
👉 0. 개요
본 문서에는 프로젝트에서 사용했던 모델에 대한 개인적인 이해와 학습을 진행하면서 직면한 문제점들, 그리고 그 문제점들을 어떻게 해결하려 했는지를 다룬다.
모델의 핵심적인 부분을 이 문서에서 소개했으며, 모델에 대한 전체 설명은
여기에 기술하였다.
👉 학습과 관련된 글로 바로 넘어가려면 옆 목차의 2. 1차 학습 후 💥 Class Imbalance 💥 문제을 눌러주시면 됩니다.
데이터 파트와 겹치는 부분이 있지만, 이 문서에서는 학습 관점을 중심으로 기술하려고 했다. 이 문서에서 사용하는 데이터셋의 용어는 이전 문서에서 쓰이는 용어와 동일하다.
직면했던 이슈들을 해결하기 위해 많이 찾아보고, 공부하고, 현업 선배님들에게 자문하는 등 정말 많이 고민할 수 있었고, 배울 수 있었던 좋은 시간이였다.
프로젝트 학습 과정에서 직면한 대표적인 이슈들은 다음과 같다.
💥 MAIN ISSUES 💥
- 심각한 클래스 불균형
- 성능 향상 정체
- 프레임워크의 한계 (Challenge)
- Valid_loss를 추출하려면 Train Augmentation과 Valid Augmentation을 동일하게 해야한다..
👉
3번 프레임워크의 한계에 대해서는 본 문서 마지막에 기술했다.
👉 1. What is Deformable DETR?
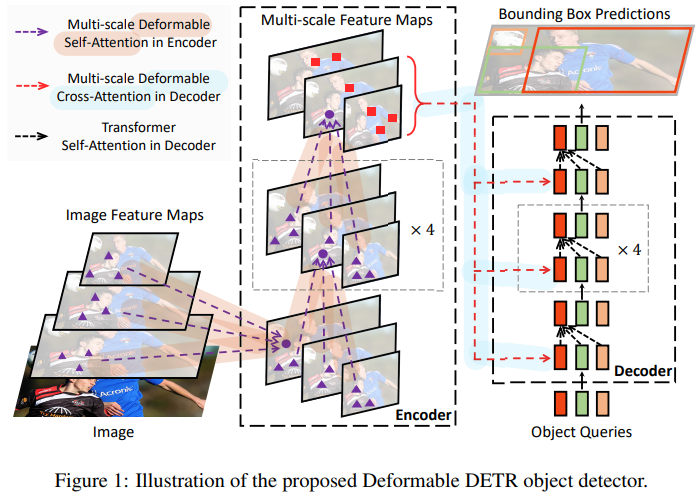
1.0 제안 배경
DETR은 Transformer의 Encoder-Decoder 구조를 따서 설계되었습니다.
그리고 many hand-designed components(post-processing : Anchor Generation, Rule-based Training Target Assignment, Non-Maximum Suppression) in object detection을 제거하기 위해 이분 매칭(Bipartite Matching)을 통해 Set Prediction Problem을 직접적으로(directly) 정의해서 해결하려 했습니다.
DETR은 더불어 최초의 fully end-to-end object detector로 소개되었습니다.
하지만, DETR은 Transformer의 특성상 slow convergence와 limitation of Transformer Attention modules in processing image feature maps으로 인한 limited feature spatial resolution으로 어려움을 겪고 있습니다.
이러한 이슈를 해결하기 위해서, Attention modules이 only attend to a small set of key sampling points around a reference하는 Deformable DETR을 제안했습니다.
Deformable DETR은 Deformable Convolution으로부터 영감을 받았고, DETR의 구조와 매우 비슷하지만, multi-scale과 DETR에서 사용하는 Transformer의 Attention 방식이 아니라 논문에서 제안된 Multi-Scale Deformable Attention 방식을 도입해서 사용합니다.
Deformable DETR은 DETR보다 작은 객체들에 대해 더 좋은 성능을 보였고, 10x less training epochs를 사용하였습니다.
1.1 DETR의 두 가지 이슈들
DETR은 Transformer 특성상 크게 2가지 한계점을 가지고 있습니다.
Slow Convergence
모델이 최적으로 수렴하기 위해서 기존 Object Detectors보다 매우 많은 Training epochs가 요구됩니다.
👉 극복하기 위해 Deformable Attention 제안됨
1. Sparse한 Attention이 아닌 Attention Mechanism이라고 하면 모든 input에 대해서 Attention 연산을 수행합니다.
- Query가 주어졌을 때, Key 값은 포함된 이미지의 모든 다른 픽셀들이 되는데 이렇게 되는 경우 DETR에서도 학습 시간이 굉장히 오래 걸리게 됩니다.
2. Attention이 Object Detection에서는 Attention Weight가 한 곳에 굉장히 포커싱을 해야 하는데, 처음에 Attention이 Uniform한 분포로 돼있기 때문에 포커싱을 하기까지가 굉장히 오랜 시간이 걸립니다.
- 전형적으로, 파라미터 초기화에서, (input query projection matrix at head) (input feature of query) and (input key projection matrix at head) (input feature of key)는 평균 0 & 분산 1인 분포 (uniform)를 따릅니다.
- 이것은 (number of key elements)이 클 때, attention weight ( : attention weight of query to key at head)이 key 수만큼 normalization 되는 값과 근사해집니다. ( )
- 이것은 input features에 대해 애매모호한 gradients를 야기하므로 attention weights가 특정한 keys에 포커싱하기 위해서는 긴 훈련 시간을 필요로 하게 됩니다.
- 이미지 분야에서는 Key elements가 보통 이미지 픽셀로부터 오는데, 픽셀이 엄청 많으므로, 수렴이 엄청 길어집니다.
Low Performance at small objects
DETR은 상대적으로 Small objects를 detect하는데 낮은 성능을 보여줍니다.
극복하기 위해 Multi-scale Deformable Attention 제안됨
1. High-resolution feature maps은 DETR에게 감당할 수 없는 복잡도를 일으킵니다.
-
현대 Object Detectors는 High-resolution feature maps로부터 작은 객체들이 detect되는 multi-scale features를 사용합니다.
-
하지만 high-resolution feature maps은 DETR의 Transformer Encoder에 있는 Self-attention momdule에게
Unaccpetable Complexity를 가져다줍니다.- 왜냐하면 이 module은 Input feature maps의 공간적인 크기 (픽셀 개수)에 따라 이차원적인(quadratic) 복잡도 증가를 하기 때문입니다.
The attention weights computation in the Transformer encoder is of quadratic computation w.r.t. pixel numbers.
- high-resolution feature maps를 처리하기 위해서 매우 높은 연산량과 메모리 복잡성을 가집니다.
- 그래서 limitation of Transformer Attention modules in processing image feature maps로 인한
limited feature spatial resolution으로 어려움을 겪고 있습니다.
- 왜냐하면 이 module은 Input feature maps의 공간적인 크기 (픽셀 개수)에 따라 이차원적인(quadratic) 복잡도 증가를 하기 때문입니다.
2. Single-Scale Feature Map from ResNet
-
DETR의 같은 경우 ResNet을 태워서 얻게 되는 feature map의 마지막 feature map을 사용합니다.
-
마지막 feature map 같은 경우, 작고 정교한 feature는 부족한 feature maps라고 할 수 있습니다.
-
이러한 특성 때문에 작은 물체에 대한 탐지 능력이 떨어지게 됩니다. (논문에서는 FPN 같은 걸 사용하면 이러한 한계점을 극복한다고 합니다.)
-
그래서 Deforamble DETR은 FPN은 아니지만 Multi-scale을 이용하게 됩니다.
1.2 Deformable Convolution
Deformable DETR은 Deformable Convlution Networks으로부터 영감을 얻었습니다.
일반적인 Convolution 연산은 고정된 크기의 kernel을 기반으로 수행되지만, deformable convolution은 feature를 특정 layer에 통과시켜 Sampling point를 예측한 후, 해당 point를 기반으로 convolution 연산을 수행합니다.
이미지 분야에서 Deformable Convolution Networks는 Sparse한 공간적인 위치에 접근하는데 매우 강력하고 효과적인 매커니즘입니다.
아래 이미지 예시와 같이 특정 위치의 object 들에 맞추어 sampling이 이루어지면서 고정된 크기의 kernel로부터 오는 한계점을 극복하는 것을 확인할 수 있습니다.
- 일반적인 CNN은 이미지의 물체가 아무리 크더라도 고정된 크기의 필터를 사용하기 때문에 Receptive Field가 커진다는 특성을 이용할 수 있지만, 큰 물체에 대한 탐지 성능이 떨어지는 한계가 있습니다.
- 이 문제를 극복하기 위해 Deformable Convolution Networks가 제안되었습니다.
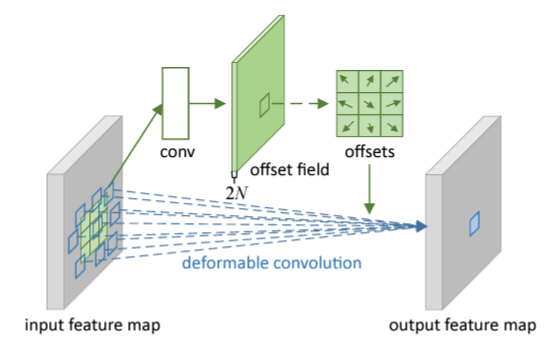
Deformable DETR의 경우 매우 비슷한 방법론이라고 할 수 있습니다.
- Kernel에 적용하는 게 아니고 Attention Mechanism을 적용할 때 이 Deformable Convolution Networks이란 방법론을 추가해서 적용합니다.
1.3 Multi-scale Deformable Attention
DETR의 경우 한 스케일 정보에 대해서만 global attention 연산을 수행합니다.
논문에서 제안된 multi-scale deformable attention module은 feature pyramid networks 도움 없이 attention mechanism을 통해서 자연스럽게 multi-scale feature maps을 종합할 수 있다고 합니다. (FPN 효과)
- Deformable DETR는 processing feature maps하는 Transformer attention modules를 대체하기 위해서
multi-scale deformable attention modules를 이용합니다.
제안된 multi-scale deformable attention module은
- 자연스럽게 multi-scale feature maps으로 확장이 됩니다.
- FPN과 같은 역할을 합니다.
- Feature Extraction 단계에서 ResNet에서 32,16,8 같은(: Level에 비례) 다양한 해상도의 feature maps을 추출한 다음에 각각의 feature map에서 추출한 sample key에 대하여 deformable attention 연산을 수행하게 됩니다.
- 각 level에서 얻은 sample keys를 모아서 한꺼번에 attention 연산을 수행하기 때문에 각 layer에 있는 각 키에 대한 attention score의 총합이 1이 됩니다.
- 따라서 Sampling 된 key 사이의 관계뿐만 아니라 여러 레벨의 feature maps들 사이의 관계와 정보를 포착하고 자체적으로 교환하게 됩니다
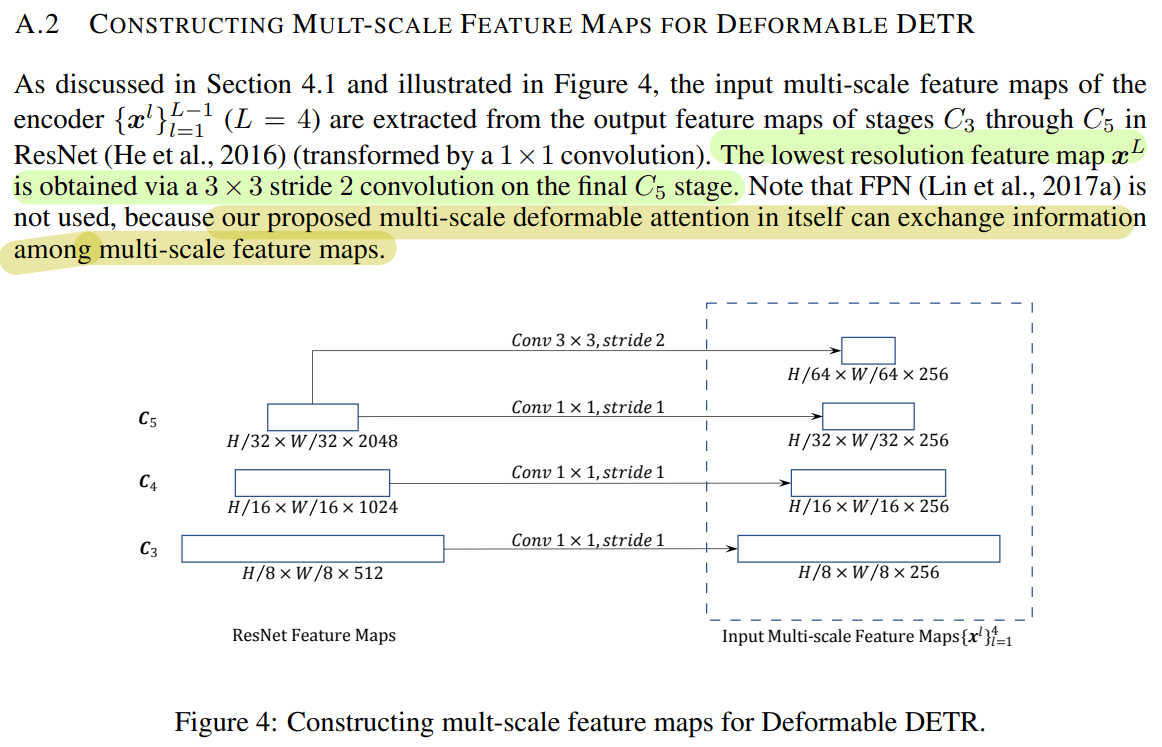
Deformable Convolution의 영향을 받았지만 다른 점이 있습니다.
- Single-scale version (deformable convoution)하고 매우 유사하지만,
multi-scale deformable attention module은 single-scale feature maps에서 추출한 지정된 개수의 sampling points(만 활용하는 대신에지정된 레벨의 개수(깊이)와 지정된 sampling points를 곱한 개수만큼을( Sampling 하는 점이 다릅니다.
- 다양한 크기의 feature maps과 level에서 나온 sampling points를 취합해서 FPN과 같은 효과를 냅니다.
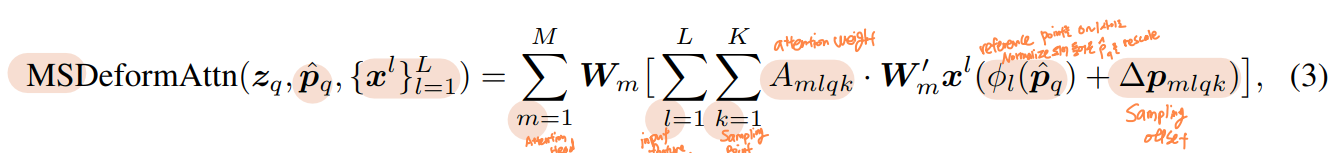
1.4 Deformable Attention
Transformer Attention을 image feature maps에 적용할 때 큰 이슈는 모든 가능한 위치 정보에 접근한다는 것입니다.
- 이 문제를 해결하기 위해 Deformable Attention module이 제안됐습니다.
- 오직
small fixed number of keys for each query에만 attention을 할당함으로써Convergence Issue와Feature spatial resolution issue가 완화되었습니다.
Deformable Attention은 Attention 연산을 수행할 때 Key가 모든 픽셀이 되는 것이 아니라, 특정 layer를 통해 예측된 Sampling points들에 대해서만 Attention 연산을 수행합니다. (=Deformable Convolution)
Deformable Attention Module은
- 모든 픽셀에 대한 attention을 수행하는 대신, 독립적인 linear layer에 통과시켜 Sampling offset, attention weights를 얻게 되며 이들을 이용하여 attention 연산을 수행하게 됩니다.
- 이때 일반적인 방식처럼 내적을 통해 구한 attention weight가 아닌 linear layer를 통해 구한 attention weight를 이용
- 해당 attention weight를 앞서 구한 sampled points의 feature와 aggregate하여 attention value를 얻습니다.
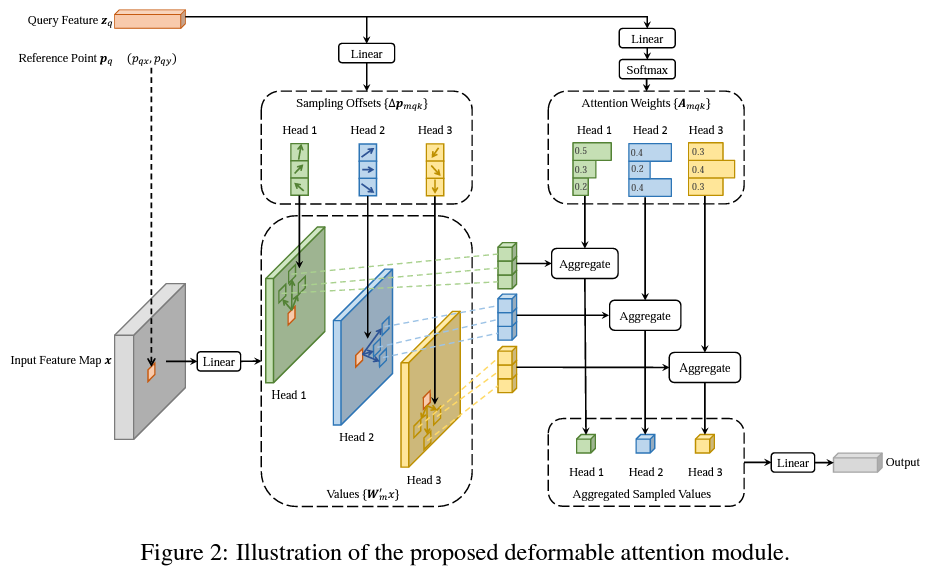
- 모든 key에 대한 Attention score는 1이기 때문에 일반적인 attention module의 경우 각 key에 부여되는 스코어가 학습 초기에 굉장히 작았으나, deformable attention을 이용하여 특정 개수의 key만 샘플링을 해서, 각 키에 부여되는 score가 충분히 큰 값을 갖게 되었습니다.
- deformable attention module은 convolution feature maps을 key elements로써 processing 하려고 디자인되었습니다.
👉 2. 1차 학습 후 💥 Class Imbalance 💥 문제
Inference
1차 학습 후 최종 생성된 Model Weight로 Inference를 해보았다.
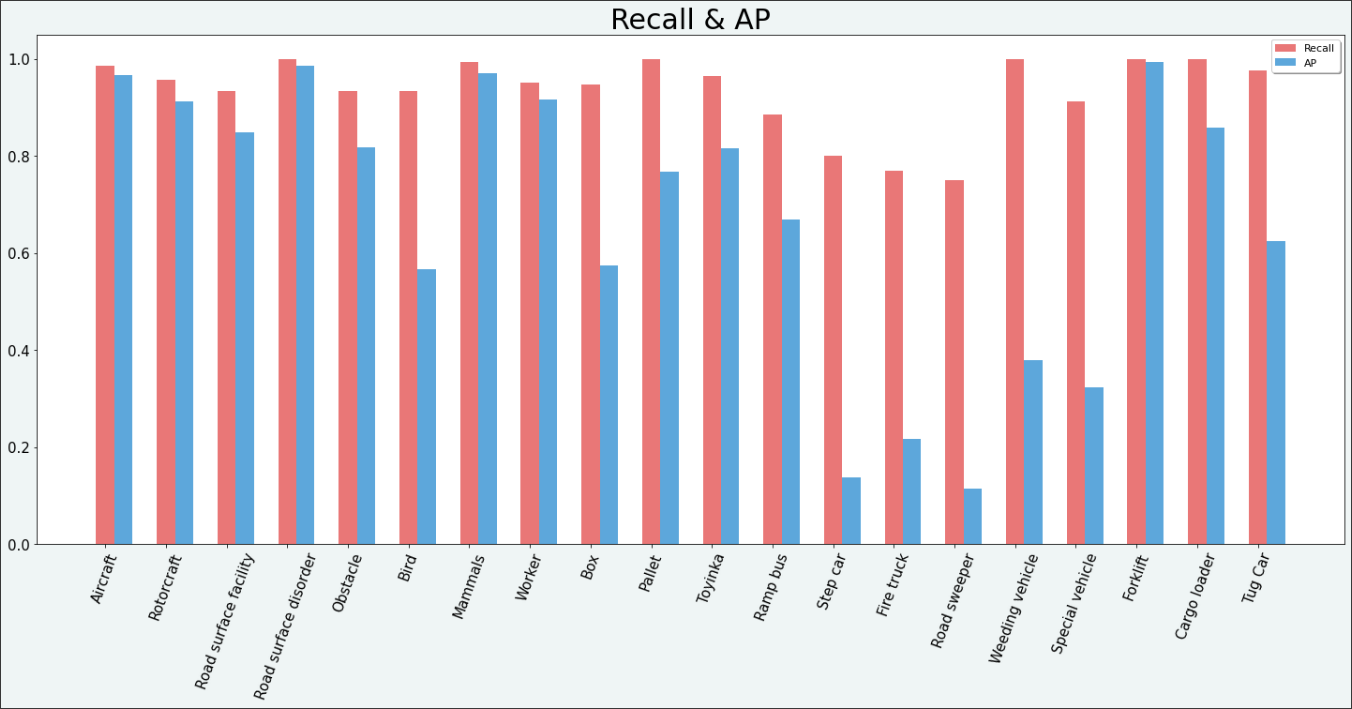
데이터의 수가 양호하고, Recall과 AP 모두 준수한 결과를 보였던 Class들을 잘 예측하는 것을 확인했다.


💥 Class Imbalance 💥
1차 데이터셋으로 학습을 마친 후, 결과 지표를 그래프로 그려보았다.
예상했던 대로 Class Imbalance의 영향을 받은 결과를 확인했고, 크게 두 가지의 고민이 생겼다.
- 특정 클래스들(
Ramp bus,Forklift,Cargo loader,Tug Car)의 데이터 수가 다른 클래스에 비해 현저히 적음에도 AP가 높게 나타났다. 이 결과를 신뢰할 수 있는가?
- Epoch가 진행되면서 Recall은 향상되는데 AP는 그렇지 않다. 왜 그러는 것일까?
1.
상황
특정 클래스들(Ramp bus, Forklift,Cargo loader ,Tug Car)의 데이터 수가 다른 클래스에 비해 현저히 적음에도 AP가 높게 나타났다. 이 결과를 신뢰할 수 있는가?
데이터의 수가 적으면 어떤 테스트든 신뢰도가 떨어지는 건 어쩔 수 없다.
원인 모색
우연히 Train & Val 데이터의 분포가 같은 구성이었을수도 있다.
(동일 객체를 다른 각도에서 찍은 사진들이 나뉘어 들어가 있다든지)
해결 방안 도출
🛠️ 데이터의 수를 보완하자.
🛠️ 이러한 상황에서 모델의 일반화 성능을 높이는 방법들이 많이 연구가 되어있으므로 적용해보자.
(Augmentations, Focal Loss, Class Weight.... etc)
🛠️ 그리고 클래스 불균형이 아닌 데이터셋에서 하이퍼 파라미터 튜닝 등의 방법 등을 적용해서 추출해보자. (Ablation Study)
2.
상황
Epoch가 진행되면서 Recall은 향상되는데 AP는 그렇지 않다.
원인 모색
높은 Recall값을 가질 때 낮은 Precision을 가지는 경우는 Positive Sample의 경우에 Positive라고 잘 예측하지만 반대로 Negative Sample 또한 Positive라고 예측을 해버리는 경우이다.
실제로 target 값의 분포가 불균형할 때 이러한 경우가 많이 발생한다.
해결 방안 도출
False Positive를 class-wise , iou-wise로 나눠서 같이 확인해보자.
👉 Framework 내 추출하는 코드를 Custom 하지 못해 실패
Target 값의 분포 불균형을 최대한 해소하자.
🛠️ Class Imbalance 해결 방안 시도 🛠️
그래서 최종적으로 Class Imbalance를 해결하기 위한 시도로 3가지를 결정했다.
1. 데이터 수가 부족한 클래스들의 이미지 보충
- 데이터셋 관련 문서에서 자세히 기술
- 이미지 크롤링
- 데이터 증강
2. 클래스 불균형 상태에서 모델의 일반화 성능 향상 시도
- Data Augmentation
- Label Smoothing
- Mixup, Cutout, CutMix, Mosaic 등
- Focal Loss
- Class Weight 등
3. 클래스 불균형이 아닌 데이터셋에서 Optimization을 시도
- 별도로 균형 잡힌 클래스 분포를 가진 데이터셋 (Mini Dataset)을 생성해서 Ablation Study를 진행해보자.
1번은 데이터셋 관련 문서에서 자세히 기술했다.
2번과3번은 아래 3. Ablation Study (Experiments)에서 기술한다.
👉 3. Ablation Study (Experiments)
Mini Dataset Generation
클래스와 Target의 분포가 균형 잡힌 데이터셋을 만들어서 Optimization을 시도할 필요성을 느꼈다.
(클래스에 속하는 객체의 개수 동일하게 100개씩 추출해서 생성)
그래서 아래의 과정들을 거쳐서 미니 데이터셋을 새로 Custom으로 생성하였다.
전체 생성 코드는 여기에서 확인할 수 있다.
- 전체 이미지 파일명, 경로, 클래스명 등이 담긴 csv 파일을 Dataframe으로 만들고, Dataframe 내 class 개수 / class 이름 변환 (Class Unification)
- Dataframe 내 이미지 경로를 활용해 json 파일에 접근해서 각 class 별 100개의 이미지씩 추출 👉 클래스 19개
- Json (label 파일) 내 class id 값 수정 (바뀐 클래스 개수에 맞게)
- 새로 생긴 데이터셋 경로에서 각 클래스별 인덱스를 추출하고 Validation 비율에 맞게 데이터 분할 (Train / Val 데이터 디렉토리 구분하여 생성)
- Train, Valid 인덱스를 활용해서 Annotation 용 Meta file (txt 파일) 생성
Ablation Study (Experiments) feat. Optimization
Class Imbalance 상황에서 모델 학습을 진행할 때, 최적의 값들을 산출하여 개선의 필요성을 느끼고 위에서 만든 Mini Dataset으로 Optimization을 수행했다.
수행하면서 다양한 기법들의 개념, 필요성, 적용을 더 깊이 알아갈 수 있는 시간이었다.
처음엔 수동으로 진행했으나, Colab 환경상 시간이 너-무 오래 걸리고, 진행 속도가 현저하게 느렸다.
그래서 나중에 자동으로 값들을 비교하여 탐색하는 Wandb.sweep 기능을 서칭하여 MMDetection Framework에 연동해 진행했다.
Sweeping이 끝난 후, 유의미한 결과를 남긴
Trial만 남겨서 결과를 비교 분석했다.
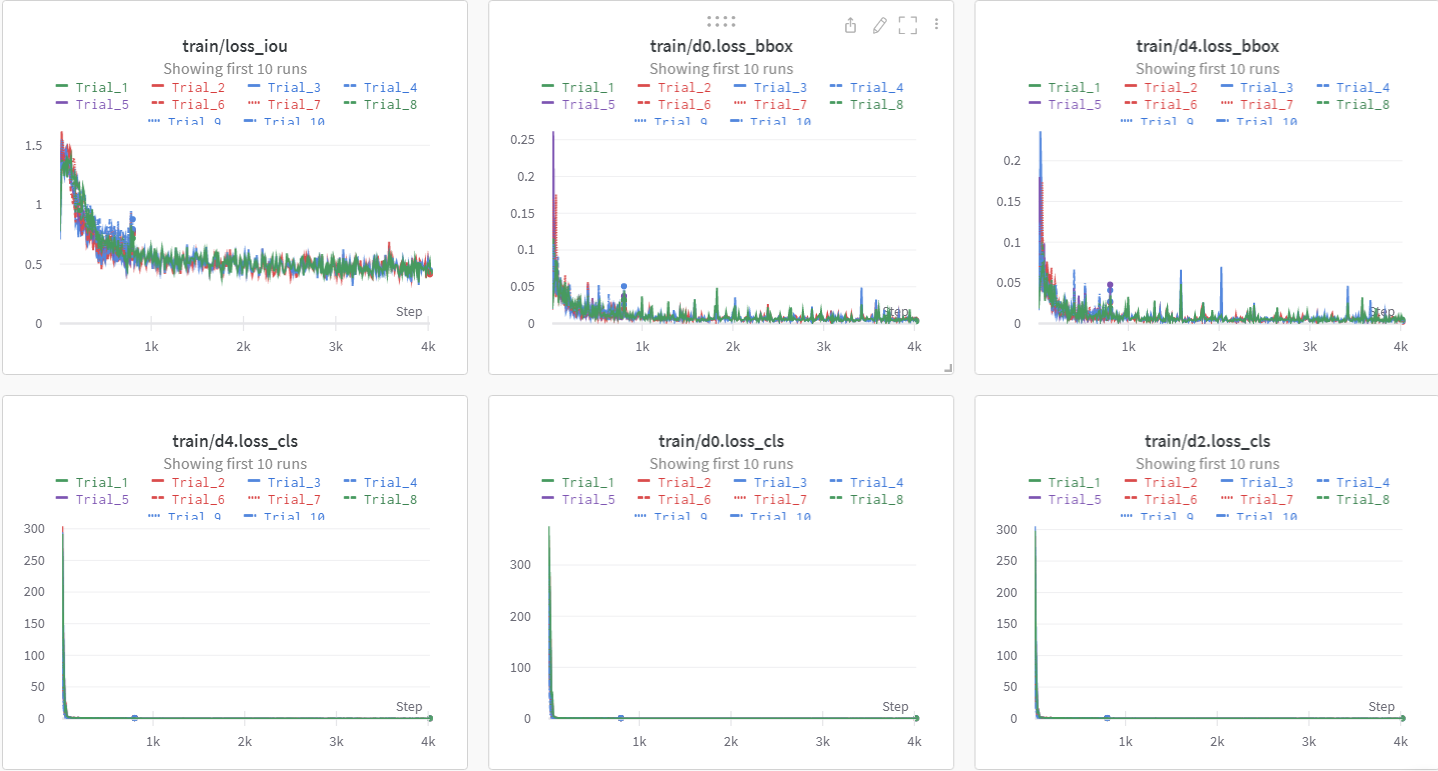
1. Backbone
본 논문에서는 ResNeXt-101을 사용했을 때, 가장 성능이 좋았다고 발표했다.
그래서 MMDetection의 Deformable DETR의 Backbone resnet-50과 결과를 비교 분석했다.
ResNeXt-101이 학습 시간이 2배 정도 더 소요ResNeXt-101이resnet-50보다 2% 성능 향상
👉 학습 시간과 성능의 Trade-off 고민 후, renet-50 Backbone을 결정했다.
2. Encoder & Decoder Layer Numbers
DETR 논문의 Ablation Study에서 Encoder와 Decoder Layer 개수의 증가 (12개)가 성능 향상에 도움을 준다는 연구가 있지만 그 정도가 약하다.
기존 6개에서 10개, 12개로 실험했다.
6개보다 연산량이 대폭 증가해 학습 시간이 훨씬 더 많이 소요- 늘어난 학습 시간에 비해 미세하게 성능 향상
👉 학습 시간과 성능의 Trade-off와 GPU 학습 환경을 고려하여 6개를 결정했다.
3. Quantity of Reference points
- MMDetection 모델 구조 안에 있는 코드에 Reference points 를 설정할 수 있는 코드가 없다.
(내부적으로 기본 설정으로 돌아가는 것 같음)
4. Augmentations & Generalization Attempt
Deformable DETR의 Train 시 적용되는 augmentations은 DETR의 기준과 동일하게 구현돼있다.
- we use scale augmentation, resizing the input images such that the shortest side is at least 480 and at most 800 pixels while the longest at most 1333.
policies=[[{ 'type': 'Resize', 'img_scale': [(480, 1333), (512, 1333), (544, 1333), (576, 1333), (608, 1333), (640, 1333), (672, 1333), (704, 1333), (736, 1333), (768, 1333), (800, 1333)],
- To help learning global relationships through the self-attention of the encoder, we also apply
random crop augmentationsduring training,{ 'type': 'RandomCrop', 'crop_type': 'absolute_range', 'crop_size': (384, 600), 'allow_negative_crop': True }
- a train image is cropped with probability 0.5 to a random rectangular patch which is then resized again to 800-1333.
'type': 'Resize', 'img_scale': [(480, 1333), (512, 1333), (544, 1333), (576, 1333), (608, 1333), (640, 1333), (672, 1333), (704, 1333), (736, 1333), (768, 1333), (800, 1333)],
Deformable DETR의 Valid & Test Time Augmentation 시 적용되는 augmentations은 Deformable DETR 논문을 기준으로 구현돼있다.
On test-dev set,TTA including
horizontal flipandmulti-scaletesting=⇒ Best performance... dict( type='MultiScaleFlipAug', img_scale=(1333, 800), flip=False, transforms=[ dict(type='Resize', keep_ratio=True), dict(type='RandomFlip'), ...
👉 필자는 Task 특성상 객체들이 빠르게 형태를 이동하는 것을 고려하여 본래 각에서 약간 틀어진 형태를 학습할 수 있게 Rotate와 빛의 밝기나 역광 등을 고려하여 BrightnessTransform을 추가하였다.
👉 그리고 Class Imbalance를 보완하기 위해서 Mixup과 Mosaic을 Train pipeline에 추가했다.
- 기존 논문을 기존으로 구현한 pipeline보다 약
7%정도 성능 향상을 보였다.
5. Optimizer
DETR에서 사용했던 AdamW with weight decay handling 로 적용돼있었다.
👉 비슷한 weight decay ratio를 설정하고 SGD, Adam 등 다양한 optimizers를 실험해봤는데, AdamW이 가장 성능이 좋았다.
6. Learning Rate Scheduler
DETR, Deformable DETR의 논문에는 언급돼있지 않지만, Step scheduler가 적용돼있었다.
👉 여러 schedulers를 시험해봤는데, CosineRestart(warm) Learning Rate Scheduler이 가장 결과가 좋았다.
- 주기적으로 learning rate를 갱신시킴으로써 학습 시 모델의 일반화에 도움을 주고 과적합을 방지하는 역할을 한다.
7. Bounding Box Loss
DETR의 논문을 기준으로 L1 loss가 적용돼있었다.
Boxes의 좌표 차이를 더욱 부드럽게 모델에게 인식시키기 위해 Smooth L1 loss를 적용했다.
는 로 정답 label과 예측한 값의 차이
인 부분(즉, 오차가 작은 부분)에서 곡선이고 외에 영역에서는 직선이다.
따라서 error의 값이 충분히 작을 경우 거의 맞는 것으로 판단하며, loss값이 빠른 속도로 줄어들게 된다
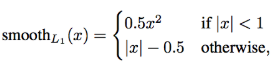
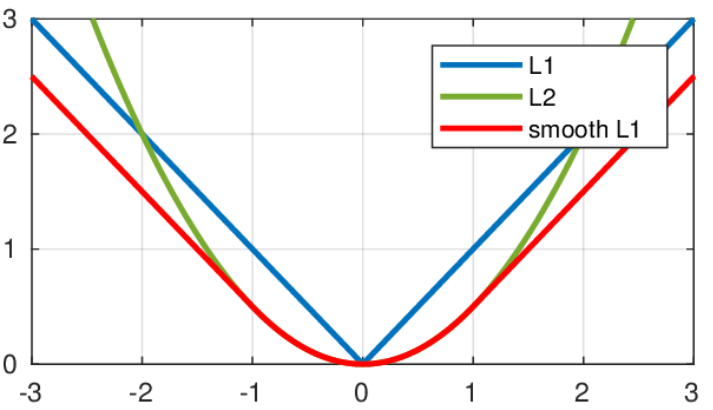
👉 실험 결과, L1 loss를 사용했을 때보다, 약 6% 정도 성능 향상을 보였다.
8. IOU Loss
DETR의 논문에 나와있는 것처럼 L1 Loss를 보완하기 위해 Generalized IOU이 적용돼있었다.
필자는 GIOU를 개선한 DIOU와 CIOU를 비교 실험을 진행했다.
- DIOU : 두 box가 겹치지 않았을 때, GIOU처럼 Bbox의 영역을 넓히지 않고 중심 좌표를 통해 박스의 거리 차이를 최소화함으로써 수렴 속도를 향상시켰다
- CIOU : CIOU 논문 저자는 Bbox에 대한 좋은 Loss는
overlap area,central point distance,aspect ratio세 요소를 고려하는 것이라고 말한다. 따라서 overlap area와 central point distance를 고려하는 DIoU에 추가로 aspect ratio를 고려하는 CIOU가 제안되었다.
👉 실험 결과, 같은 실험 조건에서 CIOU가 GIOU보다 3.5배 / DIOU보다 4배가 빠르고 성능이 더 좋았다.
👉 4. 성능 향상 정체 Problem
💥 성능 향상 정체 💥 문제
상황
위의 1차 데이터셋에서 데이터 수가 현저히 부족했던 클래스들 (Step car, Fire truck, Road sweeper, Weeding vehicle,Special vehicle)를 크롤링해서 추가한 2차 데이터셋을 위의 Ablation Study에서 산출한 값들로 재학습을 시도했다.
하지만, 예상과 달리 성능이 어느 구간에서 향상되지 않는 💥 성능 향상 정체 문제💥가 발생했다.
원인 모색
-
Ablation Study에서 산출한 하이퍼 파라미터, loss 등이 문제라고 생각
- Original 값들로 재 학습해보았지만, 해결 X
-
과적합이 일어났다고 생각
- Dropout, Regularziation의 weight 등을 강화해보았지만 해결 X
-
데이터의 문제인가?
- 학습에 방해가 되는 데이터가 있는지 일일이 확인
- label file에서 class 일치하는지 확인
해결
전 데이터 관련 문서에서 기술했지만, 1. 크롤링해서 추가한 데이터들의 미흡한 정제상태, 2. Bounding box format 불일치로 인한 문제였음을 발견했다.
- 전체 데이터셋 분포를 혼란스럽게 하는 데이터들을 제거, 재정제하여 재추가
- Bounding box format 일치화 진행
위 2가지 방법을 적용하여 🛠️성능 향상 정체 문제를 해결🛠️했다.
👉 5. 최종 학습 결과
최종으로 생성된 데이터셋으로 Ablation Study로 산출한 값들로 학습을 진행했다.
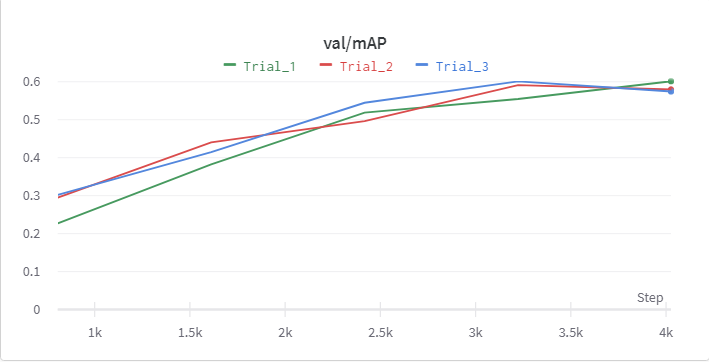
최종 결과
Class Imbalance가 완벽히 해소되지는 않아서 mAP가 기하급수적으로 증가하진 않았지만, 전보다 10%의 성능 향상을 보였다.
Target 분포가 불균형하여 데이터를 정제하여 추가한
imbalanced 클래스들의 준수한 성능 향상을 확인할 수 있었다.최종 학습 전
최종 학습 후
Imbalanced한 클래스들의 객체들을 잘 detect하고, 다른 클래스들에 대해서도 준수한 성능을 보이는 것을 보여준다.





👉 6. 학습 시 Challenge였던 점
Val Loss vs 검증의 유의미성
MMDetection Framework 특성상 학습 중 val loss를 추출하려면 train에 사용했던 augmentations을 valid 할 때 적용해야 한다.
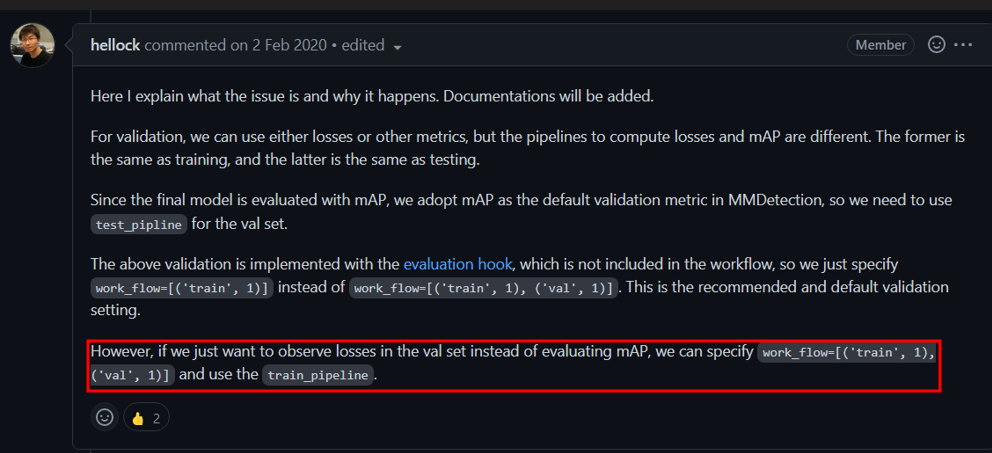
어떤 결정을 내려야 하는지 오랜 고민과 선배님들에게 자문해서 결정을 했다.
👉 val loss를 추출을 못하더라도 train pipeline과 valid pipeline을 다르게 하는 것으로 검증의 유의미성을 확보하는 것으로 결정
- Object Detection 과제에서
val_loss는 참고지표지 성능지표가 아니다.mAP라는 성능지표가 있으므로 val loss가 절대적인 성능 지표가 아니다.
- Train augmentations과 valid augmentations을 동일하게 해서 검증의 신뢰성과 유의미성을 잃는 것이 더 치명적이다.
- Valid set에 train aug를 적용하면 같은 모델이라도 매번 평가 결과가 다른데 이 점이 검증의 신뢰성을 더 떨어뜨림.
TTA, 이미지 수를 증가하기 위한flip이나resize crop같은 요소를 제외하면 valid set에는 augmentations을 되도록 적용하지 않는 것이 신뢰성 있음.
