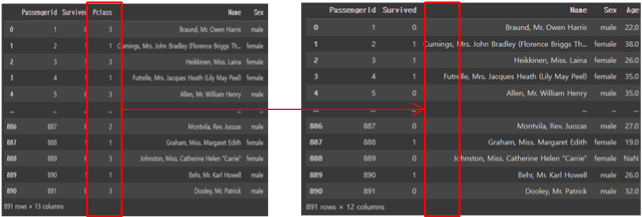
우선 삭제하고자 하는 컬럼이나 인덱스 값을 labels 인자에 넣어준다.
그 후 axis로 삭제하고자 하는 축을 넣어준다.
axis=1이면 컬럼 단위로 삭제해주고, 0이면 행 단위로 삭제해준다.
inplace=False이면 원본 DataFrame은 유지한 채 새로운 DataFrame을 반환한다.
inplace=True이면 원본 DataFrame을 drop해준 후 None값을 반환한다.
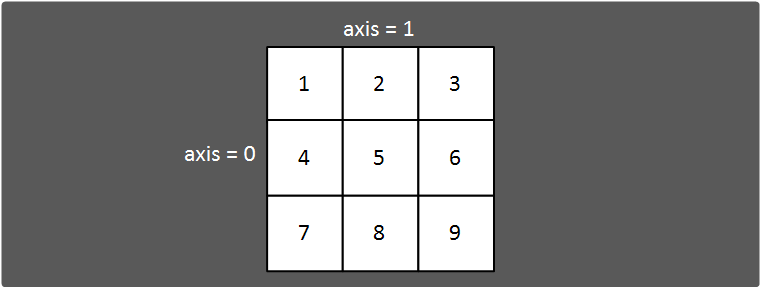
drop( )메소드에서 axis는 축을 의미하는데 위 그림으로 이해하면 편할 것 같다.
「Numpy에 대하여.」편에서 설명했으니 참고해주면 된다.
- 데이터 셀렉션
DataFrame에서는 특정 데이터, 혹은 조건에 맞는 데이터를 찾고자 할 때 데이터 셀렉션 기능을 제공한다.
크게 [ ]을 이용한 셀렉션, iloc[ ]을 이용한 셀렉션, loc[ ]를 이용한 셀렉션이 있다.
1. [ ]을 이용한 셀렉션
# selection을 통해 Series 반환
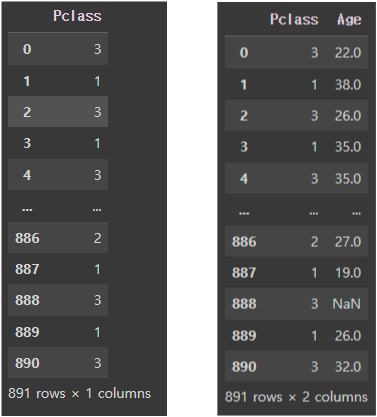
titanic_df['Pclass']
# selection을 통해 DataFrame 반환
titanic_df[['Pclass', 'Age']]DataFrame뒤에 붙는 '[ ]'를 이용하면 원하는 컬럼의 데이터를 뽑을 수 있다.
여러 컬럼을 뽑고싶으면 두번 째 예시처럼 리스트 형식으로 넣어주면 된다.
DataFrame의 '[ ]'를 이용한 셀렉션은 불린 인덱싱을 제공한다.
예를 들어 타이타닉호의 생존자(survived=1) 데이터를 구하고 싶을 땐 다음과 같이 구할 수 있다.
titanic_df[titanic_df['Survived'] == 1]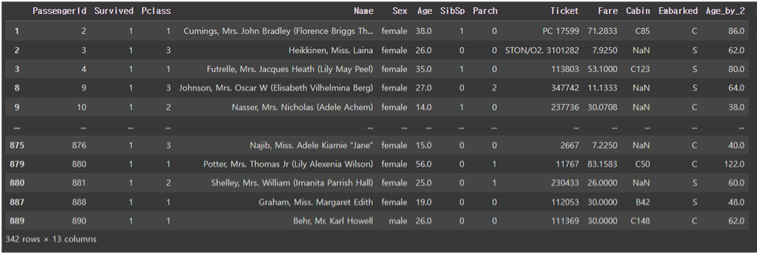
불린 인덱싱은 실전에서 많이 사용되므로 잘 숙지하자.
2. iloc[ ]를 이용한 셀렉션
iloc[ ]는 위치기반 인덱싱 방식이다.
즉, 원하는 데이터의 '위치'를 입력하면 가져올 수 있다는 것이다.
아래와 같이 임의의 DataFrame을 만들어 설명하겠다.
# 임의의 DataFrame 만들기.
test_df = pd.DataFrame(
{'Name':['치연', '종혁', '찬규', '미선'],
'Grade': [40, 70, 50, 10],
'Sex': ['M', 'M', 'M', 'F']}
)
test_df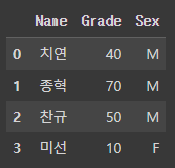
위의 DataFrame에서 2행 2열 위치의 데이터 70을 뽑으려면 iloc[1, 1]을 이용하면 된다.
test_df.iloc[1, 1]그럼 다음과 같은 코드는 어떻게 작동할까?
test_df.iloc[0:2, 1]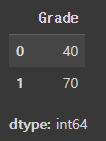
즉, iloc[ ]는 위치 기반으로 데이터를 추출할 수 있게 해주는 인덱싱 방식이다.
3. loc[ ]를 이용한 셀렉션
loc[ ]는 명칭기반 인덱싱 방식이다.
loc[ ]는 행의 위치로 index값을 입력받고, 열 위치로 column값을 입력 받는다.
여기서 주의해야 할 점은 행 위치가 index가 입력되어야 한다는 점이다.
인덱스(index)는 행을 분리할 수 있게 해주는 고유한 값이다.
즉, 고유한 값은 모두 index가 될 수 있다. 예를들어 다음과 같은 DataFrame이 있다고 가정하자.
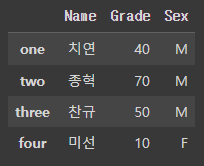
iloc[ ]를 설명했던 DataFrame과 상당히 유사하지만 index의 명칭이 다른 것을 눈치 챘는가?
이처럼 index는 고유한 값이면 문자형도 가능하다.
이때 '치연'이라는 값을 loc[ ]를 이용해 가져오고 싶다면 다음고 같이 작성하면 된다.
test_df.loc['one', 'Name']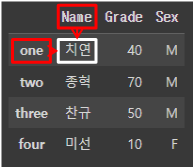
4. 정렬, Aggregation, Groupby
- 정렬
DataFrame을 정렬하는 API로는 sort_values( )가 있다.
sort_values메소드의 인자로는 by, ascending이 있다.
by는 정렬을 수행할 기준이 되는 컬럼을 의미하고, ascending은 오름차순으로 정렬할 것인지 내림차순으로 정렬할 것인지 정하는 인자다.
default는 True다.
# 임의의 DataFrame 만들기.
test_df = pd.DataFrame(
{'Name':['치연', '종혁', '찬규', '미선'],
'Grade': [40, 70, 50, 10],
'Sex': ['M', 'M', 'M', 'F']}
)
# Grade를 기준으로 오름차순 정렬
test_df.sort_values(by='Grade')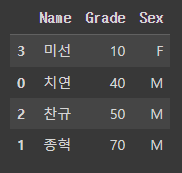
# Grade를 기준으로 내림차순 정렬
test_df.sort_values(by='Grade', ascending=False)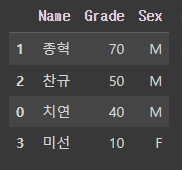
- Aggregation
DataFrame에는 min( ), max( ), mean( ), count( ), sum( )과 같은 aggregation 함수가 존재한다.
DataFrame에 aggregation함수를 적용하면 해당하는 모든 컬럼에 aggregation이 적용된다.
titanic_df를 다시 로드하고 titanic_df를 이용해 count( )와 sum( ) aggregation을 적용해보자.
titanic_df.count()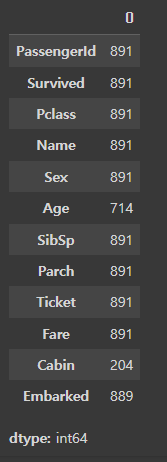
titanic_df['Age'].sum()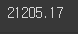
DataFrame에 aggregation을 적용시 해당하는 모든 컬럼에 적용한다는 점을 기억하자.
또한, aggregation함수의 인자에는 axis라는 인자가 있다. 이는 aggregation을 적용할 축을 설정하는 인자다.
axis=0은 열에 대해, axis=1은 행에 대해 aggregation을 진행하는 것을 의미한다.
- Groupby
Groupby는 EDA(Exploratory Data Analysis)에 많이 사용되는 기법이다.
Groupby는 특정 컬럼을 기준으로 다른 데이터를 바라보고 싶을 때 사용할 수 있다.
다시 test_df를 가져와 진행해보자.
# 임의의 DataFrame 만들기.
test_df = pd.DataFrame(
{'country': ['KOR', 'JAPAN', 'KOR', 'KOR', 'JAPAN', 'JAPAN'],
'Name':['치연', '종혁', '찬규', '미선', '철수', '영희'],
'Grade': [40, 70, 50, 10, 100, 0],
'Sex': ['M', 'M', 'M', 'F', 'M', 'F']}
)
test_groupby_df = test_df.groupby('country')위는 test_df에 country를 기준으로 groupby시켜준 것이다.
test_groupby_df는 DataFrameGroupBy라는 객체가 된다.
보통 이렇게 groupby를 하게 되면 aggregation과 같이 이용된다.
다음은 groupby와 aggregation 함수를 이용한 예시이다.
# 나라별 grade 합을 구하는 로직
test_groupby_df['Grade'].sum()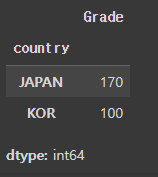
위 로직을 그림으로 풀면 다음과 같다.
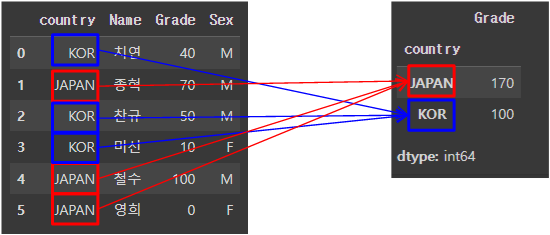 하지만, 만약 groupby객체에 여러 aggregation을 적용하고 싶다면 어떻게 해야할까?
하지만, 만약 groupby객체에 여러 aggregation을 적용하고 싶다면 어떻게 해야할까?
Pandas에서는 agg라는 메소드를 제공하는데 이를 이용하면 한번에 여러 aggregation을 여러 컬럼에 적용할 수 있다.
test_groupby_df.agg({'Grade': ['max', 'min', 'mean'],
'Sex': ['count']})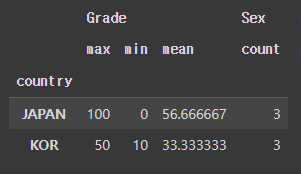
agg에는 인자로 딕셔너리가 들어올 수 있다.
이때 키 값으로는 aggregation을 적용할 컬럼이 들어오고, value값으로는 원하는 aggregation 함수를 문자형으로 작성해주면 된다.
5. 이상치(NULL) 값 제거
이상치 데이터, 그중에서도 NULL값은 어떻게 처리할까?
Pandas에서는 이를 위해 isnull( ), fillna( )라는 메소드를 제공한다.
- isnull( )
DataFrame의 isnull( )메소드는 각 데이터에 대해 그 값이 NULL값인지 아닌지를 반환해준다.
titanic_df.isnull()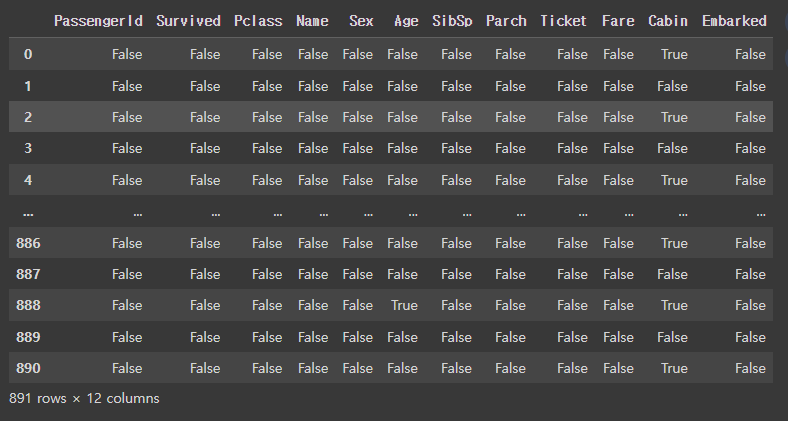
- fillna( )
fillna( )메소드는 자동으로 NULL값을 찾아 사용자가 인자로 넣어준 값으로 채워주는 역할을 한다.
age_titanic_df = titanic_df['Age'].fillna(-1)
age_titanic_df.isnull().sum()
=> 0titanic_df의 Age컬럼에는 177개의 Null값이 존재했는데 DataFrame의 fillna 메소드를 이용해 -1로 채워준 코드다.
6. 이외의 다양한 API
지금까지 설명한 API이외에도 매우 많은 Pandas API가 존재한다.
다음은 내가 실제 데이터 핸들링할 때 많이 쓰는 Pandas API다.
- apply( )
- isnull( )
- replace( )
- concat( )
- explode( )
- merge( )
- factorize( )
- get_dummies( )
- unique( )
- DataFrame.astype( )
- DataFrame.reset_index( )
- DataFrame.idxmax( )
- DataFrame.shape( )
Reference
