저번 글에서 정리한 survey 논문을 읽으며 기초적인 지식은 조금 쌓았으니, 이번에는 SR 분야에서 CNN을 처음 적용해 유의미한 결과를 낸 SRCNN 논문을 살펴보려고 한다. 논문의 정확한 이름은 "Image Super-Resolution Using Deep Convolutional Networks", Dong et al., 2014 이다. SRCNN은 간단한 구조로 이전의 SOTA를 능가하는 성능을 낸 모델이기도 하다. 차근차근 살펴보자.
1. 저자가 이루려고 한 것
SRCNN이 나오기 전에는 sparse-coding based method를 기반으로 한 A+와 같은 모델이 SOTA였다. 이러한 상황에서, 저자는 처음으로 SR에 CNN을 도입하여 이전 SOTA를 이기는 모델을 만들고자 하였다. 제안된 구조는 간단한 3-layer CNN이다. 이렇게 비교적 간단한 모델로 유의미한 성능 차이를 만들어 낸 것이 인상깊다. 또한, optimization에 꽤 어려움을 겪었던 이전 방법들과는 다르게, CNN을 도입해 optimization을 간결하게 한 것도 눈여겨 볼만 하다.
한마디로 정리하자면, 저자는 기존의 sparse-coding based method를 CNN의 관점으로 볼 수 있으며, 그것이 더 효율적이라는 주장을 한 것이다.
2. 주요 내용
1) SR의 문제
SR은 그 task가 가지는 근본적인 문제가 있다. ill-posed problem이라고 하는데, 이는 모델이 data에 굉장히 민감하게 반응하며, 성능 또한 좌우된다는 뜻이다. underdetermined inverse problem이라고 부르기도 한다. 왜 이런 문제가 생길까? 그 이유는 하나의 LR image에 대해 굉장히 다양한 HR image가 정답이 될 수 있기 때문이다. 이를 해결하기 위해 많이 사용되는 방법은 많은 prior 정보를 제공해 solution space를 어느 정도 강제해 주는 것이다. prior 정보를 배우기 위해서는 example-based 방법들이 많이 사용된다. LR과 HR image를 mapping하는 function을 배우거나, 유사도를 이용해 학습하는 방법들이 그 예시이다.
2) Sparse-coding based method
SRCNN이 등장하기 전 사용되던 방법이 Sparse-coding based method이다. sparse-coding based method는 deep learning을 사용하지 않고 SR model을 만드는 방법이다. 자세히 다룰 생각은 없지만, 여러 개의 basis vector를 만들어 이들의 linear combination으로 LR과 HR 이미지를 mapping 하는 방식이다. 나중에 이 부분에 대한 논문도 읽어보려고 한다.
SRCNN 논문 자체가 sparse method를 CNN의 일종으로 볼 수 있다는 아이디어에서 시작했기 때문에, sparse method의 파이프라인을 짚고 넘어갈 필요가 있다.
3) Sparse-coding based method pipeline
- LR image에서 patch들이 overlap(겹치게)되게 crop해주고, 전처리를 해준다.
- 얻은 patch들은 low resolution dictionary로 encoding된다.
- sparse coefficient들이 high resolution dictionary로 전달되고, HR dictionary를 이용해서 이미지를 복원(reconstruct)한다.
- 이렇게 overlap되는 복원된 patch들을 weighted averaging을 해서 최종 output을 내게 된다.
대부분의 external example-based method들은 위의 pipeline을 사용한다. 이러한 모델들은 dictionary를 학습하고 최적화하는 것에 집중한다. 그러나 dictionary를 제외한 나머지 절차들은 거의 optimize하지 않는다. (여기서 dictionary는 이미지 patch들을 위해 구한 basis들을 의미한다. 각 이미지 patch는 dictionary 속 basis들의 linear combination으로 표현할 수 있다.)
읽다 보니 왜 굳이 overlapping patch들을 사용하는지 궁금해졌다. 찾아본 결과, 더 정확하고 부드러운 HR image를 위해 overlapping은 굉장히 중요한 지분을 차지한다고 한다. 만약 overlapping을 사용하지 않고 patch들을 뽑는다고 가정한다면, 각 patch는 HR image 복원에 한 번씩 밖에 쓰이지 않을 것이다. 이렇게 되면, HR 이미지가 부드럽지 않고, 뚝뚝 끊기는 느낌으로 복원될 것이다. 반면에 overlapping patch들을 사용하면, 각 patch의 경계 값이 여러 번 복원에 사용되고, 그것의 weighted average로 최종 HR 이미지가 나오기 때문에 조금 더 부드러운 결과를 얻을 수 있는 것이다. 이후에 살펴보겠지만, SRCNN은 이러한 pipeline이 CNN과 같다는 생각에서 등장하게 되었다.
4) SRCNN (Super-Resolution Convolutional Neural Network)의 구조
본격적인 모델의 구조를 보기 전에 주목해서 봐야 할 포인트들을 짚고 넘어가려고 한다.
- SRCNN은 의도적으로 간단한 구조로 만드려고 노력했다.
- 간단한 구조임에도 이전 SOTA 모델보다 좋은 성능을 낸다.
- filter와 layer 개수가 많지 않기 때문에, CPU에 얹어서 사용해도 될만큼 online-use에 있어서 실용적이다.
- 더 큰 데이터 셋과 큰 모델에 훈련시킬 경우, 복원 퀄리티가 더 좋아질 가능성이 존재한다.
i) Contributions
논문의 주요 contribution에 대해 살펴보자.
- SR를 위한 Fully Convolutional Neural Network를 제안했다.
-> 모델은 LR과 HR 간의 직접적인 end-to-end mapping을 배우게 된다. (optimization도 end-to-end)
-> 전처리를 많이 하지 않는다.- Sparse-coding based method와 딥러닝 기반의 SRCNN 간의 관계를 정의했다.
- SR task에서 딥러닝이 좋은 성능과 실행속도를 가짐을 보였다.
아래 사진은 이를 증명하는 자료이다.
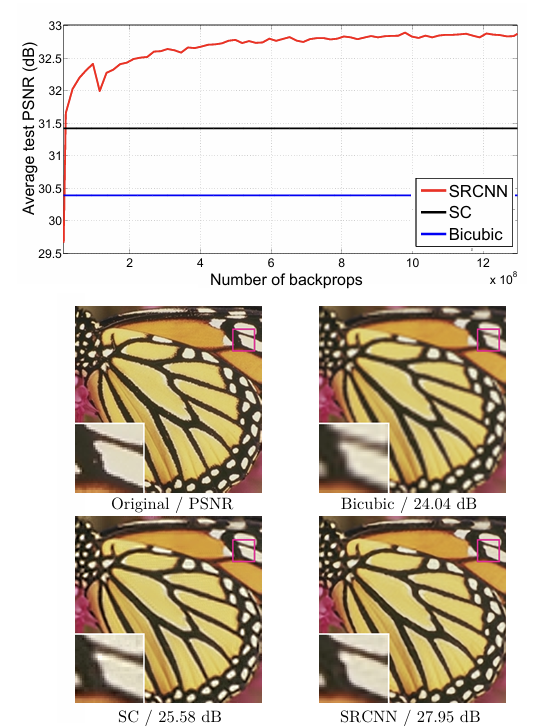
SRCNN의 PSNR값이 가장 큰 것을 확인할 수 있다. 그래프에 등장하는 bicubic은 가장 기본적인 보간법이고, SC는 앞서 봤던 Sparse coding method를 의미한다. 적은 backprop수로도 SC와 bicubic의 성능을 뛰어넘는 것도 인상 깊다.
ii) Formulation
LR 이미지 하나가 있다고 하자. 먼저, HR 이미지와 사이즈를 맞춰주기 위해 LR 이미지에 bicubic interpolation을 이용해 upscale한다. 이것이 학습 과정에서 유일하게 적용하는 전처리이다. 이렇게 interpolation 된 image를 라고 표현하자. 우리의 목표는 를 이용해서 를 출력하고, 가 최대한 ground truth HR image인 와 비슷하게 하는 것이다. 이때, upsample하긴 했지만, 는 아직 LR 이미지라고 표현한다. 요약하면, 우리가 배우고자 하는 것은 라는 mapping이 것이다. 는 3가지 부분으로 구성된다.
- Patch Extraction & Representation
- Non-linear Mapping
- Reconstruction
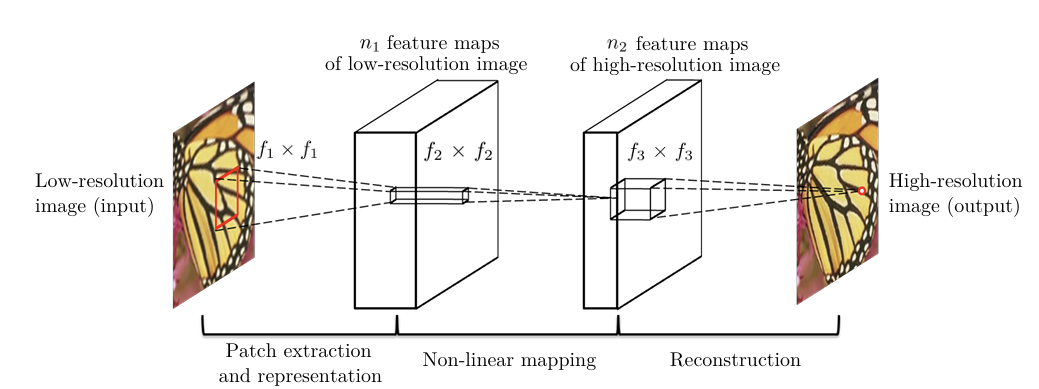
Patch Extraction & Representation
전통적인 method는 overlap 되는 patch들을 뽑고, PCA 등의 pre-trained basis들을 이용해서 representation을 구성했다. 이 과정은 CNN에서 이미지에 filter를 태우는 것과 동일하게 볼 수 있다. 이때, 각 filter는 basis로 볼 수 있다. SC(Sparse coding)와는 다르게, SRCNN에서는 basis와 동일한 의미를 가지는 filter를 optimization에 포함시킨다. 이 layer를 아래 식과 같이 표현한다.
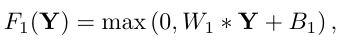
은 각각 filter와 bias를, 연산은 convolution을 의미한다. 또, 은 크기의 filter 개를 의미하며, 는 을 적용한 conv layer 1개인 것이다. 는 input image의 채널 수이다. 은 차원의 벡터이고, convolution 후 ReLU를 적용한다.
Non-linear Mapping
첫 번째 layer 통과 후, output channel의 개수는 이다. 두 번째 layer에서는 차원을 차원으로 mapping한다. 이 과정은 filter size가 1x1이라면 1x1 convolution을 적용하는 것과 같은 효과를 내고, 만약 3x3이나 5x5와 같은 filter size라면 그냥 일반적인 conv layer를 통과한다고 생각하면 된다.
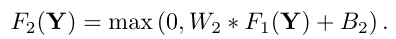
첫 번째 layer에서와 유사하게, 는 크기의 filter 개 가지고, 는 차원의 벡터이다. 여기서 의 차원은 추후에 reconstruction시에 사용할 HR patch에 사용된다.
Reconstruction
전통적인 SC 방식에서는 앞서 언급했듯이 overlapping HR patch들의 평균을 내서 최종 output을 뽑는다. 이때 평균을 내는 것은 CNN으로도 가능하다.
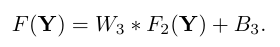
식은 역시 이전의 두 layer들과 같은 형식이며, 는 크기의 filter 개로 구성되어 있다. 물론, 역시 를 차원으로 가지는 벡터이다. output으로 이미지를 뽑아야 하기 때문에 채널을 input과 같은 개로 맞춰준다. 그런데 CNN이 평균을 내는 것과 같은 효과를 줄 것이라는 보장이 있는가? 내가 고민해보고 내린 답은 '있다'이다. CNN은 learnable filter를 가지고 있고, 우리는 output으로 HR image를 복원해 내야 한다. 그렇기 때문에 두 번째 layer에서 얻은 feature map을 세 번째 conv layer에 먹이면 우리가 의도하지 않았어도, 좋은 복원 퀄리티를 위해 averaging filter와 같이 학습된다는 것이다.
주목해야 할 것은
1. 세 개의 layer 모두 다른 직관에서 온 아이디어들이지만, 모두 Convolutional layer가 되었다는 것.
2. CNN 내의 모든 filter weight들과 bias들이 optimization에 포함된다는 것이다.
-> 이러한 점에서 SRCNN을 end-to-end mapping이라고 표현한다.
5) Sparse-coding based method와 SRCNN의 관계
이 부분에서는 Sparse-coding based method를 CNN으로 해석할 수 있음을 보인다. SC method에서, 크기의 LR patch를 뽑는다고 하자. 뽑힌 patch는 LR dictionary로 project 될 것이다. 이 dictionary의 size가 이라고 하자.
->이는 CNN에서 filter를 개 적용하는 것과 같은 연산으로 볼 수 있다.
그리고 나서 SC solver는 개의 coefficient들을 input으로 받아들여 개의 coefficient들을 output으로 내보낸다. (SC의 경우 로 대부분 설정한다.) 만들어진 개의 coefficient들은 HR patch 복원에 사용된다.
-> 이는 1x1 convolution의 의 특수한 케이스()라고 볼 수 있다.
그러나 SC가 SRCNN과 다른 점이라고 하면, SC method는 SRCNN처럼 feed-forward 형식이 아닌 iterative algorithm이라는 점이다. 반면, SRCNN은 feed-forward의 장점을 이용해 효율적인 계산이 가능하다. 참고로, SRCNN에서 위에서 언급한 'SC solver'에 해당하는 부분은 첫 두 layer이다.
이후 SC에서 개의 coefficient들은 HR dictionary로 project되고,HR 이미지가 출력된다. 이때, overlap되는 HR image patch들은 average된다.
-> 위에서 언급한 것과 같이, 이 과정은 SRCNN의 마지막 layer와 동일하다고 볼 수 있다.
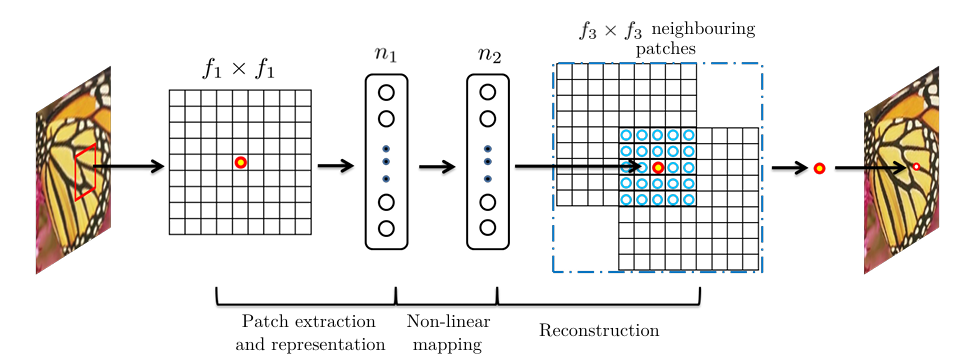
지금까지 설명한 것들이 위의 사진으로 나타나 있다.
6) Training
주어진 ground truth HR image를 라고 표현하고, 그에 대응하는 LR image를 라고 하자. 우리가 배우고자 하는 모델은 이고, 로 구성되었다. loss function으로는 MSE를 사용한다. 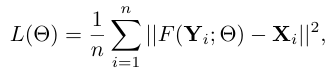
MSE를 loss function으로 사용하면, 모델은 높은 PSNR을 선호하게 된다. 꼭 PSNR만을 사용해야 하는 것은 아니다. CNN의 특성상 만약 PSNR이 아니라 미분 가능한 다른 metric을 적용하면, 그 metric에 맞게 학습이 진행될 것이다. PSNR은 인간의 눈과 비슷하다기 보다는, pixel difference를 최대한 줄이는 방향으로 학습한다. 인간의 눈으로 보기에 좋은 결과를 내기 위해서는 SSIM과 같은 metric을 사용하는 것이 좋다.
이제 본격적으로 training setting에 대해서 알아보자.
- SGD, 기본적인 backprop 사용 . 아래 식과 같이 parameter update가 진행됨.
- weight들의 초기화는 의 Gaussian 분포를 사용해서 random하게 뽑는다. (bias=0)
- learning rate: 첫 두 layer는 1e-4, 마지막 layer는 1e-5
- Conv layer의 padding=0
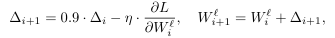
기본적인 세팅은 위와 같다. 또한, ground truth image인 에서 를 합성해주는 과정이 필요하다. 먼저, 에서 크기의 patch들을 뽑아준다. 논문에서는 이를 sub-image라고도 표현한다. 그런 다음 gaussian filter를 적용하고, upsample을 bicubic interpolation을 해줘 를 얻는다.
7) Experiments
위에서 정한 규칙으로 여러 가지 실험을 진행한다. SR은 YCbCr 중 Y 채널에만 적용되며(즉, c=1), PSNR과 SSIM도 Y 채널에 대해서만 평가된다. dataset은 ILSVRC-2013 ImageNet과 91-images dataset을 사용했으며, 로 설정한다.
i) Dataset
기본적인 네트워크의 세팅은 이다. Validation Set은 Set5(5개의 class로 구성된 dataset)를 사용한다.
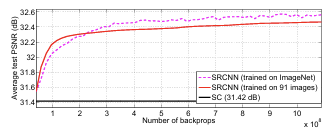
이러한 네트워크를 갖고 훈련시키면 위의 그래프에서처럼 ImageNet이 91-images dataset보다 더 좋은 성능을 낸다. 그래서 저자는 default training 시에 ImageNet을 사용한다.
주어진 데이터가 다양할수록 SRCNN의 성능이 올라간다는 것을 어느정도 증명하지만, 성능의 차이가 많아진 데이터에 비해 미미하다는 점은 좀 아쉽다.
ii) Model- Performance Trade-offs
위에서 정의한 의 세팅을 기본으로 performance와 속도간의 trade-off에 대해 알아보자. 
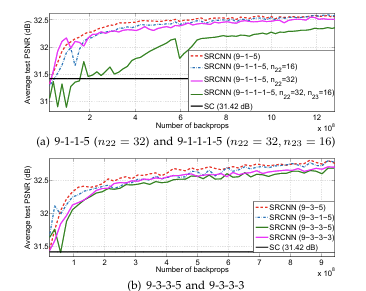
먼저 filter의 개수를 바꿔 실험해본다. ImaegeNet에서 train하고, Set5에서 testing을 진행한다. restoration 속도는 filter 개수가 적을수록 빠르지만, 모델의 성능은 filter 개수가 많을수록 좋아지는 것을 확인할 수 있다. (그러나 가장 성능이 안좋은 버전도 31.42dB의 SC 보다는 PSNR이 높다.)
filter 개수에 따라 restoration time과 모델의 성능 간의 Trade-off가 존재한다.
다음은 filter의 사이즈를 바꿔보는 실험이다. 들어가기 전에, 논문에서 사용하는 filter 사이즈에 대한 표현을 짚고 넘어가자. 와 같이 filter 사이즈가 주어지면, 9-1-5와 같이 표현한다. 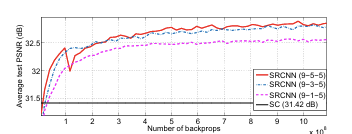
저자는 3개의 버전을 만들어서 실험해보았다. 구체적인 PSNR 수치는 의 backprop에서 끊었을 때 9-1-5 버전이 32.52dB, 9-3-5가 32.66dB, 9-5-5가 32.75dB 정도 나온다. 그래프를 보면 아래와 같이 정리해볼 수 있다.
filter size가 클수록 네트워크의 성능이 좋아질 것이라는 결론을 도출할 수 있다. 단, 속도 측면에서는 좋지 않은 영향을 준다.
마찬가지로, 속도와 네트워크 성능간의 trade-off가 존재한다.
마지막으로는 layer의 개수를 바꿔보는 실험이다. CNN의 layer를 늘리면 모델의 성능이 증가한다는 것의 잘 알려져 있기에, SRCNN에서도 이러한 실험을 해볼 필요가 있다. 추가되는 layer는 을 가진다. initialization과 learning rate는 기존의 두 번째 layer와 동일하다. 이 layer를 위의 실험에서 진행한 9-1-5, 9-3-5, 9-5-5 사이에 끼워넣는 방식으로 layer를 늘린다. 최종적으로 실험에 사용되는 세 가지 버전은 9-1-1-5, 9-3-1-5, 9-5-1-5이다.
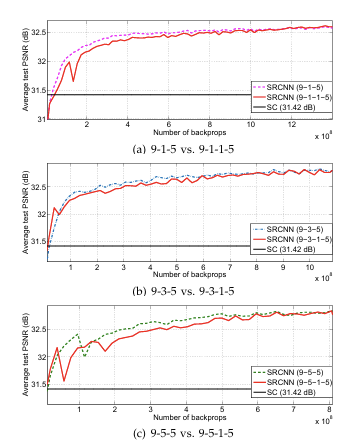
그래프를 보면, 다음과 같은 결론이 나온다.
1. 4-layer net이 3-layer net보다 수렴속도가 느리지만, 충분한 training timed을 주면 수렴한다.
2. depth를 늘리는 것이 무조건 좋은 성능을 보장하지는 않는다.
-> 수렴을 위해서 더 작은 lr을 사용해야 하고, 훈련 시간도 오래 걸리지만, 유의미한 성능차이가 나타나진 않는다.
물론 네트워크에 pooling과 FCL이 없어서 initialization과 lr에 더 민감한 것이지만, 수렴을 보장하는 lr을 찾는 것도 layer가 깊어질수록 어렵다. 심지어 수렴하더라도, local minimum에 빠져 좋은 성능을 내지 못할 수도 있다.
이러한 "deeper is not better" 현상에 대한 이유는 아직 연구해야 할 분야 중 하나라고 한다. (2014년 기준) 그리고, 깊이가 좋은 성능을 보장하지 않기 때문에 이후의 실험에서는 3-layer net을 사용한다.
iii) Color Channel에 대한 실험
이전의 실험은 Y channel만 가지고 진행했었다. 저자는 여기서 더 나아가 SRCNN이 별도의 네트워크 구조 변화 없이 더 많은 channel들을 이용해 학습할 수 있다고 주장한다. 그래서 우리가 많이 사용하는 RGB의 채널 개수인 c=3에 대해 실험을 진행한다. 구체적인 내용을 다루면 글의 분량이 너무 길어질 것 같다 적지 않겠다. 일단 결론은 아래 표로 확인할 수 있다.
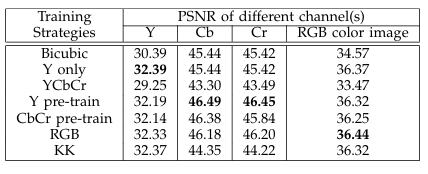
표의 내용은 다양한 내용을 말해주고 있지만, color 이미지는 RGB channel에 대해 학습시키는 것이 가장 좋은 성능을 낸다는 것이 key takeway이다.
8) SOTA와의 비교
이 섹션에서 사용하는 네트워크는 3-layer network로, 로 구성된다. 훈련에 사용된 dataset은 ImageNet이다. 또한, upscaling factor {2,3,4}에 대해서 네트워크를 훈련한다. 비교의 사용된 모델은 SC, NE+LLE, ANR, A+, KK 등이다. 각각의 모델들이 어떤 구조인지까지는 다루지 않겠다.
Test set으로는 Set5,Set14를 사용하며, 평가에 사용된 metric은 PSNR과 SSIM이다. 추가로 인간의 눈과 잘 align되는 NQM(Noise Quality Measure), WPSNR(Weighted PSNR), IFC(Information Fidelity criterion), MSSSIM(Multi-Scale Structure Similarity)도 도입한다. 이제 실험 결과를 살펴보자.
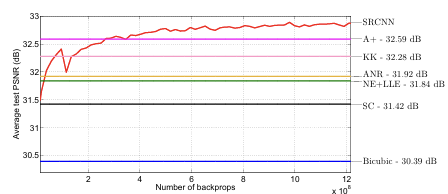
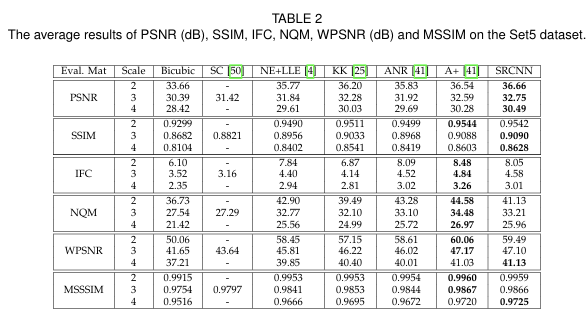
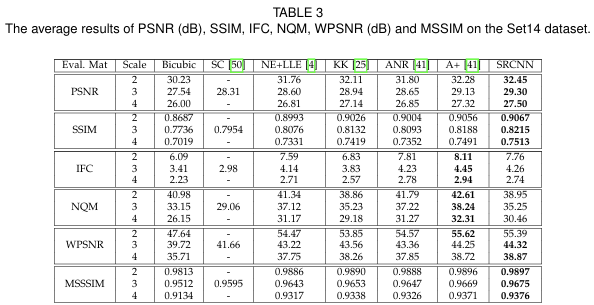
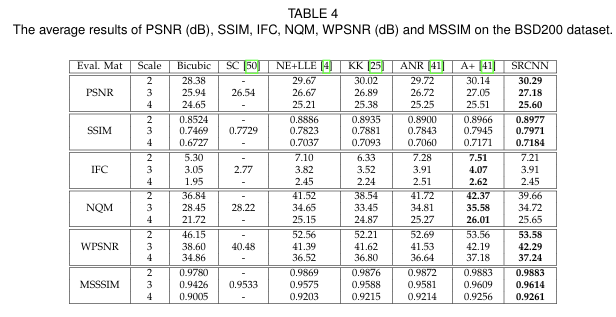
Table 2,3,4는 각각 다른 test set에 대한 결과를 보여준다. 각 metric에 대한 네트워크의 성능이 적혀 있으며, 모든 upscaling factor 2,3,4에 대해 실험한 것을 볼 수 있다. SRCNN은 의 backprop에서 멈춘 결과임을 알아두어야 한다.
upscaling factor 3을 보면, SRCNN의 PSNR값이 이전의 SOTA인 A+ 보다 0.15dB, 0.17dB, 0.13dB씩 높다.
또 하나 눈 여겨 볼만한 것은 SC와 bicubic method의 IFC와 NQM 점수이다. SC가 bicubic method보다 눈으로 보기에 더 좋은 성능인 것은 당연하다. 그러나 IFC와 NQM 점수는 bicubic이 더 높다.
이를 통해 우리는 IFC와 NQM이 우리의 눈과 같은 방식으로 image quality를 보지 않는다는 것을 알 수 있다.
전반적으로 SRCNN은 이전의 SOTA 값을 outperform한다는 결론을 낼 수 있다.
-> 저자들은 훈련 시간이 충분히 주어지면 더 나은 성능을 얻을 수 있을 것이라고 예측한다.

위의 사진을 봐도 SRCNN이 가장 sharp 한 edge를 만들어냄을 알 수 있다.
Running time도 모델의 성능을 평가하는데 중요한 요소 중 하나이기 때문에, 다른 모델들과 SRCNN을 이러한 측면에서도 비교해보아야 한다. 사용한 dataset은 Set14이다. SRCNN은 전반적으로 빠른 속도를 가지며, 그 중에 9-1-5 버전이 가장 빠름을 알 수 있다. 여기서도 이전에 언급한 모델 성능과 속도간의 trade-off가 관찰된다.
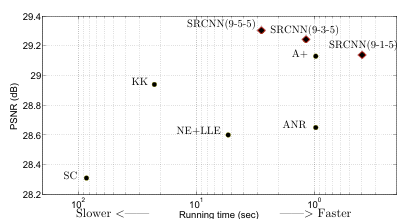
저자들은 이렇게 SRCNN의 속도가 빠른 이유는 feed-forward 구조 때문이라고 주장한다. 이전의 SOTA 모델들은 복잡한 optimization 문제들을 해결해야 하기 때문에 속도가 느려진 것이다.
3. 논문 내용의 실용성
SRCNN은 글을 작성하는 시점에서 많이 사용되지는 않는다. 많은 도메인들에서 그랬듯이, SR 분야에서도 Transformer를 적용한 method들이 SOTA를 지배하고 있다.
1. online use도 가능한 모델을 만들었다.
2. SR model에 CNN을 처음으로 도입해 좋은 성능을 내고, 모든 weight들의 optimization을 가능하게 함으로써 딥러닝이 SR 분야에도 잘 적용될 수 있음을 증명했다.
3. SRCNN과 Sparse-coding based method간의 관계를 설명했다.
이렇게 transformer가 SOTA를 지배하고 있음에도, SRCNN은 위의 내용들을 가능하게 했다는 점에서 아주 중요한 논문이라고 생각한다.
4. 더 찾아볼 내용
SRCNN에서 더 발전한 VDSR, SRGAN, EDSR/MDSR 도 쭉 이어서 리뷰할 계획이다. 이번에 논문을 리뷰하면서 등장했던 sparse-coding based method에 대한 내용을 더 알아보기 위해 관련 논문을 더 읽어보고 싶다. 따라서, 추후에 더 찾아볼 논문들 리스트는 아래와 같다.
1.Image Super Resolution as Sparse Representation of Raw Image Patches, Yang et al.
2. Image Super-Resolution via Sparse Representation, Yang et al.
3. VDSR-> SRGAN -> EDSR/MDSR
