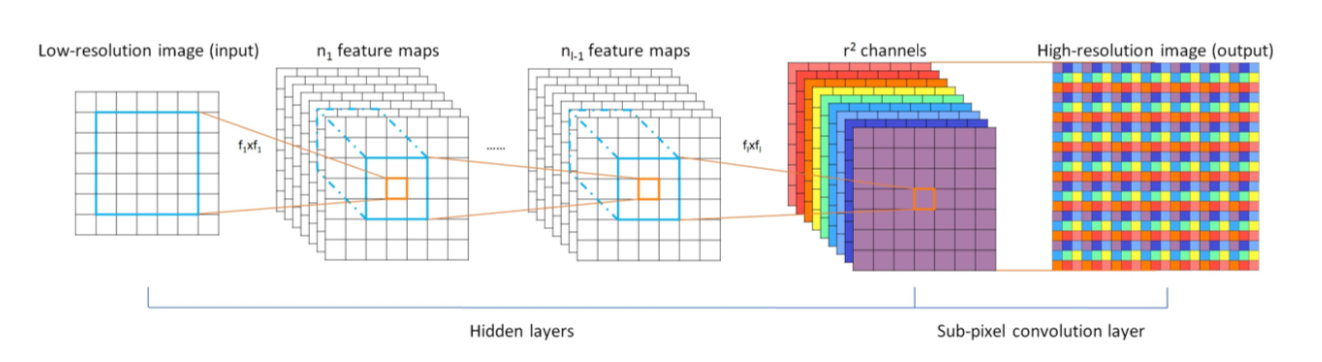
ESPCN


ESPCN은 FSRCNN 모델과 같이 기존의 LR(Low-Resolution)이미지에서 feature extraction을 한 후 마지막 layer에서 HR(High-Resolution)으로 upscaling 시키는 방식의 모델이며, FSRCNN이 ConvTranspose2d를 이용하여 upscale을 한 반면, ESPCN은 PixelShuffle을 이용하여 upscale을 하였음.
[Abstract]
ESPCN의 큰 특징 2가지
- 첫째, 3개의 convolution layer를 사용함.
- 둘째, LR 이미지를 그대로 convolution layer에 넣고 마지막 단계에서 sub-pixel convolution layer를 이용하여 upscailing 함.
이렇게 함으로써 LR 공간에서 feature들의 특징을 뽑아내게 되고, 이는 filter size를 줄여 최종적으로 모델의 복잡성이 낮아지게 됨.
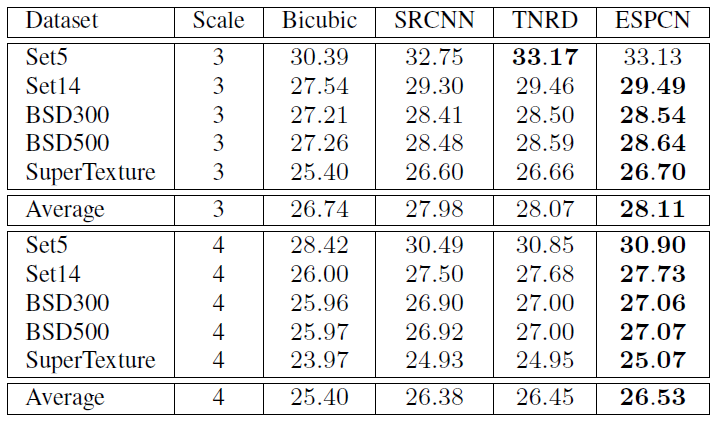
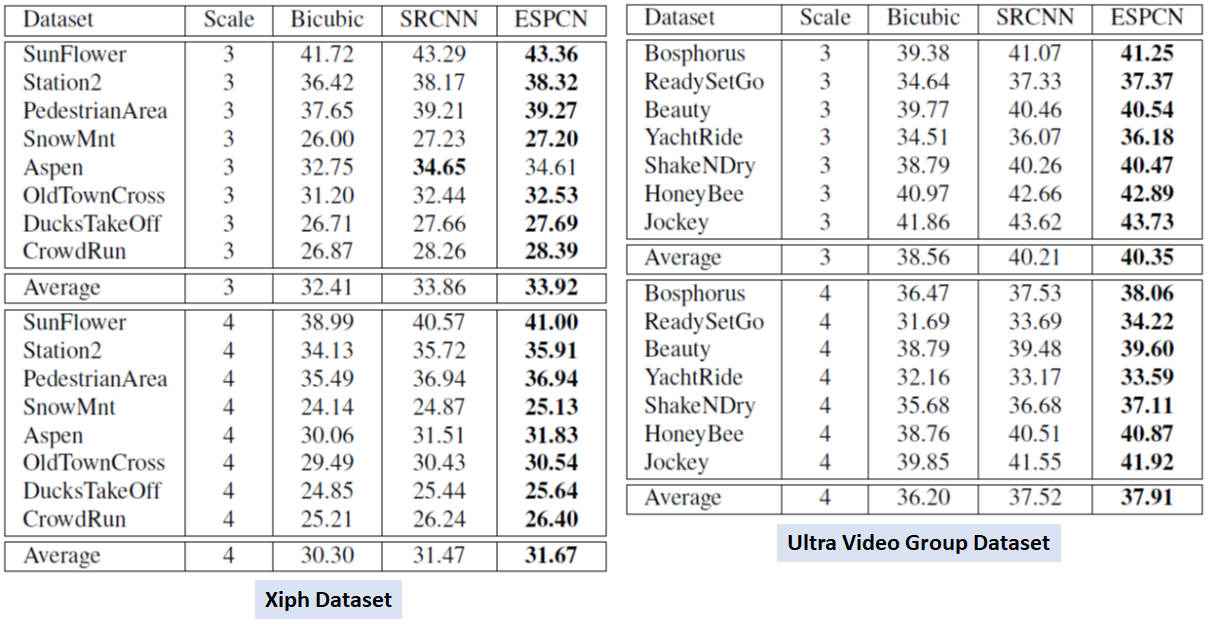
[Results]



[ESPCN structure]
-
1단계 : 특징 추출(feature extraction)
- 원본 이미지를 그대로 입력 데이터로 사용
- num_channel = 1
- 5x5 필터
- output_channel = 64
- Tanh()
-
2단계 : 특징 추출(feature extraction)
- input_channel = 64
- 3x3 필터
- output_channel = 32
- Tanh()
- 3단계 : 업스케일링(upscaling)
- input_channel = 32
- 3x3 필터
- output_channel = num_channels * (scale_factor ** 2)
- nn.PixelShuffle(scale_factor)
https://pytorch.org/docs/stable/generated/torch.nn.PixelShuffle.html
Light ESPCN
마지막으로 필자는 ESPCN 모델의 성능 감소는 최소화하면서 더욱 가벼운 light-ESPCN 모델을 제안함.
[light-ESPCN structure]
-
1단계 : 특징 추출(feature extraction)
- 원본 이미지를 그대로 입력 데이터로 사용
- num_channel = 1
- 1x1 필터
- output_channel = 64
- Tanh()
-
2단계 : 특징 추출(feature extraction)
- input_channel = 64
- 3x3 필터
- output_channel = 32
- Tanh()
- 3단계 : 업스케일링(upscaling)
- input_channel = 32
- 3x3 필터
- output_channel = num_channels * (scale_factor ** 2)
- nn.PixelShuffle(scale_factor)
https://pytorch.org/docs/stable/generated/torch.nn.PixelShuffle.html - nn.sigmoid()
[Result & Code]
https://github.com/seogihyun/Super_Resolution/tree/master/light-ESPCN

Computer Vision Deep Learning Engineer