복습 문제
1. outlier라는 데이터 프레임이 있다.
칼럼 중 score 가 5이상일 경우 NA를 할당하게 만드려면?
(ifelse 함수식 사용)
[답변] outlier$score <- ifelse(score>5, NA, score)
2. 데이터 프레임의 구조를 확인하는 기능을 하며, str보다 가독성이 더 좋은것은?
[답변] dplyr의 glimpse()
3. 결측치 확인을 위해 사용하는 함수는?
[답변] is.na()
4. 이상치를 영어로 하면?
[답변] outlier
5. 다음 코드를 실행시키면 평균값을 얻을 수 있나? (ox)
[답변] x
6. 열별 NA의 여부와 갯수를 쉽게 찾기위해 쓰이는 함수는?
[답변] summary()
7. ggplot 함수를 사용할 때 aes() 안에 X= 와 y= 이외에 지정할 수 있는 변수는?
[답변] color shape fill size
8. 결측치는 데이터 프레임에서 'NA'로 표시된다.
결측치가 있는 데이터를 변형하지 않고 총합을 구하는 단계에서 사용할 코드로 가장 적절하지 않은것은?
1) na.rm = T
2) na.omit()
3) sum()
4) table()
[답변] 3
9. airquality에서 Solar.R열의 평균을 구하시오
[답변]
1) mean(airquality$Solar.R, na.rm = T)
[1] 185.9315
2) summary(airquality)
10. 월별 오존 농도와 기온을 나타내는 산점도를 그리시오
[답변] ggplot(airquality, aes(x=Month, y=Ozone, color=Temp)) + geom_point()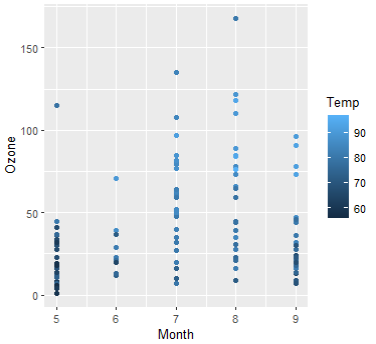
11. 산점도 색이 안예쁘다. 색을 그라데이션으로 말고 각각 나오게 바꿔봐라.
[답변] 숫자형으로 되어있는 값을 문자형으로 변환해본다.
ggplot(airquality, aes(x=Month, y=Ozone, color=as.character(Month))) + geom_point()
-> as.character 보다는 as.factor로 변환해서 뽑아내는게 더 맞다.
12. airquality에서 Solar.R 결측치인 데이터만을 출력하시오
[답변] > airquality %>% filter(is.na(Solar.R)) %>% filter(!is.na(Ozone))
Ozone Solar.R Wind Temp Month Day
1 28 NA 14.9 66 5 6
2 7 NA 6.9 74 5 11
3 78 NA 6.9 86 8 4
4 35 NA 7.4 85 8 5
5 66 NA 4.6 87 8 6
13. mpg에서 도시연비와 고속도로 연비의 "평균연비"를 만들고,
평균연비가 11이하 37이상인 관측치는 NA로 값을 바꾸세요
[답변]
mpg1 <- mpg %>% mutate(평균연비 = (cty+hwy)/2)
mpg1$평균연비 <- ifelse(11>mpg1$평균연비|37< mpg1$평균연비, NA, mpg1$평균연비)
14. 위에서 추가된 평균연비에는 NA가 몇개 있는지 확인하려면?
[답변] table(is.na(mpg1$평균연비))
15. 평균연비에서 이상치를 제외한 '평균연비'의 평균을 구하세요
[답변]
식:mean(mpg1$평균연비, na.rm = T)
답:20.19604🍃 라벨달기
데이터 만들기
> g <- ggplot(mpg, aes(x=displ, y=hwy)) +
geom_point(size = 3, aes(color = drv)) +
theme_economist()
> # theme_economist() : 바탕색 지정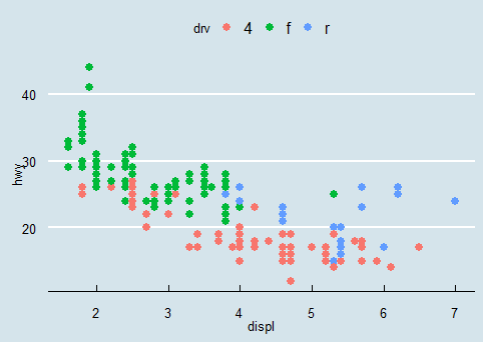
> # 라벨달기
> g + labs(title="<배기량 연비비교>")
> x와 y에도 달아주기 당연 가능
> g + labs(title="<배기량 연비비교>", x="배기량", y="고속도로 연비")
> g + labs(title="배기량 연비비교") +
xlab("배기량") + ylab("고속도로 연비")
> # 위아래 같은 결과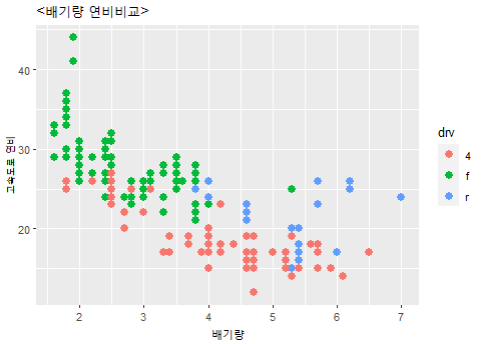
🍃 facet
facet_grid
면을 나눠서 여러가지 그래프를 한번에 보고 싶을 때 사용한다
> g + facet_grid(drv ~ cyl)
> # 클래스에 따라 산점도를 출력하세요
> p <- ggplot(mpg, aes(displ, hwy)) + geom_point()
> p + facet_wrap(vars(class))
> # p + facet_wrap(~ class) 도 동일 결과
facet_wrap
- grid와 동일하게 여러 그래프를 한 화면내에서 보고싶을때 사용. 단, 실행 결과 화면에서 보이는 행열의 갯수를 조절할 수 있다는 점에서 차이가 있다.
- 범주형 데이터, 행 또는 열의 개수가 많은 데이터를 시각화할때 사용하는 듯 하다.
> p <- ggplot(mpg, aes(displ, hwy)) + geom_point()
> p + facet_wrap(~ class, nrow = 2)
> p + facet_wrap(~ class, ncol = 2)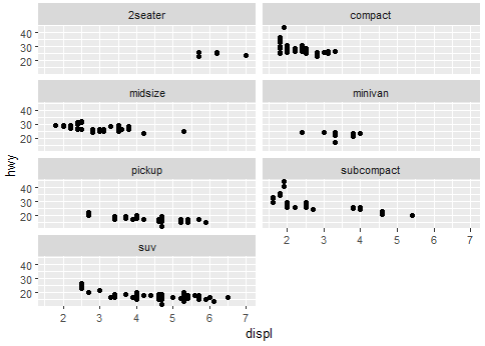
--------
🍃 jitter
- 지터(jitter)는 데이터 값에 약간의 노이즈를 주는 것이다. 데이터를 시각화 할때 같은 값을 가지는 데이터가 그래프에 여러 번 겹쳐서 하나만 있는 것 처럼 표시되는 현상을 막아준다.
- 예를 들어
10개 있는 값 10과100개 있는 값 20은 양의 차이가 나지 않는가. 그런데 시각화하면 두 값 모두 점 하나로 겹쳐서 보이기 때문에 그래프만 보면 어떤값이 더 많은지 알 수가 없다. 이럴때 노이즈를 추가(jitter)하면 데이터 값이 조금씩 움직이며 데이터가 몰리는 점이 더 쉽게 파악됨
방법 1. geom_ponit(옵션으로 position = "jitter")
> g <- ggplot(mpg, aes(x=displ, y=hwy, color = drv)) +
+ geom_point(size = 3, position = "jitter")
> g
방법2. geom_jitter() 사용
> # height 인자는 높이조정 - 점이 흩뿌려지는 높이
> # width 인자는 너비조정 - 점이 흩뿌려지는 너비
> g <- ggplot(mpg, aes(x=displ, y=hwy, color = drv)) + geom_point(size = 3)
> g + geom_jitter(width = 0.5, height = 05)
> g + geom_jitter(width = 2, height = 2)
> # x축과 y축을 보면 점 흩뿌려지는 정도가 달라진걸 확인 가능
🍃 geom_line()
값이 이어진 선 형태로 보여준다
> ggplot(economics, aes(date, unemploy)) + geom_line()
> g <- ggplot(mpg, aes(x=displ, y=hwy, color = drv)) + geom_line()
> g
> # 선 굵기 조절도 가능
> g + geom_line(size = 1)
># 선의 종류를 지정해 줄 수도 있다.
># geom_line(linetype =)
> # 예시
> ggplot(mpg, aes(x=displ, y=hwy, color = drv)) + geom_line(linetype = 3)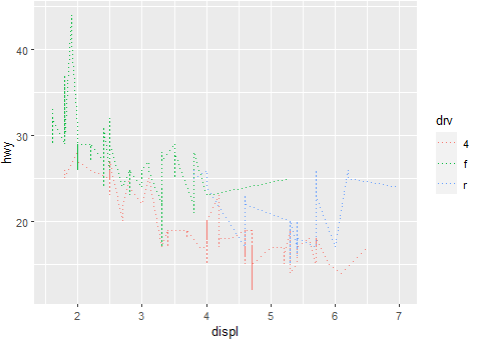
🍃 geom_bar()
연속된 값들을 바형태로 보기에 적합하다
> ggplot(data=mpg, aes(x=drv)) + geom_bar()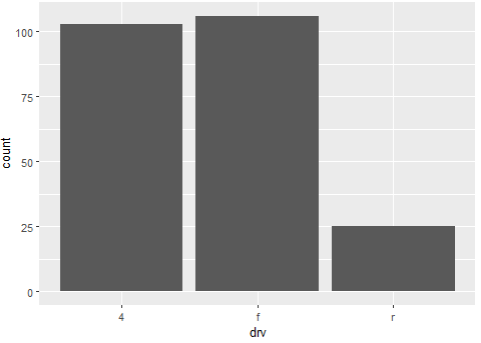
ggplot(data=mpg, aes(x=class)) + geom_bar()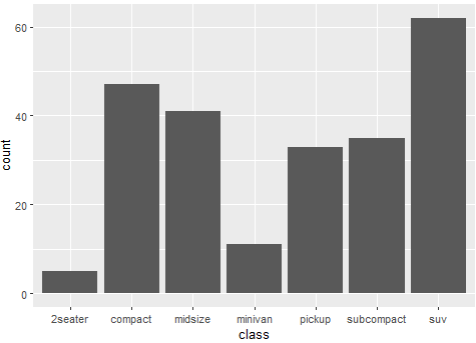
색 넣기도 가능하다
> ggplot(mpg, aes(x=class))+ geom_bar(color="red", fill="white")
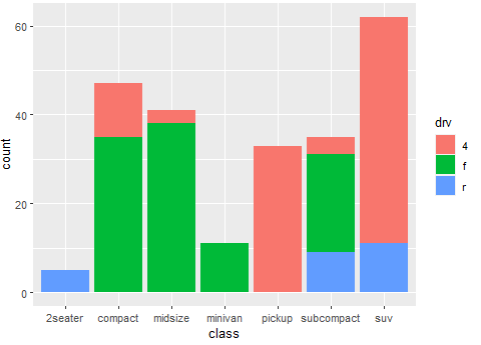
> ggplot(mpg, aes(x=class, fill=drv)) + geom_bar()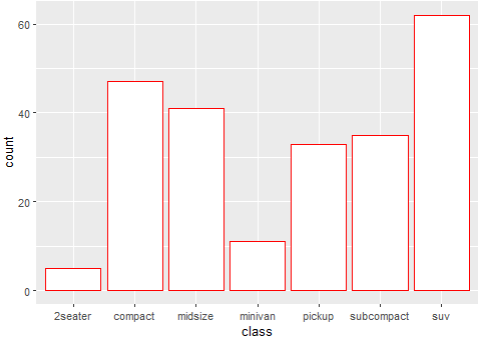
🧃 position = fill, aes(fill=)
- aes(..., fill = )
- aes는 자료의 데이터를 기반으로 한 그래프틀을 무엇으로 할지 정해줄때 사용하는 함수이고, class는 mpg안의 데이터
→ 아래 예시는 fill 함수를 aes안에 써줌으로써 mpg안의 데이터인 class에 색상이 지정되어 drv위에 입혀진것이다
- position = fill
말 그대로 막대 그래프를 화면에 꽉 채워서 x값 내 데이터의 상대적인 비율을 나타낼 때 쓴다고
→ 아래 예시는 mpg 자료 내에서 drv에 따른 class의 비율을 나타낸 그래프인 것이다
ggplot(mpg, aes(x=drv, fill=class)) +
geom_bar(position = 'fill')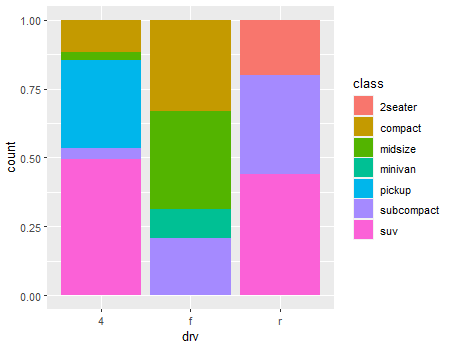
🧃 position = dodge
- 막대의 위치를 개별적으로 나란히 표현하라는 명령어
- fill 혹은 color 함수를 이용해 반드시 표시할 막대의 데이터를 구분지어 줘야 한다.
- class를 x축으로 잡고 drv데이터를 나란하게 표시해라
ggplot(mpg, aes(x=class, fill=drv)) +
geom_bar(position = 'dodge')
geom_bar() 안에 들어가는 position들은 한 함수에 한번만 설정이 가능
position='dodge', position=fill은 불가능하다
> ggplot(mpg, aes(x=class)) +
+ geom_bar(position = 'dodge', position = "fill")
Error in geom_bar(position = "dodge", position = "fill") :
formal argument "position" matched by multiple actual arguments🍃 geom_histogram()
- 연속형 데이터에 대해 그릴때 사용하는 함수
ggplot(mpg, aes(x=displ, fill=drv)) +
geom_histogram()
ggplot(mpg, aes(x=displ, fill=drv)) +
geom_histogram(stat = 'count')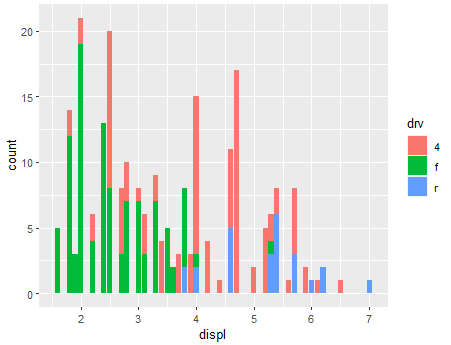
+) geom_bar() vs geom_histogram()
- bar : 범주형 데이터를 시각적으로 표시한다
예) 빨강, 검정, 갈색 머리를 가진 사람들의 수
각각의 x값은 서로 다른 요인
∴ 막대 사이에 공백이 있다
- histogram : 간격, 데이터의 밀도를 표시하는 데 사용됩니다
예) 나이의 분포, 키의 분포
하나의 연속적인 데이터와 하나의 범주형 데이터에 대한것으로 일반적으로 연속데이터를 x축에 배치하고 범주형 데이터를 y축에 배치*** 아래 문제의 이유는?
> # 이건 나오는데
ggplot(mpg, aes(x=class)) +
geom_histogram(stat = 'count')
> # 이건 오류뜨는 이유는
> ggplot(mpg, aes(x=class)) + geom_histogram()
Error in `f()`:
! StatBin requires a continuous x variable: the x variable is discrete.Perhaps you want stat="count"?
→ 오류메시지를 읽어보면
geom_histogram()에는 연속적인 x변수가 필요한데 현재 x변수는 이산형이기 때문으로 보인다.
→ 히스토그램은 한 변수의 데이터를 일정한 수의 bin으로 나눈후
해당 bin에 속하는 숫자 등을 세서 그래프를 그린다.
이경우 x축은 그 변수의 bin 값(ex.구간값)들이고 y축은 count 수가 되는데, 이 count는 원래 데이터셋에는 없던 변수이다.
🧃 막대기 넓이조절
ggplot(mpg, aes(x=displ)) + geom_histogram(binwidth = .5)
ggplot(mpg, aes(x=displ)) + geom_histogram(binwidth = 10)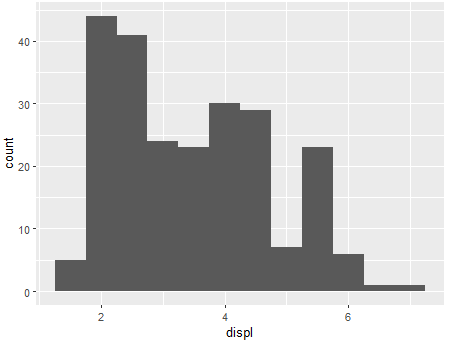
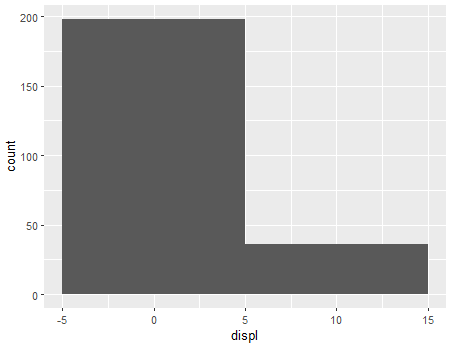
🧃 막대기 갯수
ggplot(mpg, aes(x=displ)) + geom_histogram(bins=3)
ggplot(mpg, aes(x=displ)) + geom_histogram(bins=10)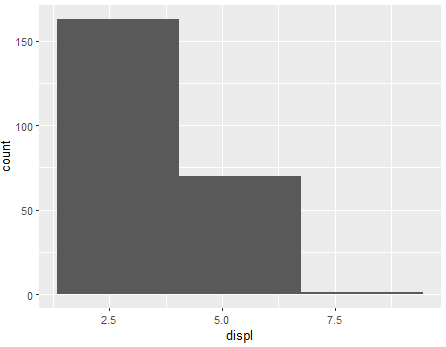

+) 열 = column = ... =
열 = column = 변수 = variables = 특성 = 속성 = attribute = feature
행 = row = observation = 관측치
+) 범주형 데이터를 시각화할때는
point로 하면 분석이 어려울 수도 있다.
아래 예시처럼 같은 값은 한 점으로 겹쳐서 표시되는 point보다 다른 좋은 것들이 많다
ggplot(mpg, aes(drv, hwy)) + geom_point()
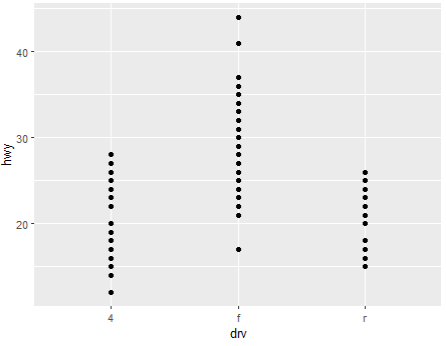
ggplot(mpg, aes(drv, hwy)) + geom_boxplot()
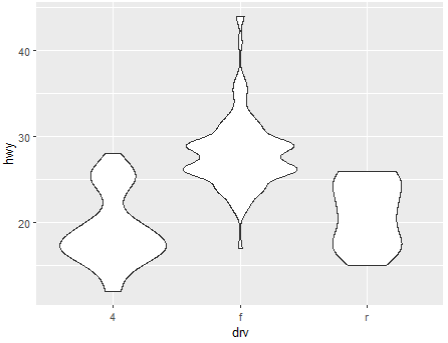
ggplot(mpg, aes(drv, hwy)) + geom_violin()
+) 문제 하나 풀기
> # 구동방식(drv)별로 도시 주행연비(cty)의 평균을 막대그래프로 나타내보세요
> ggplot(mpg, aes(drv,mean(cty))) + geom_col()
> # 제조사 별로 구동방식에 따른 주행연비 평균을 막대그래프로 나타내보시오
mpg1 <- mpg %>% group_by(manufacturer, drv) %>% summarise(mean(cty))
str(mpg1)
ggplot(mpg1, aes(drv, cty, fill= manufacturer)) +
geom_col(position= 'dodge')
> # 근데! 조건과 ggplot을 나누지 않아도 된다!
하나로 이어서 적어주면 되는데
이때, 데이터셋을 이미 앞에 적어놨기 때문에 ggplot에 data를 안적어줘도 ok!
mpg %>% group_by(manufacturer, drv) %>%
summarise(c=mean(cty)) %>%
ggplot(aes(x=drv, y=c, fill=manufacturer)) +
geom_col(position = 'dodge')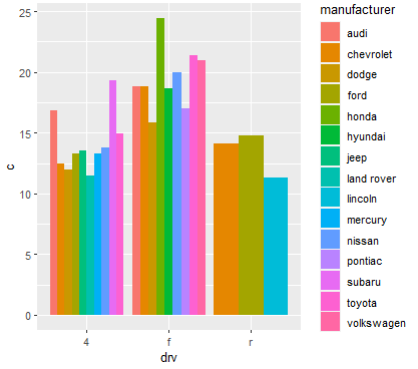
근데 위 코드를 실행하면
`summarise()` has grouped output by 'manufacturer'. You
can override using the `.groups` argument.와 같은 문구가 출력된다. 친절하게 .groups 인수를 사용하여 재정의 해보라 했으니
mpg %>% group_by(manufacturer, drv) %>%
summarise(mean(cty), .groups = "drop_last") %>%
ggplot(aes(drv, `mean(cty)`, fill=manufacturer)) +
geom_col(position = 'dodge')이렇게 추가하면 더이상 위 문구는 출력되지 않는다. 이 옵션은 마지막 group 변수를 삭제한다는데..
아마도 내 생각으로는 group_by를 두 개로 묶어서 문제가 생길수 있다고 경고가 떴던거 같음. .groups = "drop_last" 옵션은 두번째 변수(drv)로 생긴 값을 버리겠다고 선언한거고. 그러면 문제가 생길 일이 없으니까.