Summary
The ResNet paper introduces the concept of residual learning to address the challenges associated with training very deep neural networks. Traditional deep networks face optimization difficulties, particularly due to vanishing and exploding gradients. ResNet overcomes these issues by reformulating layers to learn residual functions instead of directly mapping inputs to outputs. This approach allows the training of extremely deep networks (up to 152 layers) while maintaining efficient training and improved performance. Compared to architectures like VGGNet, ResNet achieves higher accuracy with fewer parameters and lower computational cost.
Introduction
Background: The Challenge of Deep Neural Networks
- Deeper networks naturally integrate low-, mid-, and high-level features in an end-to-end multi-layered structure.
- While increasing depth theoretically improves feature representation, it introduces significant optimization challenges.
- A key question posed by the paper: "Is learning better networks as easy as stacking more layers?"
- The answer is no, as deeper networks suffer from:
- Vanishing/exploding gradients that hinder convergence from the beginning.
- Difficulty in optimization despite techniques like normalized initialization and batch normalization.
Solution: Residual Learning Framework
- Instead of directly mapping inputs to outputs, layers are reformulated to learn a residual function:
- Residual function: ( F(x) = H(x) - x )
- Original function transformation: ( H(x) = F(x) + x )
- This reformulation allows easier learning by enabling identity mappings when necessary.
- To the extreme, an identity mapping is optimal when residuals are zero.
Shortcut Connections
- Key component of ResNet’s architecture, designed to ease optimization:
- Skipping one or more layers while maintaining information flow.
- Adding outputs of residual functions to the outputs of stacked layers.
- No additional parameters or computational overhead.
- Enables effective end-to-end training of deep networks.
- Despite its depth, ResNet achieves lower complexity than VGGNet.
ResNet
Model Architecture
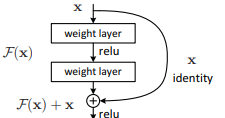
- The core idea behind ResNet is residual learning, formulated as:
[ F(x) = H(x) - x ]- Instead of directly learning ( H(x) ), the model learns ( F(x) ), making training easier.
- The final function is represented as:
[ H(x) = F(x) + x ]
- ReLU activations and biases are omitted in some notations for simplification.
Bottleneck Architecture
For deeper versions of ResNet (e.g., ResNet-50/101/152), the authors propose a bottleneck design to reduce computation while preserving performance.
Each bottleneck residual block consists of:
-
1×1 convolution (reduce dimensionality)
-
3×3 convolution
-
1×1 convolution (restore dimensionality)
This allows deeper models to remain computationally efficient and parameter-efficient, enabling scalable deep networks.
Performance
- Solving the degradation problem:
- Deep networks without residual connections suffer from performance degradation, where deeper networks perform worse than shallower ones.
- ResNet enables training of deep networks (e.g., 152 layers) while maintaining strong performance.
- Improved optimization:
- Shortcut connections help mitigate vanishing gradients.
- Gradients flow more effectively through the network.
- Computational efficiency:
- Despite its depth, ResNet has lower complexity than architectures like VGGNet.
Conclusion
- ResNet introduces a new paradigm for deep learning by using residual learning.
- Overcomes optimization challenges that arise in very deep networks.
- Enables training of ultra-deep networks without degradation in performance.
- Residual connections introduced by ResNet have since become foundational in modern architectures, including ResNeXt, DenseNet, EfficientNet, and even Transformer-based models like BERT and Vision Transformers (ViT). Their ability to stabilize deep network training makes them a core design principle in today's deep learning research and applications.
References
He K, et al. (2015). Deep Residual Learning for Image Recognition. arXiv:1512.03385
