이번에 리뷰할 논문은 바로 "A Dynamic Residual Self-Attention Network for Lightweight Single Image Super-Resolution" 입니다.
해당 논문을 읽기 이전에 몇 가지 초점을 세워두고 논문을 찾게 되었습니다.
- 고해상도 이미지를 처리하는데 있어서 추가적인 파라미터 및 계산 복잡성 없이 성능을 잡을 수 있을지
- 복잡한 Architecture가 아닌 단순한 idea를 기반으로 활용하였는지
- 다양한 입력 영상 혹은 이미지에 대해서 유연하게 대처가 가능한지
위 3개의 질문을 답해준 논문이 바로 해당 논문입니다. 본 논문은, 기존의 너무 유명한 shortcut connection을 주된 아이디어로 고해상도 이미지를 처리하며 다양한 입력에 대한 특징적 통계에 따라 유연하게 대응이 가능한 전략을 제시하고 있습니다.
그럼 본격적으로 리뷰해보도록 하겠습니다❗️
SISR Model에서 본격적으로 CNN이 활용이되면서 많은 성능향상이 이루어졌습니다. 기존의 Vision 분야에서 CNN의 활용 이후 다양한 연구에서 더 깊은 layer를 쌓아 올리는 연구가 활발하게 이어졌습니다. 이러한 영향은 SISR Model의 연구에도 이어졌으며 더 깊은 layer가 더 높은 성능을 기록했으나 파라미터와 계산 복잡성이 증가한다는 점에서 한계가 존재했습니다. 더불어 미리 설계된 고정 구조로 인해서 input video의 statistics의 다양성에 대한 유연한 대처가 어려운 문제가 존재합니다.
이런 문제들을 해결하고자 본 논문에서는 Buliding block 간의 Residual Connection을 Dynamic하게 설계하여 경량화를 하고자 했습니다. Dynamic Residual Self-attention Network(DRSAN) 제안은 크게 두 가지 측면에서 핵심 제안들이 존재합니다.
- Dynamic Residual Attention(DRA)에 기반하여 입력 영상의 통계의 다양성에 동적으로 지원이 가능
- 추가적인 파라미터 없이 3차원 Attention map을 생성하는 Residual Self-attention module(RSA)로 성능 향상
즉, 본 논문에서 제안하고 있는 DRSAN은 DRA와 RSA의 조합으로 제안되어 동적으로 다양한 입력들에 대한 유연성과 Complexity Computational과 성능 사이의 균형을 이루었습니다.
CNN based SR Model인 SRCNN의 경우, 간단한 3-layer CNN으로 우수한 성능을 기록하였습니다. 이와 함께 Vision 분야에서의 Shortcut Connection, elementwise addition을 통해 Network의 성능 향상 및 Optimize의 어려움을 해결하는 연구들이 이어졌습니다. 이러한 영향을 받아 SR Model도 더 깊게 설계하고자 하는 연구들이 이어지게 됩니다. 하지만 이러한 연구 방향성은 많은 Complexity Computational과 많은 Parameter를 요구하기 때문에 이를 실생활에 사용하는 데 많은 어려움이 존재합니다. 더불어 Lighting하는 과정 속에서 Network의 성능과 비용의 Trade-off 관계에서 균형이 매우 중요한 과제로 여겨집니다.
이러한 균형을 잡기 위해서 많은 선행된 연구들이 이어져 왔습니다. 특히, 네트워크의 가중치를 재사용하여 파라미터를 줄이는 Recursive 네트워크 구조를 제안하여 파라미터를 줄이는 데 기여하였습니다. 하지만 해당 방식의 경우 네트워크 연산 수가 증가하였기에 근본적인 문제를 해결하지 못한 한계점이 존재하였습니다. 이에 더 나아가 파라미터와 연산량 문제를 해결하기 위해 Shortcut Connection을 적극적으로 활용하는 연구들이 이어지게 됩니다.
Feature 재사용 이외에도 많은 연구들이 이어졌으며 대표적으로 Attention mechanism을 활용한 연구가 있습니다. Attention 관련 연구로는 1D Channel Attention, 3D Channel Attention 등의 변형 연구들이 이어졌습니다. 하지만 Optimize된 구조를 찾기 위해서 많은 실험이 필요하기 때문에 시간적 소요가 가장 큰 문제가 존재하였습니다. 더불어 입력 이미지의 다양한 statistics에 유연하게 대응하기 위해선 동적으로 최적화 된 연산이 필요합니다. 그러나 선행된 연구들의 경우 동일한 연산 및 고정된 Architecture로 대응하기에 유연성이 떨어지는 문제점이 존재하였습니다.
위의 문제들을 해결하기 위해 본 논문에서는 Residual Connection을 사용하여 HR 이미지를 재구성하는 Dynamic Residual Self-Attention Network(DRSAN)을 제안하게 되었습니다. 이는 복잡한 고정된 Network 구조 설계가 아닌 입력 이미지의 특징에 따라 동적으로 Residual Connection을 제어하도록 설계하였습니다. 이를 통해 Buliding block 사이의 Residual Connection을 동적으로 자동화 설계를 통한 경량화를 수행합니다.
-
Dynamic Residual Attention(DRA): Input image의 feature에 따라 Residual Connection 제어 수행
-
Residual Self-attention(SRA): 3D Attention map을 사용하여 Feature를 Adaptive recalibrates 수행
이를 통해서 더 적은 파라미터로 더 좋은 성능을 기록할 수 있습니다.
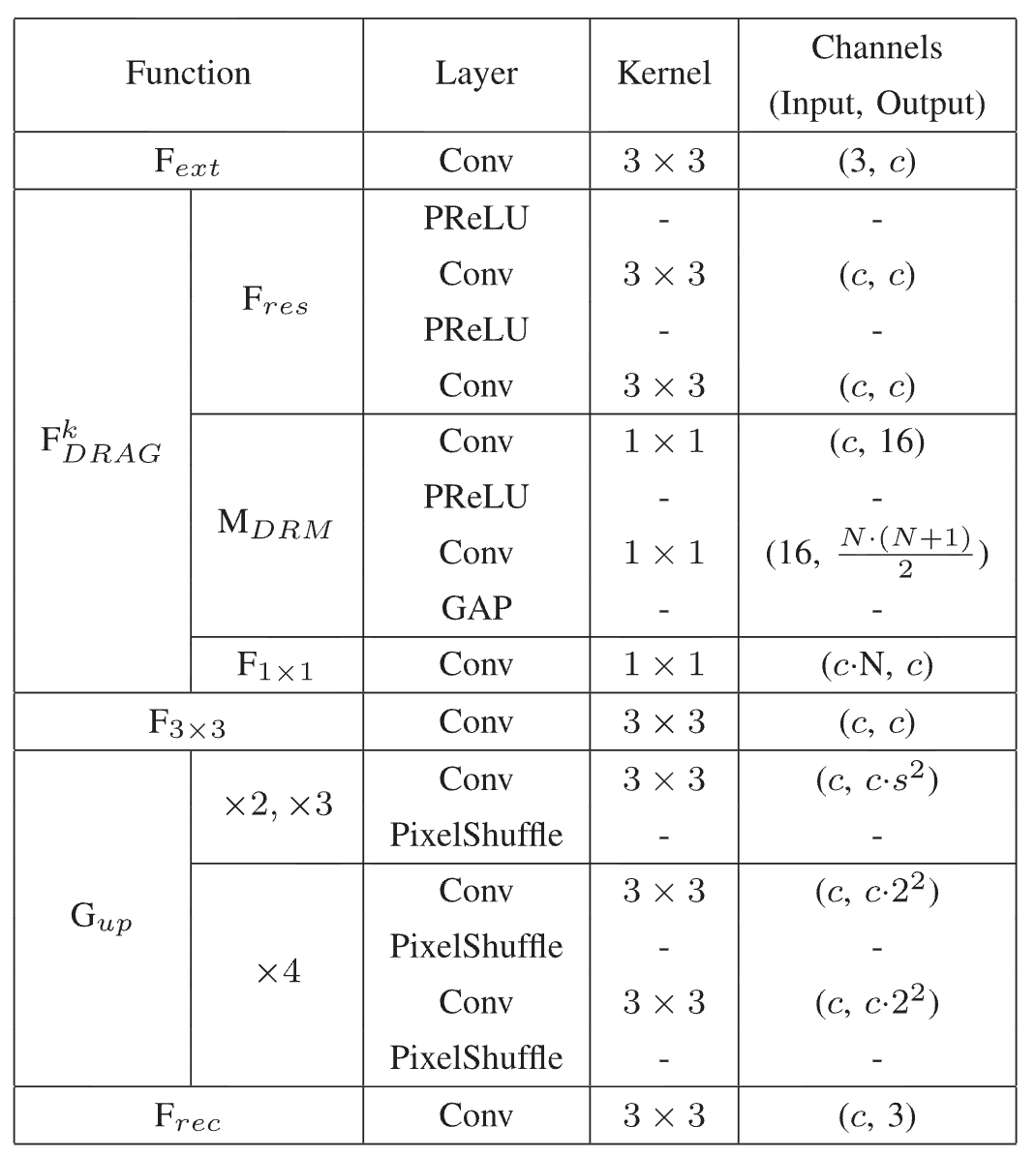
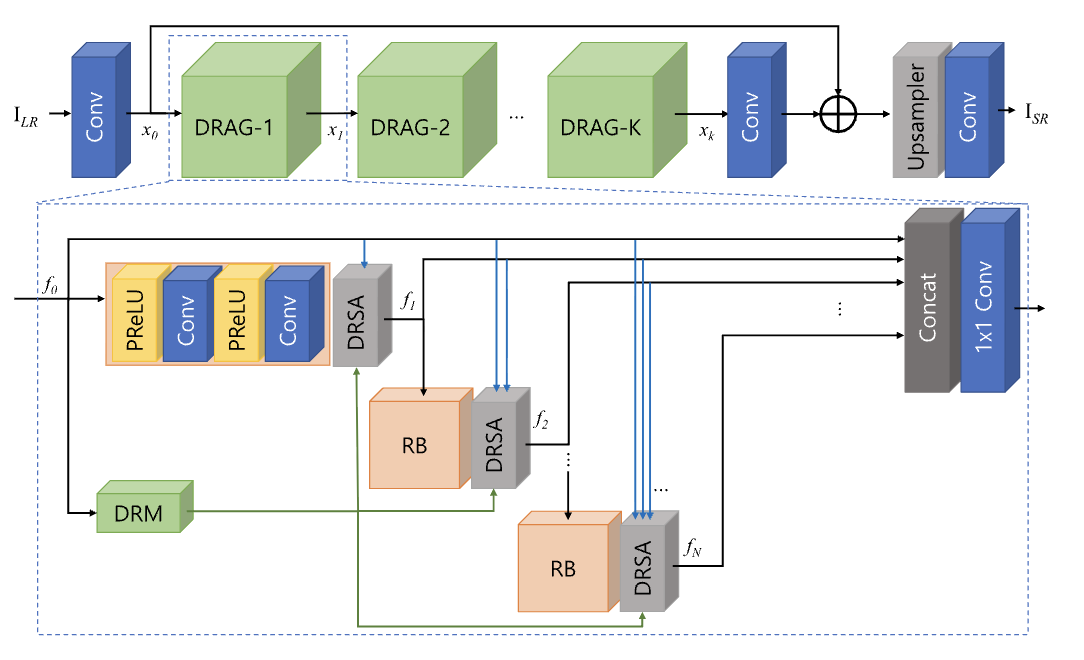
DRSAN의 경우, 크게 세 가지 주요 모듈로 구성되어 있으며 이는 각각 Feature Extraction Module, Non-linear Mapping Module, Reconstruction Module 입니다.
-
Feature Extraction Module: 입력으로 받은 저해상도 이미지에서 초기에 Shallow feature를 추출하는 역할을 수행합니다. 이는 매우 간단하게 커널 크기가 3인 하나의 Convolution layer로 구성되어 있습니다. 해당 모듈의 feature를 나머지 두 모듈로 전달하게 됩니다. 먼저, 다음 단계인 Non-linear Mapping Module로 전달하여 더 깊은 수준의 특징을 학습하는 데 사용이 되며 Reconstruction Module로의 전달을 통해 저해상도 이미지의 중요한 정보를 최종 고해상도 이미지 재구성 과정에서 보존하는 데 기여하여 Global Residual learning 기법을 활용합니다.
-
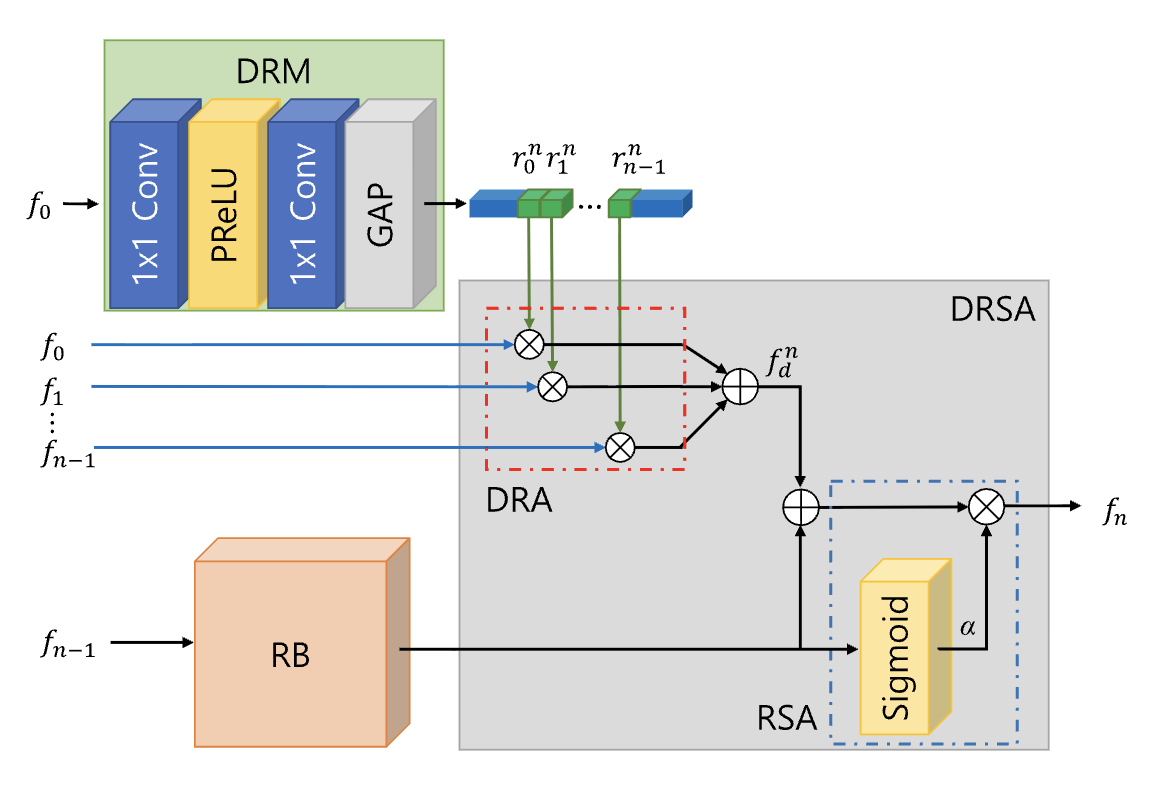
Non-linear Mapping Module: 해당 모듈은 Shallow feature를 받아 이미지 복원에 필요한 high-level feature을 학습하고 추출합니다. 해당 모듈의 경우 크게 3가지 핵심 요소가 존재합니다. 먼저, Residual Block(RB)으로 잔차 학습을 통해서 최적화의 어려움 해결과 성능 저하 문제 해결게 기여하여 각 RB의 경우 Activation function으로 PReLU와 Convolution 순으로 구성되어져 있습니다. Dynamic Residual Module은 입력의 다양성을 동적으로 제어하는 핵심 요소입니다. 입력 이미지의 statistics를 분석하여 DRAG 내의 여러 RB로부터 오는 다양한 Residual path에 적절한 가중치를 할당하게 됩니다. 즉, 어떤 Residual Block의 출력을 얼마나 중요하게 사용할지 동적으로 결정합니다. 이를 통해서 feature 흐름을 유연하게 조절함으로 Network의 Representation을 높일 수 있습니다. 마지막으로 Dynamic Residual Self-Attention (DRSA)는 두 가지 형태의 attention mechanism을 포합하고 있습니다. 먼저, DRA의 경우, DBM에 의해 계산된 동적 가중치를 사용하여 이전 RB로부터 들어오는 특징들을 동적으로 결합합니다. 이를 통해서 각 Residual path의 중요도를 조절하고 다양한 입력에 대해서 최적의 특징 조합을 찾아낼 수 있습니다. 또 다른 attention mechanism은 바로 RSA입니다. 해당 기법은 Residual block 내부의 특징에 3차원 attention map을 생성하여 feature recalibrate을 수행합니다. 해당 기법은 추가적인 파라미터가 필요하지 않으며 이는 어텐션 계수를 생성하여 중요한 특징에 더 많은 가중치를 부여하고 덜 중요한 특징은 억제하여 네트워크의 성능에 기여합니다.
-
Reconstruction Module: 비선형 모듈에서 최종적으로 추출된 feature을 실제 고해상도 이미지 형태로 변환하고 재구성하는 마지막 모듈입니다. 해당 모듈은 먼저, 3x3 convloution layer를 적용합니다. Global Residual learngin을 통해서 네트워크가 LR 이미지와 HR 이미지 간의 직접적인 매핑이 아닌 잔차로 인해서 오히려 학습의 안정성을 높일 수 잇습니다. Upsampler Network는 하나의 Conv layer와 pixel-shuffle layer로 이루어져 있습니다. 해당 방식은 LR 공간에서 특징을 처리하고 마지막에 한 번에 업스케일링함으로써 계산 효율성을 극대화하며 아티팩트를 줄이면서 부드러운 업샘플링을 제공합니다. 최종적으로는 실제 RGB 리미지로 변환하여 재구성을 수행하게 됩니다.
{kind=link}
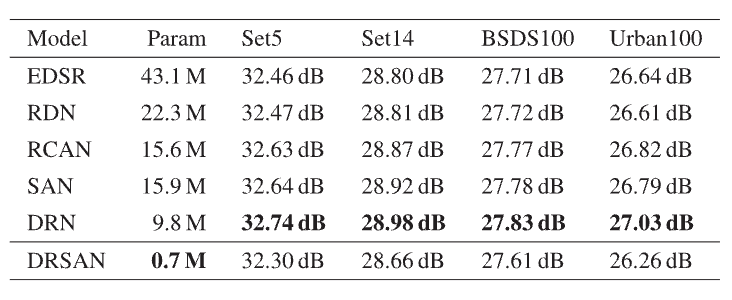
DRSAN이 기존의 무거운 SOTA 모델들과 비교했을 때, 모델 크기와 연산량이 현저히 적으면서도 이미지 초해상도 작업에서 매우 우수한 성능 효율성을 달성했음을 보여줍니다. 이는 모바일 기기나 실시간 처리와 같이 자원이 제한된 환경에서 DRSAN이 실용적으로 활용될 수 있음을 시사합니다.

2배, 3배, 4배 업스케일링을 수행하여 다양한 Single Image Super-Resolution (SISR) 모델들이 저해상도(Low-Resolution, LR) 이미지를 고해상도(High-Resolution, HR) 이미지로 복원하는 성능을 시각적으로 비교한 결과입니다.
결과적으로 본 논문의 제안은 입력 통계를 고려하여 다양한 잔차 특징의 조합을 활용하는 경량 SR 시스템을 위한 동적 잔차 네트워크 scheme을 제안했습니다. 또한 잔차 구조와 협력하여 추가 모듈 없이 네트워크 성능을 향상시키는 RSA를 도입했습니다. 네트워크 설계 scheme 및 attention 메커니즘은 복잡한 네트워크 구조를 설계하지 않고도 다른 잔차 네트워크에 쉽게 적용할 수 있습니다.
