이번 글은 SGD, GD, Mini batch SGD를 제대로 정리하기 위해 쓴다. 굉장히 자주 나오는데 머리 속에서 정리가 제대로 안돼서 개념을 한 번 짚고 넘어가야 할 것 같다.
일단, SGD는 Stochastic Gradient Descent, GD는 Gradient Descent를 의미한다. 하나하나씩 살펴보자.
1. Gradient Descent(Batch Gradient Descent)
일단, 세 가지 방법에 가장 기본이 되는 방법이다. 경사 하강법이라고도 불리고, parameter update시에 global minima를 찾기 위한 방법이다. 아래 그림이 예시로 가장 많이 쓰인다.
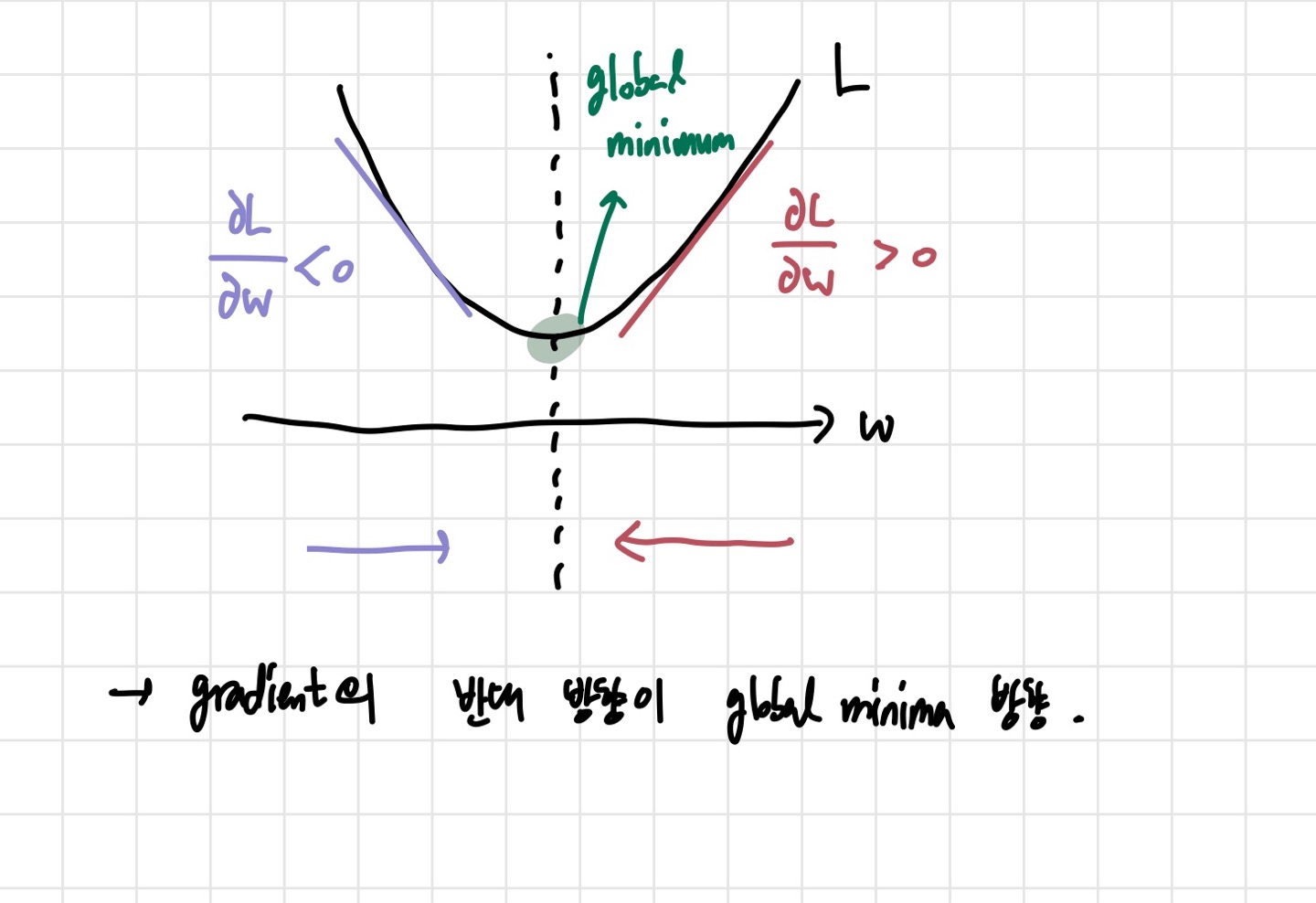
이 그림은 gradient descent를 직관적으로 이해하기에 좋은 방식 중에 하나이다. 물론 실제로 loss function은 이것보다 훨씬 더 복잡할 것이고, 도 엄청나게 많을 것이지만, 간단하게 하나의 parameter 를 업데이트 하는 과정을 알아보자. 어디서 시작할지는
의 초기화를 어떻게 하느냐에 따라 다르다. 만약 gradient가 양수라면, global minima의 방향은 거기에 (-) 를 붙인 방향일 것이고, gradient가 음수일 때도 마찬가지일 것이다. 그렇기 때문에 global minima의 방향은 gradient의 반대 방향이라고 생각할 수 있다.
이러한 방식으로 global minima 값에 가까이 간다. 위의 과정을 계속 반복하면 결국은 global minima에 도달할 것이기 때문이다. 이 과정을 수학적으로 나타내보자.
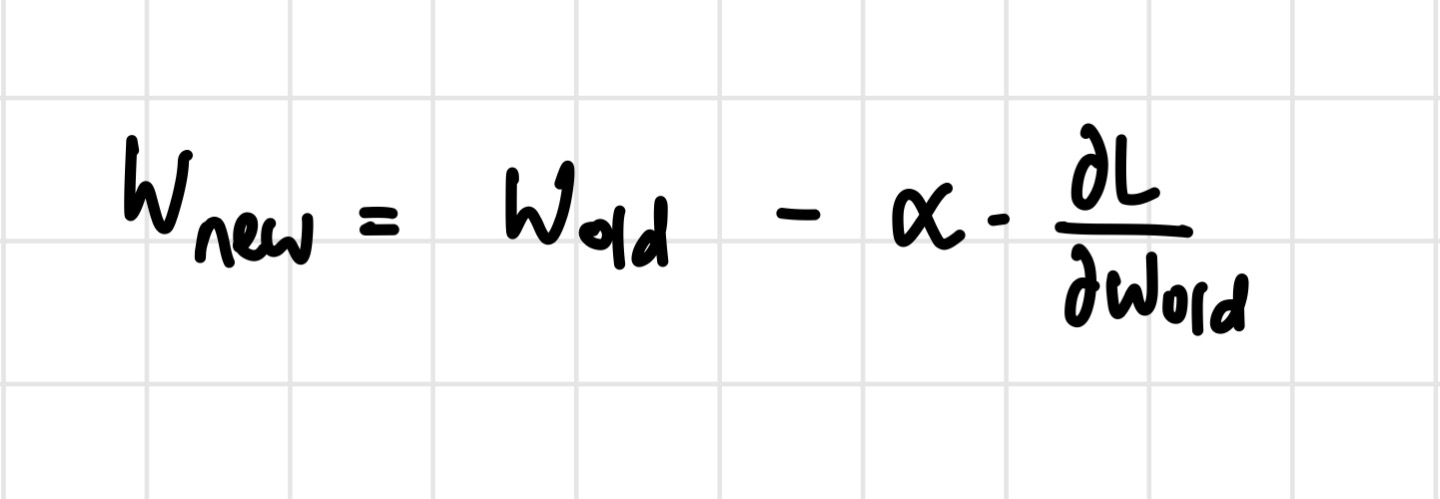
위의 식처럼 업데이트가 진행될 것이다. 마이너스가 붙는 이유는 앞서 언급한 gradient의 반대 방향으로 가기 위해서이다. 는 learning rate를 나타낸다. 참고로, 앞서 언급한 3가지 방법 모두 이 parameter update식을 사용한다.
이것이 Gradient Descent의 기본적인 메커니즘이다. 그렇다면 SGD, GD, Mini batch SGD 의 차이는 무엇일까? 가장 큰 차이는 한 번 parameter update를 진행할 때 데이터를 얼마나 보느냐에 있다. GD는 parameter update를 진행할 때 모든 데이터의 gradient 값을 다 고려하여 update한다.
2. Stochastic Gradient Descent
SGD가 나오게 된 이유는 간단하다. GD는 모든 데이터를 보고 global minima의 방향으로 parameter update를 진행하는데, 만약 데이터의 양이 방대할 경우 너무 오랜 시간과 많은 계산량에 시달리게 된다. 또한, local minima에 빠질 가능성도 존재한다. 이러한 문제를 해결하기 위해 SGD가 등장한 것이다.
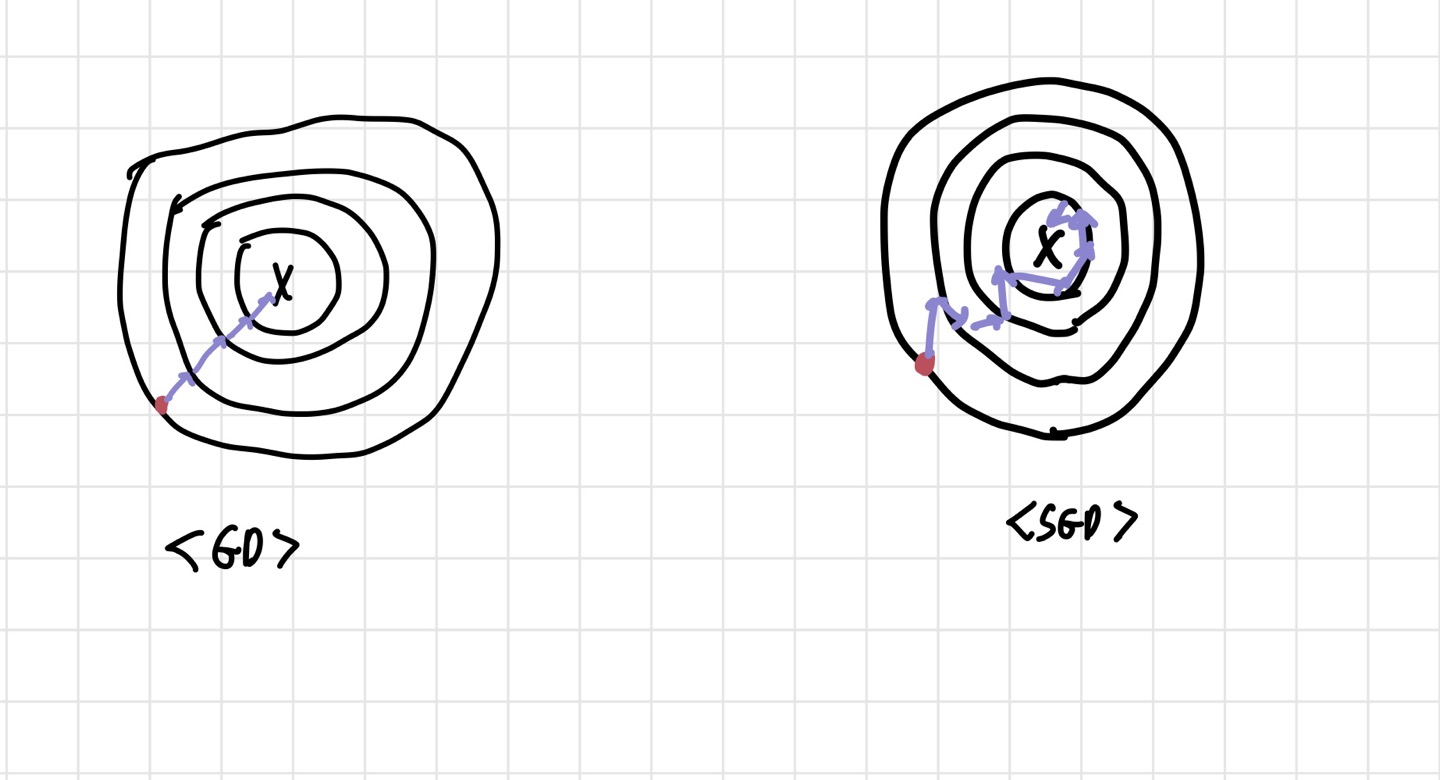
SGD는 데이터를 하나씩 random하게 뽑아 gradient를 계산해 parameter update를 진행한다. 이러한 randomess가 있기 때문에 stochastic이라는 워딩이 붙은 것이다. 이렇게 랜덤하게 뽑기 때문에 local minima에 빠질 가능성도 적고, 계산량도 적어진다. 단, 실제 GD를 했을 때의 정확한 gradient 값이 아닌 approximate한 gradient를 계산해서 update에 반영하기 때문에 수렴 경로가 조금 noisy 할 수 있다.
3. Mini Batch GD
SGD는 GD보다 계산량이 적고 속도가 빠르다는 장점이 있었지만, 수렴 경로가 noisy하다는 단점도 존재했다. 이를 보완한 것이 Mini Batch GD이다. SGD와 GD의 중간격이라고 봐도 될 것 같다. 한 번 업데이트하는데 모든 데이터를 다 봐도 문제가 있고, 하나씩만 봐도 문제가 있으니, 하나보단 더 많이 보자는 뜻이다. 즉, 한번 업데이트 하는데 적당한 사이즈의 mini batch를 뽑아서 보자는 뜻이다. 보통 batch size는 16,32,64,128,256 정도로 설정한다. 이 방법을 사용하면 GD보다 속도는 빠르고, SGD보다 오차가 적어지는 효과가 있다. 현재 가장 많이 사용하는 방법은 Mini Batch GD이다. 요새는 SGD와 Mini batch GD를 혼용해서 사용하는 것 같다.
