Deep Neural Network
일반적으로 hidden layer의 개수가 2개인 network부터 deep neural network라고 한다. layer의 개수가 많아질수록 만들 수 있는 network의 경우의 수가 많아진다. 각 층에 퍼셉트론을 몇 개 쓸 것인가에 대한 선택지가 늘기 때문이다.
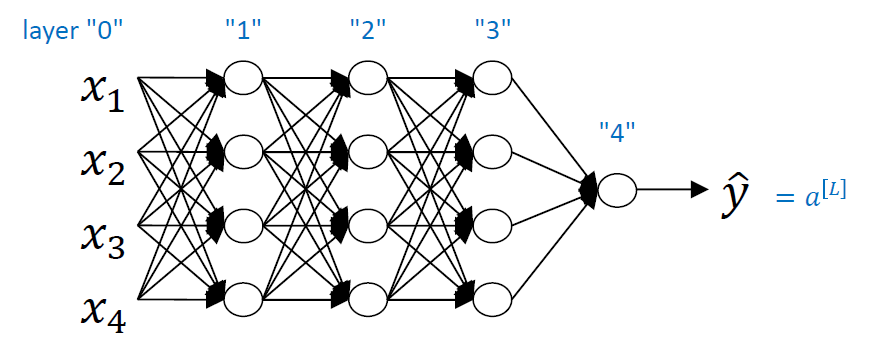 notation에 대해 설명해본다.
notation에 대해 설명해본다.
L: layer의 개수. hidden layer와 output layer의 개수를 합친 것이다. 위의 경우L은 4이다.n[l]: layerl에 있는 unit의 개수이다. 퍼셉트론의 개수를 의미한다.a[l]: layerl의 activation들이다.
z[l] = W[l]a[l-1] + b[l]
a[l] = g[l](z[l])x: network의 inputy hat: network의 prediction
Forward Propagation in a Deep Network
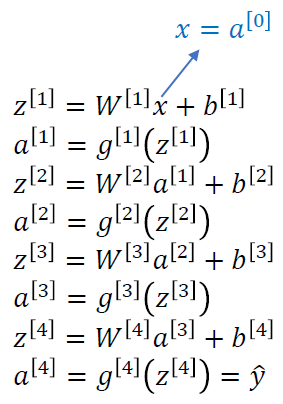 그냥 linear transformation과 non-linear transformation을 반복적으로 수행시키는 것이 forward propagation이다.
그냥 linear transformation과 non-linear transformation을 반복적으로 수행시키는 것이 forward propagation이다.
z는 example 하나에 대해 표현할 때 사용하고, example m개를 한꺼번에 말할 때는 Z를 사용한다.
W는 z이든 Z이든 상관없이, example이 1000개든 10000개든 관련없이 항상 동일하기 때문에 변하지 않는다.
W는 training sample의 개수에 dependency가 있는 것이 아니라 layer의 unit의 개수에 dependency가 있다.
또한 input x를 나타내기 위해 x를 a[0]라고 나타내기도 하는데, 이는 activation function을 사용한 것은 아니지만 표기의 통일성을 주기 위함이다.
Parameters W[l] and b[l]
z[1]일 때 layer 1에서 input x(a[0])이 (2,1)이고, 원래의 식은 (W.T)x이므로 이 때의 W가 (2,3)인데 transpose되었으므로 (3,2). 그럼 (3,2)x(2,1) = (3,1)이 된다.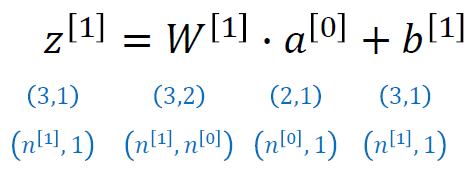
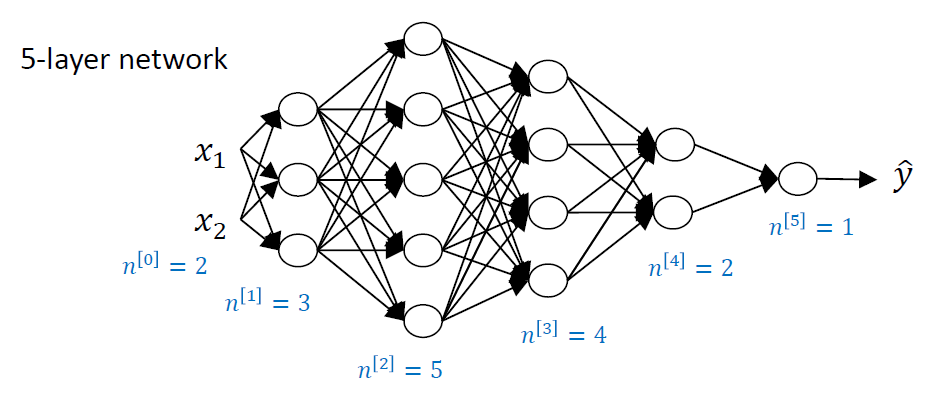
z[2]일 때 layer 2에서 a[1]이 (3,1)이고, 원래의 식은 (W.T)x이므로 이 때의 W가 (3,5)인데 transpose되었으므로 (5,3). 그럼 (5,3)x(3,1) = (5,1)이 된다.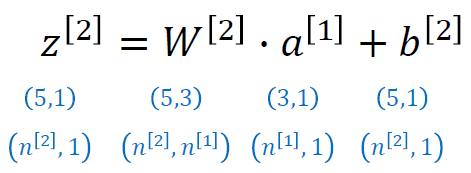 이를 일반화하면, 다음과 같다.
이를 일반화하면, 다음과 같다.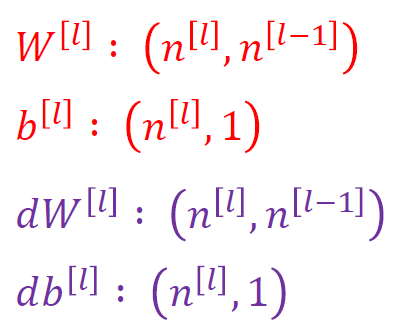
Circuit Theory and Deep Learning
똑같은 문제를 푸는 model을 만들고 싶을 때 shallower network를 사용하게 되면 계산에 필요한 hidden unit의 개수가 기하급수적으로 늘어나게 된다.
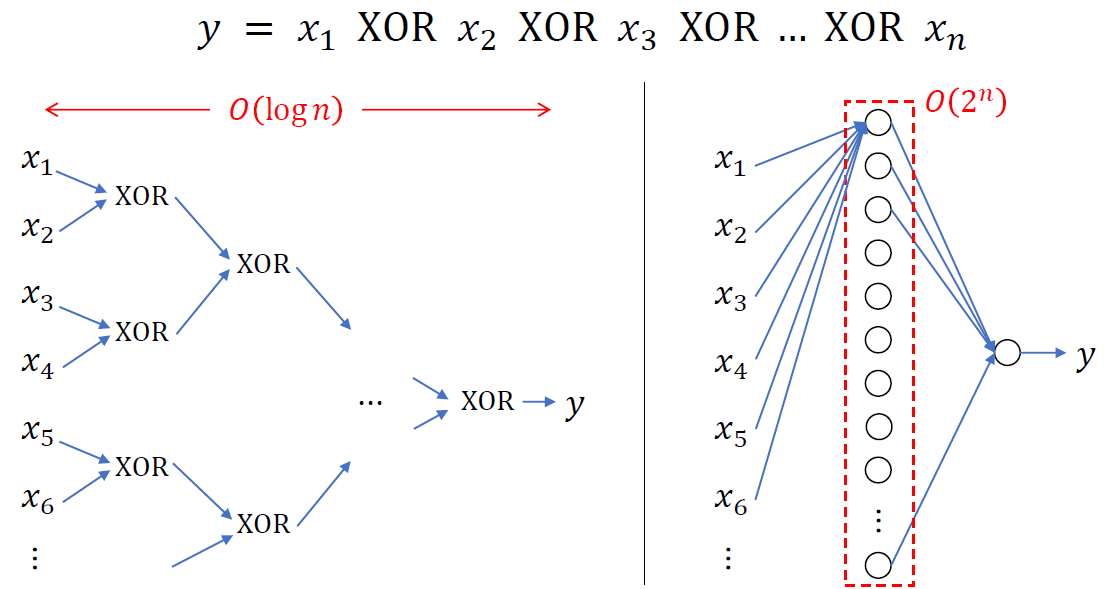
Hyperparameter
learning을 하기 전에 미리 결정해야 하는 parameter들을 의미한다.
learning rate α, gradient descent iteration의 횟수, hidden layer의 개수 L, hidden unit의 개수 n, activation function 등을 미리 결정해야한다.
처음에는 어떤 것이 좋은지 몰라서 대충 결정하게 되고 무엇이 optimal한지 정해져 있지 않다. 그래서 경험적으로 이것저것 해보면서 가장 좋은 것을 찾아내게 되는데 문제는 가장 좋은 것을 찾기 위해 최소 한번씩은 다 training을 해보아야 한다는 것이다...
결정해야 할 것들이 엄청 많은데 이것들이 서로 dependency가 있기 때문에 결정하기 더 어렵다.
