LLM은 어떻게 전자양을 꿈꾸게 되었나
글을 시작하기에 앞서, 제목에서 풍기는 대중적인 어감과 달리 이 글은 다분히 기술적인 이야기를 담고 있음을 밝힌다.
본래 의도했던 내용과 결이 많이 달라져서 시리즈를 이어가는 대신 그냥 노선을 중간에 틀어야 했다. 결론만 짧게 이야기하자면, LLM은 왜 거대해야 하며, 그것이 기존의 AI와 어떤 차이를 만들었는지에 대한 이야기다.
핵심 질문: 왜 '거대함'이 지능을 만드는가?
GPT-3가 본격적인 LLM의 시대를 열었다는 것에는 다들 이견이 없다. 그러나, GPT-3가 그 당시 주목 받을 수 있었던 이유는 단순히 그 거대한 크기 때문이 아니다. 다음 그래프가 보여주는 것은 모델 크기에 따른 창발적 능력(emergent ability)의 출현이다.
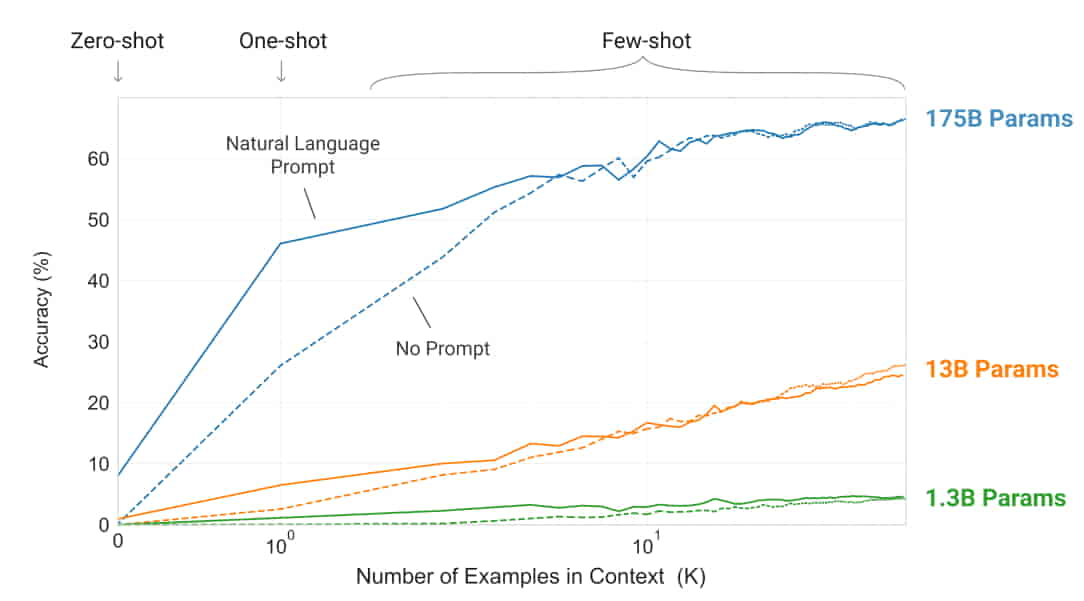
학습 없이 적은 수의 예제만으로 새로운 작업을 수행하는 것을 few-shot learning이라고 한다. 이는 단순한 패턴 매칭을 넘어선 초보적인 지능, 즉 주어진 지식을 처리할 수 있는 추론 능력을 의미한다. 하지만 '거대한 모델에 방대한 데이터를 주입한다' 는 1차원적인 설명으로는 부족하다. 대체 왜 모델의 크기가 커져야만 이것이 가능해지는지, 바로 그것이 핵심이다.
언어의 본질적 특성: 구조적 희소성(Structural Sparsity)
모든 딥러닝 모델은 손실 함수(loss function)를 최소화하는 방식으로 학습한다. 그런데 언어는 다른 데이터와 근본적으로 다른 특성을 갖는다. 가령 시각 정보와 언어 정보를 다음의 예시를 통해 비교해 보자.
-
시각 데이터는 내재된 공간적 구조(spatial structure)를 갖는다.
사과를 모르는 사람에게 사과 10개를 보여주면, 사과가 무엇인지 몰라도 "같은 객체 10개" 라는 패턴을 즉시 인식할 수 있다. 이는 사과를 정의하는 시각 정보가 모두 유사한 공간적 구조를 갖고 있기 때문이다. -
언어 데이터는 임의적인 기호 체계(arbitrary symbolic system)를 갖는다.
한국어를 모르는 화자에게 "사과 드립니다" 와 "사과는 맛있어" 라는 두 문장을 보여주면, 두 문장의 의미 차이를 즉시 파악할 수 없다. 같은 '사과' 라는 단어가 쓰였지만 그 의미가 서로 다르기 때문에, 맥락을 고려하지 않으면 둘 사이의 관계를 유추할 수 없기 때문이다.
이것이 구조적 희소성이다. 언어 데이터에서는 의미 있는 패턴의 밀도가 극도로 낮다는 뜻이다.
제한된 용량에서의 최적화 전략
작은 모델이 제한된 데이터로 loss를 줄이는 가장 효율적인 방법은 국지적 패턴(local patterns)을 먼저 학습하는 것이다.
- 특정 언어의 문법적 규칙
- 특정한 어휘들이 동시에 등장하는 빈도(co-occurence)
- 짧고 간단한 구문 구조
이는 곧 표면적 언어학 지식(surface-level linguistic knowledge)에 해당한다.
임계점을 넘어선 모델의 행동 변화
누군가 이런 생각을 했다.
충분한 용량(가중치)과 데이터, 그리고 장기적 의존성(long-range dependencies)을 처리할 수 있는 컨텍스트 윈도우가 주어지면 상황이 바뀌지 않을까?
그리고 그들은 실제로 상황이 바뀌는 것을 목격했고, GPT-3는 그렇게 세상에 등장할 수 있었다... 라는, 농담 반 진담 반의 가설이다.
어찌 됐건, 이 상태에서는 국지적 패턴을 학습하는 것만으로 더 이상 loss를 줄일 수 없는 지점에 도달한다. 하지만 참고할 데이터도, 가중치의 용량도 아직 넉넉하다. 모델은 loss를 줄일 방법을 고민하다, 끝내는 남은 가중치를 쥐어짜 전역적 패턴(global patterns)을 학습하기 시작한다.
- 담화 구조(discourse structure)
- 개념 간 추상적 관계
- 문맥에 기반한 의미 해석
전역적 패턴 학습은 메타인지적 능력(metacognitive ability)을 요구한다. 단순히 패턴을 기억하는 것이 아니라, 패턴들 간의 관계를 파악하고 새로운 상황에 적용하는 능력이다.
메타인지적 처리와 단순 암기의 차이를 보자.
단순 암기
입력: "2+2의 값은 무엇인가?"
출력: "4" (미리 저장된 답)메타인지적 처리
입력: "23847+59273의 값은 무엇인가?"
과정:
1. 덧셈 패턴 인식
2. 자릿수 처리 규칙 적용
3. 받아올림 메타 규칙 사용
4. 결과 검증
출력: "83120"이런 능력은 다층적 추상화(multi-level abstraction)를 요구한다.
- Level 1: 토큰 패턴 (문법, 어휘)
- Level 2: 의미 패턴 (개념, 관계)
- Level 3: 구조 패턴 (논리, 담화)
- Level 4: 메타 패턴 (패턴 간 관계, 적용 규칙)
메타 패턴과 추론 능력의 출현
여기서 핵심은 메타 패턴(meta-pattern) 학습이다. 이는 다음 과정을 포함한다.
- 입력 패턴 분석
- 유사 패턴군 식별
- 패턴군의 변환 규칙 추출
- 새로운 입력에 규칙 적용
구체적으로 살펴보자:
1단계: 단순 패턴 기억
"사과는 빨갛다" → 사과 = 빨간색
"바나나는 노랗다" → 바나나 = 노란색이는 단순한 연상 기억(associative memory)이다.
2단계: 패턴 간 관계 파악
예제로부터 패턴 인식: "사과는 빨갛다. 바나나는 노랗다. 귤은 주황색이다. 그렇다면 체리는?"
메타 규칙: 과일 → 색깔 서술 구조를 파악하여 기존 지식과 연결
구조를 기반으로 새로운 적용: "체리는?" → "빨갛다"3단계: 복잡한 사고 패턴 적용
"셰익스피어가 AI에 대해 뭐라고 했을까?"라는 질문에서:
불가능성 인식: 셰익스피어 시대에 AI 개념 없음
의도 파악: 셰익스피어 문체로 AI 견해 요청
패턴 결합: 셰익스피어 문체 + AI 개념 + 당대 철학적 관점
창조적 합성: 새로운 텍스트 생성이는 귀납적 추론(inductive reasoning)을 구현한 것이며, 지금까지의 AI처럼 단순한 패턴 매칭만으로는 이러한 사고 과정을 모사할 수 없다.
언어 패턴의 조합적 복잡성(combinatorial complexity)을 고려하면, 가능한 모든 패턴을 저장하는 것은 현실적으로 불가능하다. 따라서 LLM은 압축된 표현(compressed representation)을 통해 패턴의 생성 규칙을 학습한다.
왜 '거대함'이 필요한가?
지금까지의 내용을 요약하면 LLM이 거대해야 하는 이유는 다음의 두 가지로 정리할 수 있다.
-
표현력 가설(Expressivity Hypothesis): 복잡한 전역적 패턴을 표현하려면 충분한 모델 용량이 필요하다. 작은 모델로는 고차원 패턴 공간에서의 복잡한 함수를 근사할 수 없다.
-
임계 질량 가설(Critical Mass Hypothesis): 메타 패턴 학습에는 임계 수준 이상의 데이터와 가중치가 필요하다. 이 임계점을 넘어야 창발적 능력이 나타난다.
다시 말해 작은 모델은 언어가 가진 국지적 특성을 학습하기 위해 보유한 가중치의 용량을 모두 사용하지만, 그 이상으로 거대한 모델은 언어가 가진 전역적 특성을 모사하고 메타 패턴을 인지할 수 있는 표현 공간(representation space)을 확보할 수 있다.
따라서 LLM의 지능은 단순히 몸집만 불려서 나타난 결과가 아니라, 언어의 구조적 특성과 학습 알고리즘의 특징이 결합하여 나타나는 창발적 현상(emergent phenomenon)이다.
cf. 사실, 이 부분에 대해 내가 쓴 원문의 설명이 너무 장황해서, AI에게 도움을 요청했다. 그 결과로 내용의 핵심은 유지하면서도, 표현이 조금 더 축약하고 용어가 전문가답게 가다듬어진 좋은 글이 만들어졌다. 그러나 내 글에서 자주 나오는 말투와는 차이가 크기도 하고, 그다지 거창한 이름을 붙여가며 쓴 글은 아니었기에 다소 어색하게 느껴지는 점은 어쩔 수가 없었다. 그러나 어쨌건 내 글보다 읽기 쉬워진 건 사실이라, AI의 작문 실력을 존중하여(?) 그냥 고치지 않고 두기로 했다.
결론
중국어 방이라는, AI 쪽에선 매우 오래 된 역설이 있다. 요지만 설명하면, AI가 인간과 구분할 수 없게 된다 해도 그 사고 과정이 '생각' 일지 '암기' 일지는 알 수 없다는 것이다.
그러나 위의 내용에서 알 수 있다시피, LLM을 단순한 패턴 매칭이나 중국어 방으로 이해하는 것은 핵심을 놓치는 것이다. 언어는 다른 데이터에 비해 그 구조적 희소성이 매우 높다. 이는 곧 '암기' 의 난이도가 다른 데이터보다 훨씬 높다는 것을 의미한다. 현재 자주 사용되는 수십~수천억 정도의 가중치로는 언어의 형태로 저장된 방대한 지식을 암기만 가지고선 다룰 수 없다. 이는 위에 언급된 압축된 표현을 사용하더라도 마찬가지다.
즉, LLM은 실제로 계층적 추상화(hierarchical abstraction)와 메타인지적 처리(metacognitive processing)를 통해 언어의 구조적 희소성을 극복하고 지식을 습득하는, 고도화된 통계적 시스템이다.
난 어떤 사람이 아무리 숙련된 LLM 엔지니어라고 하더라도, 이런 메커니즘을 이해하지 못하고 'LLM은 그냥 큰 모델' 이라고 말한다면 그 사람에게 전문가라는 칭호를 붙이지 않는다. 진정한 이해는 "어떻게?" 와 "왜?" 에 대한 깊은 숙고를 요구한다.
