
Summary
Region-based Convolutional Neural Network(R-CNN) is a foundational model in object detection, which revolutionized object detection by introducing a method that combines region proposals with deep learning, setting the stage for significant advancements in the field.
Introduction
Before R-CNN, object detection tasks relied on traditional methods (e.g., the sliding window approach).
Traditional methods were not only computationally expensive but also struggled with detecting objects of varying sizes and shapes.
R-CNN introduced a novel paradigm by combining region proposals with deep convolutional neural networks(CNNs) to address these issues.
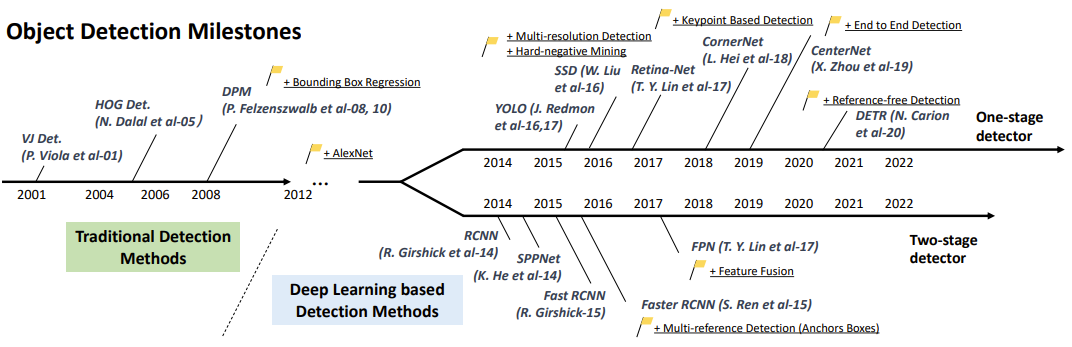
This innovation marked a significant milestone, laying the foundation for modern object detection models.
Object Detection with R-CNN
Model Overview:
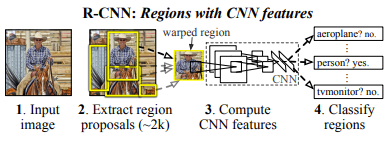
R-CNN Workflow
- Run a selective search on the image to extract around 2,000 region proposals.
- Warp each proposal into 227x227.
- Extract a 4096-dimensional feature vector by forward propagating it through the pre-trained CNN.
- Score each extracted feature vector using the SVM(Support Vector Machine) trained for that class.
- Apply non-maximum suppression.
Detailed Architecture of R-CNN
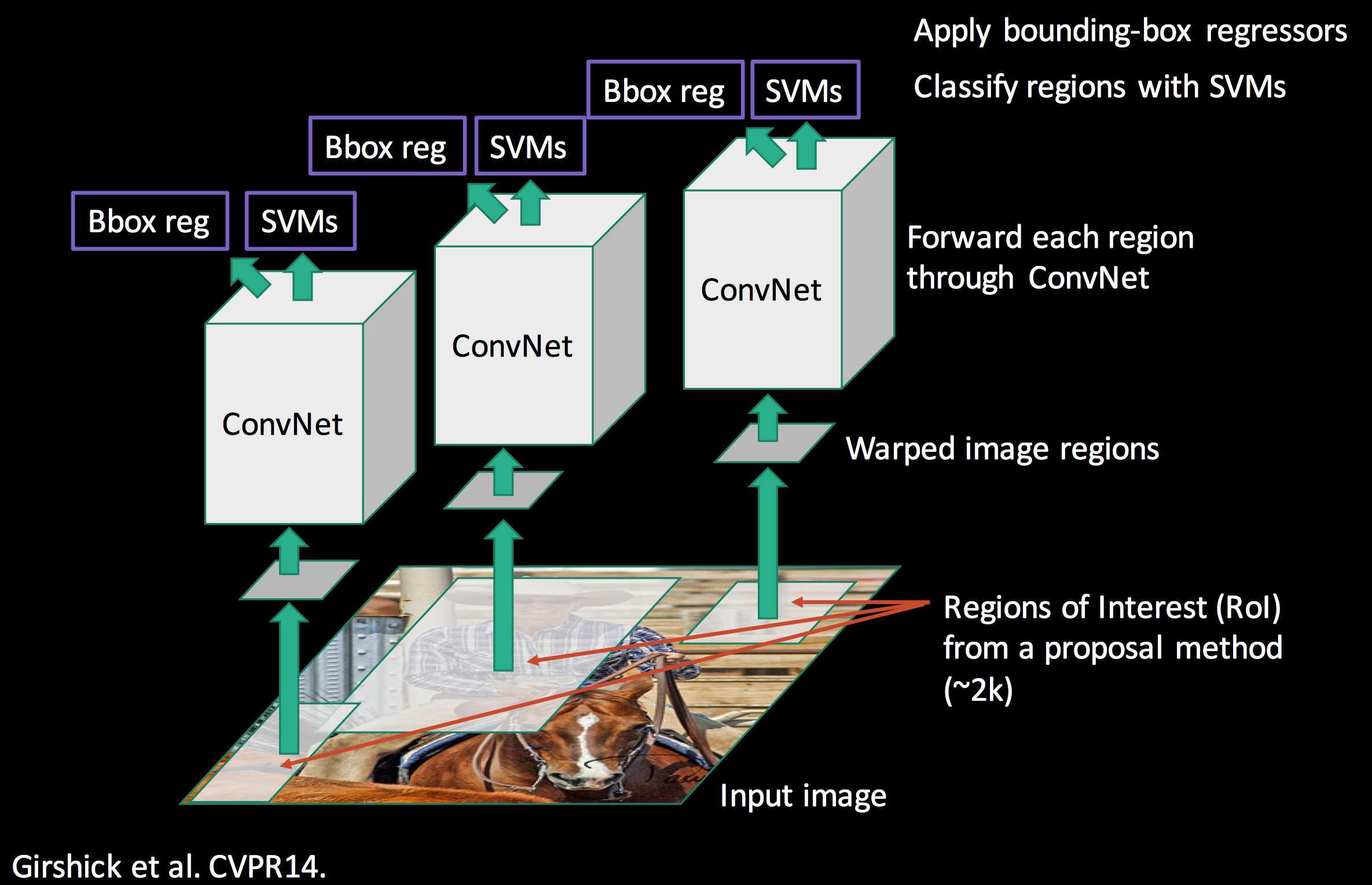
0. Input Image
1. Region Proposal generation:
-
These proposals are candidate regions that might contain objects.
- Selective Search

- Step 1. Initial Sub-Segmentation
- An image is segmented into small regions, each representing a part of an object (e.g., uniform textures or colors).
- Step 2. Recursive Combination of Regions
- A greedy algorithm combines the most similar regions into larger regions iteratively
- Similarity is measured based on color, size and compatibility.
- Step 3. Candidate Object Locations
- Generated regions are used as proposals for possible object locations
2. Feature Extraction:
Warping Region Proposals
- To ensure compatibility with the CNN's input size, all region proposals are resized to a fixed size (e.g., 227x227).
- This warping can cause distortion, potentially leading to a loss of detail especially in regions with extreme aspect ratios.
CNN Architecture
- R-CNN uses AlexNet as its backbone network for feature extraction.
- Each proposal is passed through the network and a 4096-dimensional feature vector is extracted from the fc7 layer. (network consists of five convolutional layers and two fully connected layers) to extract feature vectors.
- These vectors capture semantic and spatial information, enabling robust classification.
3. Classification:
- The extracted features are classified using SVMs.
- A reason for using SVMs instead of a CNN classifier is that SVMs demonstrated a 4% better performance on mAP(mean Average Precision).
- A separate SVM is trained for each object class to classify proposals as a specific object class or background.
4. Bounding-box regression(Localization):
- Bounding Box Regression refines initial region proposals to match better the ground truth bounding boxes.
- Unlike traditional methods (e.g., Deformable Part Models), R-CNN uses pool5 features, providing richer and more semantic representations.
The goal of the bounding-box regressor is to find an optimal transformation that maps P to G
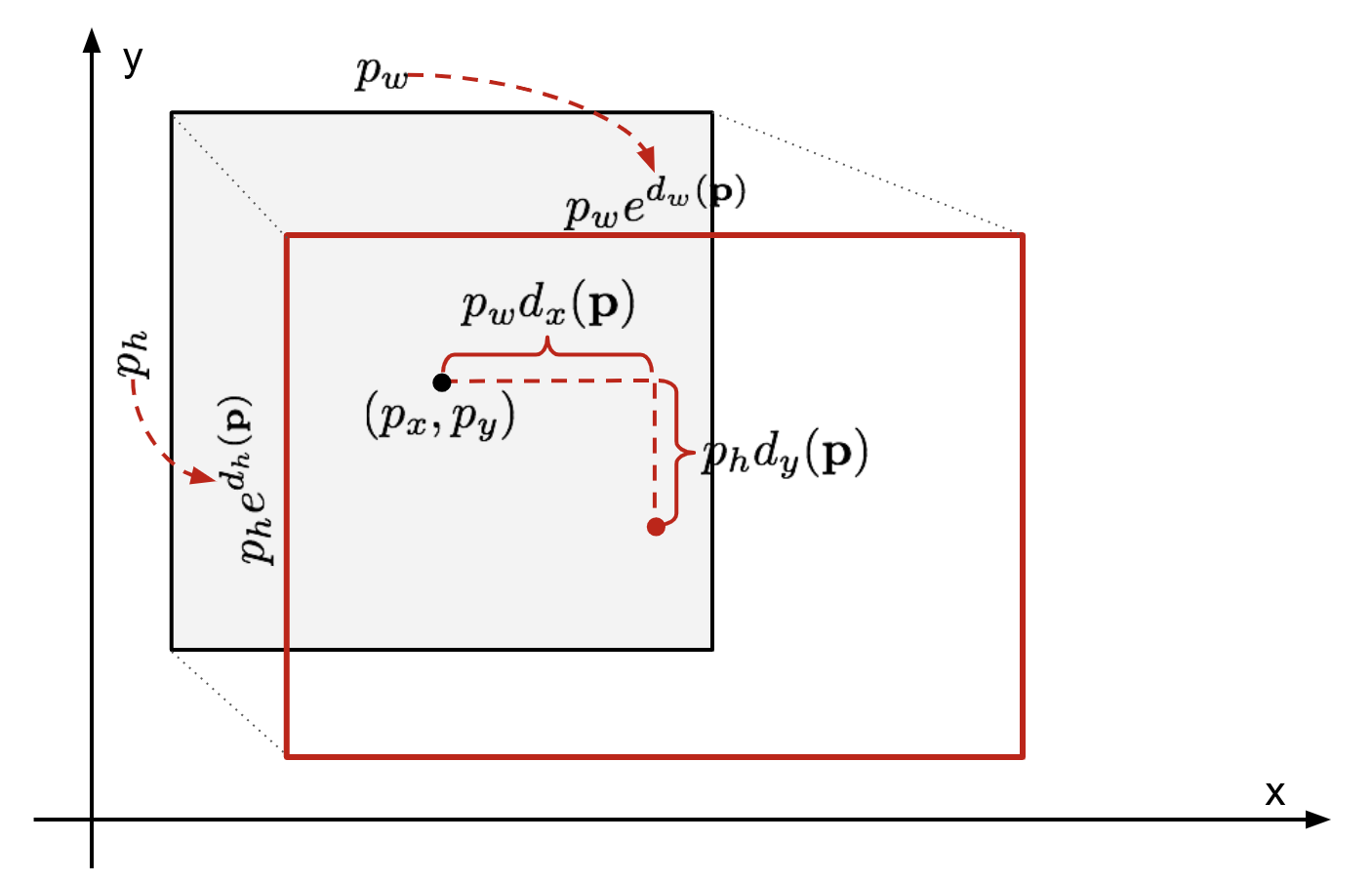
Proposals(P) and ground truth boxes are represented as:
P = (x, y, w, h), G = (Gx, Gy, Gw, Gh)
x, y: Center coordinates of the box
w, h: Width and height of the box
The goal is to learn a function d that transforms P to make it as close as possible to G.
The function adjusts:
x, y: By translating the box's center
w, h: By scaling the width and height (proportionally to the image dimensions) The refined bounding box G^ is computed as:
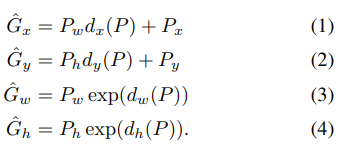
And d-functions are parameterized as:
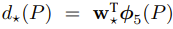
, where w is a vector of learnable model parameters.
(Φ: linear function of the pool5 features)
w can be learned by optimizing the regularized least squares objective (ridge regression):
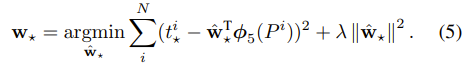
(λ is set to 1000, as determined based on a validation set)
The regression targets t for the training pair (P, G) are defined as:
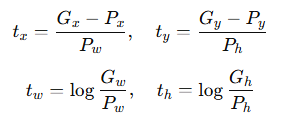
Details are provided in Appendix C
5. Non-Maximum Suppression(NMS):
- Purpose:
- To remove redundant bounding boxes overlapping, ensuring only one bounding box per object is retained.

- How It Works:
- Intersection over Union(IoU) is used as a metric to evaluate the overlap between bounding boxes.
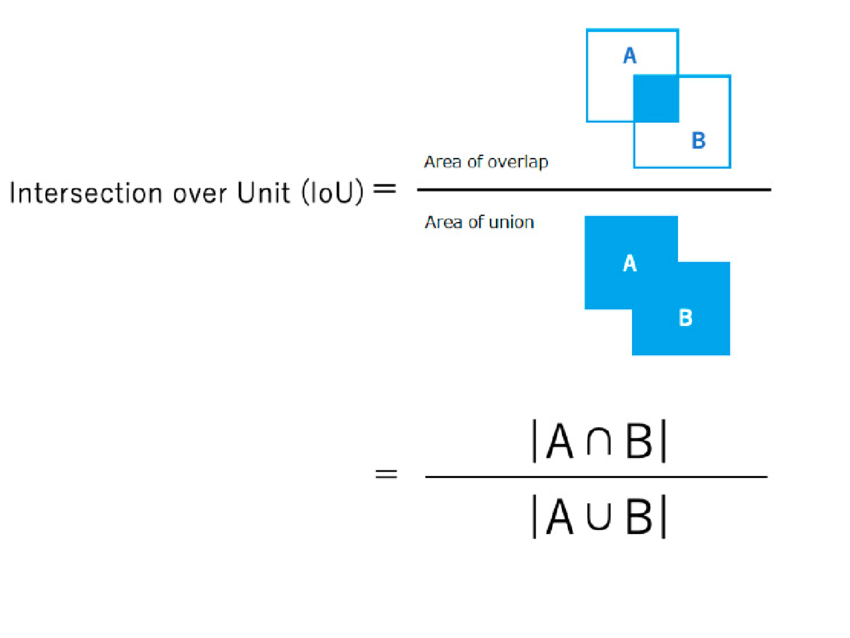
- During NMS, boxes with IoU above a certain threshold(e.g., 0.5) are considered redundant, and only the box with the highest confidence score is retained.
Advantages:
-
- Improved Accuracy: By leveraging deep learning-based feature extraction and fine-tuning, R-CNN outperforms traditional object detection methods.
-
- Flexible Feature Extraction: By using pre-trained CNNs, it becomes easier to adapt to new datasets with limited data.
Limitations of RCNN:
- Slow training and inference
: Each Region proposal is processed independently through the CNN and implemented on the CPU.
- Slow training and inference
- High storage requirements
: Features for all region proposals are pre-computed and stored, requiring significant memory.
- High storage requirements
- Multi-stage training
: Separate training stages are needed for the CNN, SVMs and bounding box regressors.
- Multi-stage training
Conclusion
- R-CNN revolutionized object detection by introducing region-based feature extraction and combining it with deep learning.
R-CNN laid the foundation for more advanced models like Fast R-CNN and Faster R-CNN, enabling end-to-end training and shared computation.
The innovations in R-CNN particularly fine-tuning and bounding-box regression remain foundational in modern object detection. - Despite its multi-stage training and computational inefficiency, the paper's groundbreaking use of CNNs for object detection impressed me, as it overcame traditional performance limitations and opened new possibilities in the field.
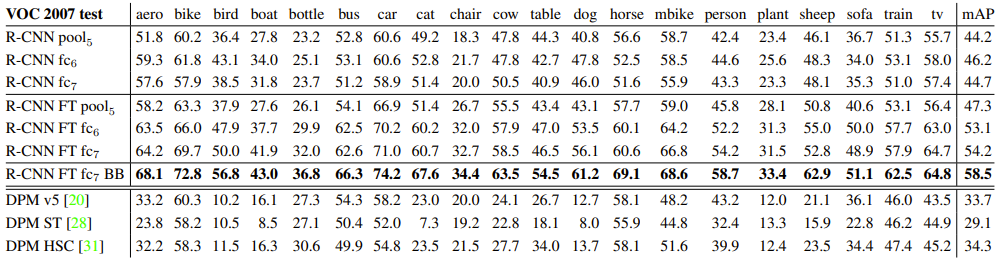
- The table presents the performance of R-CNN obtained by training an SVM using feature vectors extracted from each layer of the CNN.
- Also compares the mAP with and without fine-tuning, highlighting the impact of fine-tuning and bounding box regression on performance.
- The results demonstrate that the combination of fine-tuning and bounding-box regression yields the highest performance. Fine-tuning optimizes the feature representations for the specific dataset, while bounding-box regression refines localization accuracy.
Performance:
R-CNN achieved an mAP of 58.5% on the PASCAL VOC 2012 dataset.
References
Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. 2014 IEEE Conference on Computer Vision and Pattern Recognition, 580–587. https://doi.org/10.1109/cvpr.2014.81
Zou, Z., Chen, K., Shi, Z., Guo, Y., & Ye, J. (2023). Object detection in 20 years: A survey. Proceedings of the IEEE, 111(3), 257–276. https://doi.org/10.1109/jproc.2023.3238524
Uijlings, J., et al. (2014). Selective search for object recognition. Stanford University.
http://vision.stanford.edu/teaching/cs231b_spring1415/slides/ssearch_schuyler.pdf
Li, F.-F., Jonhson, J., & Yeung, S. (2017). Lecture 11: Detection and segmentation. https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
Chhikara, P. (2022, February 1). Intuition and implementation of Non-Max suppression algorithm in object detection. Medium.
https://towardsdatascience.com/intuition-and-implementation-of-non-max-suppression-algorithm-in-object-detection-d68ba938b630
Weng, L. (2017, December 31). Object detection for dummies part 3: R-CNN family.
https://lilianweng.github.io/posts/2017-12-31-object-recognition-part-3/
Iwasa, Y., et al. (2021). Automatic segmentation of pancreatic tumors using deep learning on a video image of contrast-enhanced endoscopic ultrasound. Journal of Clinical Medicine, 10(16), 3589.
https://doi.org/10.3390/jcm10163589
