본 포스팅은 글쓴이의 뇌피셜이 10%정도 들어가 있습니다. 쓴 내용이 대부분 논문에서 참고하였으나, 이해하기 어려운 부분은 뇌피셜로 이해하려고 노력했기 때문에 틀린 정보가 있을 수 있습니다. 피드백은 언제나 환영입니다.
Abstract
그동안 다양한 Deep Convolution 신경망이 Super-resolution 분야에서 제시되었다. EDSR은 논문 발표 당시 SOTA(State of the art) 방법론이었다고 한다. 불필요한 모듈을 제거하고, 최적화 하여 모델의 성능을 향상시켰다.
또한 다양한 scale에서 사용할 수 있는 시스템인 MDSR 역시 내세웠다. 이 방법론을 적용해서 NTIRE2017 SISR Challenge에서 가장 좋은 성능을 냈다.
EDSR은 서울대학교 Computer vision lab에서 발표한 논문입니다. (국뽕)

논문에서는 MDSR도 소개하고 있지만 이 포스팅에서는 EDSR만 살펴보도록 하겠습니다.
특징 분석
제가 본 EDSR의 핵심 파트는 3가지입니다.
1. Residual Blocks 사용
- Super-resolution 논문을 보다보면 이제는 없으면 섭섭한 Residual Block입니다.
- 제가 간단하게 정리 한 포스팅이 있습니다. (한번 봐주세요..)
2. Batch Normalization 제거
- 기존에 CNN 관련 모델들에서 Batch Normalization은 없으면 어색할 만큼 거의 대부분의 모델들에 들어가 있는 방법론이었습니다.
- EDSR에서는 과감하게 뺐습니다.
- 논문에서는 Batch Normalization 과정이 일정 범위로 정규화를 해주다보니 분류나 검출문제와는 다르게 SR에서는 유연성이 떨어진다고 봤다.
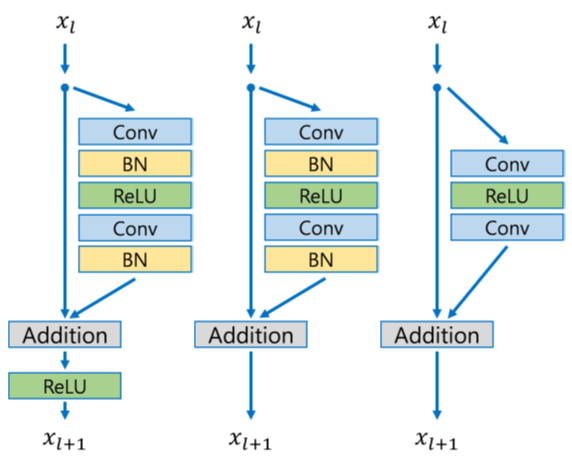
- Resnet, SRResNet, EDSR을 비교해봤을때 많은 부분이 덜어진 것을 볼 수 있다.
- 기존 SRResNet에서 BatchNorm을 빼서 얻은 이점으로는
1. GPU 메모리 사용량을 획기적으로 줄일 수 있다.
2. 유연성이 증가한다. - 위의 이점으로 줄어든 메모리만큼 더 깊은 모델을 만들 수 있는 장점이 생겼습니다.
3. loss를 L1 loss 로 변경
- 기존 SR 방법론들은 MSE(Mean Squared Error)를 널리 사용했습니다.
- 그러나 저자들은 이 논문을 통해 L1 Loss가 PSNR과 SSIM 측면에서 실험적으로 더 좋은 성능을 낸다는 점을 들어 L1 Loss 를 사용했습니다.
Single Scale Model
논문에서는 네트워크의 층 깊이와 Feature의 개수 중에 어떤 부분이 더 중요한 부분인지에 대한 분석을 했습니다.
계산 리소스가 제한되어있다고 가정했을땐, 네트워크 층의 깊이 보다는 Feature 수를 늘리는 것이 더 긍정적이라는 결론입니다.
하지만 특정 수치 이상으로 높일 경우에는 학습이 불안정해질 수 있다고 합니다.
그래서 논문에서는 Residual Scaling Factor 0.1 을 Convolution layer 마지막에 추가했습니다.
평가 결과
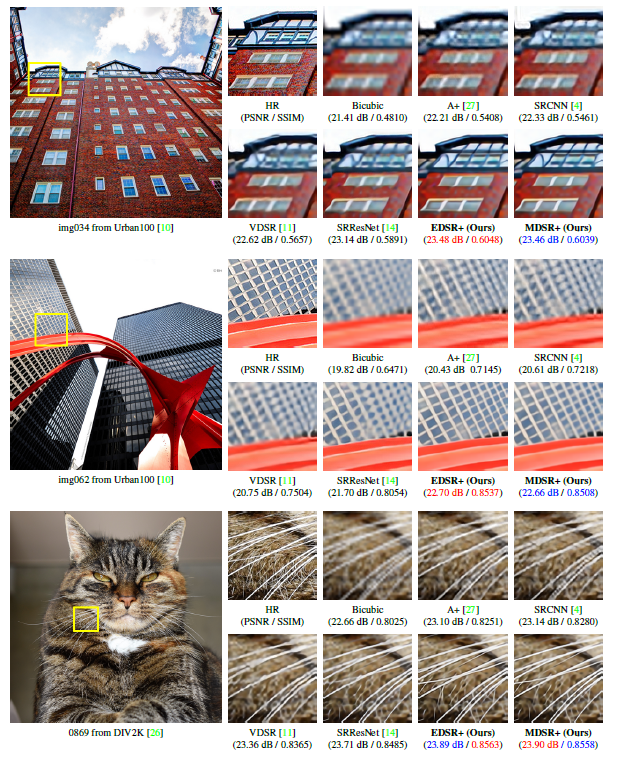
- 개인적인 느낌으로는 엣지를 잘 잡아내는 것 처럼 보입니다.
