NLP 및 추천시스템
1.[추천시스템]TF-IDF란?

특정 문서 내에서 특정 단어의 빈도인 TF(Term Frequecy) 와,전체 문서 내에서 특정 단어의 빈도인 DF(Document Frequency)의 역수를 활용하여 어떠한 단어가 얼마나 중요한지를 나타낸 통계적 수치!이 문서에는 자주 등장하고,다른 문서에는 덜 등
2.[추천시스템]정보 필터링 3가지
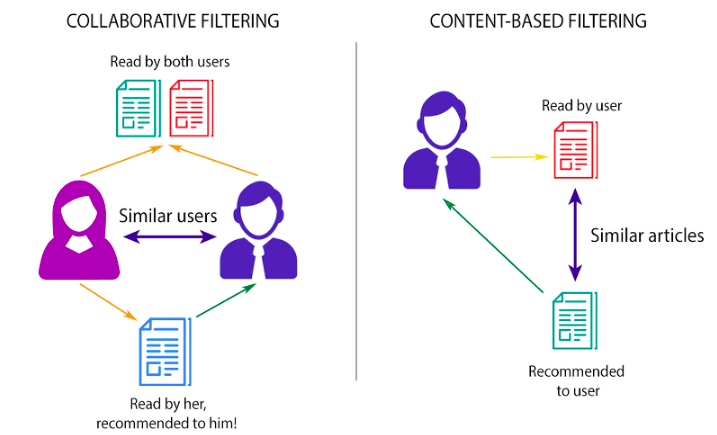
유저가 소비할만한 아이템을 예측하는 모델출처 : https://brunch.co.kr/@torch010/20비슷한 경로를 따라간 다른사람의 취향으로 추천 MF, KNN 알고리즘 활용 intuitive High computatial power, Cold sta
3.[추천시스템]Matrix Factorization이란
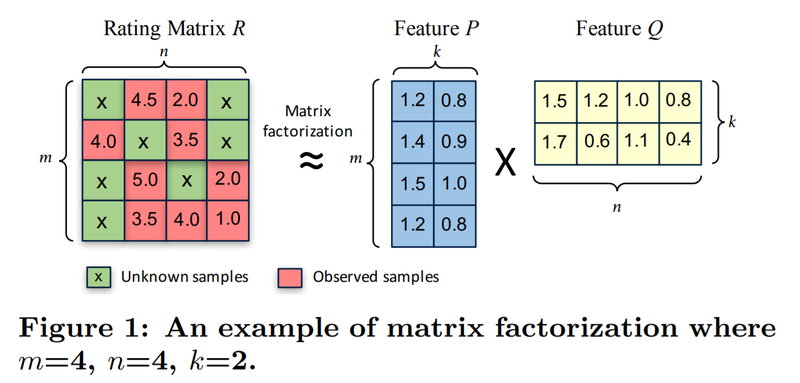
추천시스템 알고리즘 중 하나인 MF에 대하여 공부해 봅시다.\- 출처: CuMF_SGD: Fast and Scalable Matrix Factorization(https://arxiv.org/pdf/1610.05838.pdf)핵심 : (m,n) 사이즈의 행렬
4.[추천시스템]CSR Matrix란
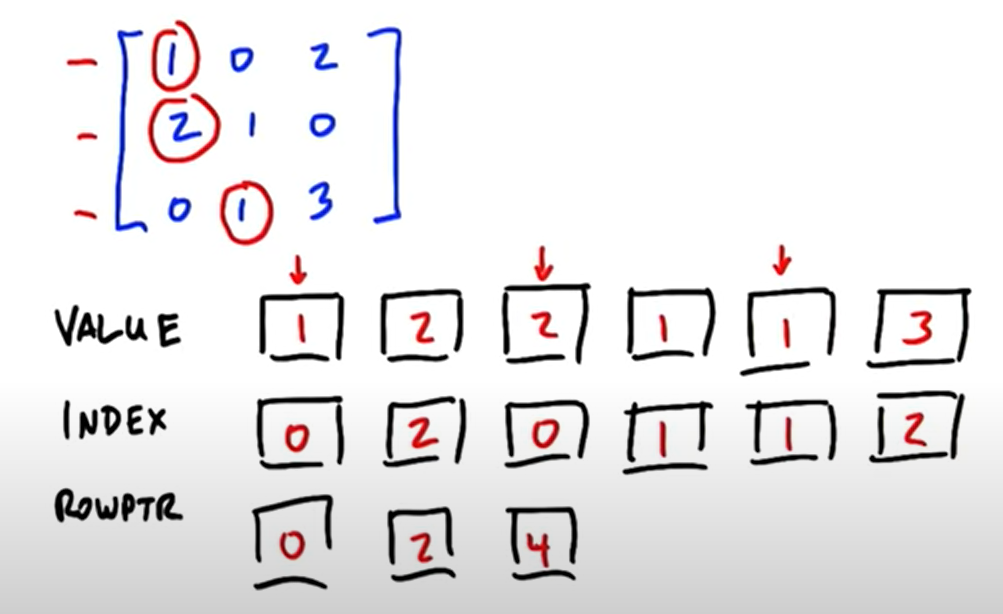
Matrix Factorization 과정에서 m과 n이 너무 크면, 대부분의 원소가 0인 Sparse Matrix가 될 확률이 높고 이것은 메모리를 너무 차지하는 비효율적인 구조가 됩니다.이를 위해 필요한 것이 바로 CSR(Compressed Sparse Row) M
5.[NLP]검색랭킹 모델링이란?
일반적으로 텍스트(키워드)의 형태로 유사도가 높은 문서를 찾아 차례로 노출해주는 시스템Slope one (Collaborative Filtering) \- 다른 사람들과 다른 아이템에 대한 정보를 이용하여 특정인의 특정아이템에 대한 정보를 추정 \- 아마존의 상품 추천
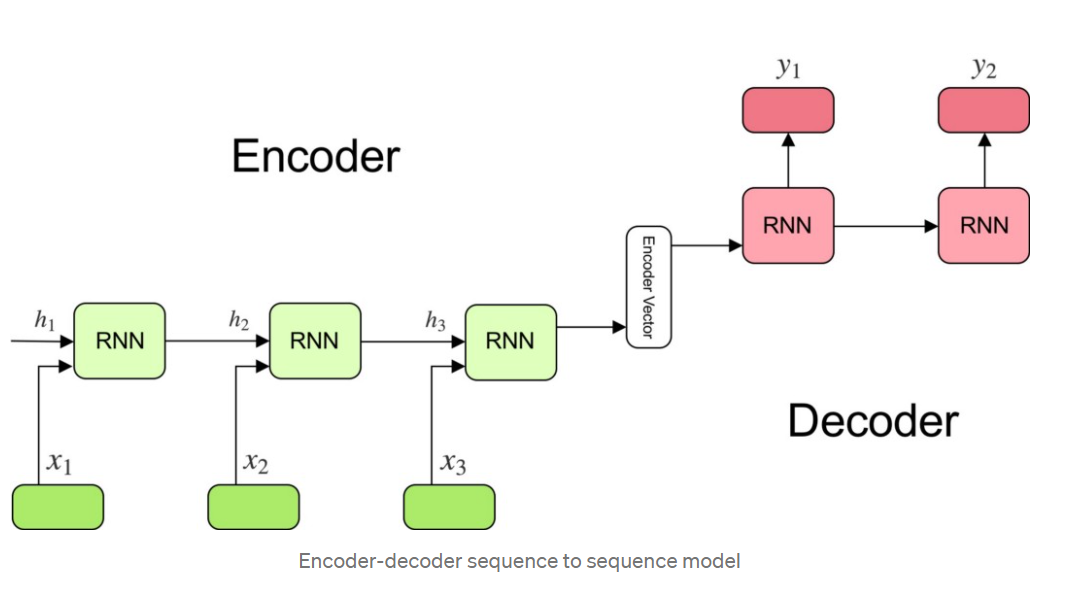
6.[NLP]Seq2Seq란
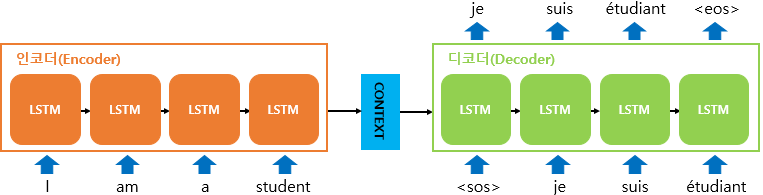
문제의식 1) RNN은 Vanishing gradient 문제가 있음(물론 이건 LSTM으로 개선되긴 했음) 2) 번역에 적용되기 어려움. RNN처럼 순차적으로 output을 내면, 언어별로 어순도 다르고, output 길이가 input 길이와 같다는 보장도 없음. -
7.[NLP]Transformer : Attention is all you need 샅샅이 파헤치기
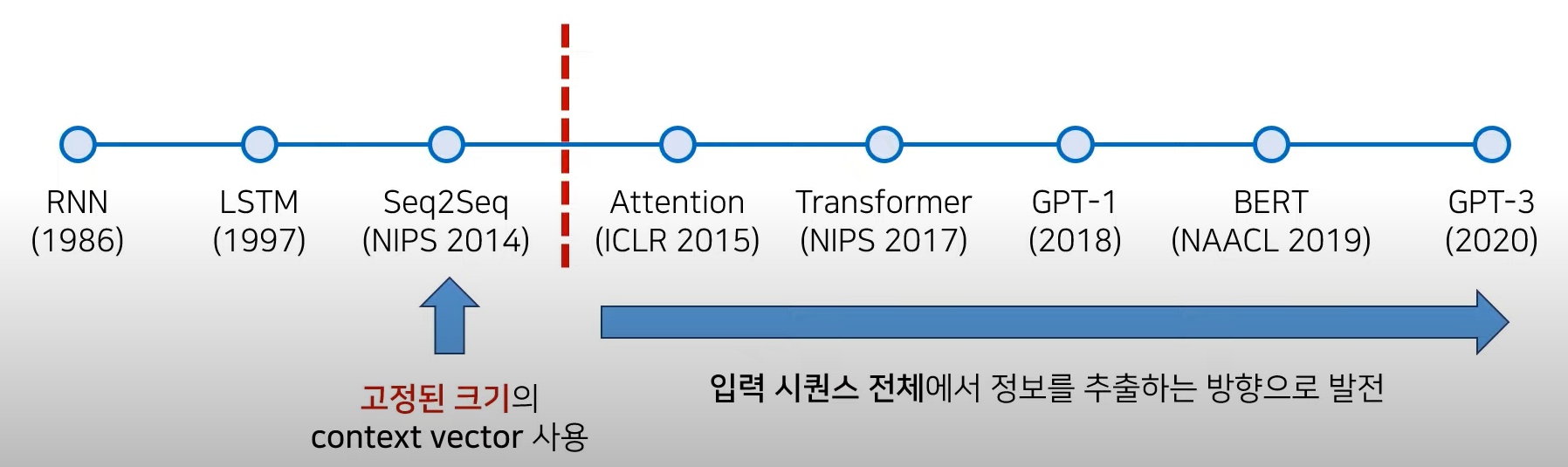
이 글은 아래 영상을 참고하여 재구성하였습니다.https://youtu.be/AA621UofTUASeq2Seq의 성능적인 한계Transformer로 비약적인 성능 향상 이룩 → 이후 Attention 기법을 많이 사용하게 됨Attention 이후에는 입력 se
8.[NLP]ELMo란

https://www.theguardian.com/media/2020/jun/10/fox-news-sesame-street-elmo-tucker-carlsonElmo는 옛날 TV 캐릭터의 이름을 따서 지었다. 기존에는 단어 그 자체에 집중하여 word embe
9.[추천시스템][ML] 평가지표(Evaluation metric) : MAP(Mean Average Precision)@m

$$MAP@12 = \\frac 1 U \\sum{u=1}^U \\sum{k=1}^{min(n,12)} P(k) \* rel(k)$$추천시스템의 evaluation Metric12개까지의 Average Precision을 전체 이용자수(U)로 mean한 값$\\sum
10.[NLP] Contextual Embedding(transformer

하나의 단어가 문맥에 따라 여러가지 벡터로 표현\-> ex) 눈 : snow, eye 등의 뜻이 있기때문에 하나의 임베딩 벡터로 표현하기엔 한계가 있음.Illustrtated TransformerIllustrated ELMo & BERTBERTviz : transfor
11.[NLP] Attention is all you need : Transformer 논문 제대로 읽기
이 글은 Attention is all you need)논문을 읽으며 내용을 정리한 글입니다. 논문을 직접 읽고 있는 그대로 해석하는 데에 집중하고자 했으며, Transfomer에 대하여 '이해'를 우선적으로 하고 싶은 분은 Transformer 논문 샅샅이 파헤치기
12.[NLP] Beam Search란?
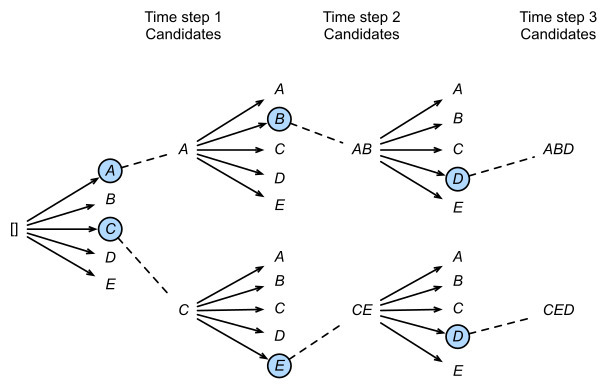
Beam Search :https://d2l.ai/chapter_recurrent-modern/beam-search.html평가값이 우수한(그림에서는 2개-1개) 일정 개수의 확장 가능한 노드만을 메모리에서 관리최상우선탐색 적용쉽게 이야기해서 Greedy Se
13.[NLP]Rouge score - Summarization의 평가 Metric

Recall-Oriented Understudy for Gisting Evaluationlabel(사람이 만든 요약문)과 summary(모델이 생성한 inference)을 비교해서 성능 계산ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S 등 다양한 지표가