
#INTRO
EVERYTHING GOOD잘 되어 가시나 : )

프릳츠 커피 너무 맛있다.
#코드카타 (09:00 ~ 10:00)
-
SQL
REPLACE('컬럼', '기존 문자', '바꿀 문자')
키보드의 0이 고장난 줄 모르고 계산을 끝낸 SAMANTHA의 평균값과
원래의 평균값의 차이를 정수로 구하는 문제# 모든 0을 공백으로 변환 SELECT CEIL(AVG(SALARY) - AVG(REPLACE(SALARY, 0, ''))) FROM EMPLOYEES
-
PYTHON
-
순열:
주어진 여러 개의 항목들을 순서 있게 배열하는 모든 가능한 경우
예를 들어, 세 개의 항목 [A, B, C]가 있다면,
이 항목들의 순열은 [A, B, C], [A, C, B], [B, A, C], [B, C, A], [C, A, B], [C, B, A] 총 6가지가 된다. -
PERMUTATIONS함수는 배열을 순열로 반환해준다.# itertools 모듈에서 permutations 함수 임포트 from itertools import permutations def solution(k, dungeons): max_dungeons = 0 # 최대 탐험 가능한 던전 수를 저장할 변수 초기화 # 모든 던전의 순열을 생성하여 탐색 for p in permutations(dungeons): current_k = k # 현재 피로도를 주어진 k로 초기화 count_dungeons = 0 # 탐험한 던전 수를 저장할 변수 초기화 # 각 순열에 대해 던전을 탐험 for min_k, consume_k in p: if current_k >= min_k: # 현재 피로도가 최소 필요 피로도 이상인지 확인 current_k -= consume_k # 탐험 후 피로도 감소 count_dungeons += 1 # 탐험한 던전 수 증가 else: break # 현재 피로도가 부족하면 탐험 중단 # 최대 탐험할 수 있는 던전 수 갱신 max_dungeons = max(max_dungeons, count_dungeons) # 최대 탐험할 수 있는 던전 수 반환 return max_dungeons
-
#프로젝트 진행 (10:00 ~ 22:00)
-
군집 분석 시도
목표 : 약 120만 개의 행을 가진 데이터로 군집 분석의 전체 사이클 돌려보기
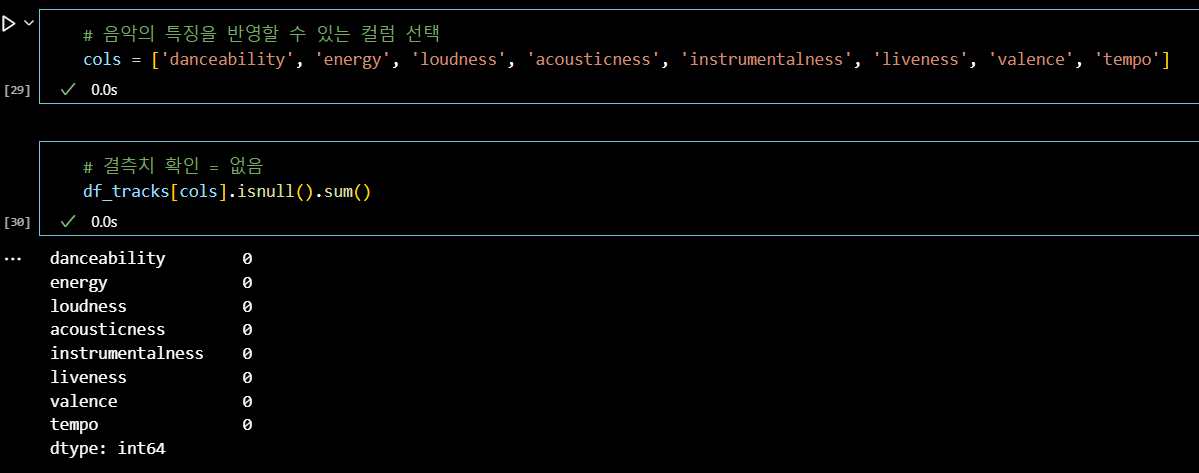
# 음악의 특징을 반영할 수 있는 컬럼 선택 cols = ['danceability', 'energy', 'loudness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo'] # 결측치 확인 = 없음 df_tracks[cols].isnull().sum()
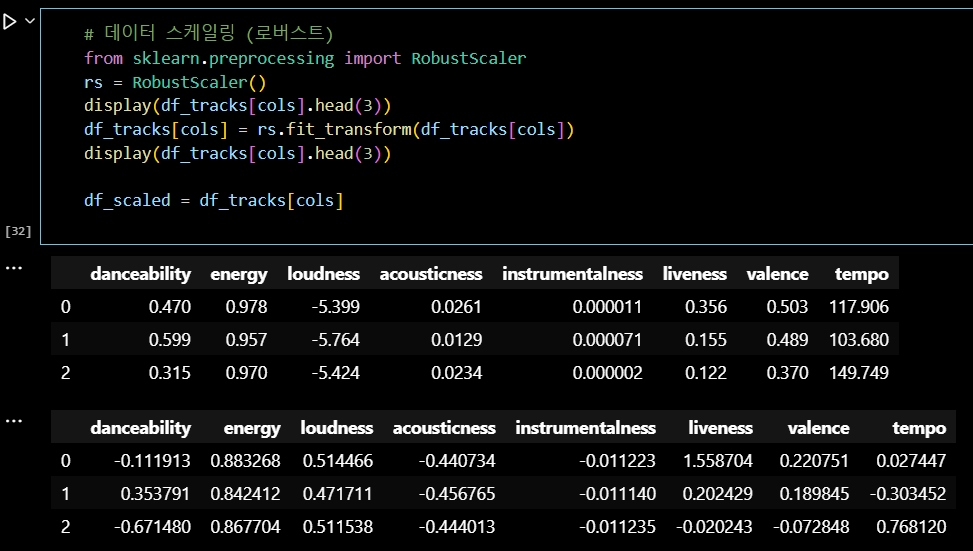
RobustScaler:
데이터의 중앙값을 기준으로 사분범위 내 값으로 스케일링하여
이상치에 덜 영향을 받는 표준화 방법
# 데이터 스케일링 (로버스트) from sklearn.preprocessing import RobustScaler rs = RobustScaler() display(df_tracks[cols].head(3)) df_tracks[cols] = rs.fit_transform(df_tracks[cols]) display(df_tracks[cols].head(3)) df_scaled = df_tracks[cols]
# 주성분 개수를 판단하기 위한 pca 임의 시행 pca = PCA(n_components = 3) pca.fit(df_scaled) # 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지 print(pca.explained_variance_ratio_) print(pca.explained_variance_ratio_.sum())

# pca 시행 pca_df = pca.fit_transform(df_scaled) pca_df = pd.DataFrame(data = pca_df, columns = ['PC1','PC2','PC3']) pca_df.head()
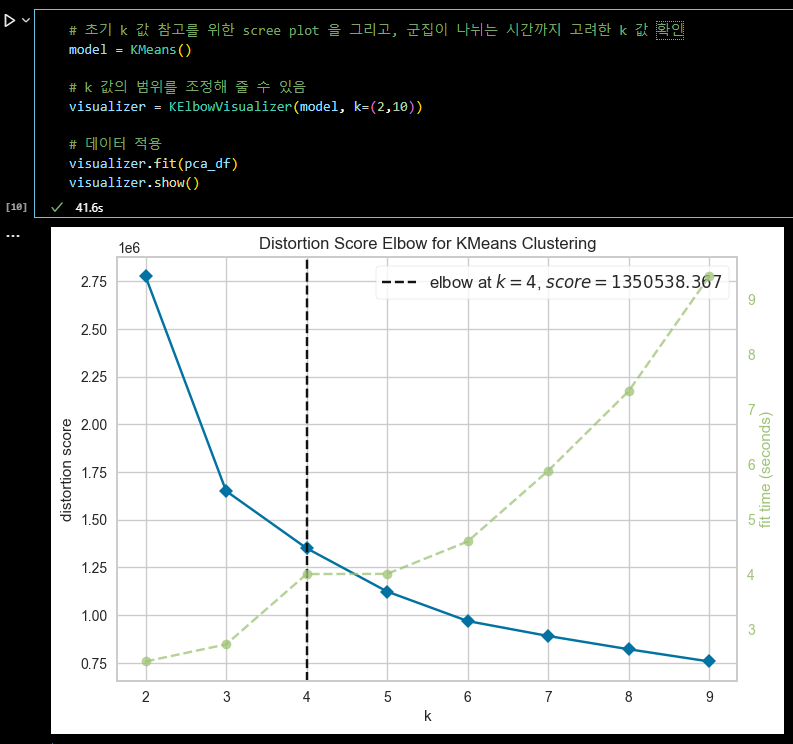
# 초기 k 값 참고를 위한 scree plot 을 그리고, 군집이 나뉘는 시간까지 고려한 k 값 확인 model = KMeans() # k 값의 범위를 조정해 줄 수 있음 visualizer = KElbowVisualizer(model, k=(2,10)) # 데이터 적용 visualizer.fit(pca_df) visualizer.show()
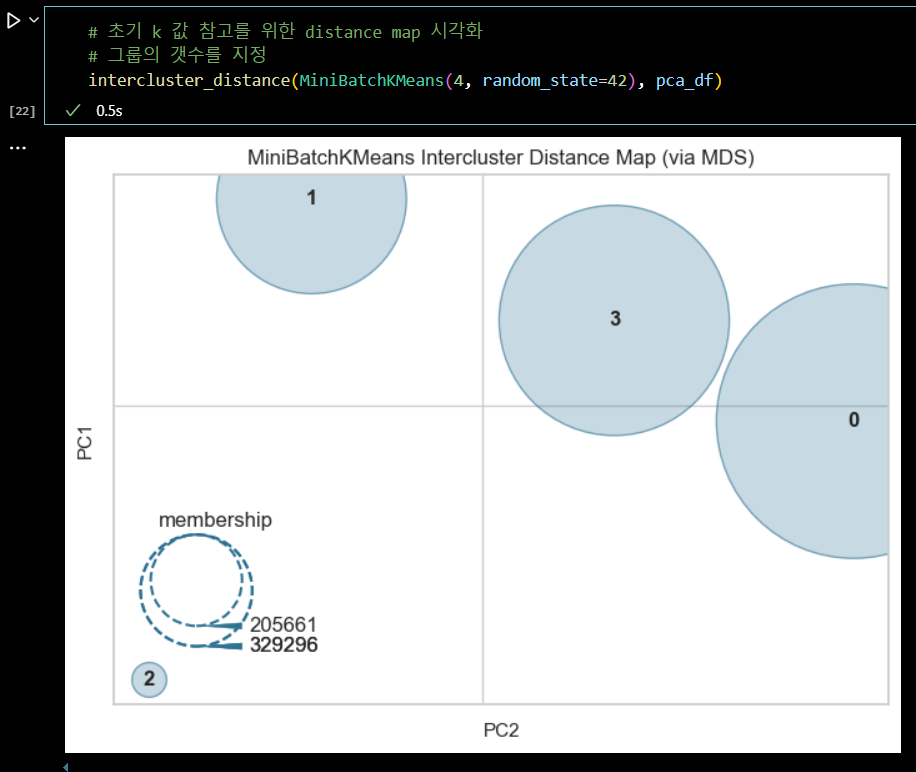
# 초기 k 값 참고를 위한 distance map 시각화 # 그룹의 갯수를 지정 intercluster_distance(MiniBatchKMeans(4, random_state=42), pca_df)
# K - MEANS # 군집개수(n_cluster) 4, 초기 중심 설정방식 랜덤 optimal_k = 4 kmeans = KMeans(n_clusters = optimal_k, random_state = 42, init = 'random') # pca df 를 이용한 kmeans 알고리즘 적용 kmeans.fit(pca_df) clusters = kmeans.fit_predict(pca_df) # 클러스터 번호 가져오기 labels = kmeans.labels_ # 클러스터 번호가 할당된 데이터셋 생성 kmeans_df = pd.concat([pca_df, pd.DataFrame({'Cluster' : labels})], axis = 1)
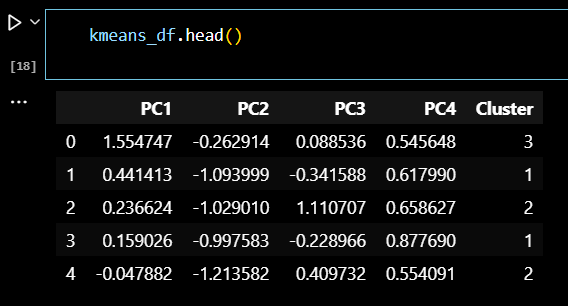
# 클러스터링 데이터셋 확인 kmeans_df.head()
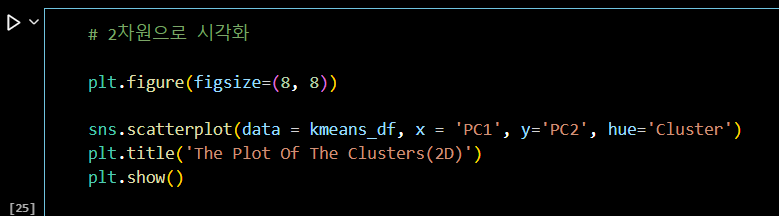
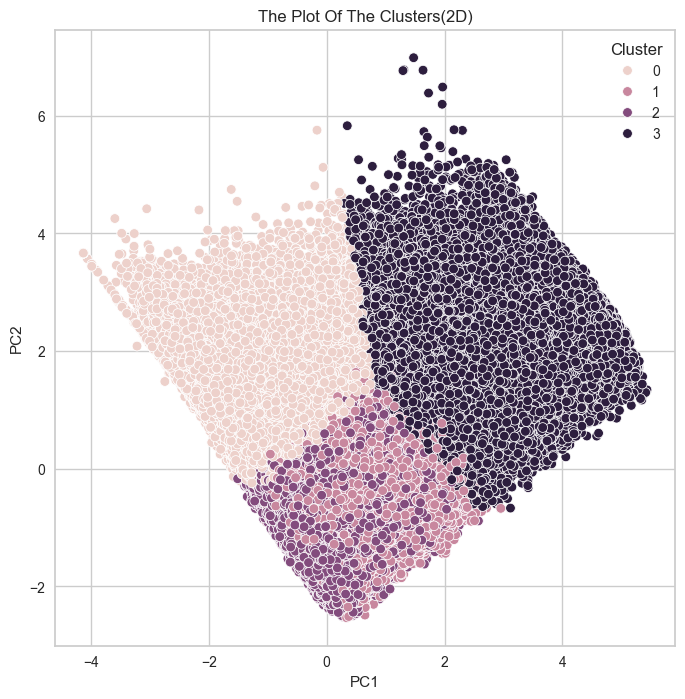
# 2차원으로 시각화
plt.figure(figsize=(8, 8))
sns.scatterplot(data = kmeans_df, x = 'PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters(2D)')
plt.show()
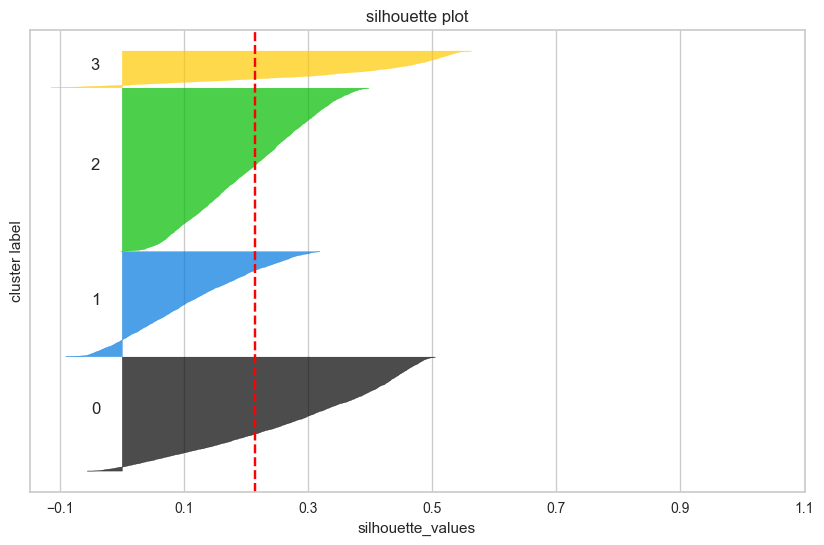
# 전체 데이터셋에서 샘플링 (10000개 샘플) import random sample_size = 10000 if len(df_scaled) > sample_size: sample_indices = random.sample(range(len(df_scaled)), sample_size) df_sample = df_scaled.iloc[sample_indices] clusters_sample = clusters[sample_indices] else: df_sample = df_scaled clusters_sample = clusters # 실루엣 계수 계산 (샘플 데이터셋 사용) from sklearn.metrics import silhouette_score, silhouette_samples silhouette_avg = silhouette_score(df_sample, clusters_sample) silhouette_values = silhouette_samples(df_sample, clusters_sample) # 클러스터별 실루엣 플롯 생성하기 fig, ax = plt.subplots(figsize = (10, 6)) y_lower = 10 for i in range(optimal_k): ith_cluster_silhouette_values = silhouette_values[clusters_sample == i] ith_cluster_silhouette_values.sort() size_cluster_i = ith_cluster_silhouette_values.shape[0] y_upper = y_lower + size_cluster_i color = plt.cm.nipy_spectral(float(i) / optimal_k) ax.fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_silhouette_values, facecolor=color, edgecolor=color, alpha=0.7) ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i)) y_lower = y_upper + 10 ax.set_title('silhouette plot') ax.set_xlabel('silhouette_values') ax.set_ylabel('cluster label') ax.axvline(x=silhouette_avg, color="red", linestyle="--") ax.set_yticks([]) ax.set_xticks(np.arange(-0.1, 1.1, 0.2)) plt.show()

2일차 스크럼 정리
비지도학습에 많은 데이터양이 무조건 좋은 것은 아니었다.
코드를 한 번 돌릴 때, 1시간이 넘어가고,
샘플 데이터셋을 만들어 시간을 단축시켰으나,
유의미한 결과를 내지 못하는 경우도 생겼다.-
팀원들도 2번 데이터셋으로 분석을 진행한 결과,
전처리, 군집 분석, 실루엣 계수 계산 과정에서 시간이 너무 오래 걸리는 문제가 있었다. -
팀 회의 결과, 1번 데이터셋 (17만 개) 으로 분석을 진행한 후,
군집화가 잘 이루어지고 실루엣 계수가 가장 높은 모델을 선택하여
같은 방식의 전처리와 알고리즘 과정을 2번 데이터셋 (120만 개)에 적용해보기로 했다.
- 역할 분담
-
계획 : 데이터셋 1번으로 모델링 후 데이터셋 2번에 적용
이상치 제거
백: RobustScaler 스케일링 후 군집 분석
김: Z-score 이상치 제거 후 군집 분석
이: Isolation 이상치 제거 후 군집 분석
강: DBSCAN or (Z-score) 이상치 제거 후 군집 분석
진: IQR 이상치 제거 후 군집 분석적용 가능한 클러스터링 모델
- K-Means
- 계층적 클러스터링
- DBSCAN
- 가우시안 혼합 모델 (GMM)
-
평가 : 모델 적용 후 실루엣 계수 확인
-
#빅분기(실기) 준비 (22:00 ~ 23:00)
-
PYTHON #25 : 범주형 데이터 분석 검정 (카이제곱 검정)
-
PYTHON #26 : 상관관계와 회귀분석
-
PYTHON #27 : 분산분석 (ANOVA)
#OUTRO
오늘의 한 줄.
ㅋㅋㅋ 잘 하고 있는 거 맞나 !

잘 하고 있는 거 맞다!