
Accelerating the Super-Resolution Convolutional Neural Network(ECCV 16)
[Abstract]
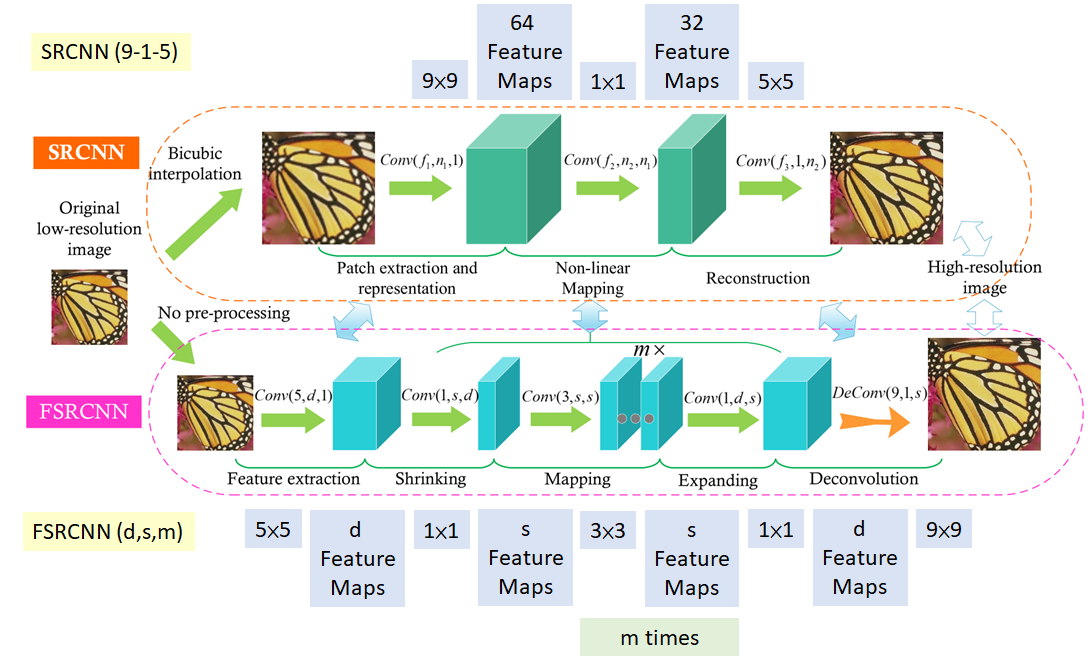
FSRCNN의 큰 특징 3가지
- 첫째, SRCNN이 Bicubic Interpolation으로 upscale을 먼저 한 후 convolution layer에 집어넣는 방식을 사용한 반면, FSRCNN은 LR 이미지를 그대로 convolution layer에 집어넣는 방식을 사용하여 convolution에서의 연산량을 줄였음.
- 둘째, network 후반부에서 feature map의 width, height size를 키워주는 Deconvolution(transposed convolution)연산을 사용하여 HR 이미지를 만들었음.
- 셋째, SRCNN의 non-linear mapping 단계를 shrinking, mapping, expanding 세 단계로 분리하였음.
그 결과 SRCNN에 비해 굉장히 연산량이 줄어들어 저자는 거의 실시간에 준하는 성능을 보일 수 있음을 강조하였으며, 연산량이 줄어든 만큼 convolution layer의 개수도 늘려주면서 정확도(PSNR)도 챙길 수 있음을 보여주었음.
[From SRCNN to FSRCNN]
[Results].png)


[FSRCNN structure]
- 1단계 : 특징 추출(feature extraction)
- num_channels = 1
- 원본 이미지를 그대로 입력 데이터로 사용
- 5x5 필터
- d = 56
- s = 12
- m = 4
- 2단계 : 축소(shrinking)
- 1x1 필터
- 3단계 : 매핑(mapping)
- SR성능에 영향을 미치는 가장 중요한 부분(매핑층의 개수 & 필터의 크기)
- 여러 층의 3x3 필터
- 4단계 : 확장(expanding)
- 축소 이전의 채널의 크기와 동일하게 확장
- 1x1 필터
- 5단계 : 업스케일링(deconvolution)
- Convolutional Transpose 사용하여 업스케일링
- 업 스케일링 요소에 관계 없이 모든 이미지가 기존 레이어의 가중치와 편향 값 공유
- 학습시간 감소
- 9x9 필터
[FSRCNN-s structure]
- 1단계 : 특징 추출(feature extraction)
- num_channels = 1
- 원본 이미지를 그대로 입력 데이터로 사용
- 5x5 필터
- d = 32
- s = 5
- m = 1
- 2단계 : 축소(shrinking)
- 1x1 필터
- 3단계 : 매핑(mapping)
- SR성능에 영향을 미치는 가장 중요한 부분(매핑층의 개수 & 필터의 크기)
- 여러 층의 3x3 필터
- 4단계 : 확장(expanding)
- 축소 이전의 채널의 크기와 동일하게 확장
- 1x1 필터
- 5단계 : 업스케일링(deconvolution)
- Convolutional Transpose 사용하여 업스케일링
- 업 스케일링 요소에 관계 없이 모든 이미지가 기존 레이어의 가중치와 편향 값 공유
- 학습시간 감소
- 9x9 필터
FSRCNN-x
마지막으로 필자는 FSRCNN 모델을 경량화 시킨 FSRCNN-s 모델과 Optimal-FSRCNN 모델을 참고하여 FPGA에서 작동 가능한 초경량화된 FSRCNN-x 모델을 제안함.
[FSRCNN-x structure]
- 1단계 : 특징 추출(feature extraction)
- num_channels = 1
- 원본 이미지를 그대로 입력 데이터로 사용
- 3x3 필터
- d = 23
- s = 12
- m = 2
- 2단계 : 축소(shrinking)
- 1x1 필터
- 3단계 : 매핑(mapping)
- SR성능에 영향을 미치는 가장 중요한 부분(매핑층의 개수 & 필터의 크기)
- 여러 층의 3x3 필터
- 4단계 : 확장(expanding)
- 축소 이전의 채널의 크기와 동일하게 확장
- 1x1 필터
- 5단계 : 업스케일링(deconvolution)
- Convolutional Transpose 사용하여 업스케일링
- 업 스케일링 요소에 관계 없이 모든 이미지가 기존 레이어의 가중치와 편향 값 공유
- 학습시간 감소
- 3x3 필터
[Results & Code]
https://github.com/seogihyun/Super_Resolution/tree/master/FSRCNN_x

Computer Vision Deep Learning Engineer
좋은 글 감사합니다 :)