참고도서
- Machine Learning: a Probabilistic Perspective by K.Murphy
- Deep Learning by Goodfellow, Bengio, and Courville
- Stanford CS231N 강의자료
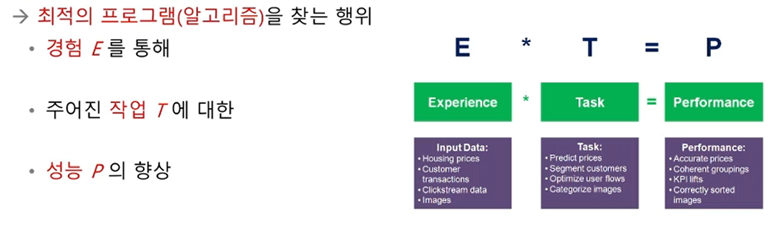
기계학습의 정의 및 개념
- 현대적 정의
어떤 컴퓨터 프로그램이 T라는 작업을 수행한다. 이 프로그램의 성능을 P라는 척도로 평가했을 때 경험 E를 통해 성능이 개선된다면, 이 프로그램은 학습을 한다고 말할 수 있다. - Mitchell1997(2쪽)
-
훈련을 마치면, "추론"을 수행
- 새로운 특징에 대응되는 목표치의 예측 -
기계학습의 궁극적인 목표
- 훈련집합에 없는 새로운 데이터에 대한 오류를 최소화(새로운 데이터=테스트 집합)
- 테스트 집합에 대한 높은 성능을 일반화 능력이라 부름
-
기계학습의 필수 요소
- 학습할 수 있는 데이터가 있어야 함
- 데이터 규칙이 존재해야 함
- (규칙이) 수학적으로 설명이 불가능해야 함
다차원 특징 공간
모든 데이터는 정량적으로 표현되며, 특징 공간 상에 존재
- -차원 데이터
- 특징 벡터 표기:
- 선형 모델을 사용하는 경우: 매개변수 수 =
- 2차 곡선 모델을 사용하는 경우: 매개변수 수 = (지수적으로 증가)
- 차원의 저주
- 차원이 높아짐에 따라 발생하는 현실적인 문제들
- 예) 인 MNIST 샘플의 화소가 0과 1값을 가진다면 개의 (특징 공간) 칸이 있는데, 이 거대한 공간에 고작 6만 개의 샘플을 흩뿌린다면 매우 희소한 분포
- 차원이 높아질수록 유의미한 표현을 찾기 위해 지수적으로 많은 데이터가 필요
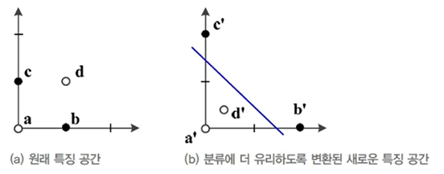
특징 공간 변환과 표현 문제
-
특징 공간 변환
선형 분리 불가능한 원래 특징 공간을 새로운 특징 공간으로 변환 시 선형 모델로 100% 정확도를 얻을 수 있다.

-
표현 학습
- 좋은 특징 공간을 자동으로 찾는 작업
-
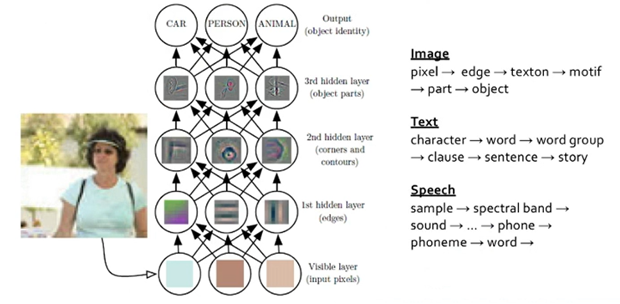
심층 학습
- 표현 학습의 하나로 다수의 은닉층을 가진 신경망을 이용하여 최적의 계층적인 특징을 학습
- 아래쪽 은닉층은 저급 특징(선, 구석점 등), 위쪽 은닉층은 추상화된 특징(얼굴, 바퀴 등) 추출
간단한 기계학습의 예
- 선형 회귀를 위한 목적 함수(MSE, 평균제곱오차)
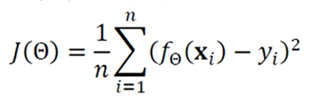
- 는 예측함수의 예측 출력
- 는 예측함수가 맞추어야 하는 실제 목표치
- 는 오차 혹은 손실
기계학습은 작은 개선을 반복하여 최적의 해를 찾아가는 수치적 방법
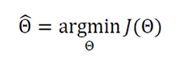
-
기계학습 요소
- input
- output
- target distribution
- data
- hypothesis -
지도학습
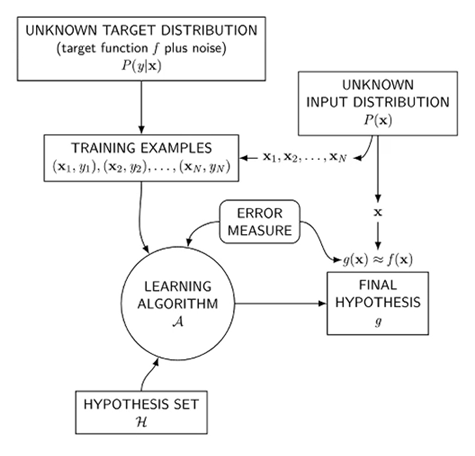
모델 선택
과소적합과 과잉적합
-
1차~12차 다항식 모델의 비교 관찰
- 1~2차는 훈련집합과 테스트집합 모두 낮은 성능 → 과소적합
- 12차는 훈련집합에 높은 성능을 보이나 테스트집합에서는 낮은 성능 → 낮은 일반화 능력, 과잉적합 -
모델의 일반화 능력와 용량의 관계
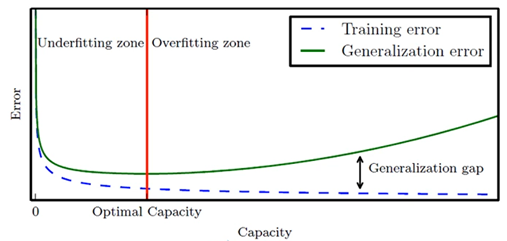
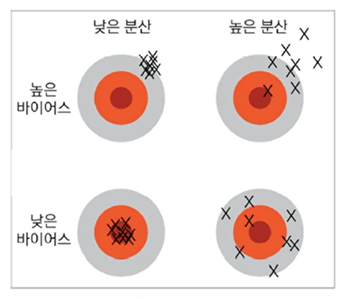
편향과 분산
일반적으로 용량이 작은 모델은 편향이 크고 분산이 작으며, 복잡한 모델은 편항이 작고 분산이 크다. → 편향과 분산은 상충 관계
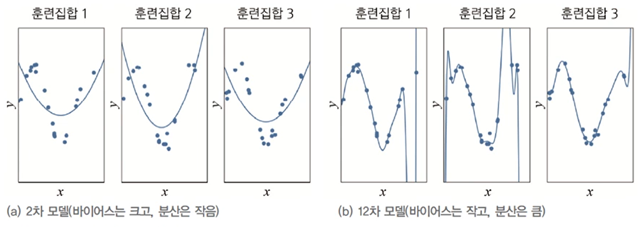
낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표!
하지만 모델의 편향과 분산은 상충 관계이므로 편향을 최소로 유지하며 분산도 최대로 낮추는 전략이 필요하다.
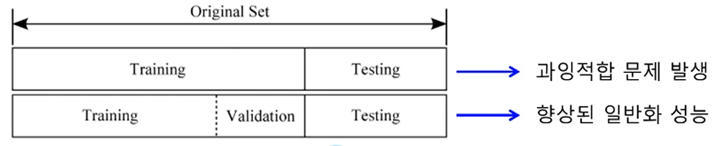
교차검증
- 검증집합을 이용한 모델 선택
- 훈련집합과 테스트집합과 다른 별도의 검증집합(validation set)을 가진 상황
- 부트스트랩
- 임의의 복원 추출 샘플링 반복
- 데이터 분포가 불균형일 때 적용
가중치 감쇠
가중치 감쇠는 개선된 목적함수를 이용하여 가중치를 작게 조정하는 규제 기법
- 가중치 감쇠를 가진 선형 회귀 예시

- : 감쇠 없음
- 큰는 가중치가 더 작아지도록 함
다양한 학습 유형
-
오프라인 학습/온라인 학습
- 온라인 학습은 IoT 등에서 추가로 발생하는 데이터 샘플을 가지고 점증적 학습 수행 -
결정론적 학습/확률적 학습
- 결정론적 학습에서는 같은 데이터를 가지고 다시 학습하면 같은 예측 모델이 만들어진다.
- 확률적 학습은 학습 과정에서 확률 분포를 사용하므로 같은 데이터로 다시 학습하면 다른 예측 모델이 만들어진다.
-
분별 모델/생성 모델
- 분별 모델은 부류 예측에만 관심 즉, 의 추정에 관심
- 생성 모델은 또는 를 추정- 따라서 새로운 샘플을 '생성'할 수 있음
