드디어 Deep Learning의 기초 논문들을 읽고 내가 관심이 있던 Super Resolution으로 들어올 수 있게 되었다. 그러나 막상 읽으려고 하니 사용하는 metric들이 낯설어 survey 논문으로 먼저 대략적인 개념을 잡고 가야 되겠다는 생각이 들었다. 읽은 논문은 비교적 최근에 작성된 "Hitchhiker's Guide to Super-Resolution: Introduction and Recent Advances", Moser et al. (2023) 이다. 처음 SR 분야에 대해 알아보는 사람에게 좋은 시작이 될 것 같은 논문이다. 내가 AI의 기초적인 내용을 훑고 SR 분야의 논문을 읽으려고 했을 때 직면한 가장 큰 문제는 loss function과 사용하는 metric이 image classification task와는 다르다는 것이었다. 그래서 논문을 이해하는데 어려움이 있었다. 그래서 이 글에서는 SR 논문에 등장하는 metric들을 이해하기 위해 Introduction, Setting and Terminology, Learning Objectives 파트만 다루려고 한다. 이 정도로 정리하고 SRCNN부터 읽기 시작하면 될 것 같다.
1. Introduction
딥러닝이 발달하면서, Super-Resolution(SR) 분야도 각광받고 있다. SR이 어떤 task인지부터 살펴보자.
Super-Resolution이란?
Super-Resolution은 저화질의 이미지를 고화질의 이미지로 향상시키는 task를 의미한다. 통상적으로 저화질은 Low Resolution(LR), 고화질은 High Resolution(HR)이라는 term을 사용한다. 응용 분야는 굉장히 다양하다. 위성, 의료, natural image등 다양한 영상에 사용될 수 있다. Deep Learning의 발달에도, SR task는 여전히 해결하기 어려운 문제이다. data에 굉장히 민감하게 모델의 성능이 좌우되는 ill-posed task이기 때문이다. 어떤 LR image를 HR image로 만들었을 때, 여러 개의 HR image가 하나의 LR image에 대한 정답이 될 수 있다. 이렇게 근본적인 불확실성이 있기 때문에 꽤나 복잡한 연구 분야로 알려져 있는 것이다.
2. Settings and Terminology
이 부분에서는 아래 4개의 질문에 대한 답을 제공한다. 하나씩 차근차근 살펴보자.
- SR이란 무엇인가?
- SR solution이 제안되었을 때, 그 방법은 얼마나 좋은 방법인가?
- SR task에 사용되는 dataset에는 어떤 것이 있나?
- SR 분야에서 이미지들은 어떻게 표현되나?
1) SR이란 무엇인가?
SR은 적어도 하나의 LR 이미지에서 HR 이미지들을 만들어 내는 방법들을 의미한다. SR은 크게 보면 두 가지 분야로 나눌 수 있는데, 그 두 분야는 SISR와 MISR이다.
- SISR(Single Image Super-Resolution): 하나의 LR image가 하나의 HR image를 만들어 낸다.
- MISR(Multi-Image Super-Resolution): 여러 개의 LR image가 여러 HR image를 만들어 낸다.
연구자들은 대부분 SISR method들을 만드는데 집중한다. SISR의 method가 MISR method로 확장될 수 있기 때문이다.
i) SISR (Single Image Super-Resolution)
위에서 언급했듯이, SISR은 하나의 LR image 를 하나의 HR image 로 scaling하는 과정을 의미한다. 사용되는 표현들을 정리해보자.
- : x와 y image의 width와 height
->- : 이미지 x에 담긴 pixel 수. ()
- : image x의 모든 가능한 position
오메가의 식에서 은 1부터 모든 자연수를 의미한다.
이제 LR와 HR image 사이의 관계를 정의해보자. scaling factor를 뜻하는 변수를 라고 하면, 위에서 언급한 height와 width들은 의 관계를 갖는다. 라고 정의해보자. 가 의미하는 것은 일종의 degradation이다. HR image를 LR image로 mapping하는 식인 것이다. 이렇게 를 정의하면, 우리는 x와 y의 관계를 아래와 같이 나타낼 수 있다.
: 가 가지는 parameter (ex) scaling factor s etc.)
실전에서 는 알려져 있지 않기 때문에 우리는 이를 모델링한다. Super-Resolution은 LR -> HR로 mapping해야 하기 때문에 의 inverse mapping으로 생각할 수 있다. 어쨌든 말한 것과 같이 모델링한 SR 모델 은 다음과 같다.
: HR 이미지에 대한 예측값, : 모델의 parameter
위의 식을 딥러닝의 관점에서 보게 된다면, 주어진 loss function을 최적화하는 식을 아래와 같이 작성할 수 있다.
ii) MISR (Multi-Image Super-Resolution)
MISR은 여러 개의 LR image에서 하나 혹은 여러 개의 HR image들을 얻는 것을 말한다. many-to-one, many-to-many approach라는 표현을 사용하기도 한다. 기본적으로 SISR의 연장선으로 생각하면 된다. 로 여러 개의 LR image가 주어지고, ( ) 이를 이용해 인 y를 예측하는 것이다. 이때, 이다. 이렇게 식으로 적어놓으면 어려워 보이지만, 그냥 여러 개의 이미지를 이용해 여러 개의 이미지를 출력한다는 것을 수학적으로 표현한 것에 지나지 않는다.
2) SR solution이 제안되었을 때, 그 방법은 얼마나 좋은 방법인가?
이 질문은 SR task의 성능을 평가하는 방법, 즉 Image Quality Assessment(IQA) 에 대한 내용을 다룬다. 좋은 image quality에는 다양한 요소들이 포함되어 있다. sharpness, contrast, noise의 제거 등이 좋은 image quality로 이어질 것이다. 여기서 sharpness는 'edge와 clarity가 얼마나 잘 복원되었는가' 라는 의미로 생각하면 된다.
IQA: 인간의 지각적 평가 (perceptual assessment)에 기반한 모든 metric을 의미한다.
쉽게 말하면 이미지가 SR 모델을 타고 나왔을 때 얼마나 사실적인가를 정량화한 metric인 것이다. IQA는 주관적(subjective) IQA, 객관적(objective) IQA로 나뉜다.
i) MOS (Mean Opinion Score)
MOS는 subjective IQA의 일종으로, 사람이 1~5점 사이의 점수로 이미지의 quality를 평가하는 방법이다. 모든 사람들의 점수를 평균 낸 것이 MOS이다. 사람이 직접 평가하기 때문에 신뢰성은 높지만, 사람들을 하나하나 찾아가서 이미지를 보여주고 점수를 얻기는 너무 복잡하고 시간도 오래 걸린다는 단점이 있다.
ii) PSNR (Peak Signal-to-Noise Ratio)
영상처리에서 많이 쓰이는 objective assessing method이다. subjective IQA의 단점과 더불어 task에서 사용하는 dataset의 크기가 크기 때문에 objective한 평가 방법도 중요하다. PSNR은 객관적 평가 방법으로 유명한 방법 중 하나이며, MSE와 MAX pixel value간의 비율을 가지고 quality를 측정한다. 식은 아래의 사진과 같다.
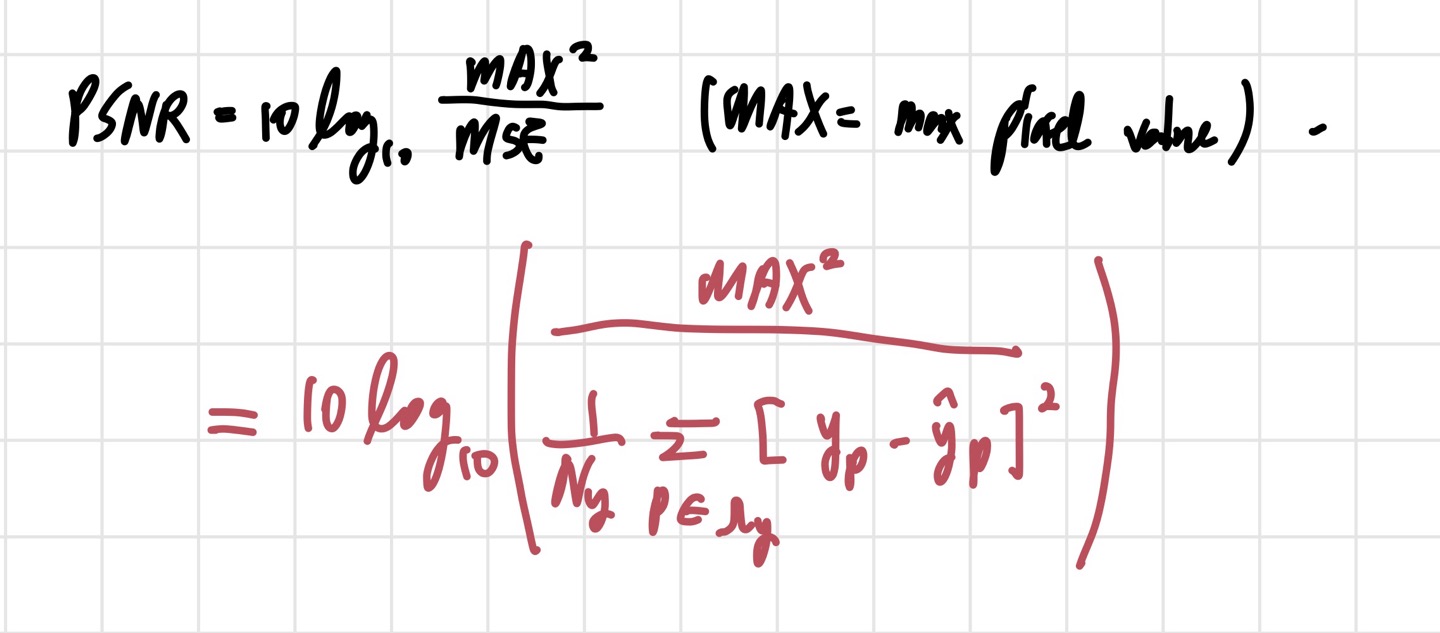
단위는 데시벨 scale(dB)를 사용한다. MSE가 낮으면 PSNR의 값은 커지고, 이는 좋은 image quality를 의미한다. 그러나 PSNR은 실전에서는 그다지 좋지 않은 결과를 낳을 수 있다. 예측값과 정답값의 pixel value 차이에만 집중하기 때문에 인간의 눈으로 봤을 때는 만족스러운 결과를 얻지 못할 수도 있기 때문이다. 이 말이 이해가 안간다면, 다음과 같은 예시를 생각해 볼 수 있다. 예를 들어 하나의 픽셀의 정답값이 1인데, 우리의 모델은 255로 예측했다고 하자. 오류가 254이고, MSE를 통해 이를 제곱하면 PSNR 값에 꽤 큰 영향을 줄 것으로 예상된다. 만약 이러한 픽셀들이 여러 개 있다면, PSNR 값은 더 낮아질 것이다. 그러나 인간의 눈으로 봤을 때, 하나의 픽셀의 오차가 큰 것은 그다지 영향을 주지 못한다. 이는 인간의 눈은 픽셀 값 그 자체가 아니라 구조에 더 집중하기 때문이다. 따라서 인간의 눈에 맞는 평가 방법이 등장하게 된 것이다.
iii) SSIM (Structural Similarity Index)
SSIM은 위에서 언급한 PSNR의 한계를 해결하려고 등장한 식이다. SSIM은 luminance, contrast, structures 세 가지 독립적인 요소들로 결정된다. luminance(휘도)는 빛의 밝기를 나타내는 용어이고, contrast(대비)는 이미지의 가장 밝은 부분과 가장 어두운 부분의 밝기 차이를 의미한다. 높은 대비는 밝은 부분과 어두운 부분이 뚜렷하게 구분되는 것을 나타낸다. SSIM은 인간의 perceptual assessment의 요구사항을 어느 정도 만족한다. 이제 luminance와 contrast를 표현하는 식을 알아보자.
위의 식에서 는 luminance를 뜻하고, 는 contrast를 의미한다. luminance는 intensity의 평균으로 예측하고, contrast는 intensity의 표준 편차로 예측한다. 논문에서는 를 표준편차라고 표현하기 때문에 논문의 식이 아닌 2번의 식이 맞는 것 같다. 이때, intensity는 특정 픽셀의 밝기를 나타내는 표현이다. 이렇게 예측한 를 가지고 similarity comparison function S를 정의한다.
- , (, )
위의 식들이 SSIM을 정의하는데 필요한 식들이다. 는 instability를 해결하고자 넣은 숫자들이고, 는 각각 luminance에 대한 comparison, contrast에 대한 comparison, structure에 대한 comparison을 의미한다. 주목할 것은 luminance와 contrast의 비교에는 앞서 정의한 Similarity comparison function이 사용되고, structure의 비교에는 covariance () 개념이 사용된다는 것이다. 이 모든 값들을 이용해 SSIM 값을 얻을 수 있으며, 는 양수인 adjustable parameter들이다. 식들의 모든 내용이 이해가 가지는 않지만, 이런 식으로 값을 얻는다는 것 정도만 알고 넘어가려고 한다.
iv) LPQ (Learninig-Based Quality)
LPQ는 연구자들이 MOS의 단점들을 딥러닝을 통해 보완하고자 만들게 된 방법이다. MOS의 주관적인 평가를 딥러닝을 통해 근사하는 것이다. LPQ 중 하나의 방법은 subjective score를 가지고 있는 dataset을 사용하는 것이다. (e.g. TID2013,DeepQA,NIMA) 딥러닝을 통해 두 개의 이미지를 비교하는 방법 중 하나를 살펴보자.
LPIPS (Learned Perceptual Image Patch Similarity): 딥러닝을 이용해서 feature를 뽑고 비교하는 방법이다.
VGGNet과 같은 extactor 를 통해 얻은 L개의 feature map을 사용한다.
은 각각 l번째 feature map의 height와 width를 의미한다.
는 scaling factor이다.
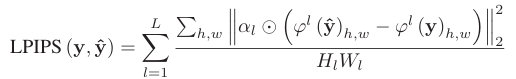
기본적으로 LPIPS는 위의 사진처럼 정의된다. 이 식을 제안한 저자들은 PSNR과 SSIM보다 인간의 눈과 비슷한 특성을 가진다는 것을 보여줬다. 그러나, LPIPS는 extractor의 성능에 따라 quality가 좌우된다는 것이 단점이다. 다른 식들도 많지만, 논문을 차차 읽어나가면서 정리하려고 한다.
v) TBE (Task Based Evaluation)
TBE는 이전의 방법들과 다르게 task-oriented feature에 집중하는 방식이다. SR 방식의 성능을 다른 CV task를 통해 평가하겠다는 의미이다. 예를 들어, SR 모델의 성능을 Image Classification과 같은 다른 task를 이용해 평가한다고 치자. 이때, SR를 일종의 전처리로 생각하고, SR를 적용한 것과 적용하지 않은 모델 두 개를 만들어 훈련시켜 성능이 개선되는지 보는 것이다. 만약 SR을 적용한 방식의 classification 성능이 더 좋았다면, SR의 성능도 좋다고 추측해볼 수 있다.
vi) Evaluation with Defined Features
이 방법의 하나의 예시는 GMSD(Gradient Magnitude Similarity Deviation)이다. 이 방법은 pixel-wise GMS(Gradient Magnitude Similarity)를 사용한다. 기본적으로 이미지의 gradient를 이용해 두 이미지의 similarity를 평가하겠다는 것이다. 인간의 눈이 gradient 변화에 민감하다는 것에서 영감을 얻어 만들어진 idea이다. gradient magnitude는 라고 표현한다.
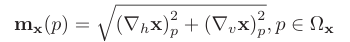
는 각각 horizontal, vertical gradient를 의미한다. 이렇게 얻은 gradient magnitude는 GMS map을 만드는데 사용된다.
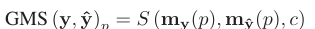
그리고 이렇게 얻은 GMS map의 평균을 취해주면 GMSD가 된다.
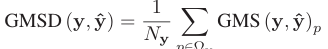
또 다른 방법 중에 하나는 FSIM(Feature Similarity) Index이다. 마찬가지로 gradient magnitude를 사용하지만, PC(Phase Congruency)라는 개념이 합쳐진다. 솔직히 이 부분은 제대로 이해하지 못했기 때문에 나중에 다시 다루겠다.
vii) Multi-Scale Evaluation
실전에서 SR 모델들은 각기 다른 scale에서 resolution enhancing을 진행하는데, 이를 MS(Multi-Scaling)이라고 한다. 이에 따라 기존의 metric을 바꿔줘야 한다. MS-SSIM index는 SSIM에 MS를 적용한 metric이다. 의 scaling 범위를 가지는데, 이미지를 부터 2로 계속 나눠주면서 downsampling을 한다. 이렇게 다양한 scale에서 enhancing을 진행하는 것이다. 각 scale에 대해 comparison을 계산하기 때문에 MS-SSIM은 아래의 식과 같이 표현할 수 있다.
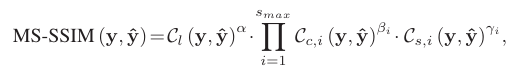
비슷한 논리로 GMSD도 변형시켜 사용할 수 있다.
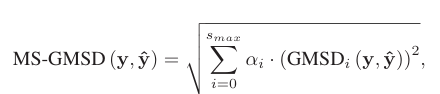
3) SR task에 사용되는 dataset에는 어떤 것이 있나?
SR 분야에서는 굉장히 광범위한 dataset들을 많이 사용한다. 아래 사진에서 보는 것과 같이 다양한 quality와 컨텐츠가 들어있는 dataset들을 확인할 수 있다.

datset들은 LR image와 HR image가 짝을 이루어 supervised learning에 적합한 방식으로 만들어지기도 하고, HR image만 주어지기도 한다. HR image만 주어졌을 경우, HR image에서 LR image를 생성하여 학습에 사용할 수 있다. 이때 LR image들은 bicubic interpolation과 같은 방법들을 이용해 생성된다. SR 분야에서 가장 유명한 challenge 2개는 NTIRE(New Trends in Image Restoration and Enhancement)와 PIRM(Perceptual Image Restoration Manipulation)이다. 여기서 만든 dataset을 사용하기도 한다.
4) SR 분야에서 이미지들은 어떻게 표현되나?(Color Spaces)
일반적으로 연구자들은 RGB color space를 많이 사용한다. 첫 딥러닝 기반의 SR model은 YCbCr space를 사용하기도 했다. YCbCr를 사용하는 경우, 기본적으로 Y channel만 이용한다. 어쨌든 최근에 가장 많이 사용되는 것은 RGB color space라고 보면 된다.
3. Learning Objectives
이제 SR 분야에서 사용하는 다양한 loss function들에 대해 알아보기 전에, 글을 쓰며 헷갈렸던 부분을 정리하고 넘어가려고 한다. 인공지능을 공부한다는 사람이 헷갈리면 안되는 내용이긴 하지만, 글을 쓰다 보니 등장하는 loss function과 metric의 정확한 차이를 설명하지 못했다. 따라서 내가 정리한 내용을 공유하려고 한다.
- loss function은 optimization을 하고, backprop이 일어나는 식이다. 일반적으로 사용되는 loss function에는 MSE, Cross Entropy loss 등이 있다.
- metric은 PSNR, SSIM과 같은 식들을 일컫는 말이다. metric은 모델의 성능을 평가하는 용으로 사용하는 식이며, backprop이나 parameter update 등을 하지 않는다.
헷갈린게 부끄럽지만 명확히 알아두어야 할 개념이기에 짚고 넘어간다. 이제 여러 가지 objective들을 알아보자.
1) Regression-Based Objectives
Regression-based objective는 input과 output의 관계를 명확하게 모델링하는 방식을 사용한다. 모델은 parameter들을 데이터에서 직접 parameter들을 추정한다. L1, L2 loss같은 objective가 이와 같은 식이다. L1, L2는 쉽게 사용할 수 있지만, 결과가 blurry한 단점이 있다. 이를 해결하기 위한 여러 가지의 방법들이 있다.
i) Pixel Loss
Pixel Loss는 pixel-wise difference, 즉 픽셀값 자체의 차이를 계산한다. 구체적으로는 L1, L2 loss가 있다.
- MAE (Mean Absolute Error): L1 loss를 의미하며, 식은 아래와 같다.
- MSE (Mean Square Error): L2 loss를 의미하며, 식은 아래와 같다.
- Charbonnier loss: 위의 두 개의 식 외에 유명한 loss 중 하나이다.
현업에서는 L2 loss가 outlier에 더 민감하게 반응하기(차이가 큰 건 더 크게, 차이가 적은 건 더 작게) 때문에 L1 loss를 더 많이 사용한다. 또한, 마지막의 Charbonnier loss의 을 적용하면 L1 loss와 동일하다.
pixel loss function들은 pixel-wise 계산이기 때문에 높은 PSNR 값을 선호한다. 앞서 언급했듯이, PSNR은 인간의 눈과 맞지 않기 때문에 pixel loss function도 인간의 눈과 그다지 맞지 않다. 또한, pixel loss를 사용하면 blurry한 사진을 얻는다고 한다. 이에 대한 해결책으로 사용해 볼 수 있는 것이 Uncertainty-Driven Loss이다.
ii) Uncertainty- Driven Loss
딥러닝에서 Uncertainty를 모델링하면 성능이 개선되고, robustness 또한 증가되는 효과를 얻을 수 있다. SISR를 위해 제안된 'adaptive weighted loss' 에 대해 먼저 알아보자. 기본적으로 인간의 눈은 smooth 한 지역보다 edge가 되는 pixel들에 더 예민하게 반응하기 때문에 그 부분에 우선순위를 두게 된다. 정리하자면, adaptive weighted loss는 모든 픽셀을 동일하게 취급하지 않겠다는 것이다.
을 를 parameter로 가지고, mean image 와 variance image 를 배우는 SR 모델이라고 하자. (Variance가 uncertainty를 나타낸다.) 그러면 예측값 는 아래와 같이 주어진다.
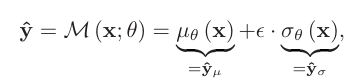
이때, 이다. 와 같이 I가 들어가 있는 이유는 이 여러 변수를 포함하는 다변량 변수이기 때문이다. 원래 보던 정규분포와 다를 바 없지만, 여러 개의 변수를 가지는 분포라고 이해하면 된다. 논문 저자에 따르면, image의 대부분의 구역이 smooth 하기 때문에 uncertainty는 대부분 sparse하다고 한다. 저자가 제안한 loss의 이름은 ESU (Estimating Sparse Uncertainty)와 UDL(Uncertainty- Driven Loss) 두 개이다.
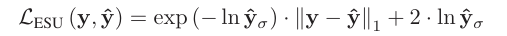
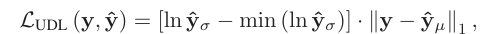
식은 위의 두 사진과 같다. 저자들이 처음 고안한 ESU를 관찰하다 보니, ESU loss가 모델의 성능을 저하시키고, SISR에 맞지 않는다는 것을 관찰했다. 이후에 수정된 것이 adaptive weighted loss인 UDL loss이다. 이렇게 정의한 식 중 로 를 배우고, 로 를 배운다. 단, 는 ESU를 통해 얻은 값으로 고정시키고 학습을 진행한다. 이렇게 굳이 두 단계로 학습을 나누는 것은 variance image가 다 0으로 되는 것을 방지하기 위해서라고 한다. 이런 방식으로 훈련을 진행하면 L1, L2보다 더 좋은 성능을 낸다고 한다. 두 단계로 나누어서 계산해야 하는 것이 training time 면에서는 단점으로 작용한다. 그러나 아직 이를 뛰어넘을만한 method가 등장하지 않았다고 한다.
iii) Content Loss
Content Loss는 예측 image와 정답 image의 차이를 비교하지 않고, 다른 domain으로 값들을 옮겨서 비교하겠다는 의미이다. 이 방법은 외부의 feature extractor를 사용하며, 대부분의 경우에 extractor는 VGGNet과 같은 CNN이다. feature extractor는 Image Classification과 같이 다른 task에서 pre-train 되어서 오며, feature map 간의 차이에 대해 SR 모델을 훈련 시킨다. 이때 pre-train된 extractor의 parameter는 고정시키고, target의 feature와 비슷한 feature를 가지는 이미지를 출력하는 것에 집중한다.
Content loss는 이러한 feature map 간의 차이를 설명한다. 식은 아래와 같이 쓸 수 있다.
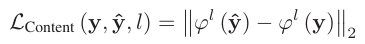
은 l번째 feature map을 의미하고, 식을 보면 예측된 feature map과 정답 feature map을 비교하고 있는 것을 확인할 수 있다. 이러한 방식의 가장 큰 목적은 pixel-level의 정보에 집중하지 않고, image의 feature들을 잡으려는 데에 있다. SRGAN이 이러한 loss를 사용한다고 한다.
2) GAN (Generative Adversarial Networks)
GAN은 여러 가지의 CV task에 다양하게 사용된다. Generator와 Discriminator의 2-player game 형식으로 학습이 진행된다. Generator는 주어진 dataset과 최대한 비슷한 output을 만들어내고, Discriminator는 실제 dataset과 Generator가 생성한 이미지를 구분해내는 역할을 한다. SR task에서는 SR 모델이 Generator가 된다. () Loss function은 아래의 사진과 같은 방식을 사용한다. 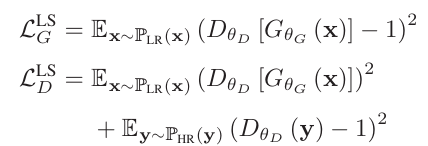
GAN은 블로그에서 이미 다룬적이 있기 때문에 자세히 설명하진 않겠다. 아래 링크를 타고 들어가면 GAN에 대한 내용을 볼 수 있다.
https://velog.io/@danlee0113/cs231n-13%EA%B0%95
연구 결과, 대부분의 adversarial loss는 hyper-parameter tuning과 random start를 통해 비슷한 score를 얻을 수 있음이 밝혀졌다. SR 분야에서도 adversarial loss가 사용되었을 때 더 나은 성능을 낸다고 한다. GAN의 가장 큰 문제는 training 시의 안정성이 떨어진다는 것이다. 이는 GAN의 구조적인 특징 때문에 생기는 문제다. regularization term을 통해 어느 정도 문제를 해결할 수 있다. 중요한 takeaway는 이전의 SR model들과 다르게 GAN 구조를 이용하면 인간의 눈으로 보기에 더 사실적인 output을 낼 수 있다는 점이다.
4. 정리
이렇게 논문의 일부를 정리했지만, 사실 많은 내용이 아직 이해가 가지 않는다. 내가 읽은 부분 중에 글에 언급하지 않는 내용들도 있다. 그러나 SR 분야에서 자주 사용하는 용어들을 많이 접했기 때문에 용어 공부를 했다고 생각하고 SRCNN부터 시작해서 다양한 논문들을 읽어보려고 한다.
