Intro
테슬라 AI Day에서 발표된 기술을 정리를 해나갑니다.
우선 Deep Understanding Tesla FSD의 Part1인 HydraNet을 살펴보겠습니다.
참고) https://saneryee-studio.medium.com/deep-understanding-tesla-fsd-part-1-hydranet-1b46106d57
내용
테슬라의 솔루션
1. 우리는 어떻게 자율주행 카를 만드는가?
2. 우리는 어떻게 학습 데이터를 생성하는가?
3. 우리는 어떻게 차 안에서 그것을 실행시키는가?
4. 우리는 어떻게 빠르게 반복시키는가?
How do We Make A Car Autonomous?
비전)
아래의 클립을 보면, 현재의 테슬라 비전의 최신 버전을 볼 수 있다.

8개의 카메라는 신경망을 통해 3차원 벡터 스페이스를 생성하며 라인, 엣지, 경계석, 교통 사인, 신호등, 자동차 등의 드라이빙에 필요한 것들을 표현한다.
오리지날 디자인은 인간혹은 동물의 비전 학습에 의해 영감을 얻었다.

테슬라는 인간의 두뇌와 같은 비전 기반 컴퓨터 뉴럴 네트워크를 만들었다는 얘기.
용어 정리하고 간다.
- Backbone:
하나의 이미지에서 여러 객체를 인식하고 객체의 풍부한 feature information을 제공하는데 사용되는 feature extracting network를 말한다. AlexNet, ResNet, VGGNet을 backBone으로 종종 사용한다. - Detection Head(Head):
피쳐 추출(백본) 후에 input의 피쳐 맵 표현을 가져온다. 실제로 사물 발견, 분리 등과 같은 일부 실제 작업의 경우, 우리는 보통 "detection head"를 적용하므로 백본에 헤드가 부착된 것과 같다.
-Neck:
목은 척축와 머리 사이에 있으며 보다 정교한 기능을 추출하는데 사용된다.
객체 감지를 위한 구조)
Input -> BackBone -> Neck -> Head -> Output
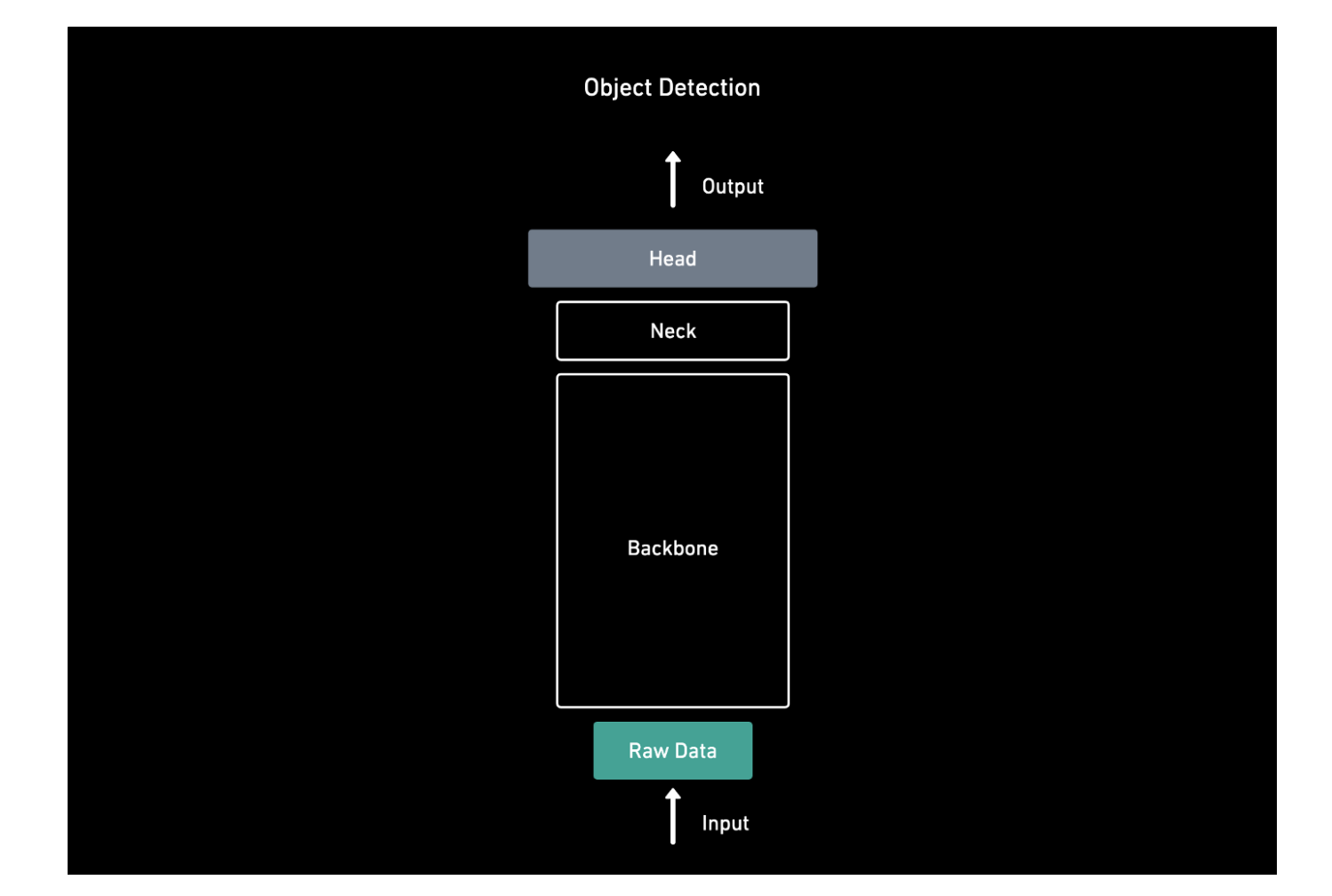
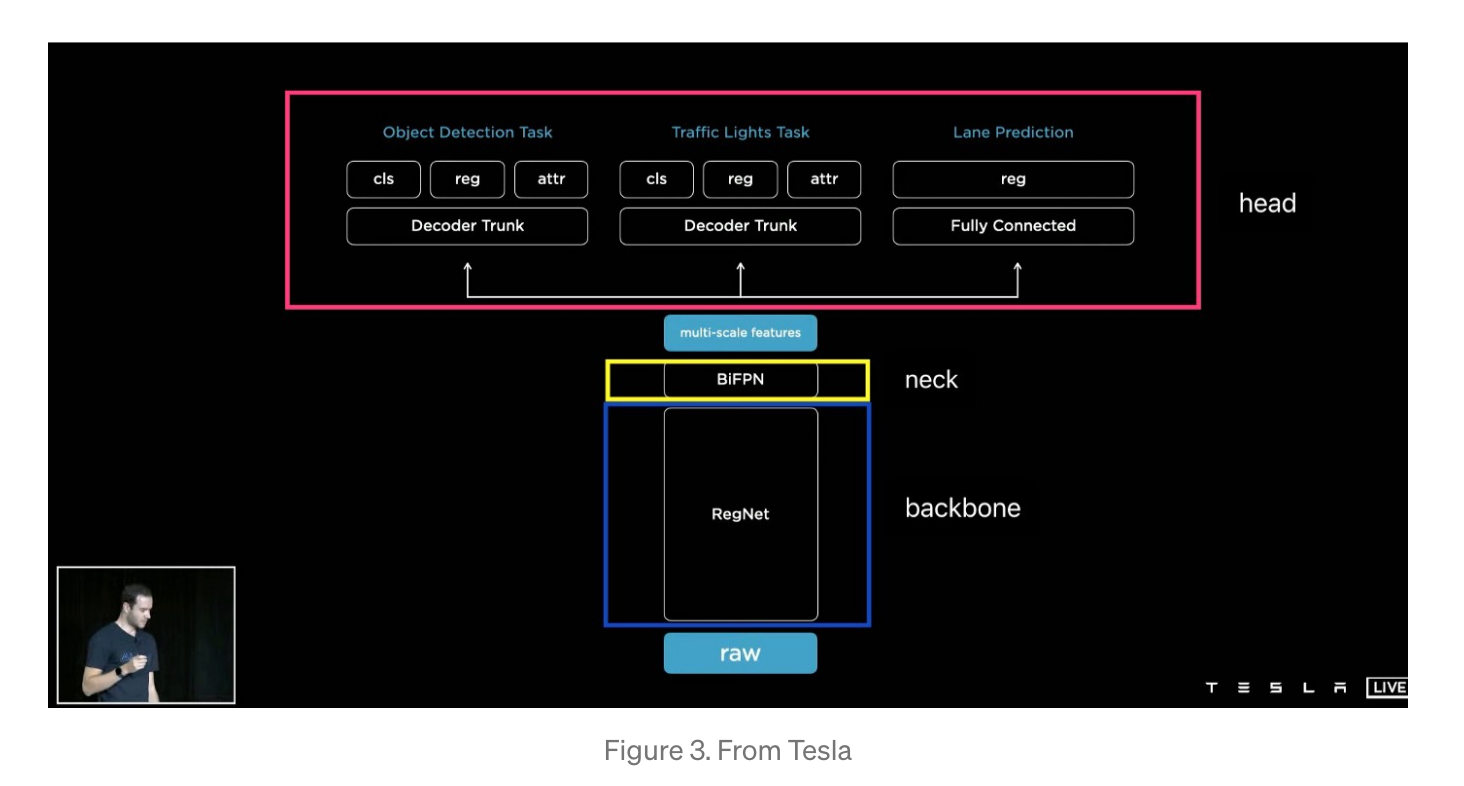
테슬라의 신경망 구조:
- backbone: RegNet + ResNet
- neck: BiFPN
- head: HydraNet
초기엔 AlexNet, VGG, ResNet, DenseNet과 같은 수동으로 설계된 일부 네트워크를 백본으로 사용했다. 이후에 데이터의 규모와 네트워크가 깊어지자 반자동 네트워크 및 자동화 네트워크 설계하는 것으로 고해하기 시작함. (AutoML과 NAS이다.)
그럼에도 한계는 존재했고, 이후 테슬라는 Residual neural network block으로 디자인된 RegNet을 사용한다.
"RegNet"은 2020 Facebook AI Research paper인 Designing Network Design Spaces에서 디자인 패러다임으로 대표되는 새로운 네트워크이다.
왜 썼을까?
1. nice design space.
2. Trade-off latency and accuracy.
RegNet
초기 설계 공간인 AnyNet
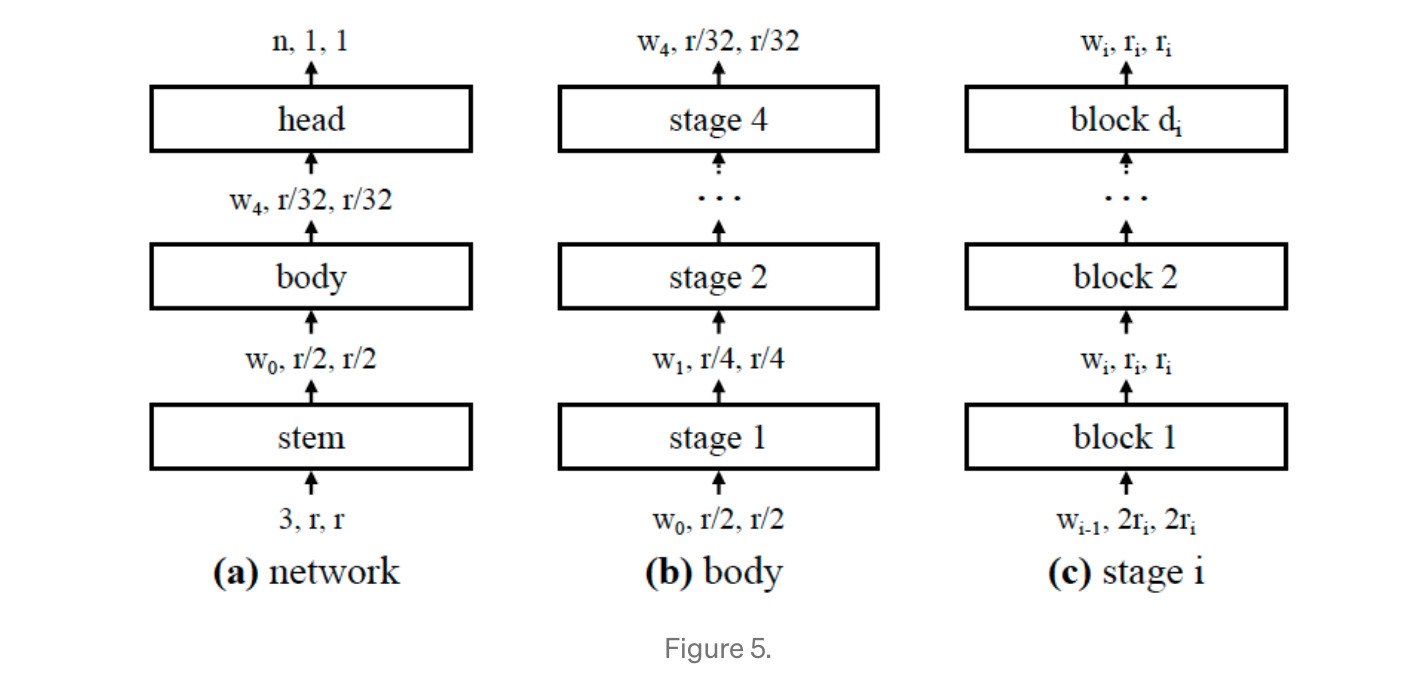
이 네트워크는 3가지 파트로 나뉜다.
-
Stem(줄기):
이미지를 처리하고 해상도를 절반으로 줄이기 위해 컨볼루션(kerner_size = 3, stride = 2, w0 = 32 output channels)을 사용한다. -
Body:
이 신경망 바디는 해상도를 진보적으로 줄이기 위한 오퍼레이션의 시퀀스한 stage로 구성되어 있다. -
Head:
출력 클래스를 예측한다. -
Stage:
같은 사이즈의 출력 맵을 생성하는모든 컨볼루셔널 레이어는 동일한 네트워크 단계에 있다.

X블록은 그룹 컨볼루션이 있는 표준 잔차 병목 현상을 기반으로 한다.
디자인 공간의 디자인 프로세스는 주로 네트워크의 본체 구축을 기반으로한다.
...
신경망 백본 처리 후 RegNet은 다양한 규모의 다양한 해상도에서 여러 기능을 제공한다. 이 기능 추출 네트워크에서 맨 아래에는 매우 낮은 채널 수가 있는 매우 높은 해상도가 있고 맨 위에는 높은 채널 수가 있는 낮은 해상도가 있다.
따라서 하단의 뉴런은 이미지의 세부 사항을 조사하는데 사용되며 상단의 뉴런은 scene context(sementic)정보를 이해하는데 사용된다. 다양한 스케일과 해상도의 이러한 기능은 다음 프로세싱인 feature pyramid network로 들어가게 된다. -
Feature pyramid networks(Neck)
초기 object detection 알고리즘은 보통 직접적으로 백본의 마지막 스테이지에 있는 마지막 레이어의 피쳐 맵디텍션 헤드에 연결한다.?
오브젝트 디텍션 업무에서는 shallow networks(네트워크의 하단)은 해상도가 높아 이미지 디테일 학습하는데 좋고, deep network(네트워크 상단)은 해상도가 낮아 semantic learning에 좋다.
하나의 피쳐 맵에서 동시에 다른 스케일의 오브젝트를 효과적으로 식별하기 어렵다는 것을 알게 됐다.
그러므로, 다른 스테이지의 피쳐 맵은 피쳐 피라미드 네트워크를 형성하여 다른 스케일의 개체를 특성화한 다음 특징 피라미드를 기반으로 개체 감지를 수행한다.

