BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
한줄요약
기존 단방향 모델이었던 sequential recommendation model을 NLP 분야의 양방향 모델인 BERT를 활용하여 양방향 sequential recommendation model인 BERT4Rec를 소개하는 논문이다.
이 논문은 SASRec과 비교하는 실험이 많으니 SASRec 논문을 반드시 읽어야한다.
이 논문에 대한 리뷰는 SASRec을 이해했다는 가정하에 진행된다.
ABSTRACT
기존 Sequential Recommendation 모델들은 Sequential Neural Networks를 사용하여 user의 historical behaviors를 왼쪽에서 오른쪽으로 hidden representations로 인코딩하여 추천한다. 하지만 이 논문에서는 왼쪽에서 오른쪽으로의 Unidirectional Models들이 아래와 같은 이유들로 최적의 방법이 아니라고 주장한다.
-
Unidirectional Architectures는 users' behavior sequences에서 hidden representation의 힘을 제한한다.
-
기존 방법들은 엄격하게 순서화된 sequence를 가정하는데 이것은 항상 실용적이지는 않다.
이러한 문제를 해결하기 위해 deep bidirectional self-attention을 사용하는 BERT4Rec을 소개한다.
정보 유출을 방지하고 양방향 모델을 효율적으로 학습시키기 위해서 Cloze objective를 Sequential Recommendation에 채택하여 시퀀스에서 무작위로 마스킹된 항목을 예측하고 좌우 context를 함께 조건화 한다.
user의 historical behaviors에 각 item이 좌우 양쪽에서 융합하도록 하여 추천하는 Bidirectional Representation Model을 학습한다.
1 INTRODUCTION
왼쪽에서 오른쪽으로의 Unidirectional Models이 user behavior sequence를 위한 최적의 표현을 학습하기에 충분하지 않다고 주장한다.
-
Unidirectional Models은 historical sequence에서 item에 대한 hidden representation의 힘을 제한한다. 왜냐하면 각 item은 이전 item들의 정보만 인코딩할 수 있기 때문이다.
-
이전의 Unidirectional Models은 자연스러운 순서를 가진 순차 데이터 (예를들어 텍스트, 시계열 데이터)를 위해 처음 도입되었는데, 이전 연구에서는 user behavior에 대해서 항상 참이 아닌 데이터에 대해 엄격하게 순서화된 sequence를 가정한다는 문제점이 있다. 실제로는 다양한 관찰되지 않는 외부 요인들로 인해 엄격한 순서에 대한 가정을 따르지 않을 수도 있다.
이러한 이유들로 user behavior sequence에서 양쪽 방향의 context를 통합하는 것이 중요하다. 이 논문에서는 BERT로부터 영감을 받아 deep bidirectional self-attention model을 sequential recommendation에 적용한다.
단방향 모델은 왼쪽에서 오른쪽으로 순차적으로 다음 item을 예측하지만, 양방향 모델은 그것이 아니다. BERT4Rec에서는 Cloze task를 도입하여 단방향 모델의 목표 (순차적으로 다음 item을 예측하는 것)를 대채한다. Cloze task를 도입하는 것은 이 논문이 최초이다. input sequence에서 일부 item을 random으로 masking ([mask]로 대체)하고 주변 context를 기반으로 masking된 item의 ID를 예측한다. 이렇게 하면 정보유출을 방지할 수 있고, 각 item의 표현이 좌우 context를 융합하도록 허용하여 양방향 모델을 학습할 수 있다. Cloze objective는 여러번의 epoch에서 더 강력한 모델을 훈련하기 위해 더 많은 샘플을 생성할 수 있다.
하지만 Cloze objective의 단점은 Sequential Recommendation의 final task와 일치하지 않는다는 것이다. 다시 말해서 Sequential Recommendation은 맨 마지막 item을 예측해야하는데, 여기서는 맨 마지막이 아니라 아무곳에나 masking을 뚫어서 그것을 예측했기 때문이다. 이를 수정하기 위해 test 동안에 우리는 [mask]를 input sequence 끝에 추가하고 최종 hidden vector를 기반으로 추천을 한다.
아래 그림에서 SASRec (c)과 BERT4Rec (b)을 비교하면 확연히 비교가 될 것으로 보인다 (단방향 모델과 양방향 모델).
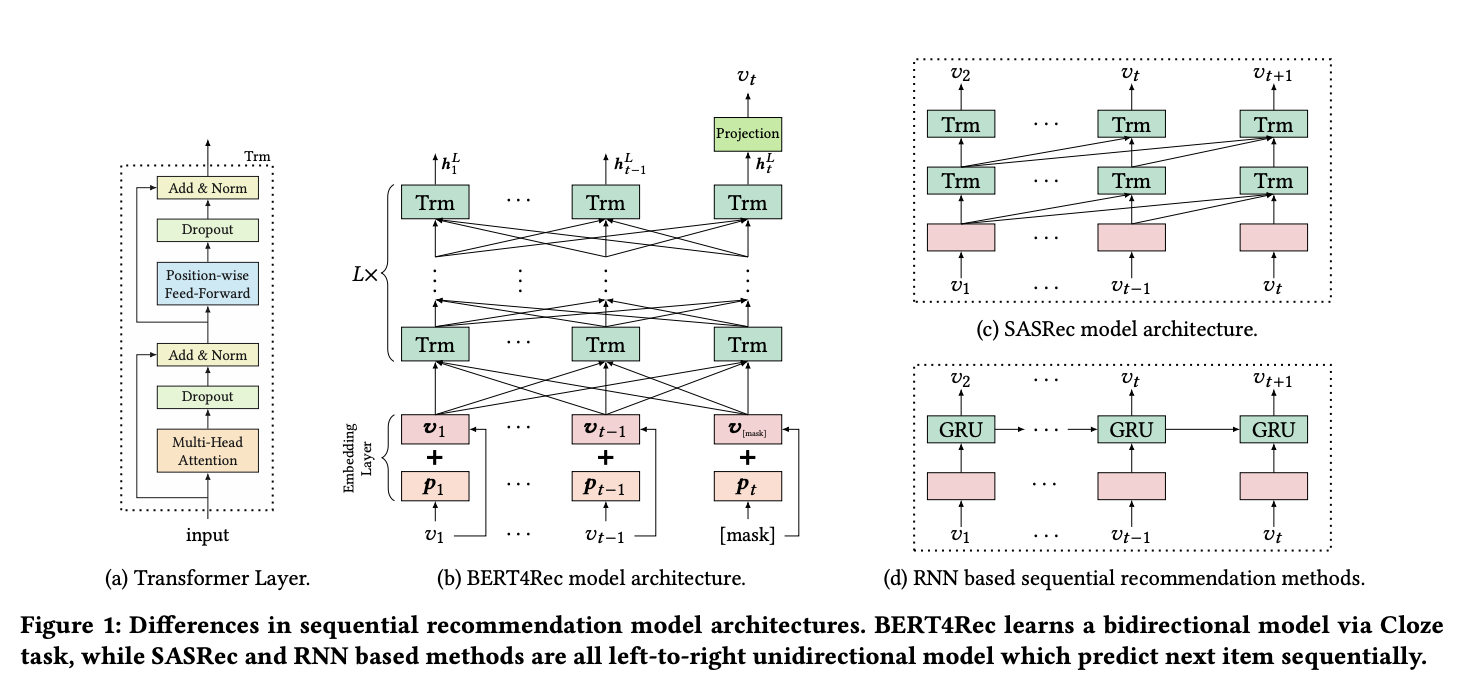
2 RELATED WORK
General Recommendation
Sequential Recommendation
Attention Mechanism -> SASRec (Unidirectional Model)
3 BERT4REC
(SASRec과 거의 내용이 동일하니 SASRec을 알고 있다는 가정하에 간단간단하게 설명하겠다)
이 논문에서는 아래와 같이 모델링 하는 것을 공식화 했다. 여기서 p는 확률이고, Su는 user u의 interactio history이고, v는 item이고, 결론적으로 말로 설명하면 v라는 item을 user u가 (nu+1) 단계에서 interaction할 확률이다.
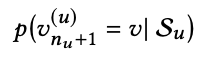
다양한 위치에서 다른 표현 subspaces의 정보를 공동으로 주목하다는 것이 유익하다는 연구들에 영감을 받아 이 논무에서는 single attention이 아니라 multi-head self-attention을 채택한다. 이 방법에 대한 것은 Section 4에서 figure로 보기 좋게 설명해준다. 수식은 아래와 같다.
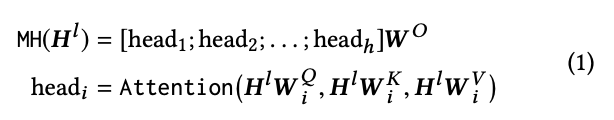
그리고 아래의 수식은 Scaled Dot-Product Attention에 대한 수식이다.
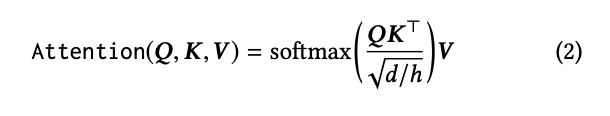
SASRec과 마찬가지로 위에까지의 수식은 linear model이다. 여기서도 non-linear 모델로 만들기 위해 Position-wise Feed-Forward Network를 적용한다. parmeters는 모든 위치에 걸쳐 공유된다. SASRec과의 차별점으로는 ReLU 대신 더 부드러운 GELU를 사용한다는 특징이 있다. 수식은 아래와 같다.
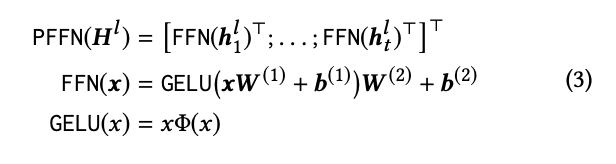
SASRec과 마찬가지로 BERT4Rec에서도 residual connection, layer normalization, droupout을 적용한다. 수식은 아래와 같다.
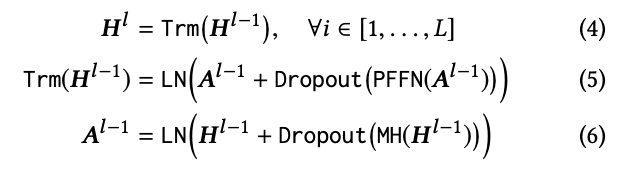
Transformer layer Trm은 input sequence의 순서를 인식하지 못한다. input의 순차적 정보를 활용하기 위해서는 Positional Embeddings을 추가해야한다. 그래서 아래와 같은 수식으로 적용된다.

Figure 1b와 같이 time step t에서 item vt를 masking 한다고 하면 ht의L을 기반으로 masking된 item vt를 예측한다. 구체적으로 말하면 2개의 layer feed-forward network에 GELU를 적용하여 target item에 대한 output distribution을 생성한다. 수식은 아래와 같다.
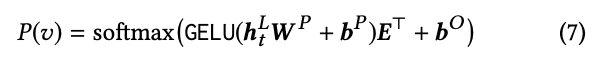
이제부터는 SASRec에 없는 내용이다. 양방향 모델에 대한 설명이 시작된다.
단방향 모델과는 다르게 양방향 모델인 BERT4Rec은 손봐야할게 있다. 일단 s1 s2 s3 s4가 주어지고 s5에 대한 것을 예측하면 되는 단방향 모델들과는 다르게 BERT4Rec은 양방향 모델이기 때문에 mask를 해서 sample들을 생성해주어야하고 각 historical subsequence를 양방향 모델로 인코딩하여 target item을 예측해야한다. 하지만 이런 접근 방식은 매우 많은 시간과 자원을 소모한다. 이를 해결하기 위해 Cloze task를 적용한다. 각 training 단계에서 input sequence의 모든 item 중에서 p 비율로 random masking하고, 좌우 context만을 기반으로 masking된 item의 원래 ID를 예측하는 것이다. 예를 들면 아래와 같다.
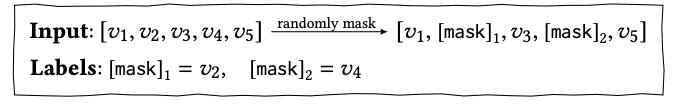
loss는 아래와 같은 수식으로 표현된다. S'u는 user behavior histort Su의 masking된 것이고, Su의m은 random masking된 item들, vm의*은 masking된 Item vm에 대한 실제 item이다.
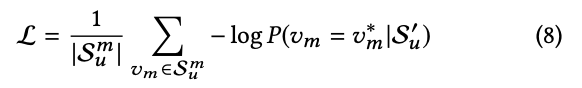
Cloze task의 또다른 장점은 모델을 훈련시키기 위해 더 많은 sample을 생성할 수 있다. mask를 하나만 뚫는게 아니라 여러개 뚫으면 더 많은 sample을 얻을 수 있고 더 강력한 모델로 훈련이 가능하다.
이런식으로 훈련을 진행한다는 점을 알아두면 될 것 같고, 이제 test 방식이다. 설명하기 이전에 우리는 하나의 이상함을 발견해야한다. 결국 BERT4Rec도 Sequential Recommendation인데 지금 훈련하는걸로 봐서는 s1 s2 s3 s4를 통해 s5를 예측하는 것이 아니라 s1 s2 [mask] s4 s5을 통해 s3를 예측하고 있다는 것이다. 우리의 목표와는 다른 학습을 진행하고 있다. 이 논문에서는 이러한 문제점을 해결하기 위해 그리고 Sequential Recommendation의 최종 목표인 미래를 예측한다는 목표를 위해 user behavior sequence 끝에 [mask]를 추가하여 이 token의 final hidden representation을 기반으로 next item을 예측한다. sequential recom mendation task (predict the last item)를 더 잘 맞추기 위해서 이 논문에서는 훈련 중에 input sequence에서 last item만 masking하는 sample을 생성한다. 저자는 이것을 fine-tuning처럼 작동한다고 말하고 이것을 통해 추천 성능을 더욱 향상시킬 수 있다고 말한다.
이 논문은 NLP 분야의 BERT에서 영감을 받았지만 몇 가지 차이점이 있다고 말한다.
1. BERT4Rec은 end-to-end model이다. BERT는 pretrain model이고 이 task는 언어에 대한 동일한 배경 지식을 공유하는데 recommendation task에서는 이 가정이 적용되지 않기 때문에 end-to-end로 훈련한다.
2. BERT에서의 next sentence loss와 segment embeddings를 제거한다. 왜냐하면 BERT4Rec은 sequential recommendation task에서 하나의 sequence로서 user의 historical behavior을 모델링하기 때문이다.
4 EXPERIMENTS
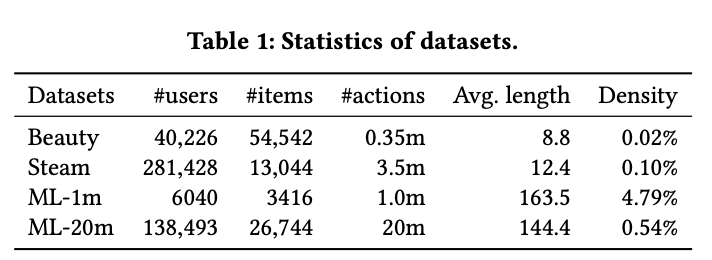
Datasets
Task Settings & Evaluation Metrics
SASRec과 동일하게 진행되며 특별한 점으로는 negtive samplig을 뽑을 수 있다. 여기에서는 100개의 negative sampling을 random으로 뽑는 것이 아니라 popularity에 따라 sampling 된다. 예를 들어 user u에 대한 negative sampling은 모든 item에서 user u가 interaction 했던 아이템을 제외한 나머지 아이템 중에서 인기있는 아이템 100개를 선정하여 negative sample로 넣어주는 것이다. 이렇게 되면 random으로 하는 것보다는 더 효과가 있다. 인기 없는 item을 negative sampling하는 것과 인기 있지만 user가 interaction을 하지 않은 item을 negative sampling하는 것은 후자가 당연하게도 더 효과가 있을 것이다.
Baselines & Implementation Details
- POP
- BPR-MF
- NCF
- FPMC
- GRU4Rec
- GRU4Rec+
- Caser
- SASRec
Overall Performance Comparison
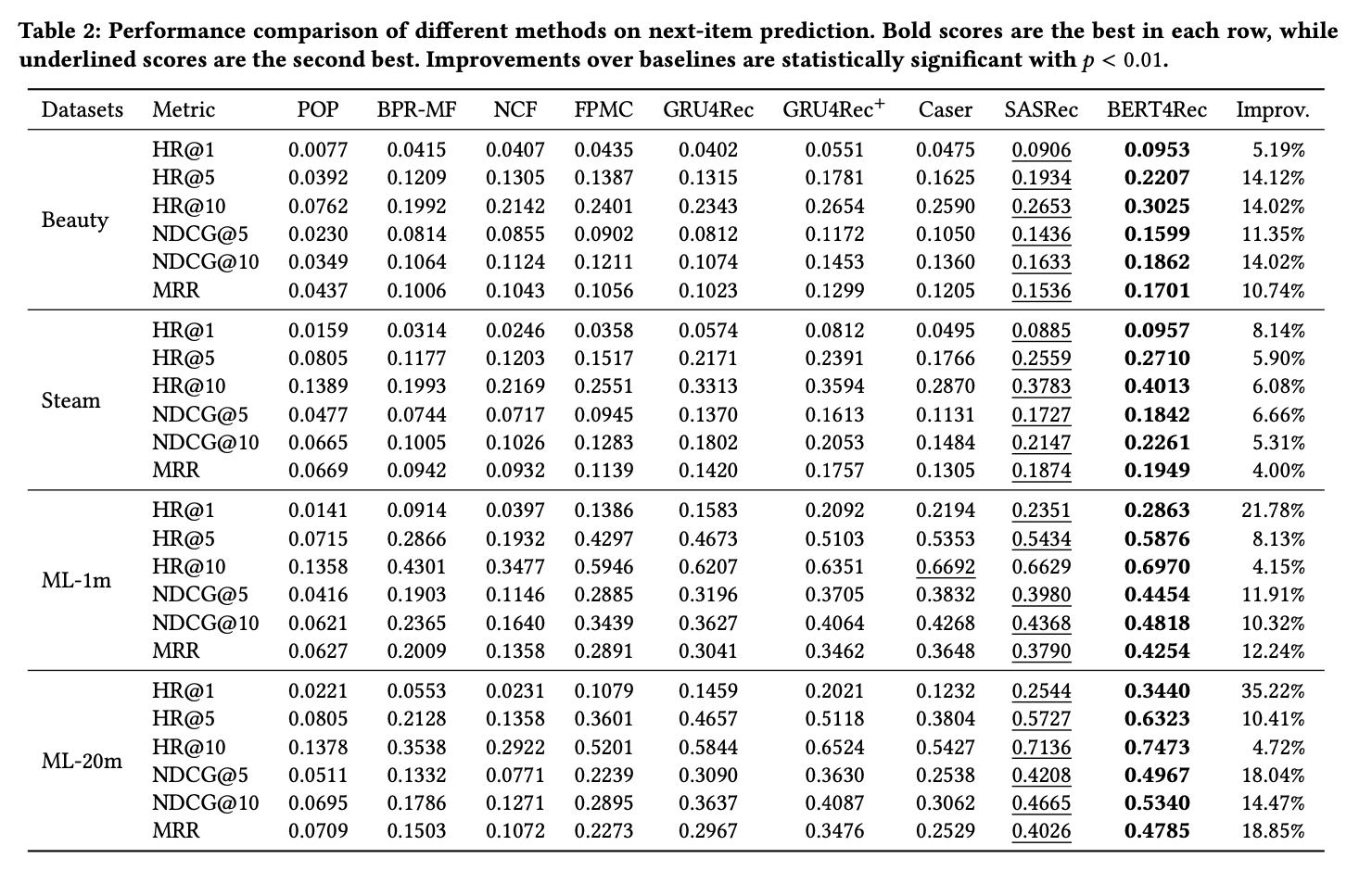
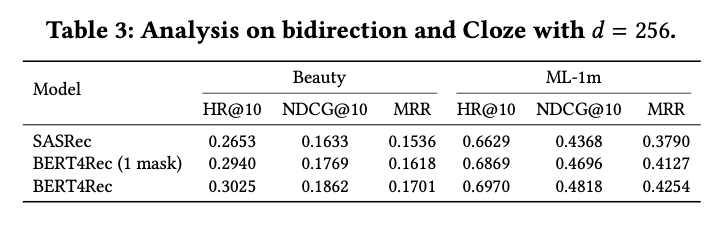
Question 1: Do the gains come from the bidirectional self-attention model or from the Cloze objective?
이 질문에 대한 답을 하기 위해 Cloze objective에서 mask를 여러개가 아닌 하나로 하도록 강제한다. 이렇게 되면 SASRec과 BERT4Rec (1 mask)의 차이점은 단방향이나 양방향이냐라는 차이점밖에 없다. 그 결과 아래의 표에서와 같이 성능 차이가 확연히 나타난다. 이것은 양방향의 중요성을 입증한다. 그리고 BERT4Rec (1 mask)와 BERT4Rec을 비교했을 때 BERT4Rec의 성능이 더 높은 것으로 보아 Cloze objective도 긍정적인 영향을 미친다고 확인할 수 있다.
Question 2: Why and how does bidirectional model outperform unidirectional models?
이 질문에 대한 답이 아래 Figure 2에 있는데, 이 질문에 대한 답을 넘어서는 흥미로운 내용들이 많이 담겨있다.
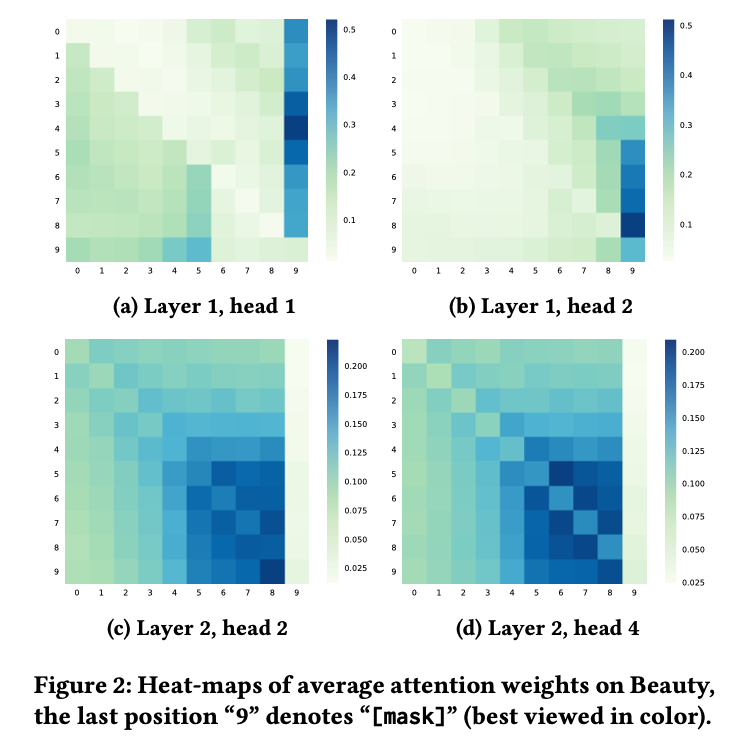
-
attention은 head마다 다르다. layer 1에서 head 1 (a)은 왼쪽에 집중하고, head 2 (b)는 오른쪽에 더 집중한다.
-
attention은 layer마다 다르다. layer 2 (c, d)는 더 최근의 item에 집중하는 경향이 있다. 이것은 layer 2는 ouput layer와 직접 연결되어 있고, 최근 item이 미래 예측에서 더 중요한 역할을 하기 때문이다. 또 다른 흥미로운 패턴은 (a)와 (b)에서 mask에 주의를 기울이는 head이다. 이것은 self-attention이 sequence-level state를 item-level로 전달하는 방법일 수 있다.
-
단방향 모델과는 다르게 BERT4Rec의 item은 좌우 양쪽 item에 주의를 기울이는 경향이 있다. 이는 양방향이 user behavior sequence 모델링에 필수적임을 시사한다.
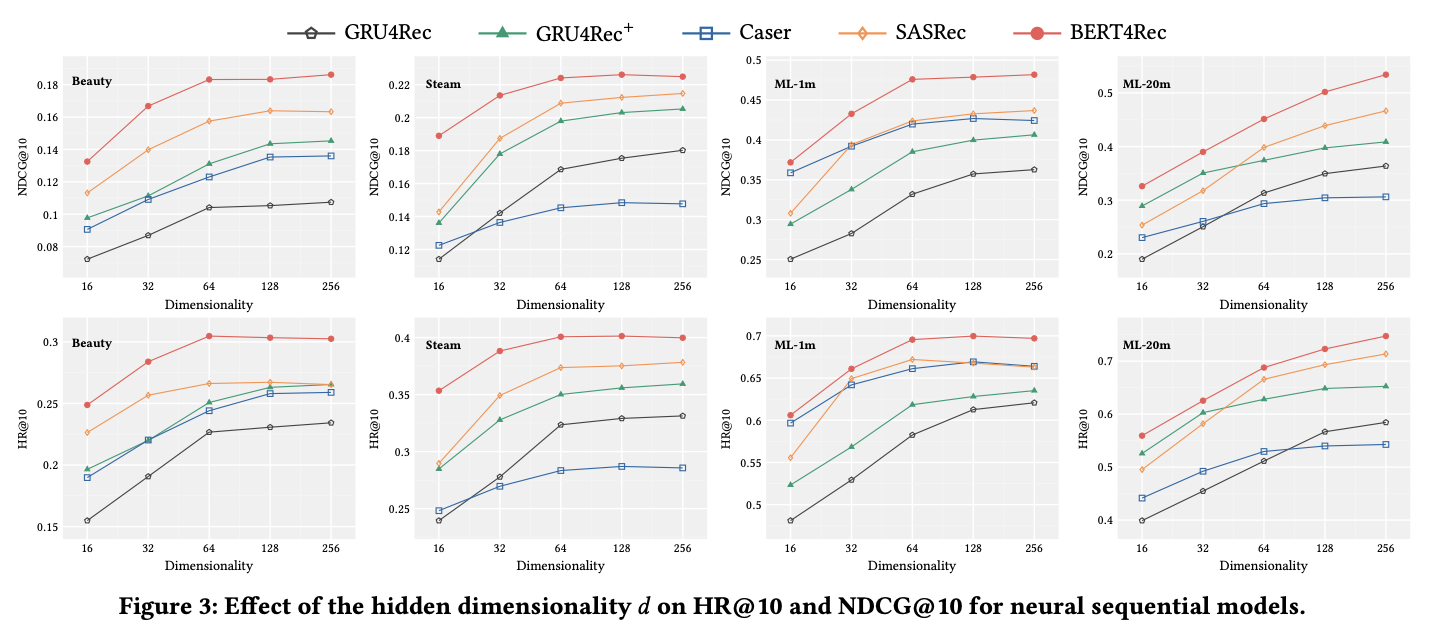
Impact of Hidden Dimensionality d
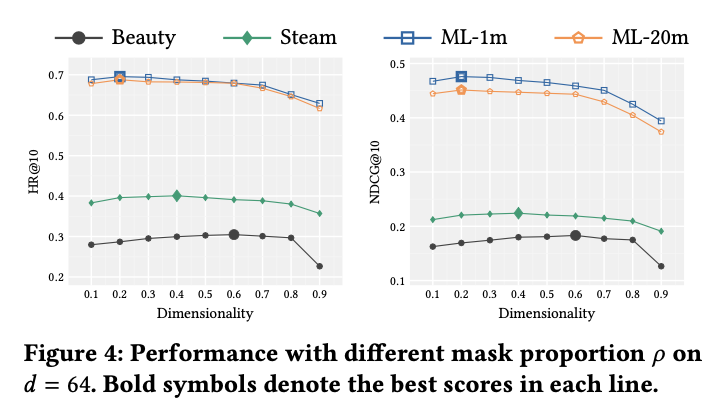
Impact of Mask Proportion p
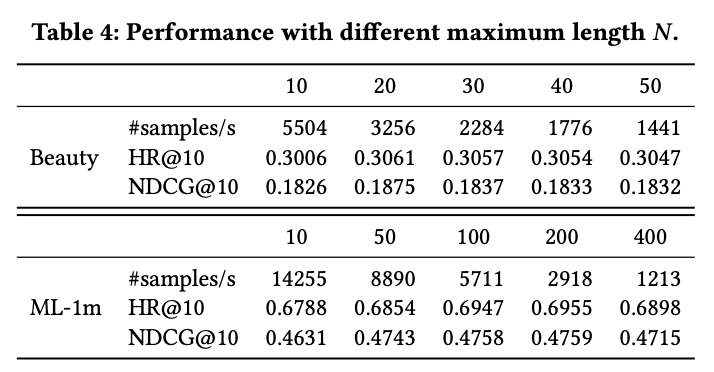
Impact of Maximum Sequence Length N
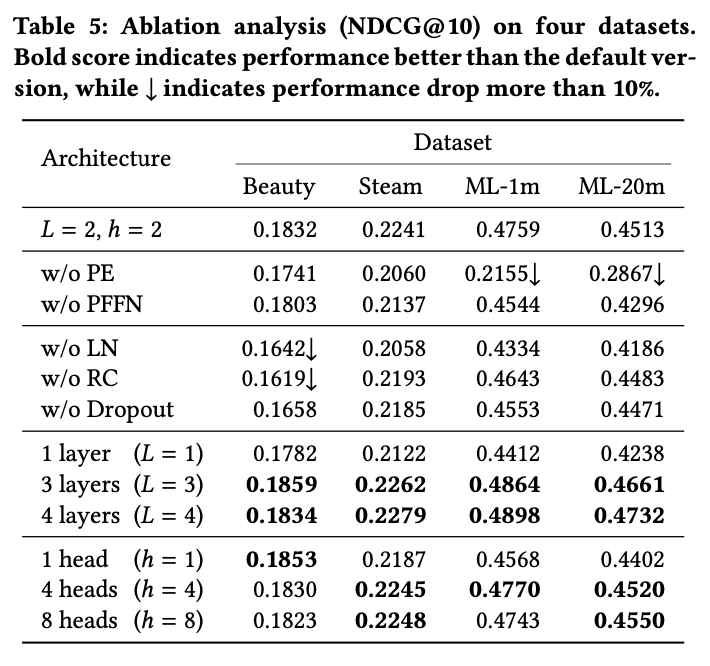
Ablation Study
5 CONCLUSION AND FUTURE WORK
deep bidirectional sequential model인 BERT4Rec을 소개하였고, 훈련을 위해 Cloze task를 도입하였다. 이것은 SOTA이다.
future work로는 item ID를 모델링하는 대신에 item feature (예들 들어 제품의 카테고리 및 가격, 영화의 출연진)을 통합하는 것이다. 또 다른 흥미루은 future work로는 user가 multiple sessions을 가질 때 explicit user modeling을 위해 user component를 모델에 도입하는 것이다.
