Experimenting With Different Models
scikit-learn's documentation에 들어가보면 Decision Tree model에서 활용할 수 있는 많은 option들이 있습니다.
Decision Tree의 depth를 10으로 하는 것은 범용적이지 않습니다.
- depth가 깊으면 너무 많은 leaf node들이 생겨서 각 leaf node들은 적은 수의 샘플을 가지고 있기 때문에 overfitting이 발생할 수 있습니다. (새로운 데이터 샘플을 예측할 때 제대로 예측하지 못할 수 있습니다.)
그렇다고 Decision Tree depth를 1 또는 2로 하게 되면 너무 큰 범위로 분류하기 때문에 학습 데이터로부터 중요한 특징이나 패턴을 포착하지 못합니다.
- 위의 경우 Decision Tree는 당연히 test 혹은 validation 데이터의 결과를 제대로 도출하지 못합니다. 이를 overfitting이라 합니다.
아래 그림은 Tree의 Depth에 따른 Error의 그래프이며 training dataset과 validation dataset에 대하여 그렸습니다.
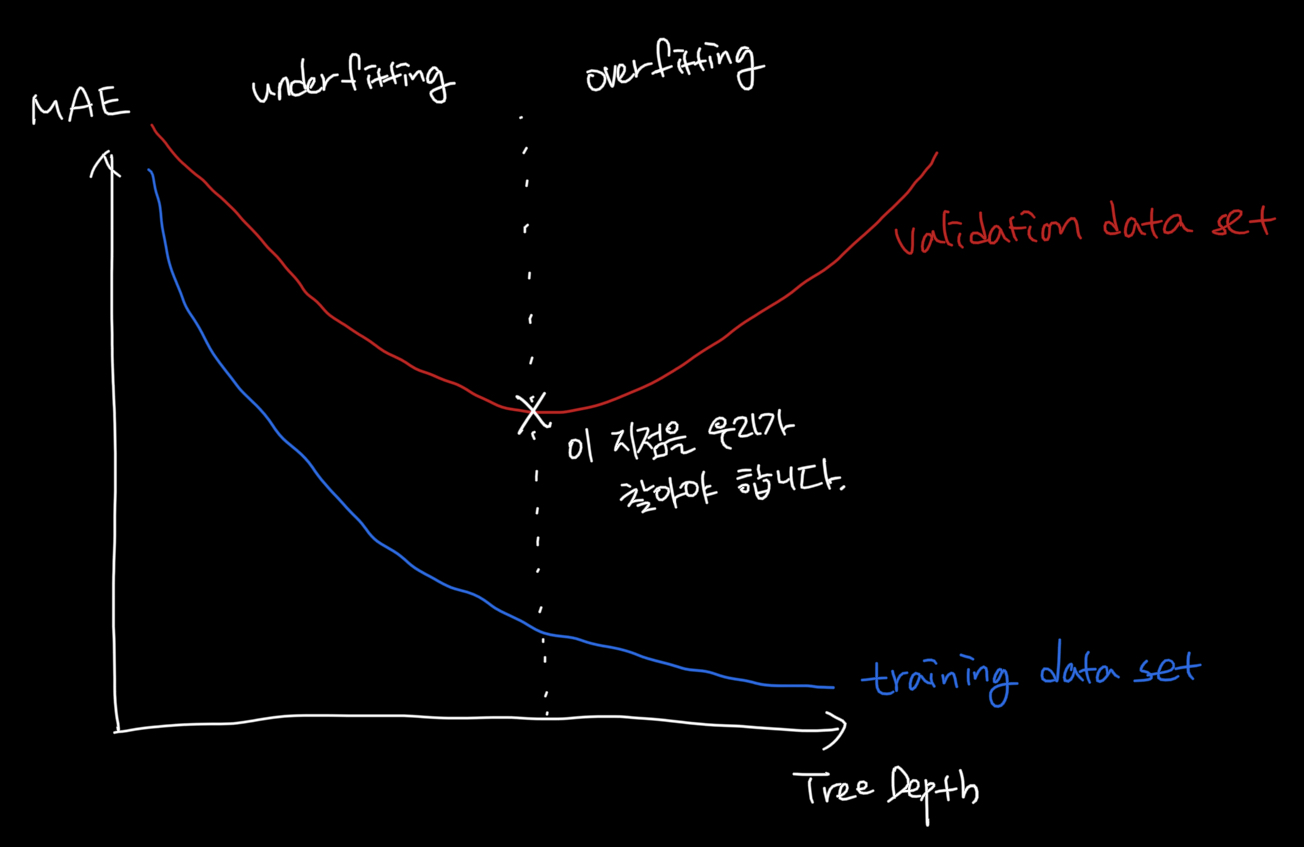
위 그림에 표현한 것처럼 우리는 validation dataset의 에러가 가장 적은 Tree Depth를 선택해야 합니다. 그래야 새로운 데이터(test data 혹은 new data)에서도 비슷하게 작동할테니까요.
Exercise
이번에는 코드로 직접 Decision Tree depth를 optimization 해봅니다.
Decision Tree의 leaf node 개수에 따른 MAE를 반환하는 함수를 작성해봅니다. (아래 코드)
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return maeStep 1: Compare Different Tree Sizes
candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500]
# 리프 노드 개수에 따른 mae를 maes에 저장합니다.
maes = []
for max_leaf_nodes in candidate_max_leaf_nodes:
mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
maes.append(mae)
# mae 값이 가장 작은 원소의 index를 찾습니다.
best_idx = maes.index(min(maes))
best_tree_size = candidate_max_leaf_nodes[best_idx]Step 2: Fit Model Using All Data
현재 우리는 Validation dataset에 대해서 가장 좋은 결과를 보여준 Decision Tree의 leaf nodes 수를 알고 있습니다.
해당 Decision Tree를 training dataset(train + validation)으로 학습합니다.
이유는 적절한 Decision Tree의 leaf nodes 수를 결정했으니 더 많은 데이터로 학습을 하기 위해서입니다.
final_model = DecisionTreeRegressor(max_leaf_nodes=best_tree_size, random_state=0)
final_model.fit(X, y)