VGGNet Paper Review - Very Deep Convolutional Networks for Large-Scale Image Recognition
Computer Vision

Summary
VGGNet is a deep convolutional neural network designed to improve image classification performance by increasing network depth while using small convolutional layers (3 x 3 conv). This architecture enables efficient feature extraction and great performance on large-scale image recognition tasks, particularly in the ImageNet challenge.
Introduction
VGGNet was developed to explore the impact of network depth in convolutional neural networks. Unlike earlier architectures that used larger convolutional filters (e.g., 7 x 7 or 11 x 11), VGGNet leverages small (3 x 3) convolution filters stacked in all layers.
This design provides several advantages:
- Better feature extraction through multiple stacked small filters
- Fewer parameters compared to architectures using large filters
- Increased non-linearity, which helps the model capture more complex patterns
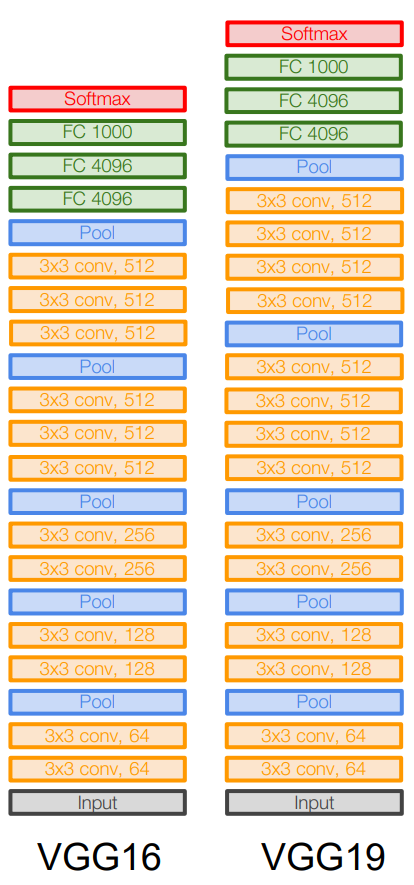
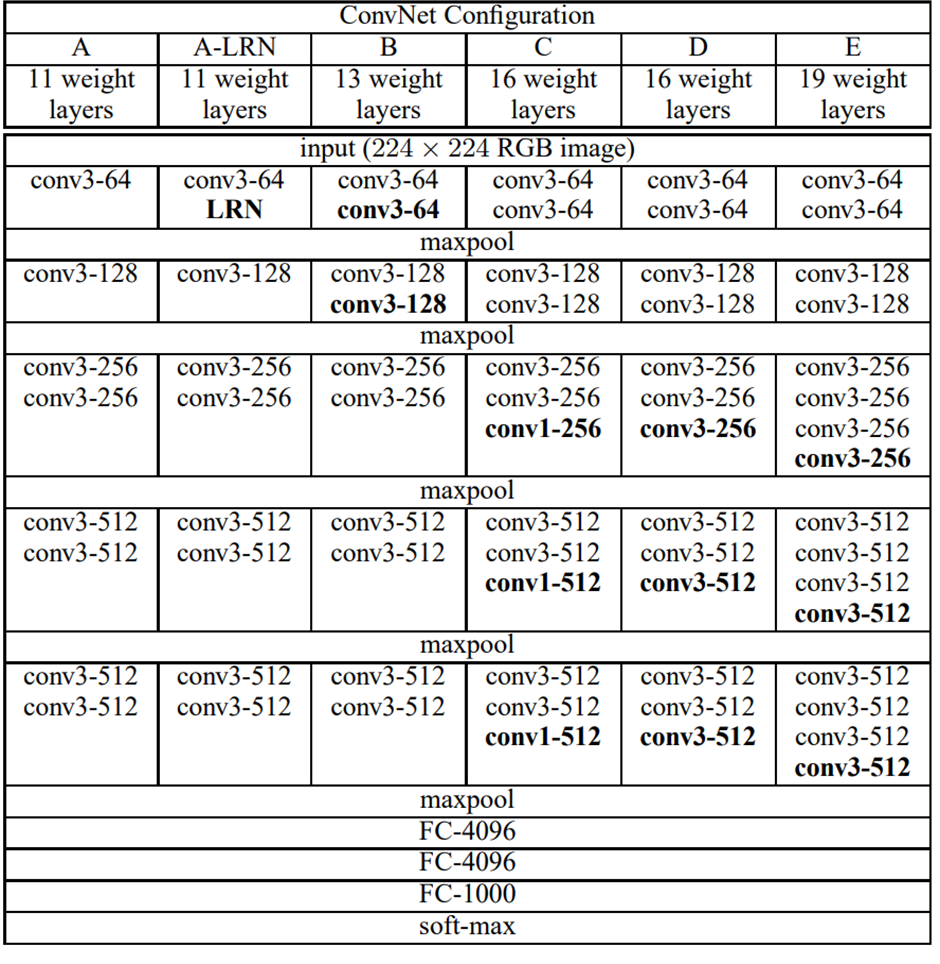
By increasing depth from 8 layers to 16 and 19 layers, VGGNet greatly improves classification accuracy while remaining computationally feasible.
VggNet Architecture
Model Structure:
VGGNet follows a structured and uniform architecture that prioritizes depth, small filters, and efficient parameter utilization. Leveraging increased non-linearity through stacked 3x3 convolutional layers enhances feature extraction and allows the network to learn more complex patterns.
Stacked Small Filters Instead of Large Filters
Rather than using a single large filter (e.g., 7 x 7), VGGNet stacks multiple 3 x 3 convolutional layers. A stack of three 3 x 3 convolutional layers (stride = 1) has the same effective receptive field as a single 7 x 7 convolutional layer, but with several advantages:
- Using small filters enables deeper networks while maintaining computational feasibility.
- Introduces more non-linearity, allowing the model to learn more complex features
- Maintains the same receptive field while reducing the number of parameters
1. Increased Non-Linearity for Stronger Feature Extraction
- Each convolutional layer is followed by a ReLU activation, ensuring that the network learns non-linear patterns.
- More non-linearity introduces additional complexity to the decision boundary, making feature representations more discriminative.
- Without non-linearity, even a deep network would behave as a single linear transformation, limiting its capacity to learn complex features.
- Stacked non-linear activations allow the network to capture hierarchical patterns, improving classification performance.
2. Fewer Parameters with Efficient Receptive Fields
One of the key advantages of using stacked 3×3 filters is the reduction in the number of parameters while maintaining an effective receptive field.
Parameter Comparison
Assuming both the input and output of a three-layer 3×3 convolution stack have C channels:
-
Three stacked 3×3 convolutions:
[ 3 × (3² C²) = 27C² ] -
A single 7×7 convolution:
[ 7² C² = 49C² ] -
Conclusion:
[ 27C² (stacked 3×3) vs. 49C² (single 7×7) ]
→ Stacked small filters are more efficient.
By leveraging small filters, VGGNet significantly reduces the number of parameters while maintaining strong feature extraction capabilities.
Training & Evaluation
VGGNet was trained on the ImageNet dataset, which consists of 1.3 million training images and 50,000 validation images across 1,000 classes. To improve model generalization and feature extraction, several key techniques were used during training and testing.
1. Data Augmentation for Better Generalization
To prevent overfitting and enhance model robustness, VGGNet applied data augmentation techniques such as:
- Random cropping: Extracting 224×224 patches from resized images to simulate variations in object size and position.
- Horizontal flipping: Randomly flipping images to improve feature invariance.
- Color jittering: Adjusting brightness, contrast, and saturation to simulate different lighting conditions.
2. Multi-Scale Training
VGGNet was trained using multi-scale input images, meaning images were resized to different scales before cropping.
- This allowed the model to learn scale-invariant features, improving classification performance on images of varying sizes.
- Unlike earlier models that used fixed input sizes, VGGNet processes images at multiple scales to improve robustness and generalization.
3. Testing & Performance Evaluation
During evaluation, the model followed two key testing strategies:
- Single-crop testing: A single 224×224 center crop from each test image was used for inference.
- Multi-crop testing: Multiple overlapping crops were extracted from an image, and the predictions were averaged to improve accuracy.
Multi-crop testing yielded better results by reducing variance in predictions, but it also increased computational cost.
Performance
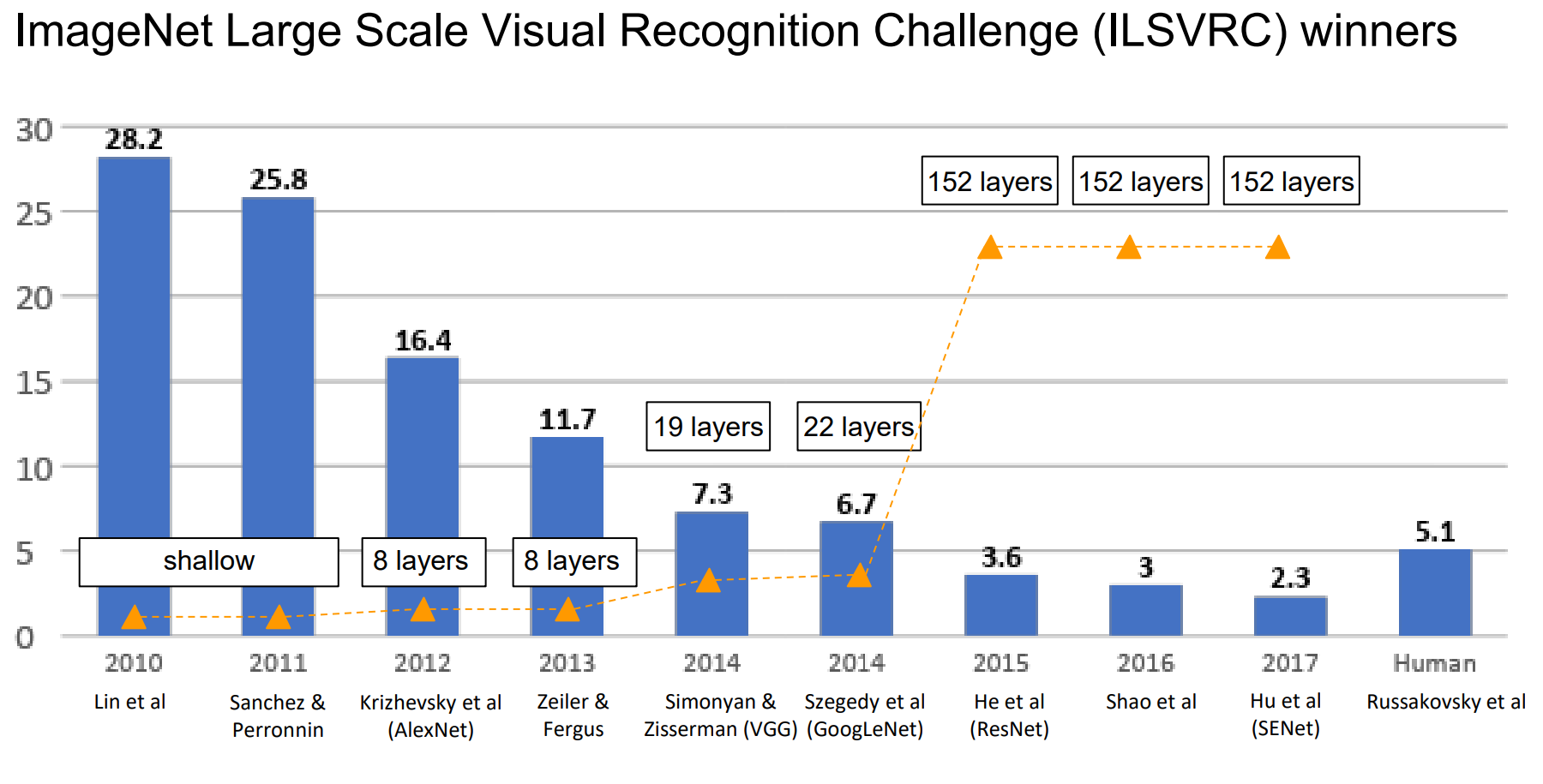
VGGNet achieved remarkable performance in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC-2014), finishing 2nd place in the classification task, just behind GoogLeNet.
- The VGG-16 and VGG-19 models demonstrated high classification accuracy while maintaining a relatively straightforward architecture.
- VGGNet’s deep, uniform architecture proved to be highly influential in the development of later CNN models.
- The model showed significant improvements in top-5 error rate, reducing misclassification rates compared to earlier architectures like AlexNet.
Key Results from ILSVRC-2014
| Model | Top-5 Error (%) |
|---|---|
| AlexNet (2012) | 16.4% |
| ZFNet (2013) | 11.7% |
| VGGNet (2014, 2nd place) | 7.3% |
| GoogLeNet (2014, 1st place) | 6.7% |
Despite being computationally more expensive than GoogLeNet, VGGNet’s simpler and more systematic design influenced many future architectures, including ResNet and DenseNet.
Conclusion
VGGNet demonstrated that increasing network depth while using small convolutional filters is an effective strategy for improving image classification performance. By replacing large filters with stacked 3×3 convolutions, the model achieves stronger feature extraction and better computational efficiency.
However, VGGNet also has limitations:
- High computational cost due to the large number of layers.
- No residual connections, which later architectures (e.g., ResNet) introduced to improve gradient flow and training stability.
Despite its limitations, VGGNet remains one of the most influential CNN architectures in deep learning history. Its structured and uniform design made it easier to understand and implement compared to more complex models like GoogLeNet.
In my view, VGGNet's simplicity and systematic approach to depth expansion were key factors in its success. While later models like ResNet introduced more sophisticated mechanisms such as skip connections to handle deeper networks, VGGNet still serves as a fundamental reference model for deep CNN architectures.
References
Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/arXiv.1409.1556
Li, F.-F., Jonhson, J., & Yeung, S. (2017). Lecture 6: CNN Architectures.
https://cs231n.stanford.edu/slides/2024/lecture_6_part_1.pdf
