
팀명 : 플러스우여곡절 길고 길었던 CV 프로젝트가 끝났다. 처음 접해보는 Deep Learning 프로젝트여서 순탄하게 진행되지 않았던 것 같지만 그래도 열심히 참여했던 CV 프로젝트 회고를 작성해보고자 한다.
1. 프로젝트 개요
A. 개요
이번 대회는 computer vision domain에서 가장 중요한 태스크인 이미지 분류 대회이다.
이미지 분류란 주어진 이미지를 여러 클래스 중 하나로 분류하는 작업이다. 이러한 이미지 분류는 의료, 패션, 보안 등 여러 현업에서 기초적으로 활용되는 태스크이다. 딥러닝과 컴퓨터 비전 기술의 발전으로 인한 뛰어난 성능을 통해 현업에서 많은 가치를 창출하고 있다.
그 중, 이번 대회는 문서 타입 분류를 위한 이미지 분류 대회였다. 문서 데이터는 금융, 의료, 보험, 물류 등 산업 전반에 가장 많은 데이터이며, 많은 대기업에서 디지털 혁신을 위해 문서 유형을 분류하고자 한다. 이러한 문서 타입 분류는 의료, 금융 등 여러 비즈니스 분야에서 대량의 문서 이미지를 식별하고 자동화 처리를 가능케 할 수 있다.
제공된 데이터셋
- 총 17개 종의 문서로 분류되어 있는 1570장의 train data
- 총 17개 종의 문서로 분류해야 하는 3140장의 test data
주어진 데이터는 다음과 같았으며, 이번 대회는 test data 가 train data 보다 많다는 점이 의아한 점이었다. 또한 이번 data는 현업에서 사용하는 실 데이터를 기반으로 대회를 제작했다고 하여 기대감이 컸다.
B. 환경
-
팀 구성 및 컴퓨팅 환경
5인 1팀, 인당 RTX 3090ti 서버를 VSCode와 SSH로 연결하여 사용 -
협업 환경
Notion, GitHub -
의사 소통
KakaoTalk, Zoom, Slack, Discord
2. 프로젝트 팀 구성 및 역할
-
팀 구성
프로젝트 팀원으로 배정된 인원은 5명 이었다. 늘 함께하던 4명을 제외하고 한 분이 새로 들어오게 되었는데 이번에 들어오신 분은 참여도가 높으셔서 개인적으로 만족스러운 팀워크를 형성할 수 있어 좋았다.
-
역할
Task 목록은 다음과 같다.
데이터 확인 및 분류(Data Verification and Classification)
데이터 전처리 및 EDA(Data Preprocessing and Exploratory Data Analysis)
모델링 및 파라미터 튜닝(Modeling and Parameter Tuning)
결과 정리 및 보고서 작성(Summarization of Results and Report Writing)모두가 함께 모든 Task 에 참여했다. 하지만 우리 팀에 Computer Vision 쪽으로 연구를 오래 진행하셨던 분이 두 분이나 계셔 그 분들의 지식과 인사이트를 바탕으로 프로젝트를 진행하였다.
3. 프로젝트 수행 절차 및 방법
A. 팀 목표 설정
1주차 : 주어진 Upstage 강의 다 듣기, test 데이터 패턴 파악하기, base line code 이해하기
2주차 : Human Classification, 기존 데이터 탐색 및 파악하기(EDA 및 전처리)
3주차 : 모델링, 모델 튜닝, 최종 모델 완성
B. 프로젝트 사전 기획
(1) 협업 문화
- 특별한 일을 제외하고는 항상 모여서 의논하면서 Task 진행할 것(Zoom, Discord)
- 오프라인 모임이 가능할 경우 오프라인 만남을 적극 활용할 것(소통 Skill Up)
- 논의 사항 및 오류 사항이 있을 경우 즉각 팀원들과 상의할 것
- New 아이디어 발생 시 Team Notion에 작성 후 팀원 호출하여 해당 아이디어에 대해 공유할 것
- 말하지 않아도 각자 중간 진행 상황에 대해 틈틈이 보고할 것
우리팀의 좋았던 점은 별 일 없으면 항상 온라인 소통 플랫폼에 항상 접속해 있는 것이었다. 문제가 생기면 언제든 소통이 가능했고 좋은 아이디어가 생겨도 실시간으로 바로바로 소통이 가능했다. 이 점이 팀 프로젝트 결과물을 뽑아내는 데 중요한 요소였던 것 같다. 다른 팀 보다 늘 다양한 과정과 관점, 다양한 결과물을 완성시켰던 것 같다. EDA 프로젝트부터 Machine Learning 프로젝트, Machine Learning 대회, Deep Learning(CV) 대회까지 동일한 팀원들과 프로젝트를 진행 중인데 변하지 않고 이런 협업 분위기가 지속되고 있어 개인적으로 너무 만족스럽다. 새로 팀에 합류하신 분도 우리의 팀 분위기에 자연스럽게 녹아들어 임해주셔서 너무 감사한 마음이 들었다.
4. 프로젝트 수행 결과
Public - Human Classification(F1 score : 0.9885)

Private - Efficientnet-b4 (F1 score : 0.9061)

우리 팀은 Model 을 사용하여 학습 시키는 방법과 직접 우리가 분류하는 Human Classification 방법 2가지를 사용하였다. 자세한 Code 및 PPT 자료는 Github 에서 확인할 수 있다. 프로젝트를 진행하며 작성했던 회의록들도 Notion_FastCampus & Notion_Plus를 통해 확인할 수 있다.
[Human Classification]
데이터를 받고 모델 학습을 진행하기 전에 test data를 확인해보자 하는 의견이 나와 data의 형태를 파악하고자 하나하나 확인하던 과정 중에 '직접 분류해보는 게 어떨까?' 하는 생각이 들었다. 팀원 모두 비슷한 생각을 하고 있었고 우리는 우리가 직접 분류를 해보기로 하였다. 이 결과물을 제출하여 1등 해야겠다! 라는 마음보다는 human 분류를 하였을 때 정확도가 얼마나 나오는지 궁금했다. 그리고 직접 분류한 결과물을 활용하여 모델 학습 시킨 결과와 비교할 때도 유용하게 쓰일 것 같아 일단 분류를 직접하기 시작했다.
[Model 학습]
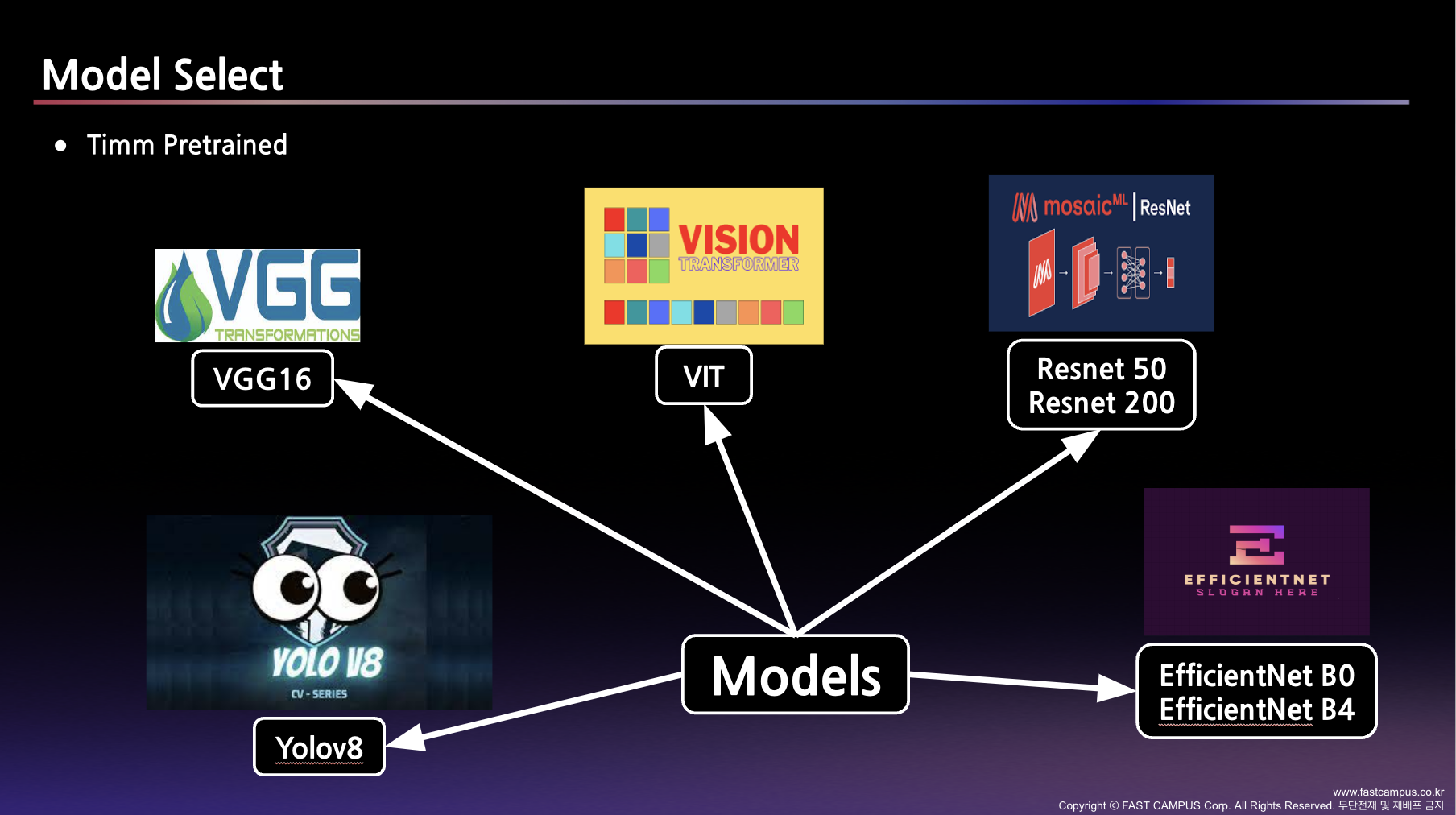
우리 팀은 다양한 모델을 활용하였다. CV에서 쓸 수 있는 모델은 다 써본 것 같다. 각 모델의 자세한 결과는 Notion 및 PPT에 자세히 기록해 뒀다.
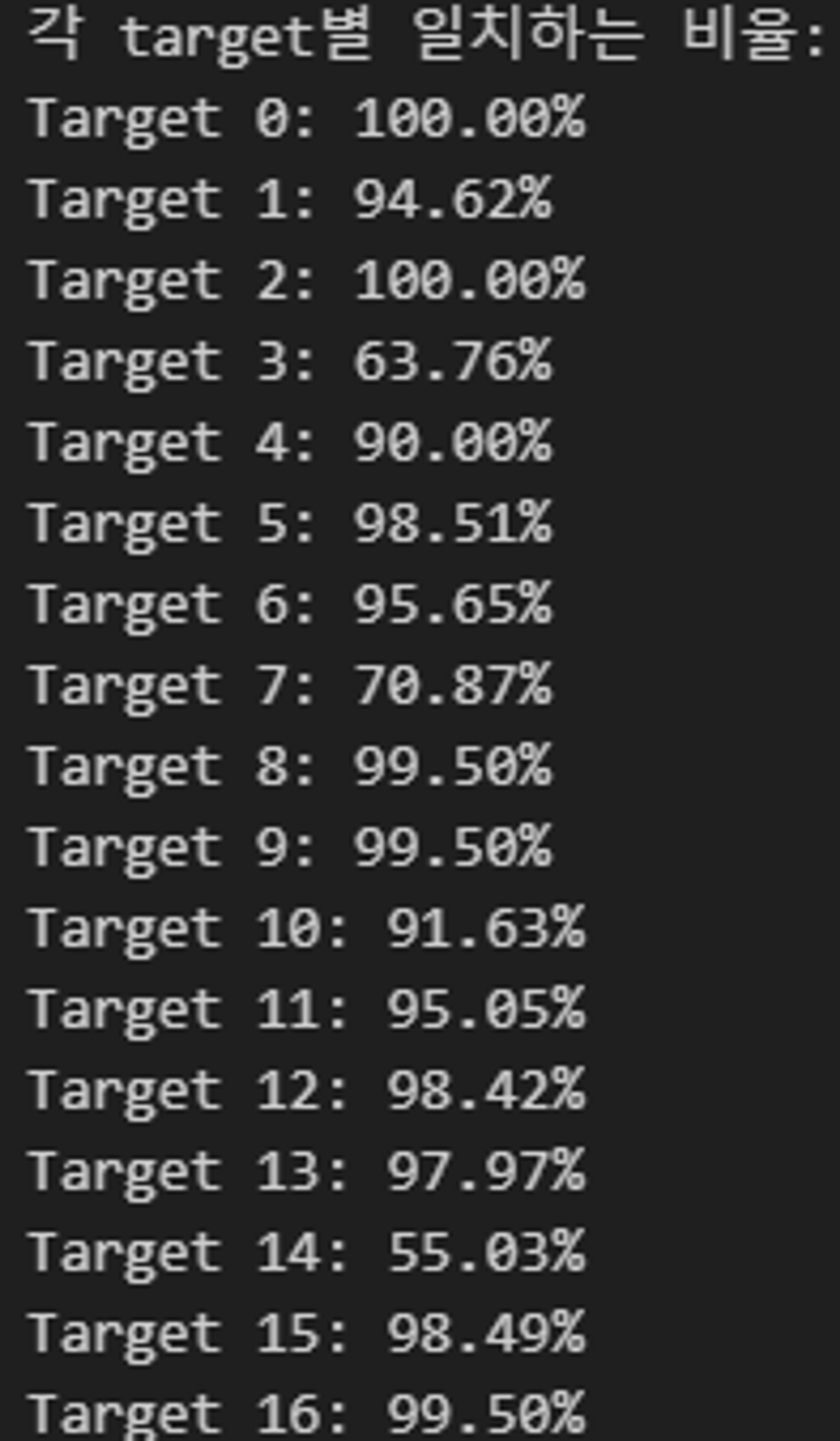
위의 모델을 사용하여 학습 된 결과를 Human Classification 한 결과와 비교하여 어떤 class에서 예측을 잘하고 못하는지 확인해보는 과정도 거쳤다.
5. 자체 평가 의견
A. 잘했던 점
- 다양한 방법으로 Augmentation을 진행하였다.
- 각자의 다양한 관점을 실시간으로 공유하여 함께 진행하는 프로젝트 분위기를 만들고자 하였다.
B. 시도 했으나 잘 되지 않았던 것들
- 강사님의 Feed back 을 통해 이 대회는 Augmentation이 중요한 대회임을 캐치하였다. 하지만 과도한 Augmentation으로 인해 서버가 터지는 이슈가 빈번하게 발생하였고, 모델 학습 시 1 epoch 을 돌리는데 2시간이 넘게 걸렸다. 결국 1500분을 투자하여 약 30 epoch 까지 학습을 시켰지만 결론적으로 서버가 터져 해당 모델을 사용할 수 없었다.
C. 아쉬웠던 점들
- 팀원 간의 수준 차이가 상당히 컸다. 나를 비롯한 3명의 사람들은 딥러닝 실전에 경험이 없는 사람이었으며, 나머지 2명은 딥러닝에 경험이 있는 사람들이었다. 그 분들과 대화를 하는 과정에서 의견 교류가 원활하게 되지 않았던 것 같다.
아마 그 분들이 엄청 답답했을 것 같다.
D. 프로젝트를 통해 배운 점 또는 시사점
- 이미지 분류를 어떻게 하는 건지에 대해 대략적으로 알 수 있게 되었다.
- 딥러닝 시스템이 어떻게 돌아가는 지에 대해 파악할 수 있던 시간이었다.
마무리
딥러닝은 강의도 처음이고 대회도 처음이고 모든 것이 처음이었던 분야라 사실 우왕좌왕 많이 했던 것 같다. 팀원 중 두 분이 어느 정도 경험이 있어 어깨 너머로 단어 하나하나 접해가며 천천히 배워과는 과정을 겪었던 시간이었던 것 같다. 이제는 어느 분야를 중점적으로 더 파고 들어야 하고 더 공부해야 하는 지 알게 되어 앞으로 그 부분을 중점적으로 더 공부해보고자 한다. 의료 AI 에 관심이 많기에 Computer Vision에 대해 더 열심히 공부해야 할 것 같다는 생각을 하였다.
#패스트캠퍼스 #UpstageAILab #Upstage #부트캠프 #AI #데이터분석 #데이터사이언스 #인공지능개발자 #ML #머신러닝 #경진대회 #딥러닝 #Computer Vision
