Efficient Attention-Sharing Information Distillation Transformer for Lightweight Single Image Super-Resolution
Paper Review
이번에 읽은 논문은 "Efficient Attention-Sharing Information Distillation Transformer for Lightweight Single Image Super-Resolution" 입니다. 3D Image 및 SR Image를 다루면서 연구를 하면서 많은 어려움들이 있었습니다.
- 3D image processing model의 경우, 2D model의 비하면 아직 연구가 부족하다고 느꼈습니다.
- 고해상도 이미지의 경우에서의 Transformer based model의 경량화가 필요하다고 느꼈습니다.
- 위의 느낀 점들을 해결하기 위해서는 Engineering Design이 필요함을 느꼈습니다.
이러한 느낀 점을 바탕으로 3D Image와 SR image, 경량화에 대해서 관심을 갖게 되었고 이를 위해서는 공학적인 설계가 필요하다고 느꼈습니다. 이런 상황 속에서 해당 논문이 부족한 점들을 해결하는 하나의 솔루션이 된 논문이라 생각합니다.
그럼 바로 리뷰해보도록 하겠습니다❗️
해당 논문에서 주된 전략은 바로 "Information Distillation + Attention Sharing + Channel-split" 입니다. 해당 3가지 전략을 통해서 Transformer based SISR model을 설계함과 동시에 경량화와 성능을 모두 잡을 수 있는 핵심 Point라고 생각합니다.
SISR model의 경우, 하나의 저해상도(Low-Resolution, LR) 이미지를 입력받아서 하나의 고해상도(High-Resolution, HR) 이미지를 출력하는 모델로 연구 초기에는 CNN 기반으로 연구되었으나 시간이 지나 Transformer가 Vision 분야에서 높은 성능을 입증하면서 해당 분야에서도 이러한 연구들이 이어지게 됩니다.
하지만 SISR model의 연구에서 가장 중요한 것은 바로 '실생활'에서 활용이 가능해야 하는 점입니다. 그러기 위해서는 성능과 계산 복잡성 상이의 균형을 가져가는 것이 핵심입니다.
CNN Based SISR Model
CNN 기반 SISR Model의 연구 초기에는 성능과 계산 복잡성 사이의 균형을 잡기 위해서 Kernel Weights 재사용 기법을 채택하여 진행되었습니다. 하지만 이러한 초기 연구 방식은 파라미터를 줄일 수 있었으나 계산 복잡성의 경우 오히려 향상하는 모습을 보이는 한계점이 존재하였습니다. 더불어 동일한 kernel을 반복적으로 활용하는 점에서 오히려 성능저하 현상이 관측되기도 하였습니다. 이외에도 가중치 공유 및 특징 공유 기법들이 제안되었으나 이는 layer가 깊어짐에 따라 오히려 계산 복잡성이 크게 증가하게 됩니다. 이러한 초기 연구의 한계점들을 해결하기 위해서 Dynamic Residual Connection, Information Distillation 기법 연구들이 이어졌습니다. 특히, Information Distillation의 경우, 점진적으로 feature를 개선하면서 파라미터와 계산 복잡성을 낮출 수 있었습니다.
즉, 경량화를 수행하는 점과 동시에 성능을 챙기기 위해서 Feature 재사용, Residual connection, Information Distillation 등 다양한 기법 등으로 보완하고자 하는 노력들이 이어지게 되었습니다.
Transformer based SISR Model
Transformer의 Language 영역에서 우수한 성능을 입증하면서 이를 Vision 분야에서도 활용하고자 하는 연구들이 활발히 이어지면서 Vision 분야에서도 Transformer를 활용하고자 하였습니다. 더불어 이러한 영향은 SISR 분야에서도 동일하게 일어났습니다. 하지만 Vision 분야에서 Transformer를 실생활에서 활용하기 위해서는 경량화가 무조건적으로 필요한 상황입니다.
Transformer based SISR Model 연구에서는 Shifted-Window, 경량화 된 CNN 과 Transformer의 결합 혹은 Super-Pixel Clustering Self Attention, Self attention matrix와 Query, Key의 가중치 공유 등 다양한 경량화 연구들이 이어졌습니다.
하지만 이러한 연구의 경우 계산 복잡도를 낮추는 데에는 긍정적인 기여를 수행했으나 구조적 한계점이 존재하였습니다. 즉, Self-attention을 더 쌓아 올리는 것이 어려운 문제점들이 존재하였습니다. 이로 인해서 Channel Correlations Self-attention layer를 도입하는 연구들이 이어졌습니다. 하지만 Spatial Correlations 파악이 어려운 한계점들이 존재하였습니다.
ASID(Attention-Sharing Information Distillation)
이러한 선행 연구들의 한계점들을 해결하기 위해서 본 논문에서는 CNN의 선행 연구 중 Information Distillation을 수정해서 Self-attention에 적용여 계산 복잡성 및 병목 현상을 해결하고자 하였습니다. 특히, 본 논문에서 제안하고 있는 ASID의 경우, Attention-shatinf, Channel-Split, Information Distillation 기법을 활용했습니다.
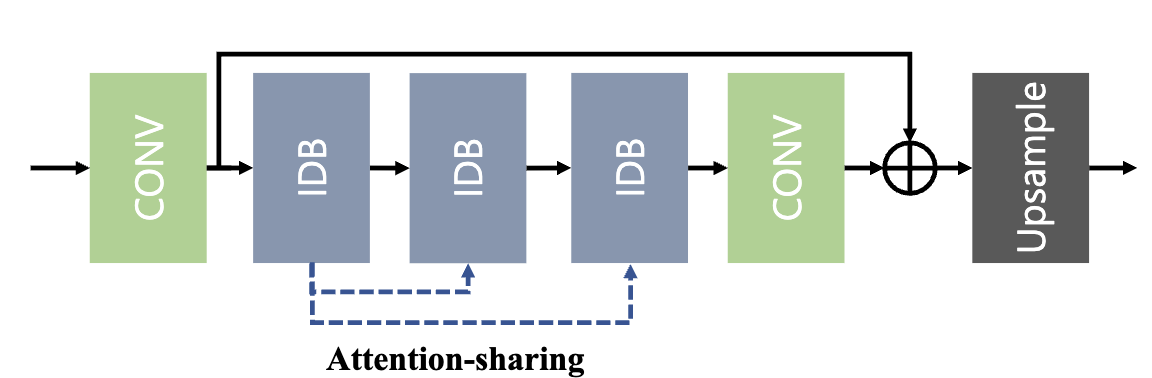
이는 ASID의 전체적은 구조를 나타낸 것으로 Local Feature Extraction을 위한 CNN과 Inforamtion Distillation Block, Upsample로 설계되어졌습니다.
본 논문에서 제안하고 있는 핵심 기술력은 바로 Inforamtion Distillation Block(IDB) 라고 할 수 있습니다.
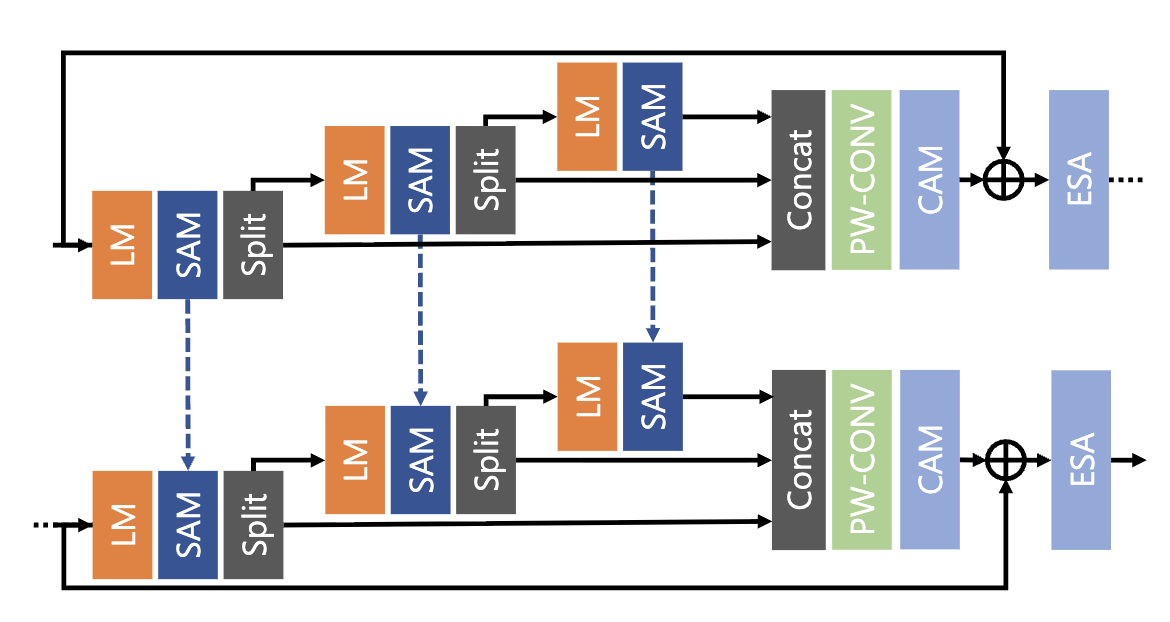
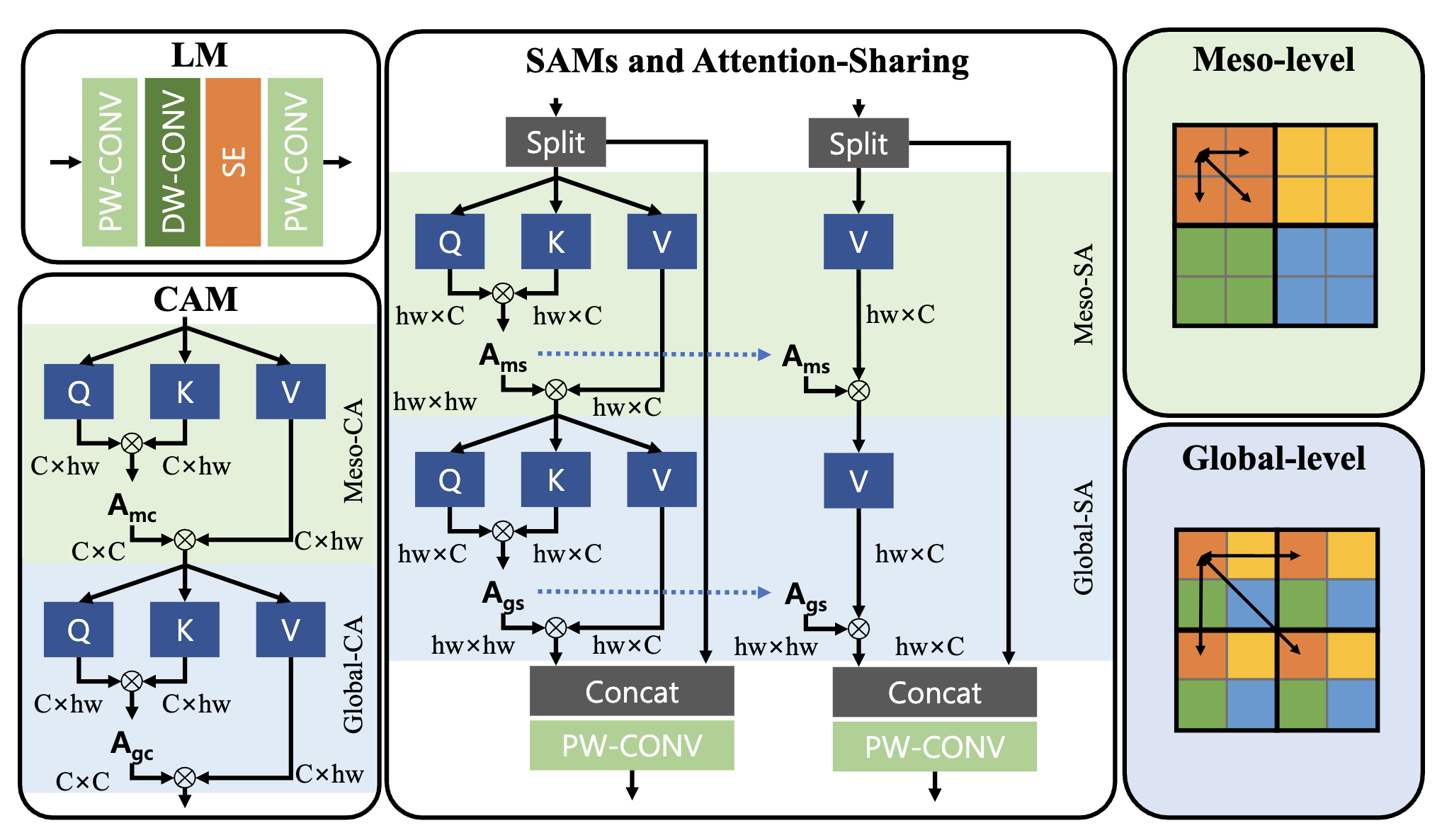
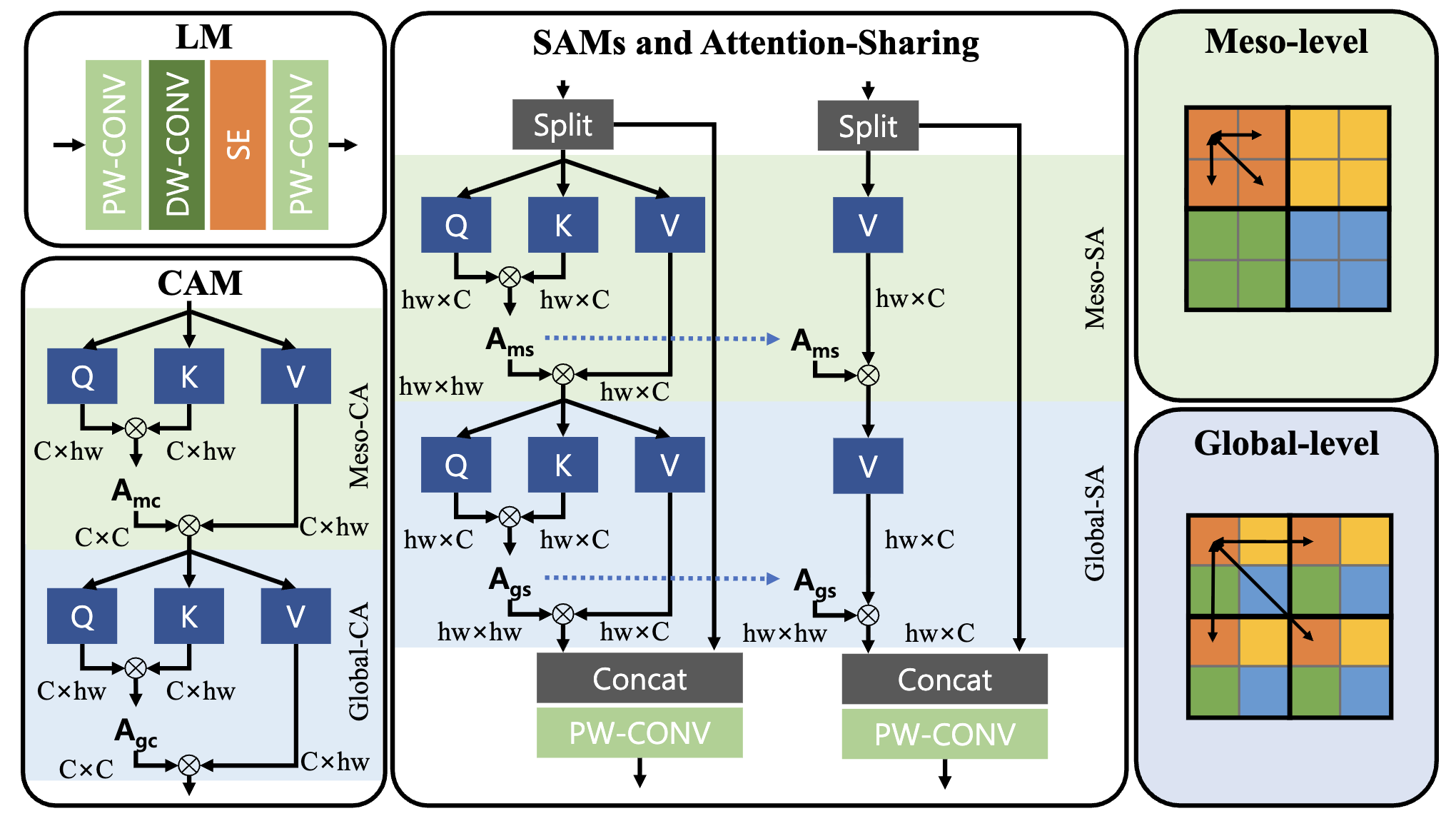
IDB는 크게 Local Module(LM), Spatial Attention Module(SAM), Channel Attention Module(CAM)로 구성되어져 있습니다. 이러한 설계는 특정 채널이 다른 채널보다 중요한 feature를 전달하는 것에서 착안되었으며 필수 Feature를 보존하고 나머지 feature를 후속 모듈로 넘기는 방식입니다.
- Local Module의 경우, 일반적으로 Local Feature Extration을 수행하게 되며 이를 통해서 Local feature Extraction을 위한 convolution layer와 Align을 수행아게 됩니다.
- SAM & CAM의 경우, Channel 분할을 통해 Channel별로 특징을 나누고 단일 윈도우 내에서와 서로 다른 윈도우(global - level) 모두에서 픽셀 상관 관계를 캡처하여 특징 표현력을 향상시키게 됩니다. 더불어 Non-overlap Window based Self-attention과 Patch 내부와 Patch 사이의 정보를 모두 통합하여 활용하기 때문에 Representation Capacity를 향상시킬 수 있었습니다. 이로 인해서 Local Inforamation과 Long-ragne Dependency를 해결할 수 있습니다.
위의 Attention Module에서 가장 중요한 점은 Attention-Sharing, Channel Split을 활용한다는 점입니다.Transformer based SR Model의 경우, 비효율적이지만 Self-Attention layer를 쌓아 올리는 데 있어서 필수적인 기법입니다.
- Attention Sharing의 경우, Self-attention layer 간에 attention matrix를 공유하며 Spatial attention 연산 필요성을 없애주는 역할을 수행하게 됩니다.
- Channel Split의 경우, Spatial attention연산에 관여하는 channel 수를 제한하여 계산량 및 파라미터를 효과적으로 줄일 수 있게 됩니다.
이로 인해서 Transformer base SR model에서 더 많은 layer를 구축할 수 있는 장점이 있습니다.
Experiments
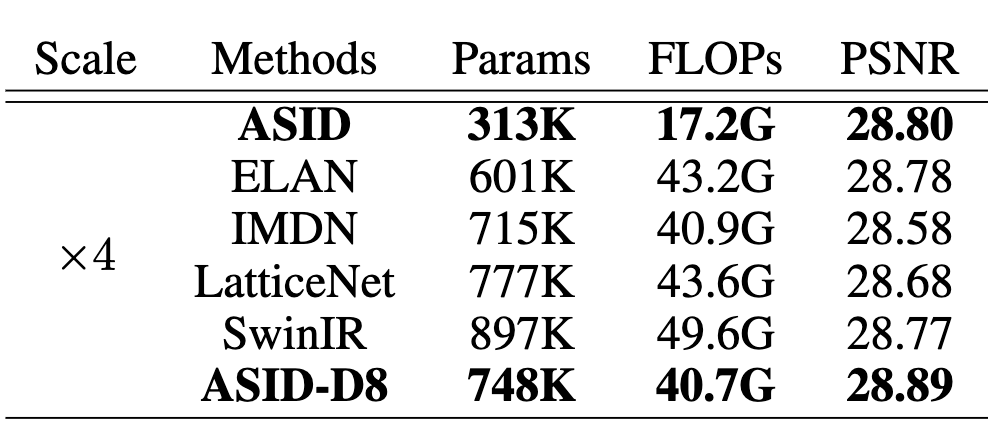
해당 결과는 4배(×4) 업스케일링 조건에서 다양한 경량 이미지 초해상도(Super-Resolution, SR) 방법들의 성능과 효율성을 비교한 것으로 비교된 모델 중 가장 적은 파라미터 수와 가장 낮은 연산량을 보이며 그럼에도 불구하고 PSNR은 28.80으로, ELAN(28.78)이나 SwinIR(28.77)과 거의 동등하거나 오히려 약간 더 높은 성능을 달성했습니다. 이는 ASID가 매우 효율적이면서도 경쟁력 있는 이미지 재구성 품질을 제공함을 의미합니다.
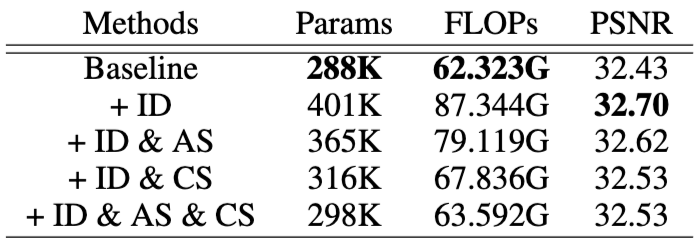
ASID 네트워크의 각 핵심 구성 요소(Information Distillation, Attention-Sharing, Channel-Split)가 모델의 성능(PSNR)과 효율성(Params, FLOPs)에 미치는 영향을 분석한 ablation study 결과입니다.
ASID가 Baseline 수준의 복잡도로 더 나은 성능을 달성했음을 보여주며, 제안된 경량화 전략들이 효율성과 성능의 균형을 효과적으로 맞추고 있음을 나타냅니다. 특히 ID에서 성능이 가장 높았지만, 파라미터와 FLOPs가 크게 증가했던 문제점을 AS와 CS가 효과적으로 완화했음을 알 수 있습니다.
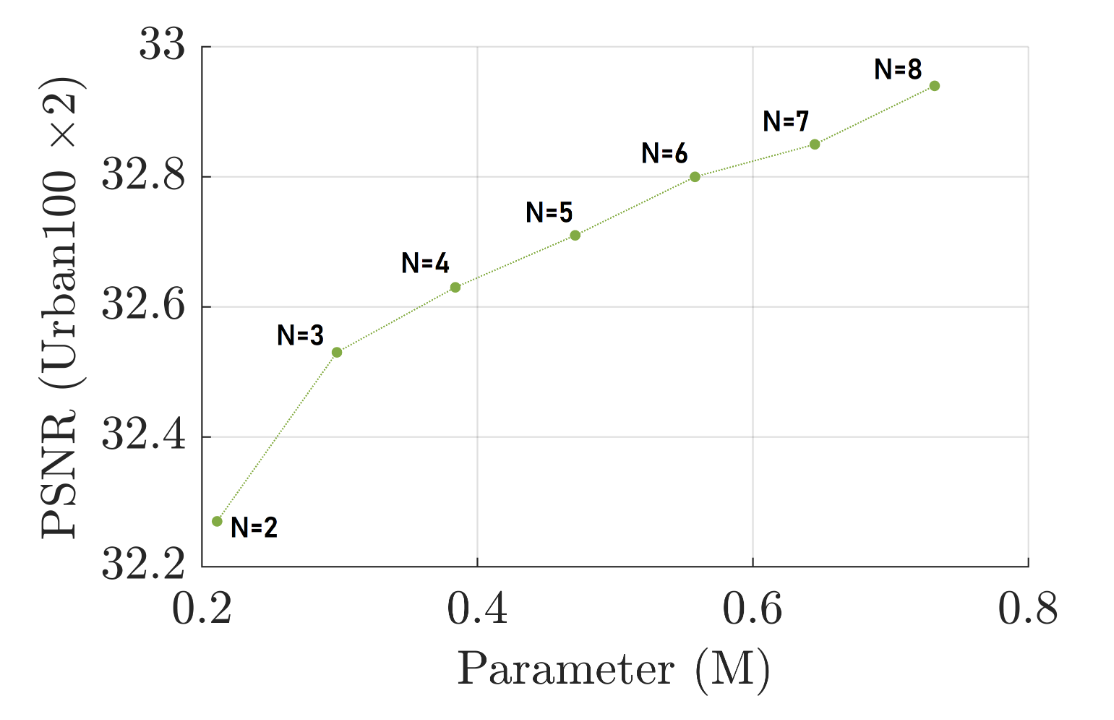
이는 ASID(Attention-Sharing Information Distillation) 네트워크의 깊이, 즉 Information Distillation Blocks (IDBs)의 개수(N)가 변화함에 따라 모델의 성능(PSNR)과 파라미터 수에 어떤 영향을 미치는지 보여줍니다.
IDB의 개수(N)가 증가할수록 모델의 파라미터 수도 증가하며, 이에 따라 PSNR 값(성능)도 점진적으로 향상되는 것을 볼 수 있습니다. 이는 네트워크가 더 깊어질수록 더 많은 특징을 학습하고 장거리 의존성을 더 잘 포착할 수 있기 때문입니다. 그러나 N=3 지점 이후부터는 파라미터 수가 계속 증가함에도 불구하고 PSNR 값의 증가폭이 점차 줄어드는 경향을 보입니다. 특히 N=6, N=7, N=8로 갈수록 파라미터 수는 상당히 늘어나지만 성능 향상은 미미합니다. 즉, N=3 지점 이후부터는 파라미터 수가 계속 증가함에도 불구하고 PSNR 값의 증가폭이 점차 줄어드는 경향을 보입니다. 특히 N=6, N=7, N=8로 갈수록 파라미터 수는 상당히 늘어나지만 성능 향상은 미미합니다. 즉, N=3 이후부터는 성능 개선 대비 파라미터 증가의 효율이 감소하여 경량화 목표에 부합하지 않기 때문입니다.
Conclusion
ASID는 Transformer에 특별히 적용된 Information Distillation 구조를 사용하여 낮은 복잡도로 여러 self-attention 레이어를 효율적으로 쌓을 수 있습니다. 또한 ASID는 attention-sharing 및 Channel-split 기술을 통합하여 일반적으로 self-attention 연산과 관련된 계산 오버헤드를 크게 줄입니다.
해당 논문을 통해서 Engineering Design의 필요성을 느끼는 계기가 되었습니다. 더불어 실생활에 활용하기 위해서 경량화 전략을 다양하게 가져가면서 각 기법들이 서로의 단점들을 보완하며 설계된 점을 통해서 특정 영역의 기법을 가져와서 활용하는 전략에 대해서 많은 영감을 받게 되었습니다.
