뇌 MRI이미지로 알츠하이머와 경도인지장애를 진단하는 CNN 딥러닝 모델 개발과정 정리 및 회고.
(2) 모델링 과정
- Github Repository 바로가기 : Alzheimer_MCI-CNN_Classifier(클릭)

딥러닝 기반 알츠하이머 및 경도인지장애 진단 모델 개발
Deep Learning based Alzheimer and MCI Diagnosis Model
- 합성곱 신경망(CNN)을 통해 Brain MRI 이미지를 알츠하이머와 경도인지장애(MCI)로 분류하는 딥러닝 모델 개발

0. 프로젝트 개요
필수 포함 요소
자유주제(의료/헬스케어)- 설정한
데이터 직무 포지션에서 풀고자하는 문제 정의 - 적합한
데이터셋선정 및 선정 이유 딥러닝 파이프라인구축- 딥러닝 모델
학습 및 검증 한계점과추후 발전 방향
프로젝트 목차
(Part1) Intro & Metadata
- Introduction
서론- Position & Intention
포지션설정, 기획의도 - Alzheimer Dementia, MCI
알츠하이머치매와 경도인지장애 - Necessity of Research
연구의 필요성 - Purposes
목표 및 가설
- Position & Intention
- Dataset & Metadata
데이터셋 및 메타데이터- ADNI dataset
데이터셋 소개 - Data Preparation
데이터 준비 - Metadata Analysis
메타데이터 분석 - Metadata EDA Dashboard
대시보드
- ADNI dataset
(Part2) Modeling
- Modeling
모델링- Overview & Structure
개요 및 구조 - Data Import & Split
데이터 로딩 및 분리 - Preprocessing Layer
전처리 레이어 - Vanilla CNN Model
기본 CNN 모델
- Overview & Structure
- Model Improvement
모델 성능 개선- Transfer Learning
전이학습 - Negative Transfer
네거티브 전이 - Hyperparameter Tuning
하이퍼파라미터 튜닝 - Final Model & Evaluation
최종 모델 학습 및 검증
- Transfer Learning
(Part3) Prediction & Conclusion
- Prediction & Comparing
예측 및 비교분석- Test Dataset
테스트 데이터셋 - Prediction & Confidence
예측 및 신뢰도 - Metrics & Confusion Matrix
평가지표 및 혼동행렬
- Test Dataset
- Conclusion
결론- Overall Summary
요약 - Limitations & Further Research
한계와 추후 발전방향 - Takeaways
핵심과 소감
- Overall Summary
Deep Learning Pipeline

(Part2) Modeling

- 진행은 다음과 같은 방식으로 진행할 예정
- Part 3-1 ~ 3-3 : 모델 모두에 공통적으로 적용되는 특징 및 소스코드를 정리
- Part 3-4 : 세 모델 중 가장 기본적인 형태의 Vanilla CNN 모델
- Part 4-1 ~ 4-3: Vanilla CNN 모델을 개선하기 위한 방법들을 적용
- Part 4-4 : 성능이 가장 좋은 최종 모델 학습 (이건 로컬에서 진행)
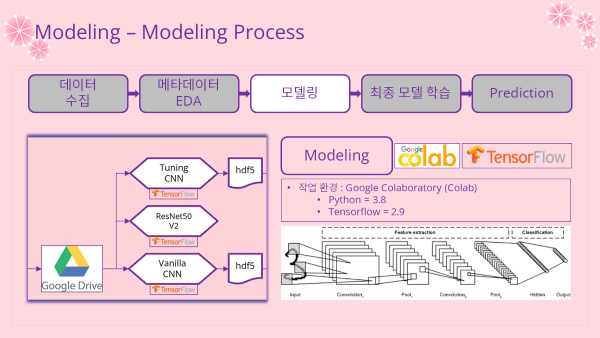
3. Modeling 모델링
- 모델링 과정들은 구글 Colab을 통해 실시하였음
- 학습을 진행한 모델은 총 3개
- 기본 CNN (Vanilla CNN)
- 소스코드 링크 : Modeling-Vanilla_CNN.ipynb
- 전이학습 모델 (ResNet50V2)
- 소스코드 링크 : Modeling-ResNet50V2.ipynb
- 튜닝 모델 (keras-tuner)
- 소스코드 링크 : CNN-Hyperparameter_Tuning.ipynb
- 기본 CNN (Vanilla CNN)
3-1. Overview & Structure 개요 및 구조
- 모델은 CNN 기반의 모델들로 진행할 것임
- CNN (Convolutional Neural Network) 합성곱 신경망
- 크게는 합성곱층과 풀링층이 있는 것이 특징
- 합성곱층 (Convolution Layer)
- 합성곱 필터(Convolution Filter)가 슬라이딩(Sliding)하며 이미지 부분부분의 특징을 읽고 학습을 진행
- 풀링층 (Pooling Layer)
- 특징을 보존하면서 데이터 크기를 축소함
- 합성곱층 (Convolution Layer)
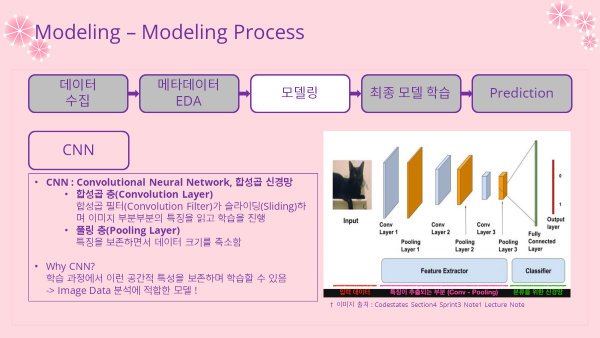
- 왜 CNN으로 했나?
- 학습 과정에서 공간적 특성을 보존하면서 학습할 수 있기 때문에 이미지 데이터 분석에 가장 적합한 모델로 꼽힘
- 이러한 CNN 모델로 인해 이미지 분석 분야는 괄목할 만한 발전을 할 수 있었음
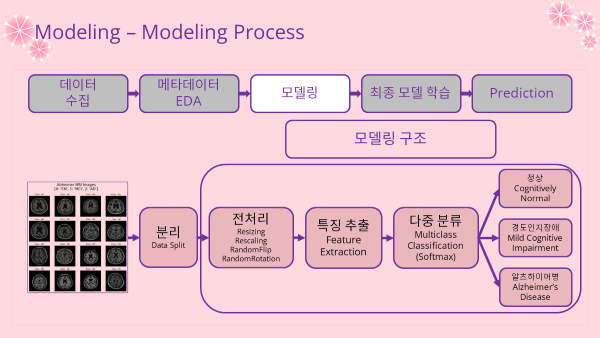
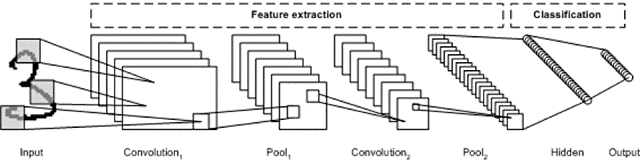
- 모델들의 기본 구조
- 전처리 Layer
- 특징추출 Layer
- 분류 Layer
3-2. Data Import & Split 데이터 로딩 및 분리
- 진행한 세 모델 모두 공통적으로 적용됨
- 위에 정리된 소스코드 링크 혹은 아래 모델별 소스코드 링크로 확인 가능!
- 이미지 데이터는 구글 드라이브에 저장해놓은 이미지를 불러와서 이용하였음
이미지 데이터 불러오기
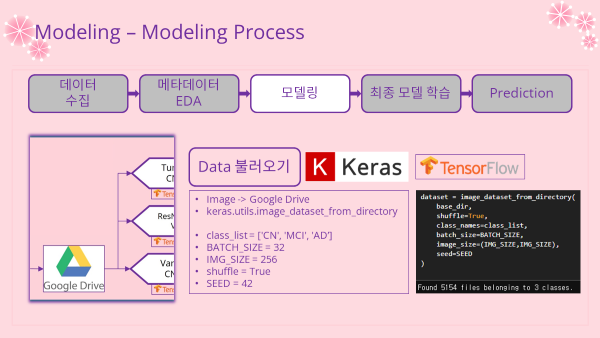
- Google drive 연동하기(mount)
from google.colab import drive
drive.mount('/content/drive')- Directory 지정 & 폴더이름(=클래스명) 확인
import os
base_dir = "/content/drive/MyDrive/AI/Alzheimer/"
data_dir = base_dir + "Axial"
os.listdir(data_dir)
'''
['AD', 'CN', 'MCI']
'''- Image Data 수 확인
import pandas as pd
# 변수 지정
CLASSES = ['CN', 'MCI', 'AD']
# 딕셔너리 형태로 이미지 갯수 저장
number_of_images = {}
for class_name in CLASSES:
number_of_images[class_name] = len(os.listdir(data_dir+"/"+class_name))
# 데이터프레임으로 만들기
image_count_df = pd.DataFrame(number_of_images.values(),
index=number_of_images.keys(),
columns=["Number of Images"])
# 결과 출력
display(image_count_df)
print("\nSum of Images: {}".format(image_count_df.sum()[0]))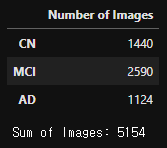
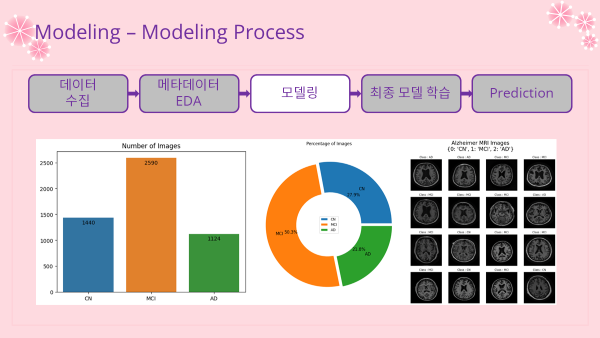
Image Data 수 시각화 (소스코드는 이 글의 다음 과정인 파트3쪽에 있어서 ppt 이미지로 대체함)
- Image Data를 Tensor 데이터로 불러오기
from keras.utils import image_dataset_from_directory
# 변수 지정
CLASSES = ['CN', 'MCI', 'AD']
IMG_SIZE = 256
BATCH_SIZE = 32
SEED = 42
# 불러오기 (배치사이즈 32, 이미지크기 256)
dataset = image_dataset_from_directory(
data_dir,
shuffle=True,
class_names=CLASSES,
batch_size=BATCH_SIZE,
image_size=(IMG_SIZE,IMG_SIZE),
seed=SEED
)
'''
Found 5154 files belonging to 3 classes.
'''
# 레이블(타겟) 클래스 확인
print(dataset.class_names)
'''
['CN', 'MCI', 'AD']
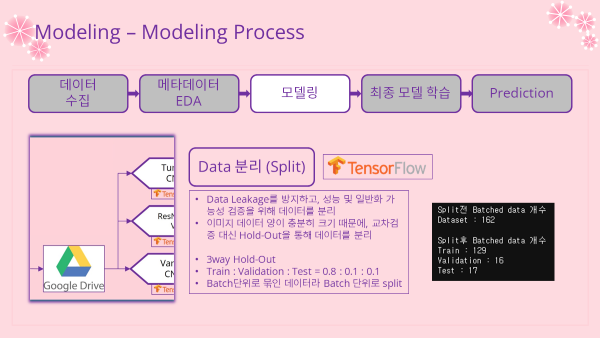
'''데이터셋 분리 (Split)
- Data Leakage (데이터 누수) 방지
- 데이터 양이 5000개 이상으로 충분히 많기 때문에 3way Hold-Out을 통해 훈련, 검증, 테스트로 데이터를 분리하여 훈련, 검증, 예측을 진행함
- Train : Validation : Test = 0.8 : 0.1 : 0.1
# 함수 지정
def dataset_split(ds, tr=0.8, val=0.1, test=0.1, shuffle=True, buf_size=10000, SEED=42):
ds_size = len(ds)
if shuffle:
ds = ds.shuffle(buf_size,seed=SEED)
train_size = int(ds_size*tr)
val_size = int(ds_size*test)
train = ds.take(train_size)
test0 = ds.skip(train_size)
val = test0.take(val_size)
test = test0.skip(val_size)
return train,val,test
# 분리 (Batch 단위로 분리가 진행됨)
train_ds, val_ds, test_ds = dataset_split(dataset)
print("Split전 Batched data 개수")
print(f"Dataset : {len(dataset)}")
print("\nSplit후 Batched data 개수")
print(f"Train : {len(train_ds)}")
print(f"Validation : {len(val_ds)}")
print(f"Test : {len(test_ds)}")
'''
Split전 Batched data 개수
Dataset : 162
Split후 Batched data 개수
Train : 129
Validation : 16
Test : 17
'''Data Prefetch (속도를 향상 시키기위한 것, 안해줘도 무방하긴함)
train_ds=train_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
val_ds=val_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
test_ds=test_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)3-3. Preprocessing Layer 전처리 레이어
- 모든 모델에 가장 앞에 위치하는 전처리 레이어
- 모델이 저장될때 해당 레이어도 포함되서 저장이 이루어짐
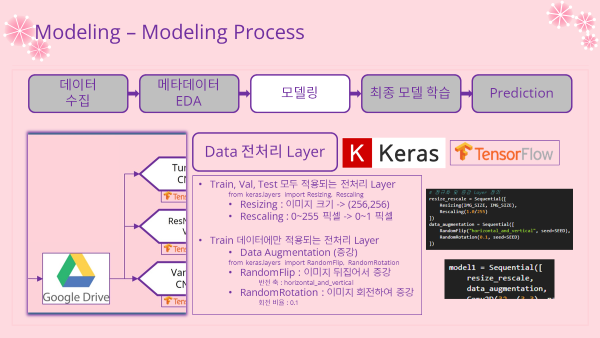
- 모든 데이터셋에 적용되는 전처리 Layer (정규화)
- Resizing : 이미지 크기를 (256,256)으로 맞춰줌
- Rescaling : 0~255의 픽셀값을 0~1의 값으로 정규화
- Train 데이터셋에만 적용되는 전처리 Layer (데이터 증강)
- RandomFlip : 랜덤하게 데이터를 수평 혹은 수직 방향으로 뒤집어서 데이터를 증강
- RandomRotation : 회전 각도에 변화를 랜덤하게 줘서 데이터를 증강
# 변수정보
IMG_SIZE = 256
SEED = 42
# 정규화 layer 정의
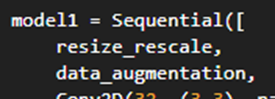
resize_rescale = Sequential([
Resizing(IMG_SIZE, IMG_SIZE),
Rescaling(1.0/255)
])
# 데이터 증강(Augmentation) layer 정의
data_augmentation = Sequential([
RandomFlip("horizontal_and_vertical", seed=SEED),
RandomRotation(0.1, seed=SEED)
])- 모델링을 할때 앞쪽에 전처리 레이어를 써서 전처리를 진행하도록 하였음
3-4. Vanilla CNN Model 기본 CNN 모델
- 노트 링크 : Modeling-Vanilla_CNN.ipynb
- 가장 기본적인 CNN 구조인 Vanilla CNN를 통해 모델링을 진행해봄
- 데이터 불러오고 전처리 레이어를 지정하는 부분까지는 위에 정리된 코드대로 진행함
- 모델 구조
- 데이터 특징 추출 Layer (총 2개의 Block으로 구성)
- Conv2D
- MaxPooling2D
- 데이터 분류 Layer (Flatten 후 은닉층을 거쳐 출력층으로 구성)
- Flatten
- Dense(relu) : 은닉층, 노드수는 64개
- Dense(softmax) : 출력층, 노드수는 3개(클래스 수)
- 데이터 특징 추출 Layer (총 2개의 Block으로 구성)
Library Import (모델별로 차이가 있어 따로 정리하였음)
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
import tensorflow as tf
from keras.utils import image_dataset_from_directory
from keras.models import Sequential
from keras.layers import Resizing, Rescaling, RandomFlip, RandomRotation
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense- Global 변수
class_list = ['CN', 'MCI', 'AD']
IMG_SIZE = 256
BATCH_SIZE = 32
CHANNELS = 3
EPOCHS = 10
SEED = 42Model Building (모델 제작)
input_shape = (BATCH_SIZE, IMG_SIZE, IMG_SIZE, CHANNELS)
model1 = Sequential([
resize_rescale,
data_augmentation,
Conv2D(32, (3,3), padding='same', activation='relu', input_shape=input_shape),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), padding='same', activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(64, activation='relu'),
Dense(3, activation='softmax')
])
model1.build(input_shape)
model1.summary()
'''
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (32, 256, 256, 3) 0
sequential_1 (Sequential) (32, 256, 256, 3) 0
conv2d (Conv2D) (32, 256, 256, 32) 896
max_pooling2d (MaxPooling2D (32, 128, 128, 32) 0
)
conv2d_1 (Conv2D) (32, 128, 128, 64) 18496
max_pooling2d_1 (MaxPooling (32, 64, 64, 64) 0
2D)
flatten (Flatten) (32, 262144) 0
dense (Dense) (32, 64) 16777280
dense_1 (Dense) (32, 3) 195
=================================================================
Total params: 16,796,867
Trainable params: 16,796,867
Non-trainable params: 0
_________________________________________________________________
'''Model Compile (모델 엮기)
- 옵티마이저 : adam
- 손실함수 : sparse_categorical_crossentropy
- 분류 문제이기 때문에 categorical_crossentropy 사용
- [0,1,2]로 label 되어있어 sparse 사용
- 평가지표 : Accuracy (정확도)
- Accuracy =

model1.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])Model Training (fit)
- batch_size : 32
- epoch 수 : 10
- validation도 함께 진행
history1 = model1.fit(
train_ds,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=val_ds
)- 마지막 epoch 결과
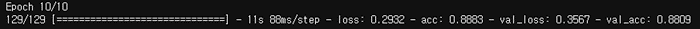
- 학습 곡선 그리기
loss1 = history1.history['loss']
acc1 = history1.history['acc']
val_loss1 = history1.history['val_loss']
val_acc1 = history1.history['val_acc']
plt.figure(figsize=(15,5))
plt.subplot(121)
plt.plot(loss1, label="train_loss")
plt.plot(val_loss1, label="validation_loss")
plt.title("Loss of Model\nSparse Categorical Entropy")
plt.legend()
plt.subplot(122)
plt.plot(acc1, label="train_accuracy")
plt.plot(val_acc1, label="valiadation_accuracy")
plt.title("Metrics of Model\nAccuracy")
plt.legend()
plt.show()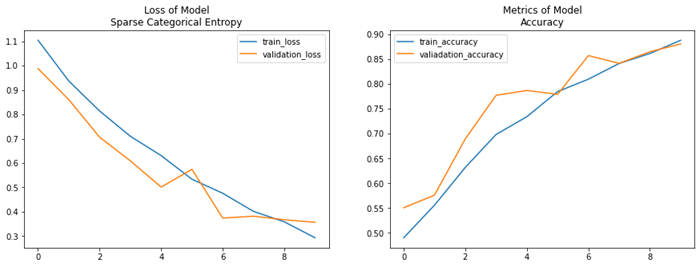
모델 저장 (Export)
- 예측 파트에서 비교분석에 쓰일 예정
model1.save(filepath="/content/drive/MyDrive/AI/Alzheimer/model1.hdf5")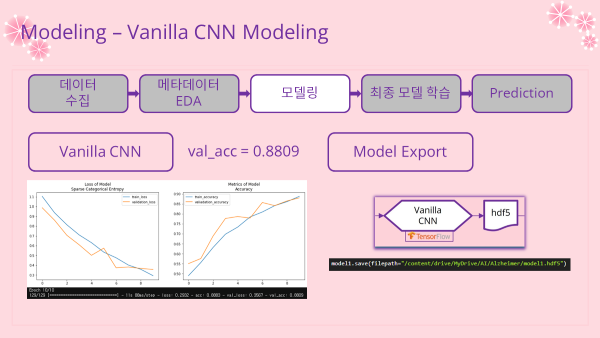
- 인사이트
- 검증 정확도(Accuracy)가 0.8809로 나쁘진 않은 성능을 보임
- 모델의 성능을 끌어 올리기 위해 두가지 방법으로 모델 개선 진행해보도록 하겠음!
- 전이학습 도입 (Part 4-1)
- 하이퍼파라미터 튜닝 (Part 4-3)
4. Model Improvement 모델 성능 개선
4-1. Transfer Learning 전이학습
- 노트 링크 : Modeling-ResNet50V2.ipynb
- 사전학습 모델을 불러와 전이학습을 진행해보았음
- 데이터를 불러오고 전처리 레이어를 지정하는 부분까지는 동일하게 진행하였음
- 사전학습 모델은 가장 많이 쓰이고 있는 ResNet 모델로 선택
- 모델 규모도 적절하면서 성능도 준수한 ResNet50V2로 진행
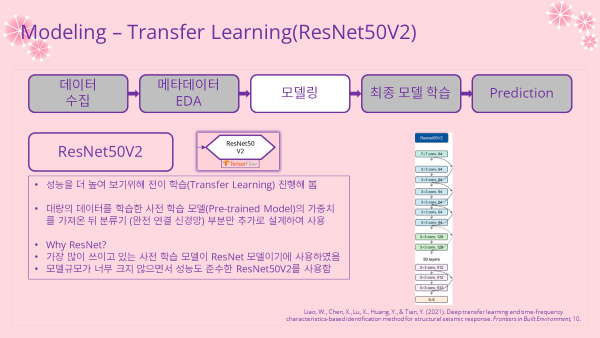
- 모델 구조
- 데이터 특징 추출 Layer
- Feature Extractor 부분만 불러와서 이용
- 가중치는 학습되지 않도록 설정
- 데이터 분류 Layer
- GlobalAveragePooling2D
- Dense(relu) : 은닉층, 노드수 = 1024
- Dense(softmax) : 출력층, 노드수(클래스수) = 3
- 데이터 특징 추출 Layer
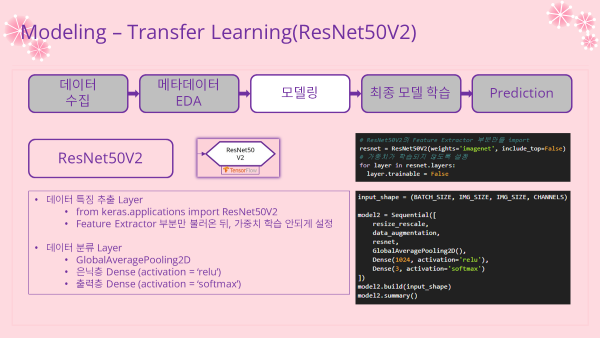
Library Import (모델별로 차이가 있어 따로 정리하였음)
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
import tensorflow as tf
from keras.utils import image_dataset_from_directory
from keras.models import Sequential
from keras.layers import Resizing, Rescaling, RandomFlip, RandomRotation
from keras.layers import Dense, GlobalAveragePooling2D
from keras.applications import ResNet50V2- Global 변수 지정
CLASSES = ['CN', 'MCI', 'AD']
IMG_SIZE = 256
BATCH_SIZE = 32
CHANNELS = 3
EPOCHS = 10
SEED = 42Model Building (모델 제작)
- ResNet50V2 불러오기
# ResNet50V2의 Feature Extractor 부분만을 import
resnet = ResNet50V2(weights='imagenet', include_top=False)
# 가중치가 학습되지 않도록 설정
for layer in resnet.layers:
layer.trainable = False- 모델 build
input_shape = (BATCH_SIZE, IMG_SIZE, IMG_SIZE, CHANNELS)
model2 = Sequential([
resize_rescale,
data_augmentation,
resnet,
GlobalAveragePooling2D(),
Dense(1024, activation='relu'),
Dense(3, activation='softmax')
])
model2.build(input_shape)
model2.summary()
'''
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 256, 256, 3) 0
sequential_1 (Sequential) (None, 256, 256, 3) 0
resnet50v2 (Functional) (None, None, None, 2048) 23564800
global_average_pooling2d_1 (32, 2048) 0
(GlobalAveragePooling2D)
dense_2 (Dense) (32, 1024) 2098176
dense_3 (Dense) (32, 3) 3075
=================================================================
Total params: 25,666,051
Trainable params: 2,101,251
Non-trainable params: 23,564,800
_________________________________________________________________
'''Model Compile (모델 엮기)
- 이전 모델과 동일함
model2.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])Model Training (fit)
- 이전 모델과 동일함
history2 = model2.fit(
train_ds,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=val_ds
)- 마지막 epoch 결과
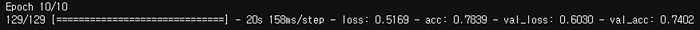
- 학습 곡선 (소스코드는 이전 모델과 동일)
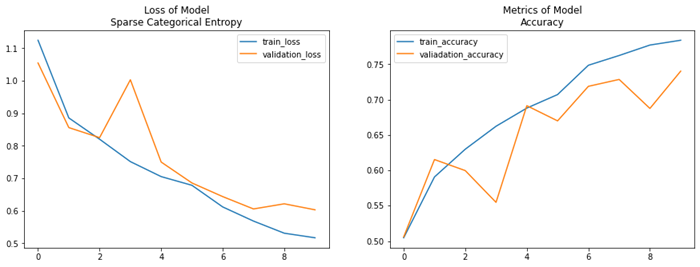
- 인사이트
- Validation score는 0.7402로 나타났음
- 이전 모델과 비교해서 성능이 오히려 감소하였음 (0.8809 -> 0.7402)
- 전이학습을 시행했을 때 오히려 성능이 감소하는 네거티브 전이 현상 발생
- Validation score는 0.7402로 나타났음
4-2. Negative Transfer 네거티브 전이
- 성능이 감소하는 네거티브 전이 현상에 대해 조사를 진행하고 정리하였음
- Negative Transfer : 관련성이 낮은 태스크 간에 전이 학습을 시도하면 도리어 성능이 악화되는 현상을 의미
- 따라서 전이학습을 적용한다고 항상 타겟 태스크의 성능이 높아지는 것은 아님
- 왜 그럴까?
- 전이학습은 사전훈련학습 데이터(훈련데이터)와 모델에 적용할 데이터(테스트데이터)가 동일한 분포를 따른다는 전제가 기본으로 깔려 있는 학습방법임
- 이는 전이학습 모델의 현재의 한계점으로 지적되는 부분이기도 함
- 예를 들어 설명해보도록 하자
- 만약에 '라면을 요리해주세요', '라면이 맞습니까?' 라는 태스크가 주어진다고 가정하자
- 경험이 적은 요리초보
- 기본 조리법대로 라면을 완성
- 완성된 라면을 라면이라 판단하기 쉬움
- 다양한 경험이 많은 요리사
- 경험에 비추어 훨씬 복잡한 레시피대로 라면 요리를 완성
- 완성된 라면을 라면이라 판단하기 어려울 수 있음
- 이처럼 때로는 사전학습을 진행하지 않은 경우가 오히려 더 좋은 성능을 나타낼 수 있다는 뜻
- 이러한 근거에 기반해 전이학습을 진행한 모델에 대한 저장 및 사후분석은 진행하지 않았음
4-3. Hyperparameter Tuning 하이퍼파라미터 튜닝
- 노트 링크 : CNN-Hyperparameter_Tuning.ipynb
- 기존 Vanilla CNN 모델의 하이퍼파라미터를 조정하여 성능을 개선해보자
- 데이터를 불러오고 전처리 레이어를 지정하는 부분까지는 동일하게 진행함
- 튜닝은 keras-tuner 라이브러리를 설치하여 진행함
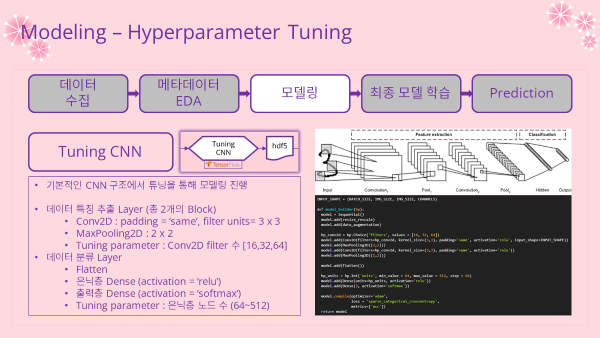
- 모델 구조
- 전체적인 구조는 Vanilla CNN과 동일하게 구성함
- 튜닝을 진행할 하이퍼파라미터
- 데이터 특징 추출 레이어
- Conv2D : filters (출력되는 채널의 수)
- 분류 레이어
- 은닉층 Dense : units (노드 수)
- 데이터 특징 추출 레이어
Library Import (모델별로 차이가 있어 따로 정리하였음)
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
import tensorflow as tf
from keras.utils import image_dataset_from_directory
from keras.models import Sequential
from keras.layers import Resizing, Rescaling, RandomFlip, RandomRotation
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras.callbacks import Callback
import IPython!pip install -U keras-tuner
import keras_tuner as kt- Global 변수 지정
CLASSES = ['CN', 'MCI', 'AD']
IMG_SIZE = 256
BATCH_SIZE = 32
CHANNELS = 3
EPOCHS = 10
SEED = 42Model Builder (함수형태로 튜닝할 모델 지정)
INPUT_SHAPE = (BATCH_SIZE, IMG_SIZE, IMG_SIZE, CHANNELS)
def model_builder(hp):
model = Sequential()
# 전처리 layer
model.add(resize_rescale)
model.add(data_augmentation)
# 튜닝 파라미터1
hp_conv2d = hp.Choice('filters', values = [16, 32, 64])
model.add(Conv2D(filters=hp_conv2d, kernel_size=(3,3), padding='same', activation='relu', input_shape=INPUT_SHAPE))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(filters=hp_conv2d, kernel_size=(3,3), padding='same', activation='relu'))
model.add(MaxPooling2D((2,2)))
model.add(Flatten())
# 튜닝 파라미터2
hp_units = hp.Int('units', min_value = 64, max_value = 512, step = 64)
model.add(Dense(units=hp_units, activation='relu'))
model.add(Dense(3, activation='softmax'))
# 모델 compile
model.compile(optimizer='adam',
loss = 'sparse_categorical_crossentropy',
metrics=['acc'])
return modelTuner 정의
- Tuning 라이브러리 : keras-tuner
- Tuning Method : Hyperband
- Tuning Object : Validation Accuracy
- 최대 epoch : 10
tuner = kt.Hyperband(model_builder,
objective='val_acc',
max_epochs=10,
factor=3,
directory=base_dir,
project_name='kt_hyperband')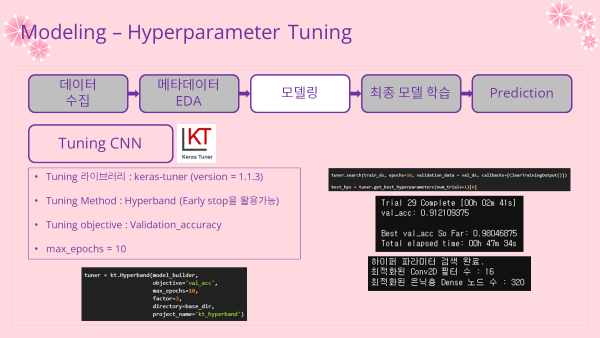
Callback 함수 정의
- 이전 출력을 지우는 Callback
class ClearTrainingOutput(Callback):
def on_train_end(*args, **kwargs):
IPython.display.clear_output(wait=True)튜닝 진행
tuner.search(train_ds, epochs=10, validation_data = val_ds, callbacks=[ClearTrainingOutput()])
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
'''
Trial 29 Complete [00h 02m 41s]
val_acc: 0.912109375
Best val_acc So Far: 0.98046875
Total elapsed time: 00h 47m 34s
'''- 최적화된 하이퍼파라미터 출력
print(f"""
하이퍼 파라미터 검색 완료.
최적화된 Conv2D 필터 수 : {best_hps.get('filters')}
최적화된 은닉층 Dense 노드 수 : {best_hps.get('units')}
""")
'''
하이퍼 파라미터 검색 완료.
최적화된 Conv2D 필터 수 : 16
최적화된 은닉층 Dense 노드 수 : 320
'''- 최적화된 파라미터로 Model Build
model = tuner.hypermodel.build(best_hps)
model.build(INPUT_SHAPE)
model.summary()
'''
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 256, 256, 3) 0
sequential_1 (Sequential) (None, 256, 256, 3) 0
conv2d_4 (Conv2D) (32, 256, 256, 16) 448
max_pooling2d_4 (MaxPooling (32, 128, 128, 16) 0
2D)
conv2d_5 (Conv2D) (32, 128, 128, 16) 2320
max_pooling2d_5 (MaxPooling (32, 64, 64, 16) 0
2D)
flatten_2 (Flatten) (32, 65536) 0
dense_4 (Dense) (32, 320) 20971840
dense_5 (Dense) (32, 3) 963
=================================================================
Total params: 20,975,571
Trainable params: 20,975,571
Non-trainable params: 0
_________________________________________________________________
'''모델 저장
- 튜닝 이후 Colab GPU 할당량 초과로 인해 모델을 저장하고 나머지 학습은 로컬에서 진행
model.save(filepath="/content/drive/MyDrive/AI/Alzheimer/model_tuned.hdf5")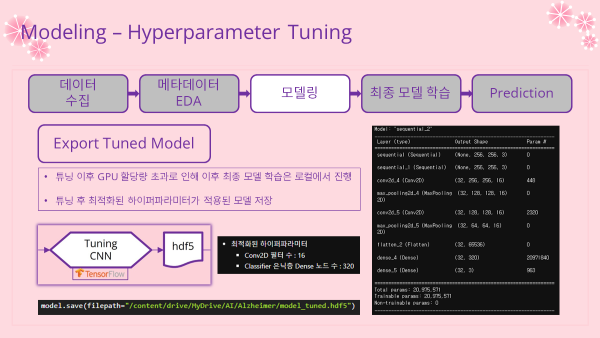
4-4. Final Model & Evaluation 최종 모델 학습 및 검증
- 최종 모델 학습 마무리 및 검증을 진행
- 노트 링크 : Final_Model.ipynb

최종 모델 학습
- 로컬 환경에서 진행하였음
- Colab에서 학습하고 저장했던 모델을 불러와서 진행
- Library Import
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
import tensorflow as tf
from tensorflow.keras.utils import image_dataset_from_directory
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint- Directory 지정 및 폴더 확인
base_dir = "./imagedata/"
data_dir = base_dir + "Axial"
os.listdir(data_dir)
'''
['AD', 'CN', 'MCI']
'''- Global 변수 지정
CLASSES = ['CN', 'MCI', 'AD']
IMG_SIZE = 256
BATCH_SIZE = 32
CHANNELS = 3
EPOCHS = 10
SEED = 42- 이미지 Data 불러오기
dataset = image_dataset_from_directory(
data_dir,
shuffle=True,
class_names=CLASSES,
batch_size=BATCH_SIZE,
image_size=(IMG_SIZE, IMG_SIZE),
seed=SEED
)
print(dataset.class_names)
'''
Found 5154 files belonging to 3 classes.
['CN', 'MCI', 'AD']
'''- Data Split
def dataset_split(ds, tr=0.8, val=0.1, test=0.1, shuffle=True, buf_size=10000, SEED=42):
ds_size = len(ds)
if shuffle:
ds = ds.shuffle(buf_size,seed=SEED)
train_size = int(ds_size*tr)
val_size = int(ds_size*test)
train = ds.take(train_size)
test0 = ds.skip(train_size)
val = test0.take(val_size)
test = test0.skip(val_size)
return train,val,test
train_ds, val_ds, test_ds = dataset_split(dataset)
print("Split전 Batched data 개수")
print(f"Dataset : {len(dataset)}")
print("\nSplit후 Batched data 개수")
print(f"Train : {len(train_ds)}")
print(f"Validation : {len(val_ds)}")
print(f"Test : {len(test_ds)}")
'''
Split전 Batched data 개수
Dataset : 162
Split후 Batched data 개수
Train : 129
Validation : 16
Test : 17
'''- Data Prefetch
train_ds=train_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
val_ds=val_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
test_ds=test_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)- Model import (모델 불러오기)
model_path = base_dir + "model_tuned.hdf5"
model = load_model(filepath=model_path)
model.summary()
'''
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 256, 256, 3) 0
sequential_1 (Sequential) (None, 256, 256, 3) 0
conv2d_4 (Conv2D) (32, 256, 256, 16) 448
max_pooling2d_4 (MaxPooling (32, 128, 128, 16) 0
2D)
conv2d_5 (Conv2D) (32, 128, 128, 16) 2320
max_pooling2d_5 (MaxPooling (32, 64, 64, 16) 0
2D)
flatten_2 (Flatten) (32, 65536) 0
dense_4 (Dense) (32, 320) 20971840
dense_5 (Dense) (32, 3) 963
=================================================================
Total params: 20,975,571
Trainable params: 20,975,571
Non-trainable params: 0
_________________________________________________________________
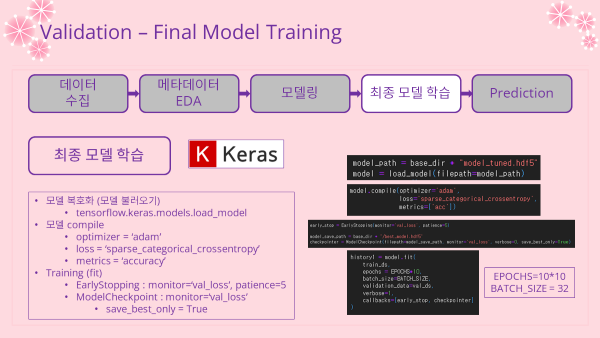
'''- Model Compile (모델 엮기)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])- Callback 함수 지정
- EarlyStopping
- 성능 모니터 기준 : val_loss
- 성능 개선 기준 epoch (patience) : 5
- ModelCheckpoint
- 모델 저장 기준 : val_loss
- save_best_only = True
- EarlyStopping
early_stop = EarlyStopping(monitor='val_loss', patience=5)
model_save_path = base_dir + "/best_model.hdf5"
checkpointer = ModelCheckpoint(filepath=model_save_path, monitor='val_loss',
verbose=0, save_best_only=True)- 모델 학습 (fit)
- epochs = 10x10 =100
history1 = model.fit(
train_ds,
epochs = EPOCHS*10,
batch_size=BATCH_SIZE,
validation_data=val_ds,
verbose=1,
callbacks=[early_stop, checkpointer]
)-
마지막 epoch
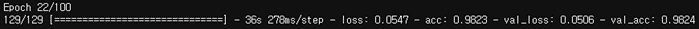
-
저장된 epoch
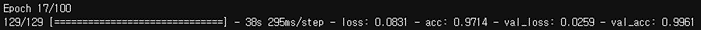
-
학습 곡선
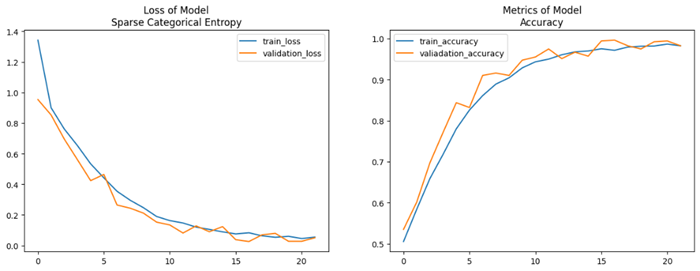
-
인사이트
- 저장된 모델의 validation accuracy : 0.9961
- 찍어서 맞출 확률인 chance level은 클래스가 3개이므로 0.3333
- Chance level과 비교했을 때 아주 뛰어난 성능의 모델이 완성되었음을 알 수 있음!
최종 모델 평가 Evaluation
- 저장된 모델 불러와서 Test dataset으로 평가 진행
model_best = load_model(filepath=model_save_path)
test_loss, test_acc = model_best.evaluate(test_ds, verbose=1)
print(f"test loss : {test_loss}")
print(f"test accuracy : {test_acc}")
'''
17/17 [==============================] - 1s 65ms/step - loss: 0.0502 - acc: 0.9853
test loss : 0.05021626874804497
test accuracy : 0.9852941036224365
'''- val_loss가 최소값이 되는 epoch의 인덱스 값을 확인
# val_loss 최소값, 인덱스 확인
print(np.min(val_loss1))
print(np.argmin(val_loss1))
print(np.argmin(val_loss1)-len(val_loss1))
'''
0.025903187692165375
16
-6
'''- 22번의 시도 중에서 오차가 최소가 되는 인덱스 값은 16 혹은 -6
- 인덱스는 0에서부터 세기 시작하고, epoch는 1에서부터 표기되므로 최적의 epoch 수는 16 + 1 = 17
- 17번째 epoch에서 오차가 최소가 됨
- Dataframe으로 만들어 보기
# 인덱스 16 혹은 -6이 최적화된 값이므로 이를 dataframe으로 만들기
train_l_m = [loss1[-6], acc1[-6]]
val_l_m = [val_loss1[-6], val_acc1[-6]]
test_l_m = [test_loss, test_acc]
loss_acc_dict = dict(zip(['train', 'validation', 'test'], [train_l_m, val_l_m, test_l_m]))
loss_acc_df = pd.DataFrame(loss_acc_dict, index=['loss','accuracy'])
loss_acc_df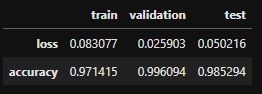
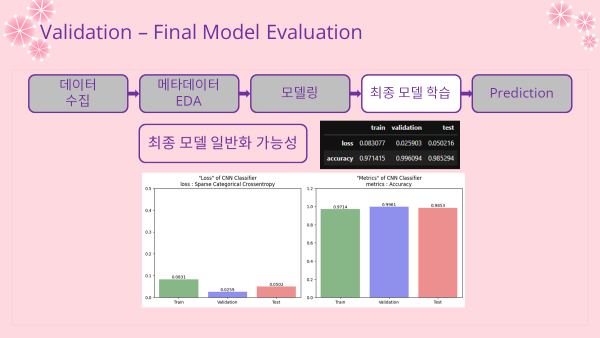
최종 모델 성능 및 일반화 가능성
- loss에 대한 barplot
loss_dict = dict(zip(['Train','Validation','Test'], [loss1[-6], val_loss1[-6], test_loss]))
loss_df = pd.DataFrame(loss_dict, index=['loss'])
loss_bar = sns.barplot(data=loss_df.round(4), palette=['green', 'blue', 'red'], alpha=0.5)
loss_bar.bar_label(loss_bar.containers[0])
plt.title('"Loss" of CNN Classifier\nloss : Sparse Categorical Crossentropy')
plt.ylim(0.0, 0.5)
plt.show()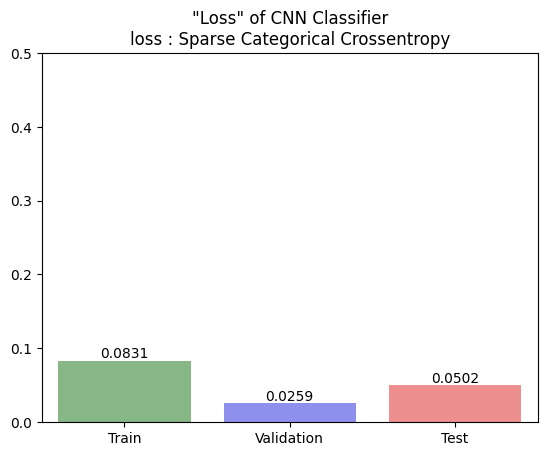
- accuracy에대한 barplot
acc_dict = dict(zip(['Train','Validation','Test'], [acc1[-6], val_acc1[-6], test_acc]))
acc_df = pd.DataFrame(acc_dict, index=['acc'])
acc_bar = sns.barplot(data=acc_df.round(4), palette=['green', 'blue', 'red'], alpha=0.5)
acc_bar.bar_label(acc_bar.containers[0])
plt.title('"Metrics" of CNN Classifier\nmetrics : Accuracy')
plt.ylim(0, 1.2)
plt.show()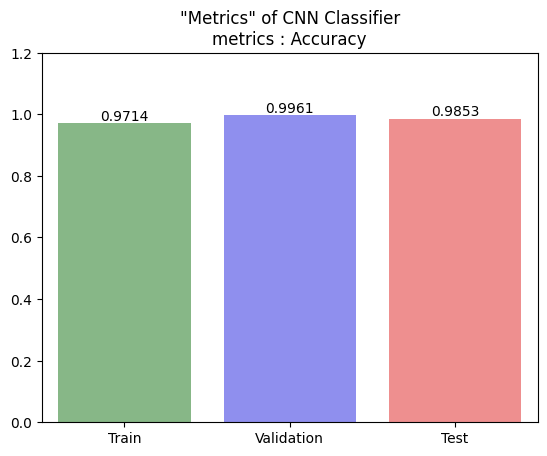
- 인사이트
- 성능은 0.9714~0.9961로 굉장히 좋은 성능의 모델임을 알 수 있음
- accuracy간의 차이가 거의 없다고 볼 수 있으므로 일반화도 굉장히 잘 된 모델임을 알 수 있음
(Part3~) 이후 과정
- 이후 과정은 다음 포스팅에서 다루도록 하겠음
- 남아있는 과정
- (3) 예측 및 결론 Prediction & Conclusion
- Prediction & Comparing 예측 및 비교분석
- Conclusion 결론
- (3) 예측 및 결론 Prediction & Conclusion

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer