논문 리뷰(14)- Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
논문 리뷰
이번에 살펴볼 논문은 SRGAN을 제안한 논문으로도 유명한 "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network", Ledig et al.(2017)이다. SRCNN, VDSR 논문에 이어서 세 번째 SR 분야의 논문이다. SRGAN은 그 이름에서도 알 수 있듯이, GAN에서 영감을 얻어 SR 분야에 맞게 변형한 모델이다. 등장 배경, Contribution, Method, 실험 내용들에 대해 더 구체적으로 알아보자.
1. 등장 배경
이 논문이 등장하기 전의 모델들의 상황에 대해서 살펴보자. 먼저 사용했던 기법들이다.
1) 이전 모델들이 사용한 기법
- 기존의 SR task 모델들은 주로 MSE를 loss function으로 사용하고, PSNR을 이용해 성능을 측정했다.
-> 높은 PSNR이 더 좋은 성능을 의미한다.- 이전의 naive한 approach: bicubic, linear, Lanczos와 같은 upsampling 기법들이 사용됨.
-> 속도는 빠르지만 과도하게 smooth한 texture 생성(low quality images) -> 점차 CNN 기반의 solution으로 발전하게 됨. ex) SRCNN- 이전 연구들에 의해 CNN은 layer가 깊을수록, Batch Normalization, skip connection, residual block과 같은 테크닉들을 사용할수록 좋은 성능을 내는 것이 밝혀짐.
-> SRCNN과 같은 논문을 통해 upscaling filter를 직접 학습하는 것이 성능 향상에 도움이 된다는 것 또한 밝혀짐.- SRGAN에서와 같이 GAN을 이용해 SR task를 해결하려는 연구들이 있었음.
-> 대부분 MSE를 loss로 사용하고, VGGNet의 feature map을 이용해 학습함. (기존의 pixel space를 input으로 사용하던 것에서 변화된 기법)
2) 이전 모델들의 문제점
다음은 이전의 기법들이 가지는 문제점에 대해서 알아보려고 한다.
- upscaling factor가 큰 경우(ex) 4배), SR를 시행한 결과물의 texture detail이 떨어짐.
- 이전 논문들에서는 높은 PSNR이 높은 성능을 의미하지만, PSNR이 높다고 해서 무조건 시각적으로 더 좋은 퀄리티의 이미지를 보장하는 것은 아님. (Peceptually unsatisfying)
-> MSE를 loss function으로 사용하는 것이 좋은 생각이 아닐 수도 있음.
-> 우리가 이미지를 보는 방식과 같은 방향성을 가지는 loss function의 필요성이 대두된 것!
SRGAN은 위와 같은 당시의 문제들을 해결하고자 연구되었다.
2. Contribution
이제 SRGAN의 contribution에 대해 알아보자.
- Image SR 분야에서 4X upscaling의 SOTA 달성. (PSNR, SSIM 기준)
-> 뒤에 살펴볼 SRResNet + MSE 조합으로 달성함.- MSE 대신에 Perceptual Loss function을 도입해 더 좋은 퀄리티의 이미지를 생성.
-> Perceptual Loss = Content Loss + Adversarial Loss- MOS(mean opinion score) 기준으로도 4X image SR 분야에서 SOTA 달성.
크게 보면 위의 세 개가 SRGAN의 가장 큰 contribution들이다. 구체적으로 사용된 method들을 살펴보기 전에 이 논문에서 중요하게 살펴봐야 할 부분에 대해 짚고 넘어가려고 한다. 먼저, SRResNet과 SRGAN을 구분해서 이해해야 한다. 또, 기존에 사용해 오던 Loss function에 변화를 주었기 때문에 Loss function의 어떤 부분이 변화했는지, 그리고 loss function에 각 부분은 어떤 역할을 하는지와 같은 것들에 집중하면 이해하는데 많은 도움이 될 것 같다.
3. Methods
1) 표현 정리
원활한 이해를 위해 논문에서 사용하는 기호들이나 표현들에 대한 정리를 할 필요가 있다.
- : Low Resolution(LR) image를 의미함. (size: HxWxC)
- : High Resolution(HR) image를 의미함. (size: rHxrWxC)
- : 을 입력으로 사용해 super resolve 한 예측값 이미지. 이 모델을 타고 나온 결과.(size: rHxrWxC)
- : loss function을 의미함
- r: downsampling factor
기본적으로 사용하는 기호들은 다 다뤘다. 이들이 어떤 관계를 이루는지도 짚고 가면 좋을 것 같다.- 과 은 SR task에서 흔히 말하는 input pair이다.
->에 Gaussian filter를 적용하고 r만큼 downsample한 것이 이다. () - = (는 뒤에 나올 generator network를 의미함.)
- 과 은 SR task에서 흔히 말하는 input pair이다.
2) Architecture
이제 사용되는 network들의 architecture를 살펴보자. 크게 Generator Network와 Discriminator Network가 있다. 일반적인 GAN과 유사하게, Generator는 Discriminator가 실제 사진과 예측값 사진을 구분하지 못하도록 최대한 실제 사진과 같은 예측값 이미지를 만들어내는 것을 목표로 한다. 또, Discriminator는 Generator가 생성한 이미지와 실제 사진을 구분해낼 수 있도록 하는 것이 목표이다. 구체적으로 각 network를 살펴보기 전에 포괄적인 내용을 담고 있는 수식을 소개하겠다.
를 생성하기 위해 CNN 기반의 Generator network를 훈련시킨다. 이때의 parameter는 로 표현된다. 위의 식은 단순하게 loss를 최소화하는 방향으로 를 업데이트한다는 내용으로 이해하면 된다. 이제 Generator와 Discriminator의 구조를 알아보자. 기본적으로 GAN의 구조를 따라가기 때문에, 아래의 min-max 최적화 문제를 해결한다.
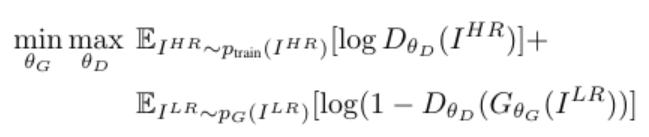
위의 식은 기존의 GAN의 min-max 식과 비슷하다. 다만 input의 표현 방식이 조금 바뀐 것 뿐이다. 아래의 원래 GAN 식과 비교해보자.
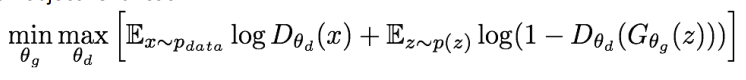
원래의 GAN 식에서 대신에 을, 대신에 을 넣으면 SRGAN의 min-max 식을 얻을 수 있다. 그 이후부터는 GAN의 식을 해석하듯이 하면 된다. Discriminator의 출력값은 [0,1] 의 범위를 가지고, 들어간 이미지가 실제일 확률을 의미한다. 그렇기 때문에 실제에 가까운 데이터라면 1에 가까운 값이, 가짜 데이터라면 0에 가까운 값이 출력될 것이다.
Discriminator의 목표: generator가 생성한 이미지 = 0, 실제 이미지 = 1로 판별하는 것
-> ,
Generator의 목표: 자신이 생성한 이미지를 discriminator가 진짜라고 판별하게 하는 것
->
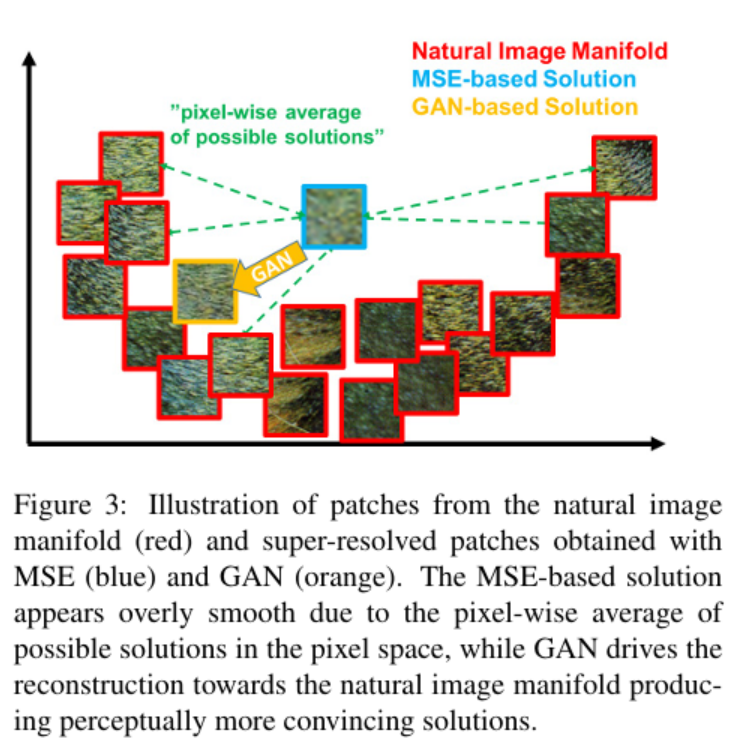
이때, Discriminator와 Generator의 parameter는 다르기 때문에 번갈아가면서 의 update를 진행한다. 하나는 min, 하나는 max 값을 찾기 때문에 최대한 두 값을 모두 만족하는 지점을 찾는 것을 목표로 한다. 이러한 방식은 pixel 값들을 평균해서 계산하는 MSE 기반의 방식들과는 다르게 perceptually satisfying한 결과를 얻을 수 있게 해준다. 논문에서는 "perceptually satisfying solutions residing in the manifold(subspace) og natural images" 라고 표현한다. 아래 사진을 참고하면 이해하는데 도움이 될 것 같다.
 이제 Generator와 Discriminator의 구체적인 구조에 대해서 알아보자.
이제 Generator와 Discriminator의 구체적인 구조에 대해서 알아보자.
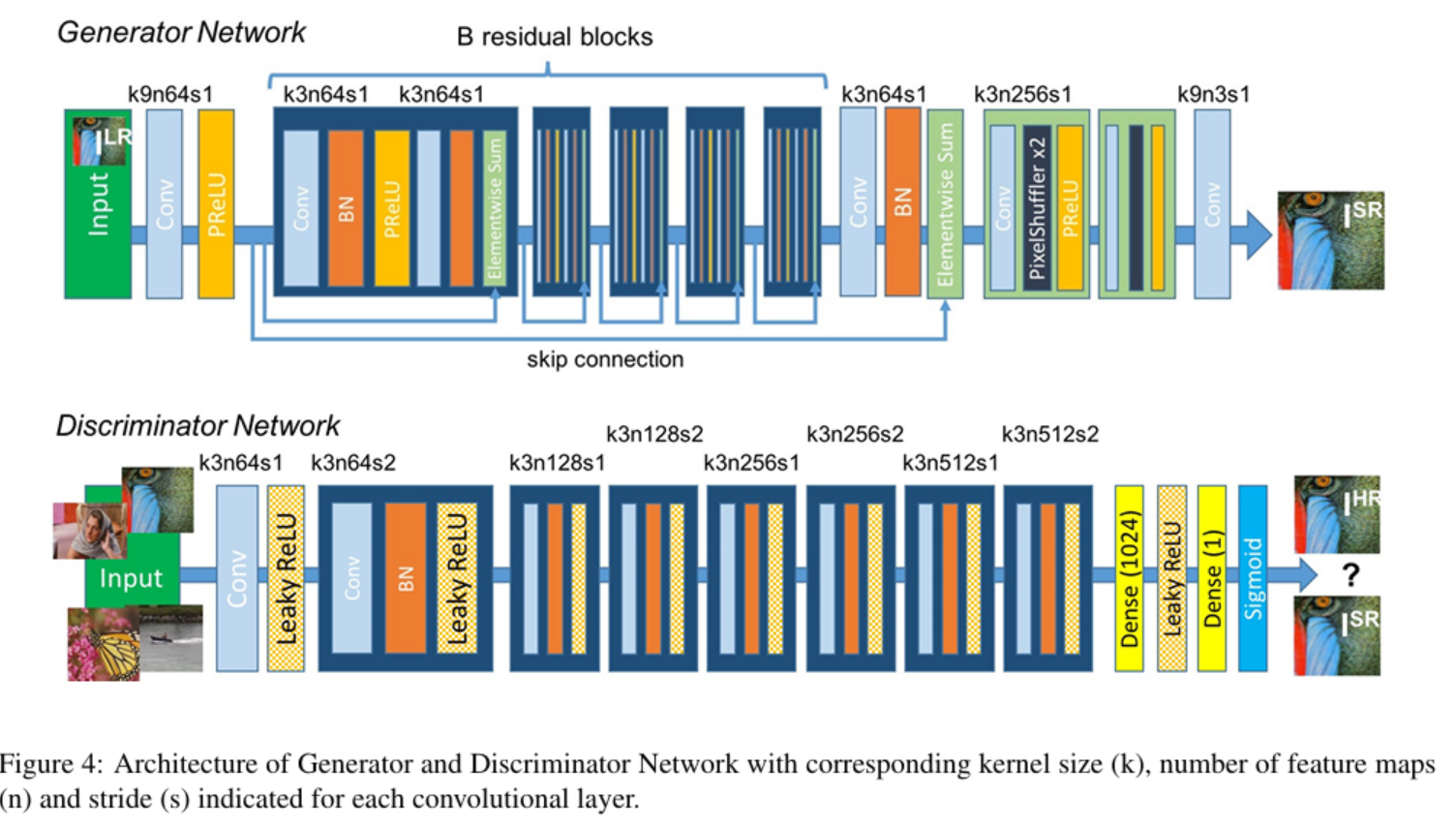
Discriminator Network(D)
위의 사진을 보면 Discriminator의 구조를 확인할 수 있다. 사용한 네트워크의 주요 스펙은 아래와 같다.
- Leaky ReLU (
- no max pooling
- conv layer 총 8개 (3x3 kernel, 64부터 512까지 단계별로 feature map 크기 증가)
- 이미지 resolution을 줄이기 위해 strided conv 사용.
-> 이미지가 진짜인지 아닌지 판별하기 위해 resolution을 줄여나가야 함.- 이후 2개의 dense layer- sigmoid를 통해 0~1 사이의 확률값을 얻게 됨.
Generator Network(G)
마찬가지로 위의 사진에서 Generator 구조도 확인할 수 있다. 주요 스펙은 아래와 같다.
- B개의 block: (conv layer 2개, 3x3 kernels, 64 feature maps) - Batch Normalization - ParametricReLU
- 이후 2개의 sub-pixel conv layer를 통해 input image의 resolution 증가시킴. (Upsampling)
위에서 ParametricReLU는 아래의 식과 같이 x가 음수일 때의 기울기를 학습할 수 있는 ReLU를 의미한다.
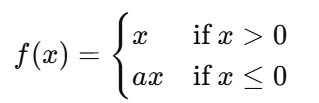
의외로 Generator와 Discriminator의 구조는 그리 복잡하지 않은, 그 동안 봐왔던 CNN network의 구조이다. 우리가 집중해서 봐야 할 것은 다음에 등장하는 Perceptual Loss이다.
3) Perceptual Loss Function
이번 논문에서 가장 중요하다고 생각하는 부분이다. 위에서 봤듯이, 기호는 을 사용한다. 식부터 먼저 살펴보자.
위에서 은 VGG loss based content loss를 사용했을 때의 최적의 값이고, 다른 loss를 사용한다면 다른 값이 더 좋은 성능을 보장할 수도 있다. 식에서 볼 수 있듯이, Peceptual Loss는 두 가지 loss의 합(weighted sum)으로 이루어져 있다. 첫 번째 term인 는 content loss라고 부르며, 두 번째 term인 은 adversarial loss라고 부른다. 각 loss가 어떤 역할을 하며, 어떤 부분에 집중하기 위해 고안되었는지 알아볼 필요가 있다.
Content Loss ()
논문에서 실험에 사용한 Content loss에는 MSE Loss와 VGG Loss가 있다. 실험 시 비교를 위해서 MSE Loss를 넣은 것 같다. 뒤에 실험 파트에서 보겠지만, 최종적으로 좋은 성능을 낸 것은 VGG Loss이다.
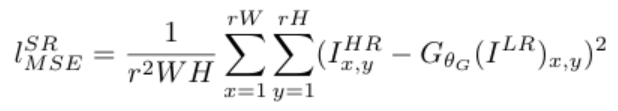
MSE loss는 위의 식과 같이 정답값인 과 예측값인 의 차이의 제곱을 모두 더해 평균을 내는 것을 알 수 있다. 이렇게 평균을 내기 때문에 앞서 언급한 것과 같이 시각적으로 좋은 결과를 무조건적으로 보장하지 않는 것이다. 그래서 저자들이 제안하는 것이 VGG loss이다.
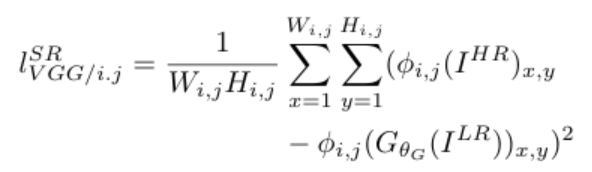
VGG loss에서는 pretrained VGG-19을 사용하며, 는 j번째 conv layer에서 나온 feature map 중에 i번째 max pooling layer 전의 feature map을 의미한다. 또, 는 j번째 conv layer에서 나온 feature map 중에 i번째 max pooling layer 전의 feature map의 width와 height를 의미한다.

위의 VGG-19 네트워크의 구조를 참고해서 살펴보자. 만약 를 찾는다면, 첫 번째 max pool layer 전에 있는 2번째 conv layer이므로 conv1_2를 표현하는 식이 될 것이다.
마찬가지로 은 4번째 pooling layer 전에 있는 3번째 conv layer이므로 conv4_3를 의미하는 것이다. CNN을 공부하면 배우듯이, high level feature들은 이미지의 content를 더 집중해서 보고, low level feature들은 edge나 모양에 집중하는 경향이 있다.
기존의 MSE Loss는 pixel space에서 정답값과 예측값의 Euclidean Distance를 측정했다. 그러나 VGG Loss는 VGG-19의 중간 layer feature map을 이용해 정답값과 예측값의 Euclidean Distance를 측정한다. feature map을 사용해 훈련시키면 시각적으로 더 만족스러운 결과를 얻을 수 있는 것이다. 어떤 feature map을 선택해서 사용하는지에 대한 내용은 이후 experiments에서 다루겠다.
식에서 보았을 때, Content Loss는 기존 이미지와 비슷한 이미지가 출력되도록 보장해주는 역할을 한다. 그 의도가 정답값과 예측값의 차이를 최소화하려는 식의 구조에 나타나 있다.
Adversarial Loss ()
Adversarial loss는 perceptual loss에 generative한 부분을 더해주는 역할을 한다. 생성된 이미지가 실제와 같이 보이게 하기 위한 loss인 것이다. 위의 figure 3와 같이 discriminator를 속이며 natural image manifold와 비슷한 이미지가 생성될 수 있도록 유도하는 것이다. 아래는 Adversarial loss의 식이다.
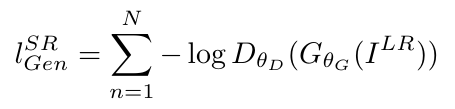
위의 식에서 은 Discriminator에 생성된 이미지 을 넣었을 때의 출력값(=실제 정답 이미지일 확률)을 의미한다. 이미지가 실제일 확률에 -를 붙인 것을 최소화하므로, 이미지가 실제일 확률을 최대화 하는 효과를 가져온다. (Generator의 목적과도 맞는 해석이다.)
4. Experiments
다음은 논문에서 제시한 주요 실험들에 대해서 살펴보겠다.
1) Training 스펙
- Benchmark Dataset: Set5, Set14, BSD100, BSD300의 test set
- Upscaling factor: 모든 실험에 대해 4X
- 평가 방법: PSNR, SSIM, MOS를 이용해 평가.
- YCbCr 중 Y channel만 사용.
- center crop 후 각 모서리로부터 4 pixel씩 제거해 평가.
- Training dataset: 모든 네트워크는 ImageNet dataset에서 350000개의 random sample 뽑아서 학습.
- LR image는 HR image를 downsample(r=4) 해서 생성.
- mini batch별로 16개의 96x96 HR 이미지 사용. (원본 이미지를 crop한 사이즈)
- LR image는 [0,1], HR image는 [-1,1]의 범위로 scaling
- HR image가 [-1,1]인 이유는 tanh를 타고 나오기 때문에 범위를 맞춰주기 위함.
- MSE Loss도 [-1,1] scale에서 계산됨. (VGG loss도 scale에 맞춰서!)
이어서 세부적인 파라미터 세팅을 살펴보자.
- Optimization : Adam ()
- SRResNet : lr = 로 iteration, MSE loss as content loss
- SRResNet의 weight를 generator의 initialization으로 사용.
- GAN 훈련 시 local optima 피하기 위함!
- 구조: Input LR image → Conv → Residual Blocks (16개) → Conv → Upsample x2 → Upsample x2 → Output HR image
- SRGAN : lr = 로 iteration 후 lr = 로 iteration.
2) MOS (Mean Opinion Score) testing
MOS를 위해서 26명의 rater에게 각 사진별로 1~5점 사이로 평가하도록 했다. rater들은 Set5, Set14, BSD100의 각 이미지 당 12개의 버전에 점수를 매겼다. 12개의 버전은 아래와 같다.
- nearest neighbor (NN), bicubic
- SRCNN , SelfExSR, DRCN , ESPCN
- SRResNet-MSE, SRResNet-VGG22(BSD100은 평가 x), SRGAN-MSE , SRGAN-VGG22 , SRGANVGG54
- original HR image.
rater들은 품질이 가장 떨어지는 NN을 1점, 품질이 가장 좋은 original HR image를 5점이라고 기준을 잡고 나머지 이미지들에 대한 점수를 매겼다. 이러한 방식으로 평가한 결과, 신뢰성 있는 결과를 얻을 수 있었다. 자세한 결과는 뒤에 표를 통해 확인할 수 있다.
위에서 언급된 버전들의 표현들에 대해서 알아보자. 통상적으로 "네트워크 이름 - 사용된 loss"의 형식으로 각 버전의 이름을 지었다. 예를 들어 SRResNet-MSE라면, SRResNet을 MSE loss로 훈련시킨 네트워크인 것이다. 또, SRResNet-VGG22와 같이 VGG 뒤에 숫자가 붙은 것은 앞서 언급했던 feature map 에서 i,j에 해당하는 숫자들이다.(i=2,j=2) 어떤 feature map을 가져다 사용했는지 알려주는 숫자인 것이다. 아래의 표를 보면, 각 dataset별로 PSNR, SSIM, MOS 값이 나와 있다.
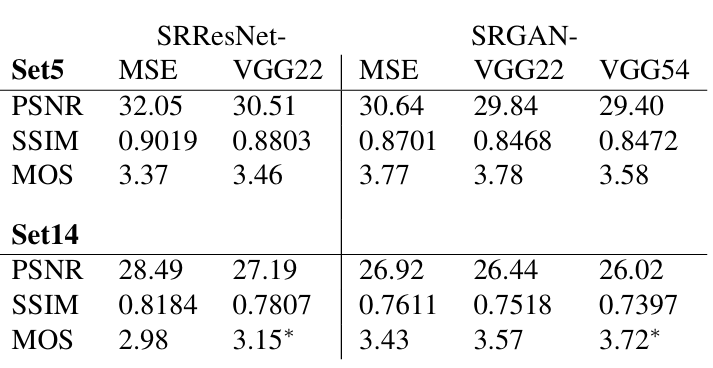
표를 해석해보자. 알아둬야 할 것은 위에서 얘기했던 SRResNet은 MSE loss로 훈련한 것이라는 점, 그리고 SRResNet은 Adversarial loss를 사용하지 않았다는 점이다. 위의 표는 단순히 실험을 할 때 다양한 조합을 사용해서 결과를 뽑은 것이다.
SRResNet
- Set5와 Set14에서 모두 MSE를 loss로 사용하는 것이 PSNR 측면에서는 좋지만, MOS는 VGG22를 loss로 사용했을 때 더 좋음.
-> 언급해왔던 MSE의 한계가 드러남.- SRResNet은 PSNR, SSIM의 측면에서 3개의 benchmark dataset에 대해 새로운 SOTA를 달성함.
SRGAN
- loss별 PSNR은 MSE>VGG22>VGG54 순이지만, MOS는 VGG54>VGG22>MSE 순이다.
- 높은 PSNR이 perceptually satisfying 하지는 않다는 것을 증명.
- MOS가 VGG54>VGG22인 것으로 보아 high level feature를 사용하는 것이 low level보다 더 좋은 퀄리티의 사진이 나오는 것을 알 수 있음.
- high level feature가 더 좋은 texture detail을 생성함.
- SRGAN은 Photo-Realistic image SR 분야에서 새로운 SOTA를 달성함.
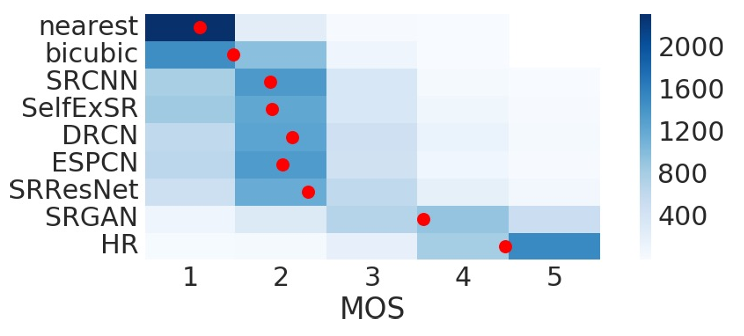
위의 그래프는 BSD100 dataset에 대한 MOS 값을 네트워크 별로 그려놓은 것이다. 빨간색 점은 각 네트워크별 평균 MOS 값을 나타낸 것이다. SRGAN의 MOS가 나머지의 네트워크들보다 적어도 1점씩은 앞서고 있는 것을 확인할 수 있다.

위의 사진처럼 육안으로 보기에도 SRGAN-VGG54가 가장 좋은 퀄리티의 사진을 출력한다.

위의 표에서도 앞서 언급된 내용을 확인할 수 있다.
5. 정리
이 글에서 SRGAN에 대해서 살펴봤는데, 내가 이 논문에서 기억해야 한다고 생각하는 포인트를 몇 가지 정리해봤다.
- SRGAN은 perceptual loss를 도입해 더욱 사실적인 이미지 생성을 가능하게 했다.
- MSE를 기반으로 훈련 시키는 것이 무조건 능사는 아님을 증명했다.
- 4X upscaling factor에서 좋은 성능을 보이며 새로운 SOTA를 제시했다.
이제 다음으로 SR 분야의 논문 리뷰는 EDSR,MDSR이 될 것 같은데, 요새 Diffusion 분야에도 관심이 생겨 이 분야의 기초 논문도 병행해서 읽어보려고 한다.
