1️⃣지도학습의 2단계
1단계: Training (훈련 단계)
- 주어진 훈련 데이터로 분류기(classifier)나 회귀기(regressor)를 학습시킴
- 기계학습 알고리즘은 이 데이터들의 분포와 패턴을 학습하여, 새로운 데이터가 들어왔을 때 어떤 클래스에 속할지 구분할 수 있는 결정 경계(decision boundary) 를 만듦
2단계: Inference/Test (추론/테스트 단계)
- 보지 못한 데이터를 학습된 규칙에 따라 분류하거나 값을 예측하는 단계
- 새로운 데이터가 들어옴
- 학습된 모델은 이 데이터를 보고, class1일지, class2일지를 예측
2️⃣훈련데이터 VS 테스트데이터
1. Training data (훈련 데이터)
- 이미 정답(label) 이 알려진 데이터
- 모델이 이 데이터를 사용해 패턴을 학습함
- 예:
Sepal length, Sepal width, Petal length, Petal width → label(꽃 종류)
2. Test data (테스트 데이터)
- 모델이 학습한 규칙을 적용하여, 보지 못한 데이터를 평가하는 용도
- 정답(label)을 숨기고, 모델이 예측한 결과와 실제 값을 비교해 성능 검증
- 예:
Sepal length, Sepal width, Petal length, Petal width → ?
👉 즉, Training = 배우는 단계, Test = 확인하는 단계
3️⃣예시
1. Iris Dataset (3-class 분류 문제)
- 데이터: 붓꽃(iris)의 특징 → 꽃받침(Sepal) 길이·너비, 꽃잎(Petal) 길이·너비
- 목표: 어떤 종(
Setosa, Versicolor, Virginica) 인지 분류 - 과정
- 데이터 분할: 보통
70% Training, 30% Test로 나눔 (과적합 방지 목적) - 전처리 (Preprocessing): 평균 0, 표준편차 1로 표준화 (StandardScaler)
- 모델 학습 (Training)
- 테스트 (Evaluation)
- 데이터 분할: 보통
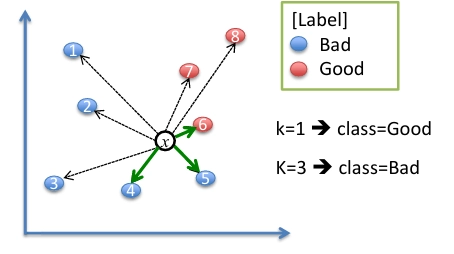
2. KNN(Classifier)
- 개념: 새로운 데이터가 들어오면, 그 주변 가장 가까운 이웃 데이터(K개)를 보고 다수결로 분류
- 절차:
- K 값과 거리 계산 방법(유클리드 거리 등)을 정한다.
- 테스트 샘플 x가 주어지면, 모든 학습 데이터와의 거리를 계산한다.
- 가장 가까운 K개의 이웃을 고른다.
- 그 중 다수인 클래스를 선택하고, 그것이 최종 분류 결과가 된다.
- k=1 → 가장 가까운 이웃이 빨강(“Good”) → 분류 결과 = Good
- k=3 → 가장 가까운 이웃 3개 중 파랑(“Bad”)이 다수 → 분류 결과 =
✅K값 선택 방법
- K가 작을 때: 불안정함(= 분산이 높음)
- K가 클 때: 불확실함(=편향이 높음)
- K 선택 원칙:
- 데이터셋의 특성에 따라 다름
- 최적의 K는 모델 평가(validation) 를 통해 찾음
- 이웃의 크기인 K는 하이퍼파라미터(hyperparameter)라서 학습 전에 정해야 하는 값임
4️⃣Overfitting (과적합)
- 정의: 모델이 훈련 데이터에서는 잘 맞추지만, 새로운 데이터에서는 성능이 떨어지는 상태
- 원인: 모델이 너무 복잡하거나, 데이터에 노이즈까지 외워버린 경우
- 결과: Training error ↓, Generalization error ↑
1. Training error (훈련 오류)
- 훈련 데이터에서 계산된 오류
- 모델이 학습 데이터에 얼마나 잘 맞추는지를 평가하는 지표
2. Generalization error (일반화 오류)
- 테스트 데이터에서 발생할 기댓값 오류
- 모델이 학습하지 않은 새로운 데이터에서도 잘 동작하는지를 평가하는 지표
📌결론
- Training error도 낮고, Generalization error도 낮아야 함
- 즉, 훈련 데이터에서만 성능이 좋은 게 아니라, 실제 새로운 데이터에서도 성능이 좋아야함
5️⃣Three-way Data Split (훈련/검증/테스트 세트 분할)

1. Training set (훈련 세트)
- 모델을 학습시키는 데 사용되는 데이터
- 모델이 패턴을 배우는 단계에서만 사용
2. Validation set (검증 세트)
- 모델 비교 및 하이퍼파라미터 튜닝에 사용 (ex. 다항회귀에서 차수 M 선택, KNN에서 K 값 선택)
- 여러 후보 모델 중에서 최적 모델을 고르는 용도
- 훈련에 직접 포함되지 않음 → 과적합 방지 역할
3. Test set (테스트 세트)
- 최종 모델의 성능 평가에만 사용
- 일반화 오류(generalization error) 추정
- 모델 선택이나 튜닝에는 절대 사용하지 않음
✅K-fold cross-validation (교차 검증)
- 훈련/검증 세트를 고정하면, 데이터가 적을 때 성능 평가가 불안정해질 수 있음
- 해결책: 교차검증(cross-validation)
- 데이터를 여러 조각(fold)으로 나누고, 교차적으로 훈련/검증에 사용
- 데이터 크기가 작을 때 특히 효과적

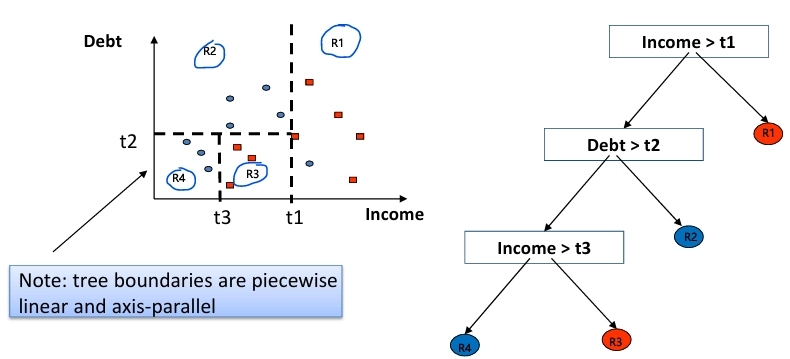
6️⃣Decision Tree (의사결정 트리)
- 트리 구조 형태의 머신러닝 모델
- 마치 질문을 계속 던지면서 "예/아니오"로 가지를 따라 내려가고, 마지막엔 결과를 얻는 구조
- 분할 정복
- 장점
- 이해하기 쉬움: 트리 구조라서 비전문가도 “이 조건이면 → 이 결과” 방식으로 직관적으로 설명 가능
- 다목적: 분류(Classification) 문제뿐 아니라 회귀(Regression) 문제에도 사용할 수 있음
- 단점
- 성능 한계: 단순한 트리 하나만으로는 복잡한 패턴을 학습하는 데 한계가 있음.
- 높은 분산: 학습 데이터에 민감해서, 데이터셋이 조금만 바뀌어도(ex. 샘플 하나 제거) 트리 구조가 크게 달라질 수 있음 → 과적합 위험이 큼
✅Pruning (가지치기)
- 배경: 의사결정나무를 끝까지 성장시키면 과적합되어 일반화 성능이 떨어짐
- 해결책: 트리를 적당히 잘라서 모델 단순화 → 복잡도를 줄여 새로운 데이터에 대한 예측 정확도를 높임
7️⃣노드 불순도 (Node impurity)
- DT를 학습할 때, 각 노드에서 데이터를 어떻게 나눌지를 판단하는데 사용되는 지표 (낮을수록 좋음👍)
- 데이터가 한 클래스에만 속하면 → 순수(Pure), 여러 클래스가 섞여 있으면 불순(Impure)
- 대표적인 방법:
Gini index/Entropy
1. Gini Index (지니 불순도)
- 정의 (pi = 클래스 i에 속할 확률)
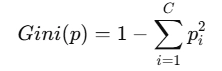
- 해석
- 모든 샘플이 한 클래스에 속하면 Gini=0 (완전 순수)
- 클래스가 고르게 섞여 있을수록 Gini 값이 커짐
- 예시
- 두 클래스가 50:50 →
- 한쪽이 100% →
2. Entropy (엔트로피)
- 정의 (단, pi=0일 때는 해당 항을 0으로 처리)
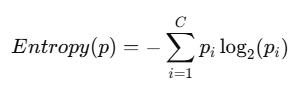
- 해석
- 순수할수록(한 클래스 확률=1) → Entropy = 0
- 모든 클래스가 균등 분포일수록 → Entropy 최대
- 예시
- 두 클래스가 50:50 → −{0.5log(0.5)+0.5log(0.5)} = 1
- 한쪽이 100% → -{log(1)+0} = 0
📌분할하기 전의 엔트로피와 분할한 후의 엔트로피의 차이(=Information Gain)가 가장 큰 속성이 나누는 기준이 됨!!
8️⃣편향(Bias)과 분산(Variance)
- Bias (편향): 너무 단순한 모델 때문에 생기는 오류 (ex. 비선형 패턴을 선형 회귀로 억지로 맞출 때)
- Variance (분산): 학습 데이터에 대한 민감도 (샘플이 조금만 바뀌어도 예측이 크게 달라지는 정도)
- 좋은 모델: 두 가지를 적절히 균형시켜 일반화 성능을 최대화 (Bias-Variance tradeoff)
9️⃣Ensemble (앙상블)
- 개념: 여러 개의 분류기를 생성하고 각 예측들을 결합함으로써 보다 정확한 예측을 도출하는 기법
- 배경(의사결정트리의 단점)
- 학습 데이터에 과적합되기 쉬움
- 데이터가 조금만 바뀌어도 구조가 크게 달리는 고분산 문제가 존재
→ 이를 완화하는 대표 해법이 바로 앙상블
1. Stacking(스태킹)
- 개념: 여러 베이스 모델의 예측값을 다시 메타 데이터셋으로 활용하여 메타 모델이 받아 학습하는 방식
- 흐름
- Base learners: DT, SVM, NN 등 서로 다른 알고리즘을 같은 데이터로 학습
- Meta-learner: 로지스틱 회귀, NN 등이 베이스 예측을 입력으로 최종 예측 학습
- 중요:
OOF(Out-of-Fold)예측으로 메타 학습 데이터를 만들어 데이터 누수 방지
2. Voting(보팅)
- 개념: 서로 다른 알고리즘으로 예측하고, 그 결과를 가지고 투표를 통해 최종 예측 결과를 선정하는 방식
- Hard voting: 예측 결과 중 다수의 분류기가 결정한 값을 최종 결과값으로 선정 (=다수결)
- Soft voting: 각 예측 결과의 레이블 값 결정 ****확률들의 평균값이 높은 레이블 값을 최종 결과값으로 선정
- 서로 상관 관계가 낮은 모델을 섞을수록 이득이 큼
- 확률 보정이 잘 되면 Soft가 유리함
3. Bagging(배깅)
- 개념: 같은 알고리즘으로 데이터셋만 다르게 여러 분류기를 만들고, 보팅으로 최종 결정하는 방식 (병렬)
- 효과: 분산 감소 → 과적합 완화
3-1. Random Forest(랜덤 포레스트)
-
여러 개의 DT분류기가 전체 학습 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤, 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 하는 방식
-
Bagging + 각 노드 분할 시 무작위 특성 하위집합만 후보로 사용
-
트리 간 상관관계를 낮춰 일반화 향상
✅Bootstrapping(부트스트래핑): 학습 데이터를 여러 개의 데이터 세트로 중첩되게 분리하는 것
-
4. Boosting(부스팅)
- 개념: 모델을 순차적으로 쌓아서, 앞선 모델의 오차를 다음 모델이 보완 (순차)
- 효과: 편향 감소
- 강력하지만 튜닝 필요. 과적합 방지를 위해 early-stopping/정규화 활용
4-1. AdaBoost(에이다 부스트)
Step 1 : 첫 번째 약한 학습기가 파란색과 빨간색을 분류
Step 2 : 오분류된 데이터에 대해 가중치 값을 부여
Step 3 : 두 번째 약한 학습기가 파란색과 빨간색을 분류
Step 4 : 오분류된 데이터에 대해 가중치 값을 부여
Step 5 : 세 번째 약한 학습기가 파란색과 빨간색을 분류
Step 6 : 마지막으로 세 개의 약한 학습기를 모두 결합한 예측 결과4-2. Gradient Boosting
- AdaBoost와 비슷하나, 경사 하강법을 이용하여 가중치 업데이트를 진행한다는 차이가 존재
- 경사하강법: 오차값(=실제값-예측값)을 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것
- 예측 성능은 뛰어나나 수행 시간이 오래 걸린다는 단점이 존재

개발자를 꿈꾸는 대학생