[코드와 함께보는 SR] RCAN - Residual Channel Attention Network
본 포스팅은 글쓴이의 뇌피셜이 10%정도 들어가 있습니다. 쓴 내용이 대부분 논문에서 참고하였으나, 이해하기 어려운 부분은 뇌피셜로 이해하려고 노력했기 때문에 틀린 정보가 있을 수 있습니다. 피드백은 언제나 환영입니다.
Abstract
CNN에서의 네트워크 층의 깊이는 Super-resolution에서 매우 중요한 요소에 속합니다. 하지만 이미지 Super-resolution에서 네트워크 층이 깊을수록 학습하기 어렵다는 점이 관찰되었습니다.
CNN 층이 깊을수록 학습하기 어려운 이유?
- 짧게 설명하자면 Gradient Vanishing 문제가 발생하기 때문.
- 이해한 바로는 주로 사용하는 sigmoid function의 값은 0~1로 이루어지는데, 층을 통과할때마다 0~1에 가까운 값을 계속 곱해지게 된다.
- 네트워크가 깊어진다는 것은 값이 0의 방향으로 지속적으로 이동한다는 점인데, 0에 가까워지면 가까워 질수록 값은 점점 소멸하는 현상이 일어나게 된다.
저해상도 이미지에서의 저주파 정보는 CNN의 표현 능력을 방해합니다. 이 문제를 해결하기 위해서 저자는 residual을 활용하여 네트워크의 층을 깊게 쌓은 RCAN(Residual Channel Attention Network)를 제안했습니다. 직역하면 잔차 채널 주의 네트워크(?)로 해석되네요.
Network Architecture
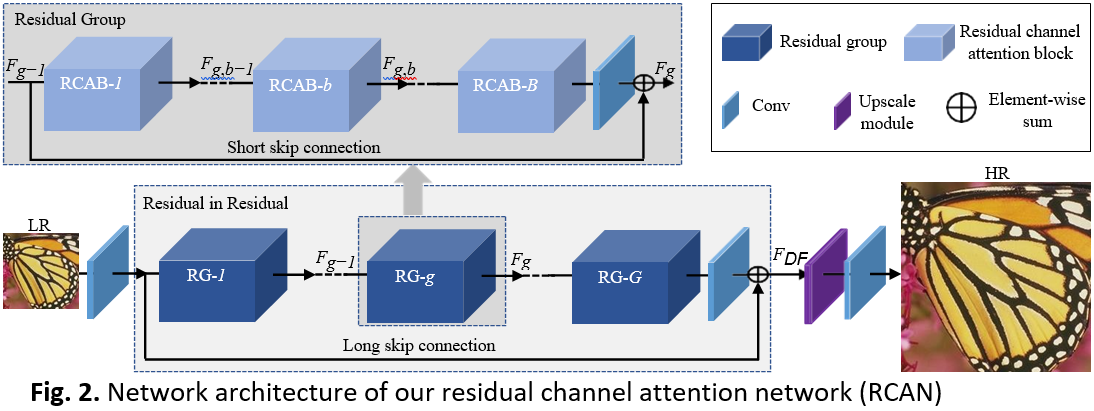
RCAN은 크게 4 부분으로 구성된다고 합니다.
-
Shallow feature extraction
- 논문에서는 Shallow feature를 잡아내기 위해서 한 층의 Convolution layer를 사용한다고 한다. Shallow feature는 이해한 바로는 본격적으로 특징을 잡아내기 이전에 필요한 '표면적인 정보' 정도로 이해했다.
-
Residual-In-Residual deep feature extraction
- 본격적으로 특징을 잡아내는 층이다. 자세한 내용은 아래에서
-
Upscale Module
- Scale에 맞게 이미지 크기를 키워주는 층.
-
Reconstruction part
- Upscale 과정에서 손실되는 High-frequency 정보를 복원하는 층.
Model Pytorch Code
본격적으로 코드를 뜯어보며 이해해보자.
- 지금부터 [9:20] <= 이런식으로 표현하는 부분은 깃허브 코드의 라인을 의미한다. 9번째 줄 부터 20번째 줄의 코드 라는 의미이다. 아래 코드는 참고하는 RCAN 깃허브 코드의 9번째부터 20번째 줄의 코드이다.
class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)- 처음으로 확인해야 할 부분은 당연히 이미지가 들어오는 Input 부분이다.
- pytorch 모델의 학습 순서는 forward 함수에서 이뤄지므로 class RCAN의 forward[106:116] 부분을 살펴보자.
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x - forward 함수에서 처음 시작하는 부분은 self.sub_mean[82]이다.
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)- common.MeanShift함수는 아래와 같다.
class MeanShift(nn.Conv2d):
def __init__(self, rgb_range, rgb_mean, rgb_std, sign=-1):
super(MeanShift, self).__init__(3, 3, kernel_size=1)
std = torch.Tensor(rgb_std)
self.weight.data = torch.eye(3).view(3, 3, 1, 1)
self.weight.data.div_(std.view(3, 1, 1, 1))
self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean)
self.bias.data.div_(std)
self.requires_grad = False-
MeanShift는 EDSR에서도 봤었던 기능인데, EDSR github issue에 대략적인 설명이 있다.
- 처음 들어가는 부분인 sub_mean에서는 sign값이 -1이어서 bias를 빼주는 형태로 들어가게 된다.
- 마지막 부분인 add_mean에서는 sign값이 1이어서 bias를 더해주는 형태로 들어가게 된다.
- RCAN 코드에서는 DIV2K 데이터셋의 RGB 각각의 평균값을 구해서 더하고 빼주고 있다.
- zero-centered 정규화 과정이라고 이해하면 될 듯 하다.
- 평균값 제거 효과
-
다음으로 self.head[102]를 거치게 된다. self.head는 Sequential로 modules_head[85]라는 리스트 변수를 받아왔다.
modules_head = [conv(args.n_colors, n_feats, kernel_size)]- modules_head는 conv라는 함수를 포함하고 있는데 이는 common.default_conv를 init에서 인자로 받았다. common.default_conv 코드는 아래와 같다.
def default_conv(in_channels, out_channels, kernel_size, bias=True):
return nn.Conv2d(
in_channels, out_channels, kernel_size,
padding=(kernel_size//2), bias=bias)- convolution layer를 리턴받는데, 기존 layer과의 차이점이라면 padding 부분이 kernal_size를 2로 나눈 값이라는 점이다.
- 앞서 간단하게 소개한 4가지 부분 중 Shallow feature extraction으로 보인다.
- 이제 본격적인 Residual 부분이다. 코드에서는 n_resgroups[71]이라는 변수에 들어간 숫자 만큼 model ResidualGroup[50:64]을 반복한다.
class ResidualGroup(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(ResidualGroup, self).__init__()
modules_body = []
modules_body = [
RCAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(True), res_scale=1) \
for _ in range(n_resblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res- ResidualGroup 역시도 내부에서 model RCAB을 n_resblocks[72]이라는 변수에 들어간 숫자 만큼 반복한다.
- 여기서 중요한 점은 ResNet의 Residual block 구조[62:64]를 가지고 있다는 점이다.
ResNet의 Residual Block이란
- 기존 신경망은 입력값 x를 넣으면 y를 찾는 H(x)를 찾는것을 목적으로 한다.
- 하지만 ResNet의 Residual Block은 기존의 신경망과 다르게 마지막단에 처음 입력한 값 x를 더해준다.
- 그러므로서 기존 H(x) = 0인 구조를 H(x) = F(x) + x 구조로 변경하게 된다.
- 이는 결국 F(x)를 최소로 한다는 것은 H(x) - x를 최소화하는 방향이 되는데, 여기서 H(x) - x 를 잔차(Residual)이라고 부르게된다.
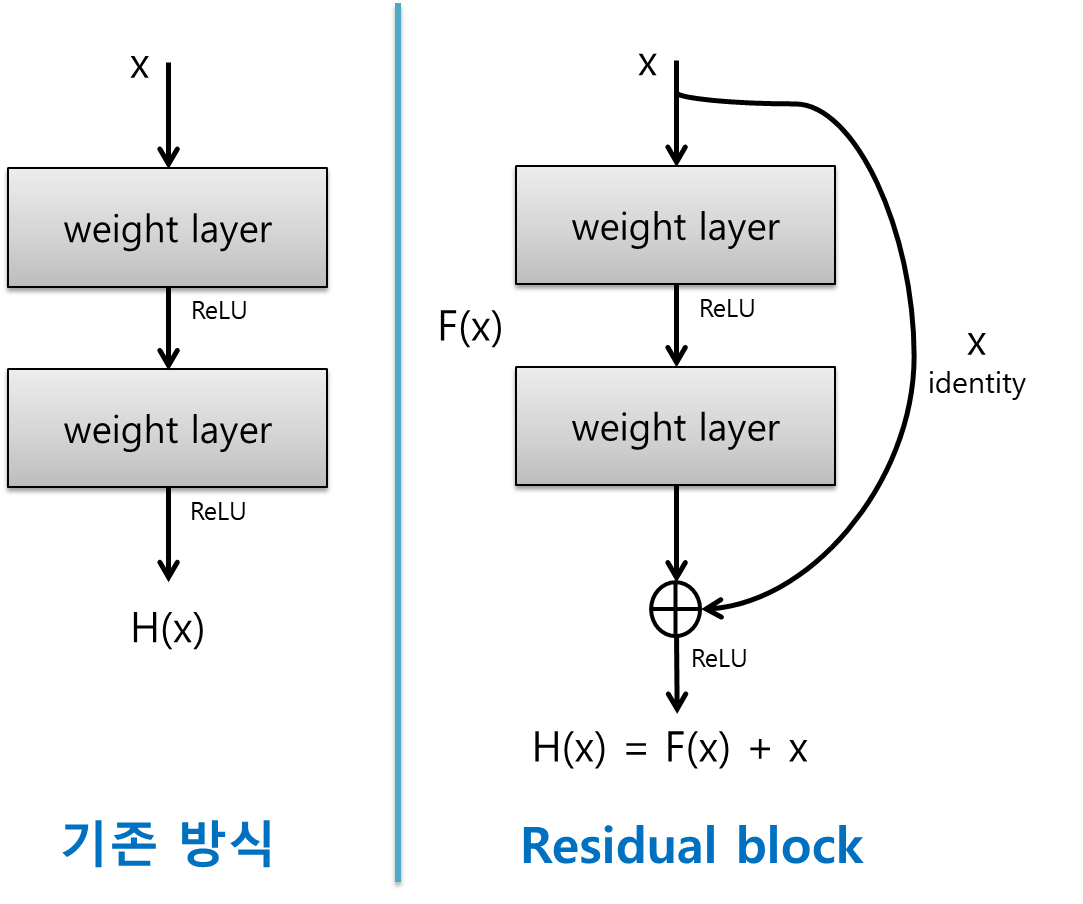
참고 블로그
- 기존 신경망은 입력값 x를 넣으면 y를 찾는 H(x)를 찾는것을 목적으로 한다.
- 다시 이어서 RCAB을 내부를 살펴보면 CALayer[9:25]를 Residual Block의 형태로 n_resblock 변수 만큼 반복한다.
...향후 추가예정...

Deep learning for super-resolution