지금까지 Neural Net에 대해, 그리고 Classification 과정에 대해 알아보았다.
이제부터는 인공지능에 대해 조금 알아봤다면 한번쯤 들었을 CNN에 대해 정리해보고자 한다.
CNN, RNN, Transformer....등등 모두 Neural Net을 어떻게 구성했느냐에 따라 다르게 부르는거지, 모두 Neural Net의 기본적인 구조와 연산을 따라가는건 변하지 않는다는걸 꼭 기억하자.
CNN은 Convolutional Neural Network의 약자로,
- 부분적으로 연결되어 있고, weight 값을 공유
- 이미지, 스피치, 텍스트와 같은 Sequential data 처리에 특화되어 있음
과 같은 특징들을 갖는다.
1. Idea for Image Classification
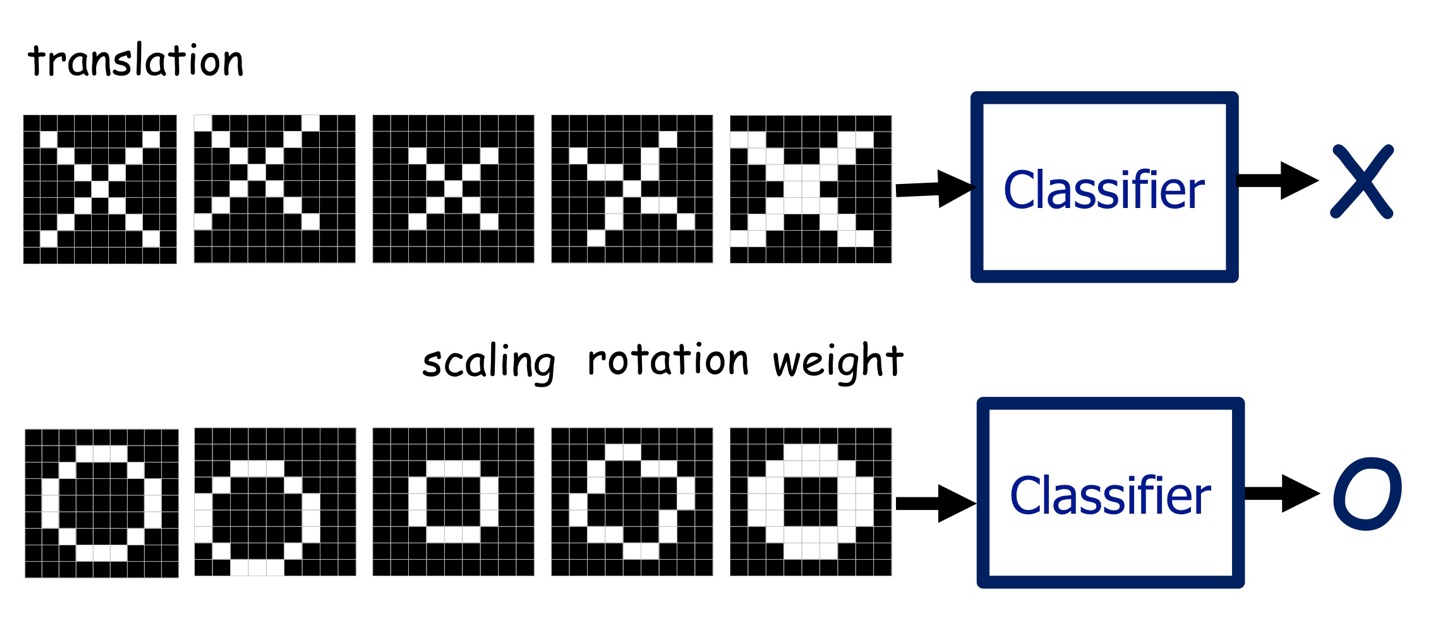
컴퓨터한테 어떤 이미지를 주고, 이게 X가 그려진 이미지인지, O가 그려진 이미지인지를 구분하게 하고싶다.
사람이 프로그램을 설계해서 구분이 가능할까? 아마 아닐 것이다.
하지만 Neural Net은 가능하다!
이제부터 어떻게 NN이 이미지를 구분하는지 그 과정에 대해 적어볼 것이다.
1.1. Local Features
위와 같은 작업을 Classifier가 처리할 수 있으려면 어떤 아이디어가 필요할까?
그 아이디어는 바로 Local Feature다.
이미지마다 고유의 패턴이 있을거고, 두 이미지의 패턴이 비슷한 위치에서 발견된다면 두 이미지는 서로 같은 이미지일거야.
여기서 고유의 패턴이 Local Feature.
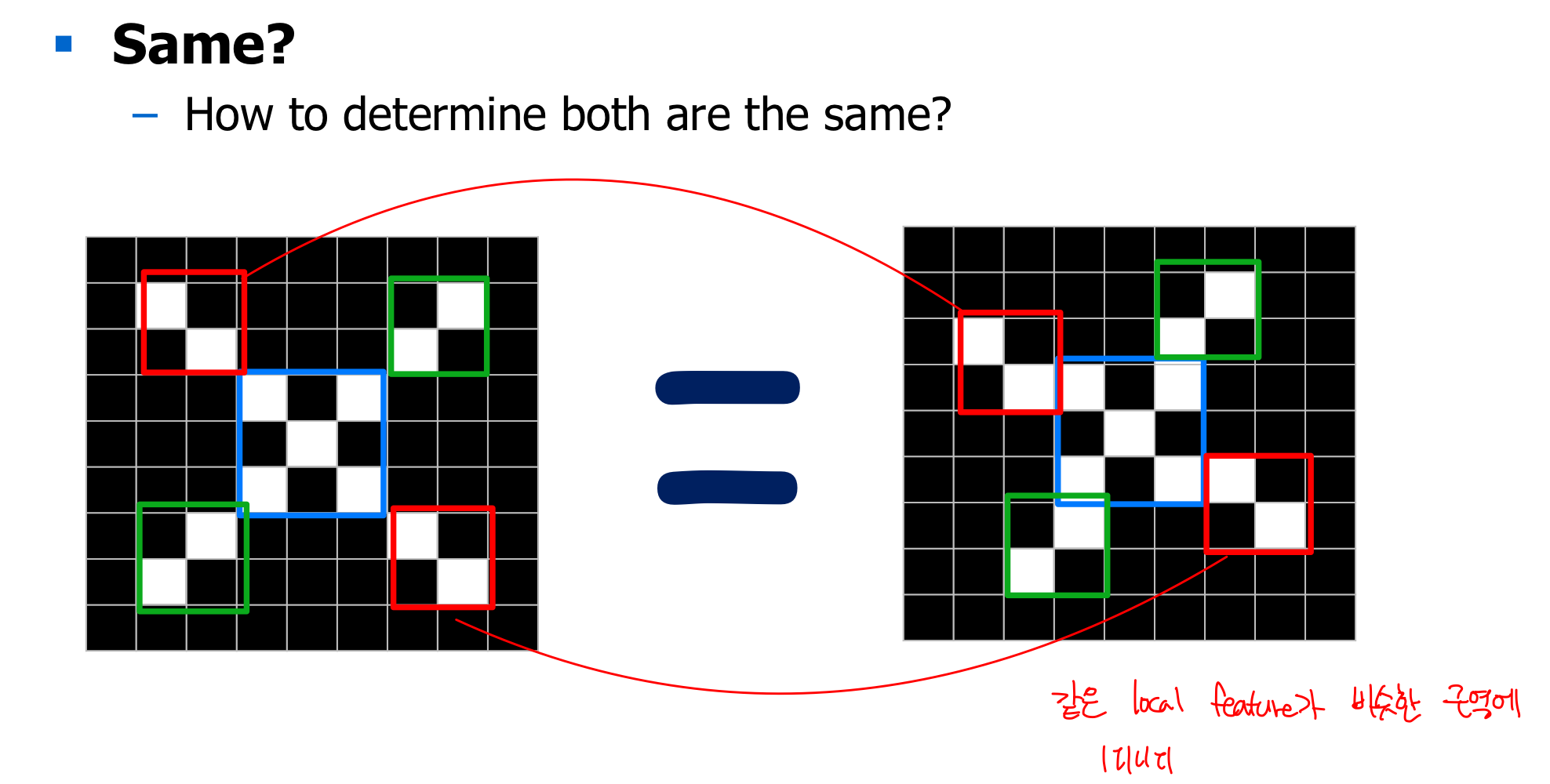
대충 이런 아이디어란 뜻이다.
당연히 "대체 이 local feature는 어떻게 정하고, 어떻게 비슷하다는걸 수치화할거야?"라는 의문이 들 것이다.
그걸 해내는 것이 바로 Convolution이다.
2. Convolution Layer
2.1. Convolution
Convolution 연산은 두 matrix의 similarity를 수치화하는 연산이라고 이해하자.
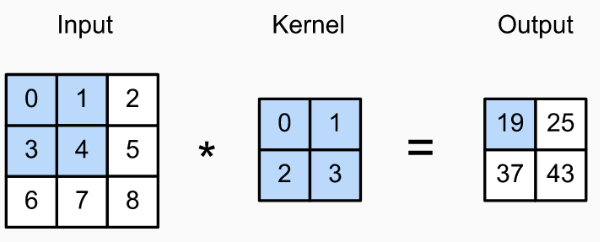
위 이미지는 Input matrix와 kernel의 convolution 연산을 나타낸 것이다.
파란색이 칠해진 부분을 보면, 행렬의 각 위치별 원소의 곱들을 전부 합하면 그게 convolution 연산이다.
임을 직관적으로 이해가 가능하다.
이런 과정은 vector의 dot product와 동일한 과정이고, 연산이 갖는 의미도 같다.
즉, convolution 연산은 두 matrix의 similarity값을 계산하는 과정이다.
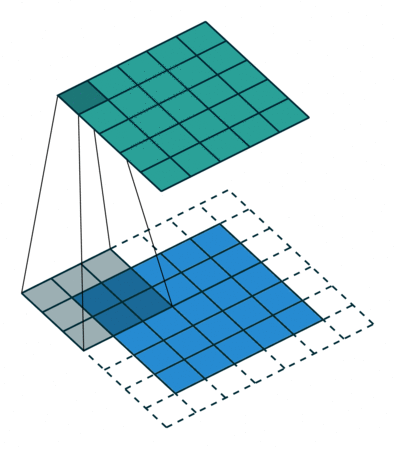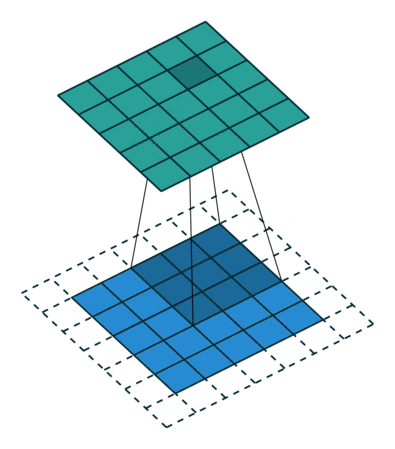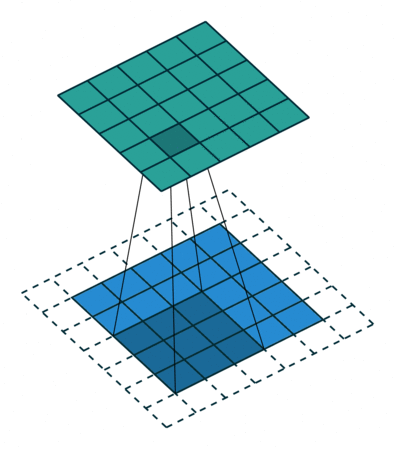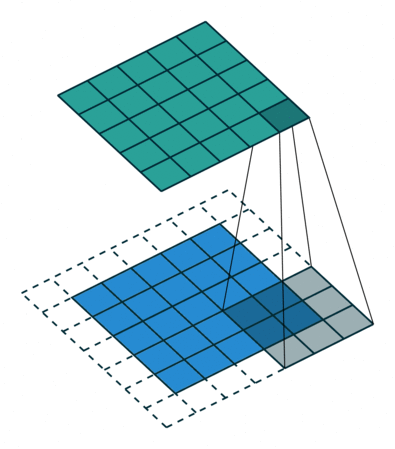
위 움짤에서 파란색이 input data, 점선으로 그려진 부분이 padding(0으로 채워진 값), 아래쪽 어두운 사각형이 filter(kernel)이다. 위쪽 청록색 사각형은 convolution 연산의 출력이다.
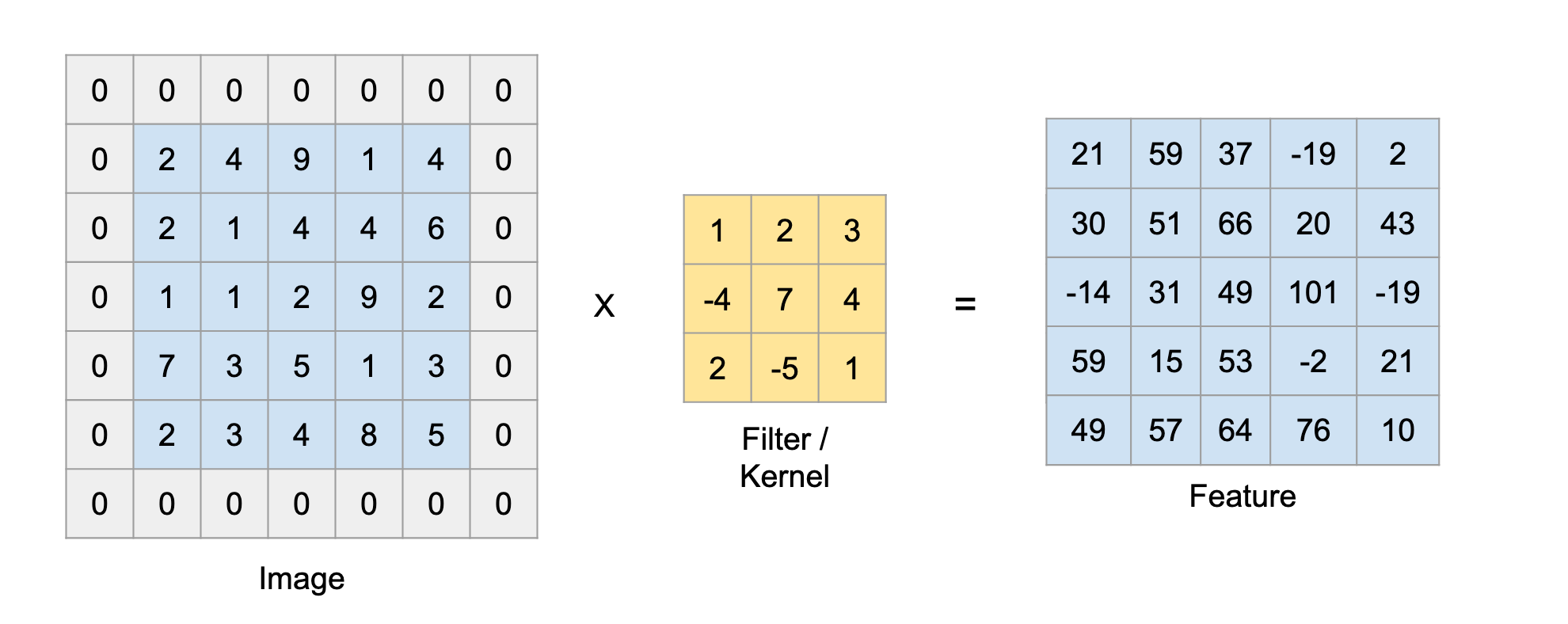
이렇게 Filter를 쭉 Image에 적용해서 나온 결과를 Feature라고 한다.
이 Feature를 다시 ReLU함수에 넣어서 0보다 작은 값은 0으로, 큰 값은 그대로 출력시키면 Convolution이 끝난 것이다.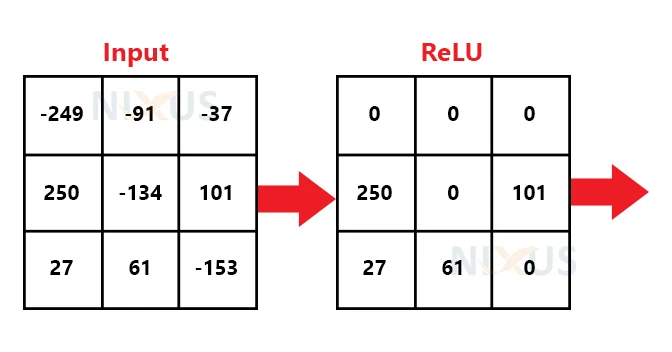
그렇게 나온 Feature map은 Filter와 유사한 부분이 이미지의 어디에 존재하는지를 알려주는 것이다.
위에서 쪽 예시로 1장 짜리 input, 1장 짜리 filter를 보여주었는데, 이제부터 1 장 == 1 channel 이라 부른다.
흑백 이미지야 0부터 255값의 1 채널의 이미지로 표현이 가능하지만, 실제로 우리가 사용하는 이미지는 3 채널 이미지다. RGB채널이 각각 존재하는 이미지.
그렇다면 이 컬러 이미지를 convolution하려면 필터는 어떻게 구성되고, 연산은 어떻게 이루어질까?
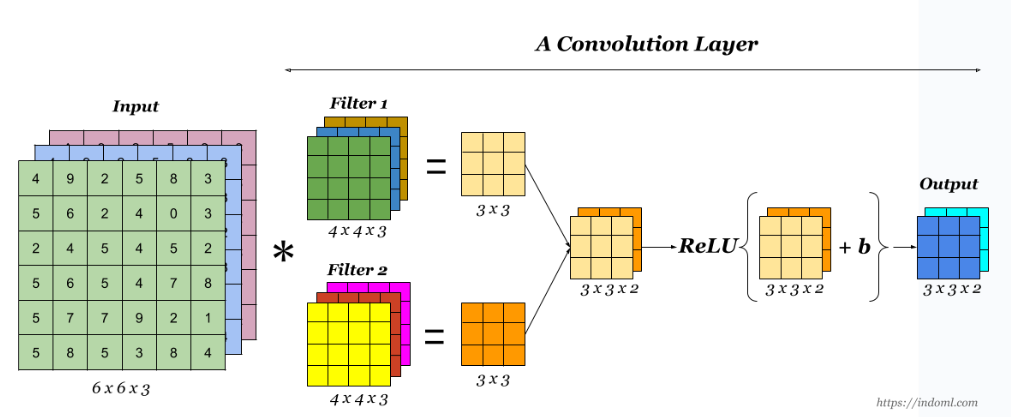
바로 이렇게 이루어진다. 위 이미지에서 convolution 연산은
input_channel1 filter_channel1 + input_channel2 filter_channel2 + input_channel3 filter_channel3
로 계산된다.
Input이 3채널이면 필터도 3채널, N채널이면 N채널,
이런식으로 필터의 채널 수는 Input의 채널 수와 같아야 한다.
필터 하나 당 feature 정보가 담긴 채널 1개짜리 행렬이 나오기 때문에, Convolution layer를 통과한 Output은 필터 개수만큼의 채널수를 갖게 된다.
위 그림에서도 필터가 2개라 Output의 채널도 2인 것을 확인할 수 있다.
2.2. Pooling
Convolution 연산을 통해 feature map을 얻어냈다. 그런데 우리가 사용하는 이미지는 보통 1920 1080 픽셀인 경우가 많고, 컬러 이미지이기 때문에 1920 1080 3개의 픽셀을 전부 계산하고 또 그런 이미지를 여러 번, 여러 장을 연산하려면 당연히 리소스가 많이 들 것이다.
이런 현상을 해결하기 위해 사용하는 것이 바로 Pooling이다.
이미지 특징은 크게 보나 작게 보나 대충 어떤 것에 대한 이미지인지는 파악이 가능하다는 것이다. 이런 특징에 기반해 이미지는 압축시켜도 정보량 손실이 크지 않다는 것을 알 수 있고, Pooling을 마음놓고 쓸 수 있는 것이다.
Pooling은 m m 픽셀을 1 픽셀로 만드는 과정이다.
종류로는 Max, Average 등등이 있다.
그 중 max pooling은 m m 픽셀 중 가장 큰 값을 1픽셀의 값으로 할당하는 것이다.
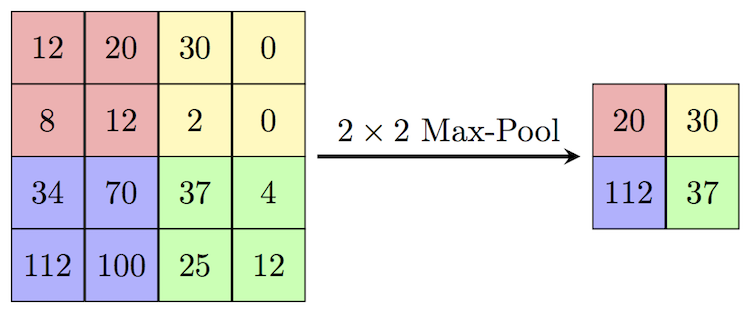
이렇게 계산하는거다. 매우 간단!
Pooling 과정은 Convolution Layer에 무조건 들어가야 하는건 아니고, convolution에 padding을 주지 않아도 사이즈가 줄어들기 때문에(?) 보통 전체 CNN에서 3번 - 4번정도 진행한다고 한다.
2.3. Classification
이렇게 convolution layer에 대해 알아봤다. layer를 반복해서 진행하면 이미지의 액기스가 나오고, 이걸 classification을 하면 그게 바로 Image Classification이다.
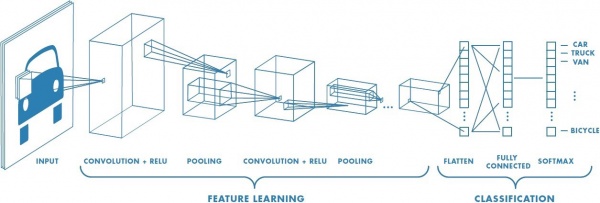
바로 이렇게. Convolution Layer의 맨 마지막 결과물을 1자로 펼쳐서 그걸 Fully Connected Layer를 거치게 하면 끝!